基本信息
原文标题:AutoPentester: An LLM Agent-based Framework for Automated Pentesting
原文作者:Yasod Ginige, Akila Niroshan, Sajal Jain, Suranga Seneviratne
作者单位:澳大利亚悉尼大学、澳大利亚新南威尔士大学、Catharsis Pvt. Ltd.
关键词:自动化渗透测试、威胁分析、自动化、LLM Agent
原文链接:https://arxiv.org/pdf/2510.05605
开源代码:https://github.com/YasodGinige/AutoPentester
论文要点
论文简介:本文针对日益增长的网络安全威胁,以及渗透测试与漏洞评估行业对专业人力日益提升的需求与供给短缺,提出了一套基于大语言模型(LLM)Agent的自动化渗透测试框架——AutoPentester。不同于现有依赖人工操作或半自动化的工具,如PentestGPT等,本框架能够以最小化人工干预,自动完成信息收集、漏洞评估、攻击执行与报告生成等完整流程。AutoPentester采用模块化设计,关键组件包括战略分析、知识检索、结果校验、循环检测和工具接口,有效模拟了人类渗透测试专家的“推理—决策—行动—纠偏”闭环。
实验证明,AutoPentester在Hack The Box平台与定制漏洞虚拟机上均相比基线工具(PentestGPT)实现了27%子任务完成率和39.5%漏洞覆盖率的提升,人机交互次数显著减少。多位行业专家参与的使用调研和消融实验进一步证实了该框架在实际工程中的效率和应用前景。
研究目的:论文旨在解决当前自动化渗透测试过程中,因自动化程度低、依赖人力高、策略推断能力不足、易于陷入死循环、工具指令生成不完整等一系列痛点问题。随着网络攻击规模与复杂度持续提升,行业渗透测试需求远超人力供给,迫切需要智能化、全自动的技术系统替代传统模式。尽管AI特别是LLM技术近年被应用于该领域,但现有工具大多仅为“顾问”系统,不能独立完成全流程,缺乏对实际行业需求的适配。
AutoPentester正是针对这些核心瓶颈,通过引入多智能体协作、检索增强与结果验证机制,实现高水平自主策略规划与行动,为行业提供一套系统级的自动化渗透测试解决方案。
研究贡献:
提出AutoPentester,一个全新LLM-agent自动化渗透测试、漏洞评估与威胁分析框架,突破既有方案在策略推理、自动调整、自动化程度和对人类专业知识依赖等关键局限。
采用多种主流LLM引擎,结合多类型测试任务,实证证明该框架在子任务完成率、漏洞覆盖率等指标上较PentestGPT有大幅提升。
分析并通过消融实验量化各核心模块(如RAG、循环识别、结果校验)对整体性能的独立及协同贡献。
基于真实渗透测试专家群体调研,从定量和定性两个维度检验工具效果及产业价值,并获得积极反馈。
引言
