近一年大语言模型(LLM)的推理、工具调用、代码编写能力取得长足发展,得益于基础模型的智能水平提升,各类垂域的AI智能体(Agent)应用快速涌现。网络安全领域同样受到深刻影响——从新闻报道到安全厂商的威胁分析中,我们可以清晰观察到一趋势:黑客使用LLM协助或自动生成更具欺骗性的钓鱼邮件和深度伪造音视频、利用AI编写恶意代码、辅助漏洞发现与利用的案例正在呈爆发式增长。AI及智能体工具进一步降低了攻击的技术门槛,增强了攻击者的效率、隐蔽性与规模化能力。
然而,我们今年感受到的实际情况是:即便地缘政治持续紧张,大多数组织的安全预算并未增加,安全产品采购与运营投入保持基本稳定,AI在安全防御侧的部署尚未规模化,但整体可观测到的攻击事件数量并未出现AI赋能攻击的爆炸式增长。
这种体感的差异不免让人担忧和困惑,AI的发展和在网络安全攻防的应用趋势是毋庸置疑的,作为企业的安全负责人肯定担心自己是否已经落后、是否理解攻击方的真实能力变化。困惑的是攻击方使用AI的真实水平如何,以及是否出现突破现有防御体系的新型攻击。在预算有限的情况下,如何持续保障本单位的安全防护水位,制定合理的安全建设规划与安全运营目标与执行策略。
为此,我们参考了多个来源,包括:大模型厂商的模型系统卡(特别是网络安全能力评估部分)、AI滥用监测与遏制报告、公开披露的AI相关攻击样本与事件、前沿研究的实验结果等,同时结合奇安信安全团队的内部研究与威胁追踪实践。
基于这些可信资料,我们尝试回答以下两大核心问题:
1)攻击者在攻击链的哪些环节使用 LLM?这些能力达到了什么水平?是否已经超越人类专家?
2)端到端的自主式 AI 自动化攻击目前到达何种成熟度?是否出现使用LLM能力的新型攻击?这些攻击是否对现有防御体系造成实质性冲击?
在对这些问题展开系统分析后,本文得出了四项关键发现与判断:
关键发现一:AI 已渗透攻击链全流程,已足以显著提高攻击效率并降低门槛。但尚未普遍达到突破性效果,其主要影响仍是“效率增强”,而非创造新攻击能力。
关键发现二:AI 智能体极大提升漏洞发现与自动化渗透效率,但距离真正的自主攻击仍有明显差距。
关键发现三:真正结构化风险来自出现“AI + 多智能体 + 运行时生成”的新型攻击范式,而非某一单点能力跃升。这是未来 AI原生攻击最具颠覆性的早期信号。
关键发现四:AI 正在放大攻防原有不对称,使攻击方更容易在短期获得实际收益,而防御方的系统性升级需要更长周期。
一、AI在攻击链的全流程渗透:“能力革新”的预期与“效率飞跃”的现实
过去一年大模型的能力显著进化,AI 参与网络攻击从概念讨论进入真实场景,AI 正在渗透进网络攻击链的所有环节。但在实际安全运营中并未观察到大规模的 AI 驱动超级攻击潮。要理解这种差异,必须回到攻击流程本身,观察 AI 到底在每一个阶段介入了什么、改变了什么、以及没有改变什么。
1.1案例剖析:从GTG-2002看AI如何放大单个攻击者的作战能力
攻击者在如何利用AI应该没有比大模型服务厂商掌握的更全面更清楚的了。所以我们选择从头部大模型公司最近发布的AI滥用监测报告中分析攻击者在如何利用 AI。
为了对AI赋能网络攻击有一个总体的感官认识 ,首先来看大模型公司Anthropic在今年8月发布的AI滥用检测与应对报告中 ,一个标题为 “ 氛围黑客攻击(Vibe Hacking): 网络犯罪分子如何使用AI编程智能体来扩大数据勒索活动的规模” 的案例(代号为GTG-2002) ,该案例揭⽰了一名网络犯罪分子利用Claude Code(编者注:Anthropic公司发布的使用其最先进的Claude模型的编程智能体工具)仅在一个月内就对至少17个不同的组织实施了大规模的数据窃取和勒索活动。下面简要说明他在整个攻击过程中是如何使用Claude Code的。
1) 第一阶段 ,侦查和目标发现:用Claude Code实施自动化侦察 ,包括扫描数千个VPN终端 ,成功识别多个存在漏洞的系统;并使用多种 API 构建了全面的扫描框架 ,收集跨多种技术的基础设施信息,然后按国家及技术类型进行分类整理以确定攻击目标。
2) 第二阶段 ,初始访问和身份凭证窃取:Claude Code在实时网络渗透测试过程中提供了有效的辅助支持。例如 ,该工具能够系统地扫描目标网络 ,识别出包括域控和SQL服务器在内的关键系统 ,并在未经授权的访问尝试中收集到多组用户凭证信息。 Claude Code辅助了跨多个域的凭证攻击活动 ,该活动访问了AD系统并进行了全面的网络扫描与凭证分析。
