随着大模型能力持续增强,人工智能应用正由高度依赖云端算力,逐步向端侧优先、端云协同的架构演进。端侧模型在降低服务延迟、强化隐私保护、缓释数据与算法合规风险等方面,正成为智能终端、自动驾驶、智慧医疗的重要技术路径。
但与此同时,端侧模型并非合规避风港,正所谓“端侧不是法外之地”。端侧模型在设备权限调用、应用互操作、本地数据回流云端、系统更新、政府备案等环节,仍面临个人信息保护、网络安全与不正当竞争等多重合规挑战。
本文中,结合现行法律法规、监管执法政策及行业实践,汇业黄春林律师团队简要分析端侧模型部署与应用中的主要法律实务问题,仅供参考。
一、端测模型的基本法律特征
1. 什么是端侧模型
参考《移动智能终端端侧大模型安全实施指南》等,能够在移动设备、智能家具、医疗设备、家用汽车等智能终端OS上本地进行部署、运算和推理的一种“小模型”。常见的端侧模型应用场景包括谷歌翻译、苹果SIRI、Gemini Nano、小艺AI助手、豆包手机助手、玩具机器人、智慧医疗设备,甚至包括特斯拉的FSD,以及大多数智能手机上的语音识别、智能修图,等等。
值得注意的是,从技术角度,端侧模型并不是直接把云端的大模型(如Gemini3、GPT5等)原封不动搬进智能终端,而是经过了专业瘦身与重塑技术,例如蒸馏、量化等。通常来说,一般的端侧模型的参数为十亿(1B)左右,而大模型的参数为千亿(100B)以上。
2. 端侧模型的常见部署方式
侧模型的部署方式通常包括三种方式:纯端侧模型,端/云混合模型(《端云协同人工智能服务用户数据保护要求》称为端云协同架构),甚至还有端/边/云混合模型。
除了医疗、汽车等特殊监管行业,完全没有云端接入的纯端侧模型相对较少,一般都是局部功能使用的端侧模型能力。本文为讨论方便,未特别说明的情况下,端侧模型指纯端侧模型部署在移动智能设备的情形。
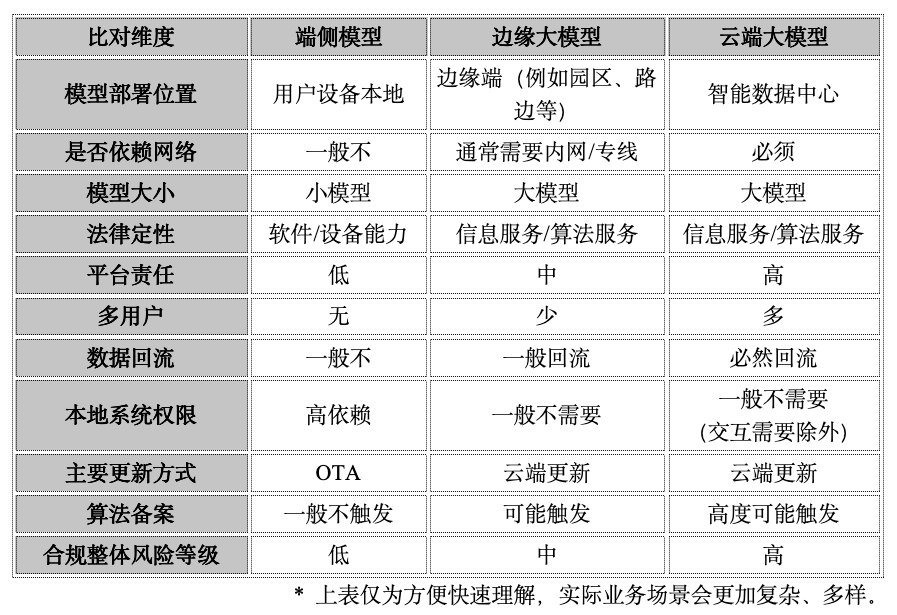
3. 端侧模型与云端大模型、边缘大模型的主要法律区别
二、端侧模型的本地权限调用合规
1.设备权限调用合规
端侧模型对设备系统权限的调用,对用户设备安全、隐私保护及财产安全影响重大,因此应重点确保相关调用行为符合以下合规要求:
首先,应严格遵循《个人信息保护法》《网络安全法》及《个人信息安全规范》等规定的最小必要、按需申请与知情同意等原则。端侧模型应在权限弹窗、隐私政策中对权限用途、调用频率及影响范围进行清晰、具体告知,实际使用应当与告知内容一致。
其次,应根据《App收集个人信息基本要求》《App个人信息安全测评规范》及《APP用户权益保护测评规范 第4部分 权限索取行为》等技术规范全面评估权限获取、使用及共享的合规性。例如,使用拨打电话、发送消息、摄像、录音、截屏等操作权限的,应当由用户主动触发和确认;使用录音、录像及位置等持续性权限的,还应当通过状态栏等方式持续提示用户权限的开启状态;申请使用设备管理器、辅助功能、监听通知栏等权限,应向用户详细说明申请的目的、使用的方式并获得用户单独同意;相关权限提供给第三方SDK、Agent使用的,应依法告知并经用户明示同意。
再次,还应遵守硬件设备及操作系统服务商的权限管理规则、开发者协议与审核政策等。
2.应用权限获取合规
在端侧模型场景下,端侧模型通过系统能力(例如INJECT_EVENTS权限)或接口机制调取第三方App的功能、数据或操作权限,实质上可能影响用户对自身数据及行为的控制权,亦可能重塑不同应用之间的竞争边界,应从包括但不限于如下角度全面评估:
首先,应充分保障用户的自主决定权,克制放大端侧模型的意图理解能力。端侧模型在触发第三方App 操作前,应确保用户具有清晰、可理解、可撤回的选择权。特别是在支付、转账、下单、签约等金融与交易类敏感操作场景中,不得通过默认执行、自动跳转、批量确认等方式弱化用户的确认环节,避免形成“技术代替意思表示”的合规风险。