当前网络空间威胁日益加剧,数据泄露、勒索攻击、钓鱼与间谍渗透等事件持续高发,攻击目标范围已从大企业延展至中小企业、公共机构乃至社会基础服务领域。随之而来的,是对计算机与网络系统安全防护水平的刚性要求必然上升,渗透测试与威胁评估已成为保障信息安全的行业标准和法律强制规范。渗透测试扮演着“模拟真实攻击者”的关键角色,致力于提前发现系统潜在漏洞,助力组织主动防御;漏洞和威胁评估则围绕脆弱点的系统识别、风险优先级分析与响应建议展开。
然而,渗透测试与漏洞评估流程高度依赖专业人才,操作高度重复且耗时,通常一次完整测试需要超过两周——严重制约了应对巨量安全需求的效率,行业人力资源已明显捉襟见肘。基于人工智能的自动化提升成为行业迫切诉求。早期自动化探索主要集中于利用深度强化学习(RL)进行攻击路径建议,但往往止步于“建议”,无法独立执行渗透、生成详尽测试报告。近年来,大语言模型(LLM)崛起,推动了初步的自动化渗透测试尝试,如PentestGPT。但这类工具存在诸多典型问题:自动化流程断点处需人工介入,策略推理与行动脱节,生成指令易出错,且工具适配面窄,大部分只针对单一安全工具或浅层任务,无法生成行业标准的渗透测试报告,也缺少行业专家参与的实际反馈验证。
本文提出AutoPentester,目标是实现“高自动化、强推理、低人力依赖”,覆盖信息收集、漏洞发现、利用到报告等渗透测试全流程。通过精细的模块协作,模拟人类渗透测试者的推理与调整过程,随输出动态规划最优攻击路径,极大提升工作效率与智能性。文章结构安排为:第II部分回顾相关自动化渗透测试进展,III介绍AutoPentester框架设计,IV、V分别阐述实验设置与评测结果,VI探讨局限、展望未来。
相关工作
当前自动化渗透测试领域主要分为两类路径:一是基于机器学习(特别是强化学习)的算法探索,二是依托大语言模型(LLM)的“智能Agent型”工具发展。
机器学习路径上,早期如Hu等提出的基于深度Q学习(DQN)两阶段自动化渗透过程,先借助网络拓扑和安全规则生成攻击树,再用RL动态规划最易利用的攻击路径,但实际执行和报告撰写依然离不开人工。HA-DRL通过代数式动作分解管理超大动作空间,实现更高效、稳定的攻击路径规划。但这些方法核心关注网络攻击路径建议,并未覆盖实际漏洞利用和报告生成。后续如NIG-AP将渗透建模为MDP过程,虽可自主发现多路径但同样受限于端到端自动化与漏洞探测覆盖。更有针对云应用的渗透测试方案,但高度依赖目标架构与手工注解,难以普适推广。整体而言,机器学习类方法重策略优化,局限于部分子步骤,难以形成全流程闭环。
LLM路径因其对工具语义、漏洞知识和任务步骤的庞大先验积累,成为当下更具前景的研究潮流。以ScriptKiddie为代表的Agent侧重于自动化单项目标(如邮箱泄露),只能输出高阶操作建议,具体执行与结果分析仍依赖人类。PentestGPT是典型尝试,其通过Summarizer、Analyzer、Generator三大模块引导策略、生成指令,对抗目标主机提出多步计划。但两大显著短板在于指令“落地”需人操控工具、对步骤执行结果人工反馈极为依赖。此外,PentestGPT对于实际操作要有相当专业的安全人员配合,降低了实际应用自动化程度。AutoAttacker在自动化层面有所进步,内嵌Metasploit工具实现“指令—执行”整合,但局限于单一攻击框架且评测面窄,PenHeal亦存在类似局限。现有多数LLM方案缺乏对真实行业场景复杂性的适配,无法生成完整测试报告,缺少对专业人士验证。