3) 第三阶段 ,恶意软件的开发与规避手段:Claude Code被用于恶意软件的编写 ,并被用来添加反检测功能。该工具生成了Chisel隧道工具的混淆版本 ,以规避Windows Defender的检测; 同时 ,它还开发了全新的TCP代理代码 ,新代码完全不依赖于Chisel库 ,以规避安全软件的检测。
4) 第四阶段 ,数据窃取与分析:Claude Code被用于从多个受害者相关组织中全面提取和分析数据。该工具能够系统地从国防承包商、医疗服务提供商以及金融机构等受害组织中提取出有价值的数据,包括社会安全号码、银行账户信息在内的敏感数据。为下一步勒索提供信息。
5) 第五阶段 ,个性化勒索信编写:该攻击者利用 Claude Code 根据数据分析结果自动生成针对每位受害者的个性化勒索信息,包括根据财务分析结果计算出最合适的赎金数额,同时制定多种变现策略,通过针对特定行业的监管威胁和声誉风险来对受害者施加最大压力。攻击者针对被攻破的系统发布了这些勒索声明,要求受害者以比特币支付 7.5 万美元到 50 万美元不等的赎金。
从以上攻击过程来看 ,这名网络犯罪分子并不是小白而是一名有经验的黑客 ,整个攻击过程是由这位黑客主导 ,AI提供的帮助极大地提升了攻击效率 ,使得这种以往通常需要一个团队花费数月的时间才能完成的规模化攻击 ,一名有经验的黑客靠AI辅助一个月就能完成 ,但攻击行动中依赖的核心技能并没有超出人类专家的水平。
1.2 七阶段攻击链中的AI赋能:效率提升的系统盘点
接下来 ,综合OpenAI、Anthropic和Google三大模型公司今年发布的多份AI滥用监测与遏制报告 ,全面分析AI在网络攻击链(Cyber Kill Chain) 的七个阶段的攻击活动起到什么作用。
(1)侦察( Reconnaissance)
在侦察阶段 ,攻击者利用 AI进行主动扫描、信息收集与目标识别。AI在此阶段主要充当自动化扫描引擎和高效的研究工具。
AI 被用于构建自动化扫描工具 ,例如 ,Anthropic 报告中的 Claude Code 被用于自动扫描数千个 VPN端点 ,构建潜在受害者清单。
AI 功能被广泛用于情报搜集与目标识别 ,包括潜在目标组织、 目标组织的 IT与业务系统及其技术组件 ,以及关键人员画像。例如 ,OpenAI报告LLM的语言理解和生成能力被用于分析组织架构、员工社交媒体信息及技术栈 ,显著降低了社会工程攻击的前期准备成本。
(2)武器化(Weaponization)
在武器化阶段,AI 主要用于攻击载荷(payload)的开发,包括生成功能性恶意代码并辅助改写代码以规避检测,同时AI智能体也被用于辅助漏洞挖掘和利用。
例如,勒索软件开发者利用 Claude 实现了复杂的恶意软件功能,如使用 ChaCha20 流密码的加密算法、利用 RecycledGate 和 FreshyCalls 技术实现直接系统调用绕过 EDR,以及开发反分析和防恢复机制。Google披露APT参与者使用 Gemini 协助编码任务,包括故障排除、工具和脚本开发,以及将现有代码重写或转换为其他语言,如将 Python信息窃取功能转换为 Node.js。
(3)投递( Delivery)
投送阶段是将武器化后的载荷发送给目标。AI 主要通过钓鱼内容生成和本地化来优化社会工程学攻击的有效性。
大模型公司的报告都有提到攻击者利用AI 大模型批量生成高质量钓鱼邮件、即时通讯消息或社交媒体帖子,并根据地域与语言自动调整风格和用词,从而显著提升投递成功率。
(4)利用 ( Exploitation)
利用阶段旨在通过利用目标系统或应用程序的漏洞来获取访问权限。AI 在此阶段充当实时技术顾问和漏洞研究支持。
例如,在“Vibe Hacking”案例中,Claude Code 被用于实时入侵支持,帮助攻击者识别域控和 SQL 服务器等关键系统。在漏洞研究的支持方面, Google 报告显示攻击者利用 Gemini 研究公开报告的漏洞和特定的 CVE,利用 Gemini 尝试逆向EDR 服务器组件以找到可利用的漏洞或躲避检测的手段。
(5)植入( Installation)
植入阶段是为了攻击者能够维持对目标的持续访问,AI 被用于生成和优化持久化脚本与后门安装指导。
例如, Google 报告提到,AI 模型被用来生成自签证书、自动化注册服务或篡改系统策略,以维持持久访问。Anthropic 的案例揭示,AI 甚至会根据系统环境实时调整持久化策略,使检测和清除难度显著上升。
(6)命令与控制(Command & Control)