其次,应遵守开放合作、公平竞争的原则。从《反不正当竞争法》等视角,端侧模型不得通过技术手段擅自调用、模拟或替代其他App 的核心功能,不得干扰其正常运行或用户选择路径。黄春林律师团队建议,优先使用接口调用的“合作模式”(例如Gemini Nano与WhatsApp、Line 和 KakaoTalk等的合作模式),而不是视觉识别的“暴力方案”;建议参照《移动互联网服务可访问性安全要求》的实践,端侧模型在进行用户意图识别、通过第三方 App 执行各类任务时,应遵循“双重授权”规范——APP授权和用户授权;建议在设计互操作机制时,应以开放、透明、可控为边界,并在用户协议中明确局限性、责任划分等内容。
三、端侧模型的本地数据回流合规
端侧模型虽以本地算力推理、本地数据处理为主要特征,但在实际运行中,仍可能基于安全、优化或同步等特定目的,将部分数据回流至云端。该类数据回流至云端的行为,一旦涉及个人信息,即应被视为中国法律意义上的个人信息处理活动,需符合合法性、必要性与知情同意等合规要求。
(一)模型安全数据回流合规
以安全监测、异常检测、漏洞分析为目的的数据回流,应严格限定于保障模型安全所必需的最小数据范围,通常应当限于不包含用户回话内容和直接识别信息(例如手机号)的日志、特征、事件或状态类信息。例如,根据《网络安全技术生成式人工智能服务安全基本要求》等规定,端侧模型“收集并留存安全日志,并支持设备联网时上传日志”。
依据《个人信息保护法》《个人信息安全规范》等,该类回流行为应在隐私政策中明确说明处理目的、处理范围及保存期限等,并避免以系统安全为由进行泛化告知和概括授权。
即便是具有系统安全之必要性,仍应尽量回流去标识化、匿名化处理后的数据,避免直接回传原始内容或明文个人信息。此外,还应当根据《端云协同人工智能服务用户数据保护要求》等规定,在端侧留存相关操作日志并提供相关操作的使用记录,确保端侧模型的安全可审计与可追责性。
(二)模型优化数据回流合规
根据《信息安全技术移动互联网应用程序 收集个人信息基本要求》等规定,训练、调优或评估模型仅为“实现改善服务质量”“研发新产品”等目的的业务功能,属于扩展业务功能。扩展业务功能不宜以默认开启方式收集用户使用数据,应由用户自主选择开启,并提供便捷的关闭、拒绝功能。
此外,根据《端云协同人工智能服务用户数据保护要求》等规定,应对数据在端侧进行脱敏或加密处理后再进行回传;在进行模型训练过程中,应采取用户个人信息保护措施,满足《生成式人工智能服务管理暂行办法》《网络安全技术生成式人工智能预训练和优化训练数据安全规范》和T/TAF 268.4等要求。
特殊场景下模型优化数据回流,还需满足相应的监管要求。例如,根据《人工智能拟人化互动服务管理暂行办法(征求意见稿)》规定,除法律、行政法规另有规定或者取得用户单独同意外,提供者不得将用户交互数据、用户敏感个人信息用于模型训练。
(三)用户数据同步回流合规
为实现多设备协同、配置同步或历史记录保存而进行的用户数据同步回流,应以用户主动选择为前提,并清晰区分“本地使用”与“云端同步”两种模式。同步范围、同步频率及存储位置应向用户充分告知,并提供随时关闭或删除的机制。若同步数据涉及敏感个人信息或跨境存储,或者用于模型优化的,还需进一步评估是否触发其他合规义务。
此外,根据《端云协同人工智能服务用户数据保护要求》等规定,应使用安全可靠的传输协议(如HTTPS等),防止数据在传输过程中被篡改、窃取或恶意攻击,确保数据的完整性和机密性。涉及同一账号体系下的跨终端、系统及渠道互通和互操作的,还建议符合《移动互联网服务账号互通和互操作保护要求》等要求。
黄春林律师团队注意到,在车联网、医疗及金融场景下,部分业务数据(例如测绘数据)的云端处理会触发特殊资质,因此应当慎重提供该等数据的云端回流服务。