行业痛点在于现有自动化方案要么仅限于策略建议、工具单一、自动化度低,要么强依赖专家,难以完整闭环且评估不足。因此亟需能够自主推理、自动行动、结果校验、报告生成并获得行业实际检验的系统级方案,AutoPentester正是在此背景下应运而生。
AutoPentester框架设计
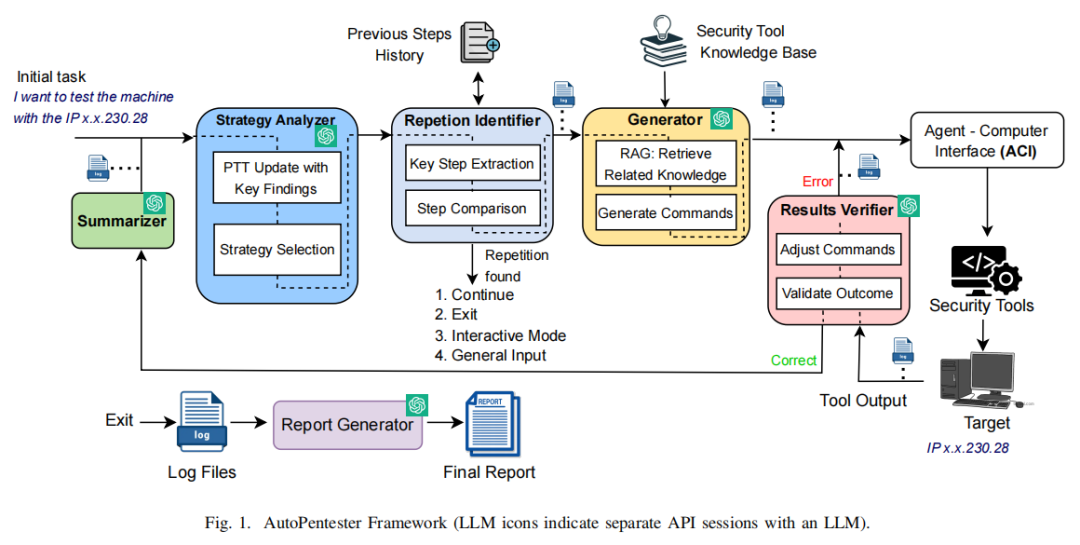
AutoPentester框架充分模拟人类高级渗透测试流程,围绕五大LLM-agent协同工作,并配合多个自动化工具接口组成完整闭环。从整体架构看(详见原文Fig.1),各模块既彼此独立又递进耦合,贯穿“输入目标—策略规划—知识补给—指令下发—行动反馈—策略调整—报告汇总”的全流程自动化逻辑。
首先,Summarizer模块负责将安全工具反馈的复杂文本输出按需分割、去重、分段摘要为便于理解的结构化语句,通过滑动窗口机制解决LLM输入长度受限一类现实难题,并为后续推理模块提供精确的环境信息描述。核心的Strategy Analyzer则在每轮循环中,基于Pentest Tree(PTT)创新结构存储和贯穿记录所有关键子任务与发现结果,结合Chain-of-Thought(CoT)推理模式,动态调整与演进攻击路径,避免频繁重复无效探索。此举本质上强化了模型的全局性记忆与推理能力,也是与PentestGPT单步推断的关键区别。
为防止操作陷入无效死循环,Repetition Identifier引入向量嵌入与余弦相似度检测机制,自动识别任务及指令的重复性,并在检测到“自我固化”时,向用户提供自由选择:继续、退出、激活交互模式或补充说明,有效保障系统的自适应和灵活性。Generator模块内嵌RAG(Retrieval-Augmented Generation)框架,将战略分析得到的子任务与知识库实时匹配,检索包含Metasploit官方文档、流行网络安全教材、HackTricks等优质知识源,通过OpenAI向量化模型过滤相关语料,大幅提升自动生成指令的准确率与实用性,尤其对复杂、多变工具环境下的参数组合给出最优解。该过程把执行平台现状(本地IP、文件路径等)纳入上下文,真正实现“零人工介入”的完整指令生成闭环。
Agent Computer Interface(ACI)进一步承担指令提取解析、工具接口调用及兼容适配任务,利用subprocess与pexpect等技术灵活对接Nmap、Metasploit、Dirbuster等主流CLI安全工具,甚至支持后续扩展至更广泛的静态/交互工具链。Results Verifier作为自回路纠偏机制,自动比对预期与实际结果,一旦发现工具输出异常、命令错误、不完全,自动纠正并重新生成最优指令。最终,Report Generator根据全程记录输出业界广泛认可的.csv格式渗透报告,涵盖CVE编号、CVSS风险分值、协议、漏洞描述与修复建议等要素,实现专业报告自动化落地。