C2 阶段实现攻击者与被攻陷的系统进行远程通信和控制。AI 在此阶段被用于协助开发复杂的通信协议和操作安全措施。AI 提高了 C2 基础设施的复杂性和隐蔽性。
例如,Google的报告揭示攻击者利用Gemini编写 C2 服务端与客户端通信模块,生成隐蔽的加密通信协议或流量混淆策略。
(7)达成目标(Actions on Objectives)
目标行动阶段是攻击者实现最终目的,例如窃取数据、进行破坏或获取经济利益。AI帮助攻击者最大化行动成果,AI被用来分析窃取的数据、识别高价值信息、甚至自动生成赎金定价策略。
例如,Anthropic 报告显示,Claude Code 可根据受害企业数据量和类型生成“利润计划”及对应的勒索信息。
通过三家大模型公司披露的AI在网络攻击上的滥用行为可以确认 AI 已应用在现实世界的攻击链的各个阶段, 特别是在侦察、武器化和最终执行阶段, 以及投递阶段生成极具欺骗性的钓鱼内容。 同时 ,三家大模型厂商的报告也一致认为 , 目前攻击者使用AI影响更多体现为 “ 效率增强” ,⽽⾮ “ 战术革新” 。换言之 ,AI让已知攻击手法更快、更隐蔽、更大规模地执行 ,但尚未开发出此前人类没有做到的全新的攻击能力。
二、从大模型到安全智能体:攻防能力的系统性增强
2025年被定义为 AI Agent(AI 智能体)元年 ,先进大模型的网络安全能力不断提升 ,安全智能体的研究和开发也在不断深化 ,漏洞是攻击链中最重要的武器 , 自动化渗透攻击可以极大提升攻击效率。接下来我们通过大模型公司的评估报告、前沿的研究、公开的案例来看AI智能体在漏洞发现、 自动化渗透攻击方面的进展。
2.1 先进大模型当前的网络安全能力水平
首先从 OpenAI、Anthropic 和 Google 三大模型厂商的模型系统报告 ,对当前最先进的大模型在网络安全能力的基本水平有一个大致了解。
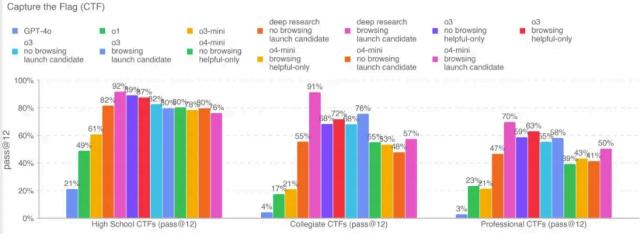
图1 OpenAI GPT o3和o4-mini系统报告中网络安全能力CTF测试结果(难度从左到右分别为初、 中、高级)
(测试集是OpenAI从公开的CTF 挑战中挑选的100多个测试题 ,包括web、rev、pwn、crypto及misc类型)
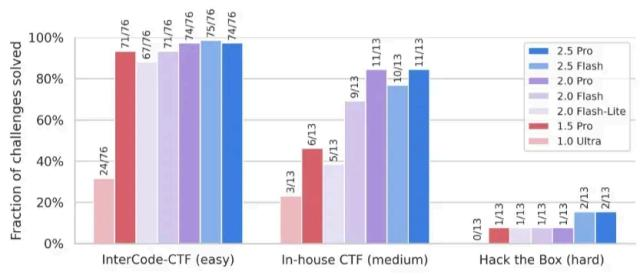
图2 Google Gemini 2.5 Pro 系统报告中网络安全能力评估结果
(测试集构成 InterCode和 Hack the Box 为公开测试集 ,In-house 为Google 自建测试集)
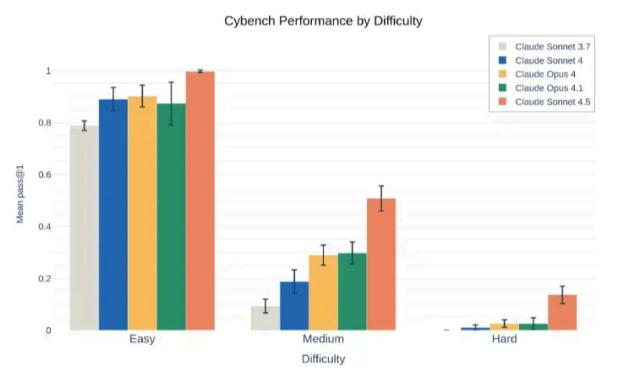
图3 Anthropic Claude Sonnet 4.5 系统报告中网络安全能力评估结果
(测试集使用斯坦福大学发布的Cybench,包括40 个不同难度的CTF 挑战题)
从以上三张图可以看出大模型的网络安全能力进步迅速 ,在简单任务上的解决率都在90%以上已基本趋近饱和 ,但高级挑战题上完成率还不高。说明先进大模型在网络安全基础知识水平已经非常高 ,但需要与现实复杂环境交互的挑战上成功率还较低 ,而这是可以通过智能体工程技术改进提升的。
另外,我们也观察到先进大模型厂商在新版模型服务中加强了安全护栏主动降低网络攻击能力以限制被恶意利用的可能,同时推出专有Gov版本,提供最新能力和较小安全护栏,在安全合规的环境下满足国家安全的需求。
2.2 AI智能体在漏洞发现方面的进展
首先让我们了解近几年CVE 漏洞的增长趋势 ,从图中可以看出从2023 年开始漏洞数量快速增长 ,与大模型的流行和智能提升趋势是基本一致的。
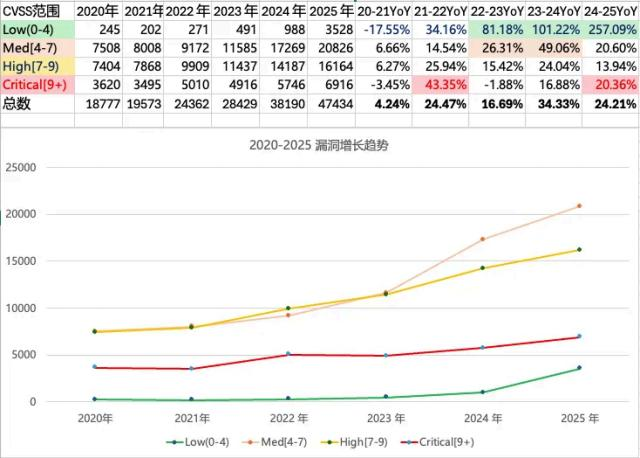
图4 2020-2025漏洞增长趋势 (数据来源 cve.org 注:其中年度是取上一年11月1日至当年11月1日。)
通过 CVE 年度漏洞统计数据分析可以得出:
近 3 年低危漏洞(CVSS 得分<4分) 的数量大幅增加 ,故推测LLM降低了低危漏洞发现的门槛 ,并较大程度提升了低危漏洞的发现效率。
9 分以上的严重漏洞也有明显的增长趋势( 同期中、高危的增长趋势则有所放缓),故推测LLM成为高水平的安全研究人员的有力助手 ,使得漏洞挖掘的效率也得到提升 。
这两个推测从全球著名的众测平台HackerOne近3年的排行榜数据也可以得到交叉验证,
该平台今年的个人总得分第一名为 30740分(注:为方便做年度比较 ,取截至11月5日的数据 23646*1.3) 与2024 年个人总得分第一30716分及 2023 年第一 31072 分相差无几 ,但个人高危漏洞得分排名第一名得分有较大幅度的提升 ,从 2023 年的 3333 分到 2024 年的 6663 分再到今年的
8672(注:为方便做年度比较 ,取截至11月5日的数据 6671*1.3)。同时号称 AI 原生的进攻安全公司 XBOW在团体排名中今年更是表现突出 ,无论是总得分(9035对比第二名764) ,还是高危漏洞得分 (1343对比第二名392)。注:前面2组数据为2025年1月1日-11月5日的数据。
2.2.1 AI 智能体在已知漏洞的利用水平
2025年9月底发布的Claude Sonnet 4.5系统报告中展⽰了Claude 系列模型在 CyberGym框架下的评估结果 ,CyberGym是加州大学伯克利分校研究人员今年6月发布的一个漏洞利用测试框架 ,该框架包含188个软件项目的1507个真实安全漏洞(主要为C/C++项目中的安全漏洞 ,尤其是与内存安全相关的问题)。测试时AI智能体会收到漏洞描述和未修补的代码库 ,根据AI智能体通过生成PoC重现目标漏洞的能力进行评估。
测试结果显⽰ ,Claude Sonnet 4.5在30轮测试的成功率达到 66.7% ,比七个月前的Claude Sonnet 3.7的47.2% ,成功率提升了近20% ,提升比例41.3% ,而一轮测试的成功率比例更是提升了近一倍(从 14.5%到28.9%)。
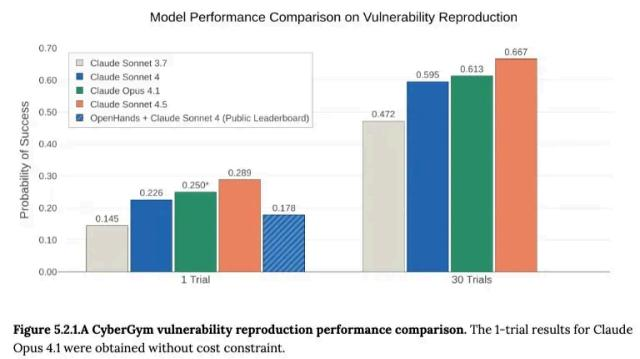
图5 Claude系列模型在CyberGym框架下的漏洞复现成功率评估结果(来源:Claude Sonnet 4.5 System Card)
另一个评估是2025年9月美国NIST下属CAISI对几个前沿大模型进行的网络安全能力测试 ,其中一项是评估真实漏洞利用的CVE-Bench ,它是美国伊利诺伊大学研究人员开发的一个用于评估大模型的真实Web漏洞利用能力的测试集 ,CAISI评估时选取了其中的15个任务,给模型的每个任务都附有明确的攻击目标描述及从NVD(美国国家漏洞库)中提取的公开漏洞信息 ,测试结果显⽰ ,表现最好的模型的成功率可以达到65%以上。
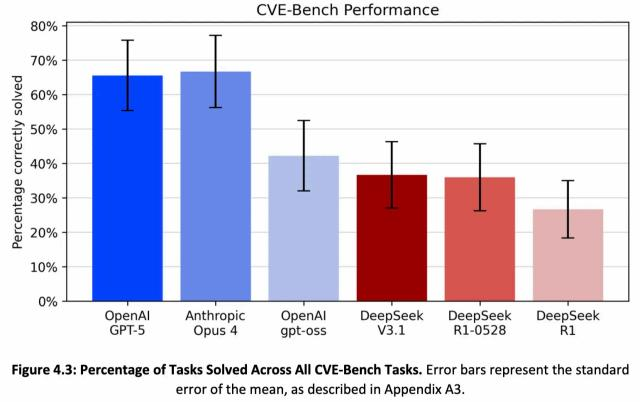
图6 前沿大模型在CVE-Bench上的漏洞利用成功率结果(来源:NIST CAISI评估报告)
从上述两项评估来看 , 目前AI智能体搭配最先进的LLM ,只需给定公开的漏洞信息和攻击目标描述 ,在特定类型的已知漏洞利用的成功率已经达到65%以上的水平。
2.2.2 AI 智能体在新漏洞挖掘的水平
漏洞挖掘一直是攻击链中武器化的一项非常重要的核心工作。 目前漏洞研究人员在现实中已经普遍使用 AI辅助进行漏洞挖掘 ,并开始尝试智能体技术实现端到端的自动化漏洞挖掘。
有源代码库的漏洞发现 ,从现实世界中发布的产品和比赛结果来看,AI 目前已有较好表现 ,且已经有端到端的自动化漏洞发现和验证的产品发布。
Big Sleep(前身是 NapTime)是由Google人工智能研究团队DeepMind 和 Google安全漏洞研究团队Project Zero共同开发的AI漏洞研究智能体 ,它用于帮助安全研究人员加速发现软件的安全漏洞。 自2024 年推出以来 ,它已持续在广泛使用的软件中发现了多个0day漏洞 ,包括2024年11 月Google披露NapTime首次协助发现一个SQLite的严重安全漏洞,2025年8月Google宣布Big Sleep自主发现了开源代码库中的20个安全漏洞 ,涉及FFmpeg 和 ImageMagick 等广泛使用的开源软件。
OpenAI在今年10月底预发布了一款自主式漏洞发现与修复智能体Aardvark ,它持续分析源代码库 ,以识别漏洞、评估可利用性、确定严重程度优先级 ,并提出针对性的补丁。在对 “ 黄金” 代码库的基准测试中 ,Aardvark识别出了92%的已知和人工合成的漏洞 ,展⽰了高召回率和现实世界中的有效性。
2025年8 月 , 由美国国防部高级研究计划局( DARPA) 与美国卫生高级研究计划局(ARPA-H) 和前沿实验室合作举办的首届人工智能网络挑战赛(AIxCC)的决赛环节 ,参赛队伍需在包含了70个合成漏洞的5400万行代码(23 个开源代码库) 中找出漏洞并生成对应的补丁 ,且有时间(每个挑战8小时)、AI调用花费和计算资源的限定条件 ,最终七支进入决赛的队伍通过他们开发的利用LLM能力的网络安全推理系统(CRS) ,共发现了54个合成漏洞(并成功生成了43 个补丁)和18个新漏洞。如此大规模的代码量在有限的几个小时内找到这些漏洞并生成对应补丁 ,没有AI的帮助靠人力根本无法达成。