AutoPentester本质上构建了具备推理自主性、行动自动化、纠错能力、报告标准化的一体化渗透测试智能体,核心创新在于分析-决策闭环、结构化知识支撑、多Agent协同及人机交互灵活融合,显著优于传统“半自动”方案。
实验设计
为全面评价AutoPentester的智能化渗透测试能力,作者在实验设置上兼顾现实复杂性与对比再现性。整体环境采用Linux虚拟机,各类网络攻防工具(Nmap、Metasploit、Netcat、Nikto、Dirbuster、John the Ripper、Sqlmap、Smbclient等)一应俱全,确保平台具备工业级测试能力。目标实体分为业界公认的Hack The Box(HTB)靶机和四台自主搭建的包含OWASP Top10典型漏洞的VM(其中一台为经典Metasploitable II),既保证战略攻击的真实性,又便于全覆盖性能评测。

具体选择HTB平台上10台机器(6易4中),兼顾知名研究(如PentestGPT基线靶机复现)与新场景(扩展靶机类型),每台机器包含多样端口、服务、漏洞类型,从实际攻防场景推演出9类子任务:端口扫描、网页与网络枚举、密码与文件分析、命令注入、已知漏洞利用等。评测以官方Writeup细分子任务清单,确保定量标准客观一致。自定义VM侧重漏洞及威胁评估场景,主打诊断速度与覆盖全面性。
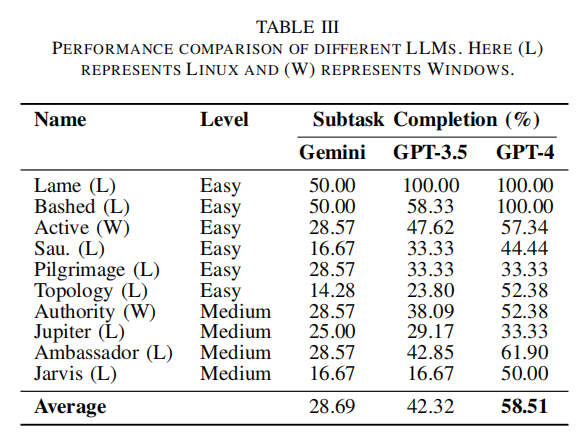
对比基准选择同为LLM-Agent范式、公开代码的PentestGPT,其余同类工作因不可复现暂不列入。对于LLM主干测试,作者尝试了Gemini-2.0-flash、GPT-3.5-turbo与GPT-4-turbo,最终以后者为主干驱动,其子任务完成率显著领先于前二者,确保架构自身能力无明显因模型选择而偏倚。
性能评估采用多维度指标:子任务完成率(Subtask Completion %)、服务覆盖率(Services Coverage %)、总步骤数、循环数(死循环)、人工交互比例、指令完整率、漏洞覆盖(针对自定义VM)。采集与统计过程严格双人复核三次实验结果取平均,充分控制人工误差。为契合实际职业评估,还辅以专业渗透测试师参与的主观问卷调研,从结果质量、策略强度、报告清晰度、人机协同效率等多维验证产业应用价值。
实验结果
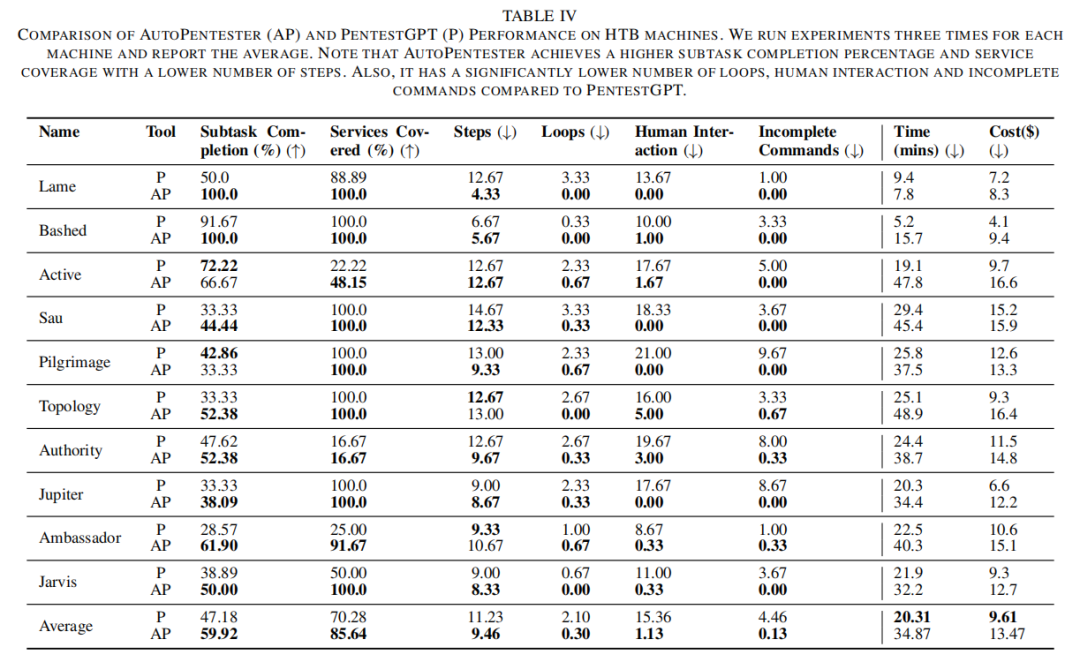