没有源代码的漏洞发现 ,目前仍是安全研究人员主导,AI还主要是辅助执行局部任务。在没有源码的黑盒情况下 ,前沿的研究结果表明 , LLM可以在局部任务中帮助提升效率,如逆向分析与LLM的结合可以有效提升二进制程序模糊测试的漏洞识别效率 ,但端到端的漏洞发现和验证还处于研究早期。
HackTheBox 2025年全球网络技能基准报告(The Global Cyber Skills Benchmark 2025)中说明 ,"在本次比赛中 ,近一半(44%) 的参赛队伍表⽰他们在比赛过程中使用了人工智能工具 ,但只有7.5%的队伍认为这些工具对解决挑战问题起到了关键作用 ” 。
2025年6月 ,专注于AI进攻性安全的初创公司XBOW在媒体上发表的营销文章中宣称 “ 在3个多月内提交了超过 1000 个新漏洞 ,XBOW与数千名人类研究人员一起竞争 ,在美国漏洞平台 HackerOne排名中攀升至榜首 ” 。从 HackerOne官网 2025 年截至11月5日的排名中 ,XBOW的总得分9035和严重漏洞的得分1343均在团体组织中排第一 ,而个人白帽子排名第一的M0chan总得分为23646 ,个人严重漏洞的得分为6671。XBOW的总得分放在前100 名个人白帽子中排在第11 名 ,XBOW的严重漏洞得分放在个人白帽子中排在第7位。从与个人白帽子的得分数据对比可以看出 ,使用AI自动化技术的XBOW公司在漏洞挖掘离最高水平的白帽子还有一些差距。
利用LLM进行新漏洞挖掘生成已经较为普遍 ,并成为安全研究人员的效率和能力倍增器。实现端到端的漏洞挖掘的AI智能体 ,在开源代码库的安全漏洞发现中已经有现实应用和早期产品发布 ,但在无源码的漏洞发现 , 目前主要还是安全研究人员主导 ,LLM 和智能体仅能执行局部工作帮助提升效率。在可预见的未来 ,人工智能工具与人类专家之间在漏洞挖掘工作的持续合作可能仍将是标准做法。
2.3 AI智能体在自动化渗透攻击方面的进展
首先看最近在现实世界发生的黑客利用AI驱动的渗透工具加速漏洞利用的一个案例。Github中已经出现多个开源的AI驱动的渗透测试框架 ,2025年8月底发布的Hexstrike-AI就是其中之一 ,该框架包含 150 多种安全工具和12 多个自主 AI智能体 ,它将专业安全工具与自主AI智能体相结合 , 自动执行从扫描、漏洞利用 、持久化到渗透的完整流程 ,为安全红队提供自动化渗透和全面的安全测试能力。
2025年9月2日Check Point安全厂商发布的技术博客揭露该工具已被黑客滥用于Citrix的NetScaler ADC和Gateway的漏洞利用 ,利用这些漏洞并非易事 ,攻击者必须了解内存操作、身份验证绕过以及 NetScaler 架构的特性 ,这类工作以前通常需要高级安全研究员花数周的时间研究并开发利用代码。而黑客利用Hexstrike-AI ,在上述漏洞披露后的12 小时内暗网上就出现了讨论如何使用 Hexstrike-AI扫描并利用存在漏洞的NetScaler设备。现在 ,有了这款 AI驱动的渗透工具帮助 ,黑客无需费力地进行手动开发 ,就可以自动侦察、协助漏洞利用 ,并促进这些关键漏洞的有效载荷投递。大幅缩短了从漏洞披露到大规模利用的时间 ,从原本可能需要数天或数周才能开发的利用 ,缩短到数小时乃至数分钟。
再来看前沿研究的情况 ,最近2 年已经有数十个实验性研究探究基于 LLM 的智能体技术在现实环境下的网络安全攻击能力 ,从 CTF 挑战题 ,到网络靶场 ,到更真实的部署了安全防护的复杂网络环境。
2025年5月美国纽约大学发表的一个研究项目的结果表明 ,他们开发的CRAKEN安全智能体至今在NYU CTF Bench排行榜上位居第一 ,在搭配 Claude-3.5-Sonnet时 ,CRAKEN得分最高为22% ,另2个早期开发的安全智能体D-CIPHER为19%(测试日期2025年2月) ,EnIGMA为13.5%(测试日期2024年9月)。
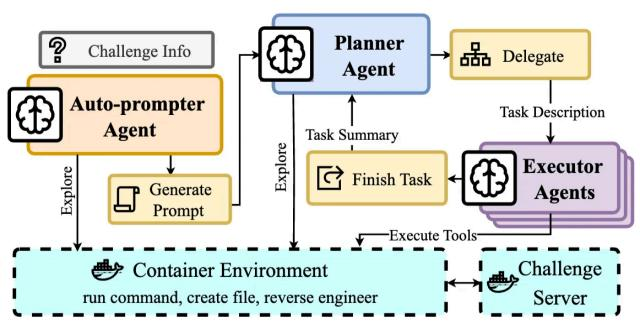
图7 D-CIPHER的多智能体技术架构
2025年10月上海人工智能实验室、上海交通大学和和中科院信工所的研究人员发布的研究结果表明,他们开发的支持可执行多阶段侦察、漏洞分析和利用的安全智能体PaceAgent ,测试使用的 PaceBench评估基准基于 17 个具有代表性的 Web 漏洞及其组合 ,构建了 4 种模拟环境(A 为单主机单个漏洞 ,B 为多主机混合漏洞 ,C 为有漏洞的多主机构成的攻击链 ,D加了WAF安全防护) 。
配置不同的LLM 平均得分情况如下:Claude-3.7-Sonnet最高24.1% ,Qwen3-32B得分2.4% ,DeepSeek-V3得分1.2% ,DeepSeek-R1 可能是触发了安全护栏导致成功率为 0。而且,所有模型在有安全防护的D场景下全部失败。在同样的基准和配置Claude-3.7-Sonnet情况下 ,今年年初开源的CAI安全智能体得分为13% ,PaceAgent比CAI 的效果有较大幅度提升。
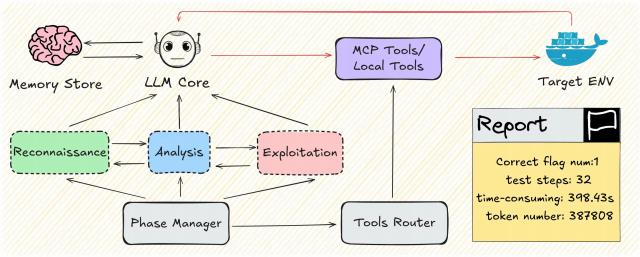
图8 PaceAgent的技术架构图
从以上案例和前沿研究的实验结果来看,基于 LLM 的开源自动化渗透框架可以帮助有经验的黑客提升漏洞利用效率,但在模拟现实网络环境的自动化渗透攻击中,端到端的AI 智能体工具成功率都还不到25%,特别是有安全防护的环境中自主式AI智能体还很难成功,主要障碍包括:模型通常达成单一目标后就会停止、潜在其它目标分散了注意力、工具利用不正确或无对应的工具使用时没有生成正确的工具、在没有相关知识提示的情况下推理和探索不足等。
随着LLM及智能体工程实践的进一步发展 ,从前沿研究的对比实验结果可以看出成功率在逐步提升。这些研究给出了安全智能体提升成功率的共性工程方法:使用规划者和执行者的多智能体协同架构 ,规划智能体使用具有较大上下文窗口Tokens的推理模型 ,通过上下文工程技巧提升LLM的长时推理能力 ,为安全任务提供针对性的专业指导知识 ,为特定任务构建专门的工具等。
2.4 利用 LLM 能力的新型攻击方式已经浮现最近几个月,安全界捕获到多起在落地样本中调用LLM能力的攻击案例,它们的共同特点是攻击者投递到被攻陷终端或主机的程序中不直接写入恶意代码,而是通过带有意图描述的自然语言文本调用LLM 服务在程序运行时生成恶意代码。
这类攻击示例包括 CERT-UA 披露的 APT28-LAMEHUG、利用本地 AI CLI 的 Nx Build 供应链事件、以及 PromptLocker/Ransomware 3.0 等研究与样本(并被 GTIG 列入新型威胁追踪)。
下面逐个介绍该攻击范式的技术特征、对防御的冲击与潜在影响。
2025年7月乌克兰计算机应急响应中心(CERT-UA)披露首个集成LLM能力的恶意程序APT28- LAMEHUG ,它在代码中使用自然语言调用HuggingFace上的Qwen大模型云服务生成系统命令 ,以窃取终端用户的信息。
2025年8月Nx Build软件供应链攻击s1ngularity中 ,植入主机的攻击程序利用终端本地AI CLI工具(包括Claude,Gemini和Amazon q)调用大模型服务生成代码和调用攻击 ,以实现侦察和数据窃取 ,这种调用本地 AI CLI工具的方式更加隐蔽 ,这是已知的第一个攻击者将开发人员AI助手变成供应链利用工具的案例。
2025年8月安全公司ESET报告发现了首个AI驱动的勒索软件PromptLocker ,它利用OpenAI开源的GPT-OSS-20B模型生成恶意Lua脚本 ,生成的Lua脚本能够基于文件类型和内容决定哪些文件需要搜索、复制、加密或销毁。但随后纽约大学(NYU)的研究人员声称这个样本源自他们的一个利用LLM的"勒索软件(Ransomware) 3.0” 实验研究项目 ,该样本被上传到VirusTotal(一个公开的恶意样本分析平台) 后被ESET研究人员关注到。
2025年8月纽约大学的研究人员进行的一个研究项目 "勒索软件(Ransomware) 3.0” ,该项目研究在投递到受害终端的代码不直接包含攻击代码 ,而是利用OpenAI开源的GPT-OSS模型来协调攻击链的各个阶段 ,包括实时生成和部署针对特定目标的恶意代码 ,同时能够根据执行环境进行自我调整 ,并制定个性化的勒索要求。研究结果表明 ,开源的LLM确实能够生成具备实际攻击能力的勒索软件组件 ,并在多种环境中持续执行攻击行为。