AutoPentester在定量实验中表现优异,尤其在HTB靶机及自建VM两路测试上,重要指标均全面超越PentestGPT。具体来看,HTB靶机10台的平均子任务完成率AutoPentester提升至59.92%(比PentestGPT高出27.0%),在漏洞服务点覆盖、步骤数减少、死循环次数压缩(下降85.7%)、人机交互量锐减至1.13(PentestGPT为15.36),以及指令出错率仅为0.1(对比4.46)。自建漏洞VM场景中,覆盖率达98.14%、步骤与失误显著低于基线,充分展现系统高效、智能、自动化程度。成本与时耗方面,虽然AutoPentester因RAG等链路增加,平均消耗高出$3.86,时耗71.9%增加,但综合节省的人力成本远超模型Token费用,其后端自动化运行能力使得实际项目交付效率大幅提升。
主观调研层面,10位资深渗透测试与网络安全从业者一致认可AutoPentester的自动化闭环、有机推理、报告质量与流程高效,综合得分3.93/5,19.8%高于PentestGPT,尤其在攻击面覆盖、信息透明度、操作高阶化、自动化流程四大项表现最优。用户自由文本反馈与情感分析结果(见原文WordCloud),正面词汇高频出现,突出“自动”、“步骤”、“报告”、具体、结构化优点,而PentestGPT依赖“手动”、用户干预、灵活但重复劣势凸显。值得一提的是,专家群体建议AutoPentester在红队演练与大规模企业评估可显著提升生产力并降低操作风险,报告模式和可读性亦备受好评。

消融实验系统性剖析了各模块对总性能的贡献。以HTB-Lame为例,基础模型加入推理型Strategy Analyzer后完成率提升25%,RAG组件使指令生成正确率与完整度进一步大幅提升;Repetition Identifier模块使循环率下降90.5%;Results Verifier则使出错概率降幅达80%,共同推动框架协同最优。消融分析充分验证模块设计合理性与系统整体协同优势。

最后,作者分析典型失败场景(如部分策略推理能力不足、特定exploit知识缺失、Web交互模式特殊等),为后续优化指明方向。
论文结论
本文提出并系统实现了AutoPentester,一种以LLM-Agent为核心的自动化渗透测试框架。大量实验证据表明,其在自动化程度、子任务完成率、漏洞覆盖面、指令准确率、步骤优化及人机交互需求等方面均显著优于现有基线PentestGPT,能够更接近真实安全专家的工作范式,显著缓解行业人力短缺与流程低效两大瓶颈。主观用户研究进一步印证了AutoPentester在实际生产环境中的高评价值和技术适用性。
与此同时,作者也坦诚指出框架在Web类GUI交互、特定知识广度和罕见攻击面等方面仍有局限,部分任务策略推理亟待Fine-Tune LLM或引入更高级的RLHF/偏好优化机制。未来研究方向聚焦于LLM推理能力提升、知识库动态扩充、交互界面友好性(如引入GUI工具支持)以及更广泛行业应用测试,力争将AutoPentester打造为“高效、智能、可落地”的专业自动化渗透测试平台。
声明:本文来自安全极客,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