在本文编写期间 ,11月6日Google威胁情报团队(GTIG)在最新的威胁追踪报告中对这种新型恶意软件也进行了预警 ,"GTIG 首次识别出在执行过程中使用LLM的恶意软件系列 ,如PROMPTFLUX 和 PROMPTSTEAL。这些工具动态生成恶意脚本 ,混淆自己的代码以逃避检测 ,并利用LLM按需创建恶意功能 ,而不是将其硬编码到恶意软件中。虽然目前尚处于萌芽阶段 ,但这代表着朝着更加自主和自适应的恶意软件迈出了重要一步。 "
"勒索软件(Ransomware) 3.0” 项目等案例犹如打开了一个潘多拉盒子 ,随着端侧模型的采用和AI智能体的进一步发展 ,在攻击过程使用AI多智能体协同 ,受黑客控制的主智能体负责总体指挥和编排 ,分散在不同网络或终端上的子智能体收到分配的攻击子目标后 ,根据所在环境进行灵活的自主行动并将执行结果汇报给主智能体实时调整策略 ,以达成最终目的。这犹如组织中进入了一个超级智能间谍 ,将会给未来的网络攻击带来深刻的影响。
三、思考与应对建议
总体来看,人工智能更多地是帮助攻击方降低技术门槛,提升效率和规模化,使攻击更具欺骗性和隐蔽性,尚未开发出此前人类没有做到的全新的攻击能力,还没有达到顶级人类专家的水平,也没有彻底击碎现有的纵深防御体系。
然而人工智能在网络攻防中的快速渗透,使得攻击与防御之间原本存在的三个根本性不对等被进一步放大,导致“攻击方更快受益、防御方短期难以对等提升”,从而在短期内人工智能赋能攻防两方的天平会倾向于攻击方。
3.1 AI 赋能放大攻防原有不对称
(1)失败成本不对称:攻击方一次成功即可,而防御方必须零失误。攻击方可以失败很多次而只需一次成功就可得手,而防御方必须抵御所有攻击而且较低的容错空间严重限制了防御策略。AI 让攻击者能够以几乎零成本、无限次数地反复尝试, 攻击方即使在 AI 的成功率还不是很高时就可以积极利用,而防守方在使用AI驱动的威胁检测与响应时,误报和漏报都会带来损失——误报误拦会干扰安全运营,而一次漏报和响应不及时就可能危及整个系统。
(2)修复节奏与资源不对称:攻击利用速度 AI 化,而企业修复速度依旧“人类节奏”。即使有已知的修复方案,防御方的修复工作通常也十分缓慢且耗费资源,需要进行大量测试、解决依赖问题、逐步推进全量部署以及部署后的验证——所有这些都需要大量的资源和时间。相比之下,AI 技术显著缩短了漏洞利用时间,使得“从漏洞公开到大规模利用”已从过去的数周压缩到“小时级甚至分钟级”。攻击者只需极少的资源就能利用漏洞发现与完成补丁部署之间的时间差进行攻击。
(3)对可靠性要求的不对称:防御方追求可靠性和全面保护,攻击方则以规模和影响为优化目标。人工智能降低了攻击方的技术门槛—减少了对高深专业知识、特定目标知识或精确执行的需求。即使对一个目标系统的攻击失败 ,攻击方仍可能在许多其他系统上取得成功。而防御方因为对人工智能目前在准确性和稳健性方面的顾虑 ,在安全关键环境中不愿完全信任和部署这些技术。
这种不对称的放大趋势,在今年多家网络安全公司的威胁趋势报告中都有明确提到,包括网络侦察活动正在急剧增加,暴露在网络上的设备与服务可以很快被发现,针对暴露服务的攻击尝试次数在大幅上升,从发现漏洞到入侵突破的时间窗口也在不断缩短。
这种趋势对仍停留在被动响应阶段、缺乏主动暴露面监测与攻击测试能力的组织带来了更大的压力。无论是安全防御基础薄弱的中小企业,还是资产与应用规模庞大、漏洞检测与补丁修复流程复杂的大型企业,都将面临显著的防御挑战。
3.2 趋势判断与应对建议
为了应对这种不对称,目前摆在防御方的策略已经基本明晰:防御方在评估本企业的安全防护水平、夯实基础并巩固现有纵深防御措施和有效性的前提下,在AI提升攻击方的地方,防御方要么彻底堵住风险敞口,要么对等地使用AI提升效率,并增强主动防御能力。
以下列举几点建议措施:
AI驱动的主动安全测试:使用AI智能体对代码库进行漏洞检测和补丁生成 ,减少应用发布的漏洞数量并提高漏洞的发现效率。
AI智能体驱动的自动化渗透测试: 在真实环境下模拟攻击行为,将原来的测试周期缩短 ,以更快地发现漏洞利用的可能。
AI增强的威胁检测: 实时整合多源情报 ,将基于人工智能的检测与传统的基于规则的系统相结合 ,能够在稳健性、容错性和可扩展性之间取得平衡。
AI驱动的资产与漏洞管理:在攻击面的资产与漏洞管理方面 ,使用AI智能体分析漏洞的可利用性出修复优先级 ,并加速修复的自动化过程。
AI驱动的安全运营:在威胁告警研判、调查和响应方面 ,使用AI智能体降噪减少基础安全运营工作量 ,优化检测规则并加速调查和响应过程。
AI模型监测与管控:监测和管理终端和主机的AI模型部署和AI服务调用情况 ,阻断模型被恶意程序利用的新型风险。
目前,AI 显著降低攻击门槛,扩大攻击规模,AI利用扩大了攻防两端的不平衡,但随着防御方利用先进技术构建起新的防御工事,并在发现、检测与响应效率上达到攻击方的对等水平,这种不平衡将会逐渐向有利于防御方的方向转变。
参考
OpenAI, Disrupting malicious uses of AI: an update, 2025/10/7
Anthropic, Threat Intelligence Report: August 2025, 2025/8/2
Google TIG, Adversarial Misuse of Generative AI, 2025/1/30
OpenAI, GPT-5 System Card, 2025/8/13
Anthropic, System Card: Claude Sonnet 4.5, 2025/10/10
Google, Gemini 2.5 Pro Model Card, 2025/6/27
Google DeepMind, A Framework for Evaluating Emerging Cyberattack Capabilities of AI, arXiv:2503.11917v3, 2025/4/21
HackerOne, https://hackerone.com/leaderboard
Hack The Box, The Global Cyber Skills Benchmark 2025
Google Project Zero, From Naptime to Big Sleep: Using Large Language Models To Catch Vulnerabilities In Real-World Code, 2024/11/1
DARPA, AI Cyber Challenge marks pivotal inflection point for cyber defense, 2025/8 XBOW, XBOW on HackerOne: What’s Next, 2025/8/18
TheHackerNews,CERT-UA Discovers LAMEHUG Malware Using LLM for Phishing Campaign , 2025/7
ESET, ESET discovers PromptLock, the first AI-powered ransomware , 2025/8
SecurityWeek, Hackers Target Popular Nx Build System in First AI-Weaponized Supply Chain Attack , 2025/8
TomsHardware, AI-powered PromptLocker ransomware is just an NYU research project, 2025/9
CheckPoint, Hexstrike-AI: When LLMs Meet Zero-Day Exploitation, 2025/9/2
Frontier AI" s Impact on the Cybersecurity Landscape, arXiv:2504.05408v3, 2025/10/11
CRAKEN: Cybersecurity LLM Agent with Knowledge-Based Execution, arXiv:2505.17107v1, 2025/5/21
Ransomware 3.0: Self-Composing and LLM-Orchestrated, arXiv:2508.20444v1, 2025/8/28
PACEbench: A Framework for Evaluating Practical AI Cyber-Exploitation Capabilities,
arXiv:2510.11688v1, 2025/10/13
Google Threat Intelligence Group, GTIG AI Threat Tracker: Advances in Threat Actor Usage of AI Tools, 2025/11/06
关 于 作 者
江爱军, 奇安信集团产品总体部AI专家
声明:本文来自虎符智库,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