四、端侧模型的系统更新合规
1.关于安全策略更新合规
安全策略更新(例如漏洞修复、加密协议升级、恶意攻击拦截规则和关键词过滤升级等),聚焦模型的安全防护能力优化,包括漏洞修复、加密协议升级、恶意攻击拦截规则更新等,是保障模型全生命周期安全的技术要求,也是法律规定的基本合规义务。
例如,根据《生成式人工智能服务管理暂行办法》等规定,“提供者应当在其服务过程中,提供安全、稳定、持续的服务,保障用户正常使用。”此外,根据《网络安全技术生成式人工智能服务安全基本要求》《端云协同人工智能服务用户数据保护要求》等规定,端侧模型应发现模型安全漏洞时,应及时对安全漏洞进行修复,例如推送安全补丁到端侧等。因此,端侧模型推送安全策略更新的,主要是基于履行法定义务,并非基于用户的同意。
但是,相关安全漏洞的报告及通知义务,还应当遵守《网络安全法》、《网络产品安全漏洞管理规定》等规定。
2.关于局部热更新合规
局部参数及局部算法更新(如优化语音识别准确率的模型参数调整、完善语义理解的局部算法优化)是端侧模型性能迭代的核心,特点是仅传输增量数据、本地融合迭代,无需替换全量模型或模型相关的应用,通常采用热更新模式。
根据《移动应用程序(APP)热更新框架安全服务规范》等规定,热更新指通过动态下发并加载代码、资源等,在App不重新下载和安装的情况下,实现代码逻辑及资源文件实时更新的技术。根据该服务规范要求,应通过数字签名等方式对热更新内容来源进行校验,确保热更新发起方身份的真实性;宜通过安全传输协议(如TLS 1.3)实现热更新数据传输过程中的安全性;对影响用户权益的热更新,需在更新后提供简要说明,保障用户知情权;热更新要能确保服务回滚能力及事件溯源能力;车联网等特殊行业的热更新,还应当符合行业监管要求;等等。
3.关于端侧模型升级合规
端侧模型版本升级,适用于模型架构调整、核心算法重构、功能重大升级等场景(例如从3.0 版本迭代至 4.0 版本,新增多模态交互功能,等),特点是更新体量大、影响范围广,主要合规要点包括:
(1)升级告知同意:必须获得用户明示同意,禁止默认勾选或捆绑升级;在同意界面明确展示更新内容、更新包大小、所需权限变更、数据处理规则变化等。
(2)旧版本支持期限告知:提前告知用户旧版本的停止维护时间,在停止维护前仍持续需提供安全漏洞修复服务。
五、端侧模型的大模型备案合规
《互联网信息服务算法推荐管理规定》《互联网信息服务深度合成管理规定》两个规定的前提都是“互联网信息服务”,纯端侧部署的模型,不符合该构成要件。反之,采取端/云混合架构的模型,需要符合前述两个规定项下的所有合规义务,包括但不限于算法备案。
但是,黄春林律师团队注意到,《生成式人工智能服务管理暂行办法》并不以“互联网信息服务”为前提,根据该办法第二条规定,只要利用生成式人工智能技术(法律上并未区别端侧还是云端部署)向境内公众提供生成文本、图片、音频、视频等内容的服务的,均适用该办法并应遵守相应的合规义务,包括安全评估及大模型备案。
同时,我们也注意到,实践中的端侧大模型的具体功能形态存在明显差异。就目前常见端侧模型场景而言,可大致区分为以下两类:
(1)第一类为效率工具型端侧模型,如AI 翻译、AI 抠图、AI语音及图片识别等,其核心特征在于仅对用户输入内容进行辅助处理与转换,输出结果与原始输入内容具有高度对应性和忠实度,即用户输入 “X” ,端侧模型生成 “X1”,新合成生成的能力比较有限,导致公众误导混淆的可能性较低。同时,由于内容生成在端侧,此类端侧模型往往也无完善的账号体系及云端同步能力,因此舆论影响力也比较有限。
(2)第二类为AIGC 服务型端侧模型,通常具备办公文档生成、多媒体生成、对话交互等能力,可能实现跨模态或跨语义理解与生成,输出结果与原始输入内容具有一定的泛化能力,即用户输入“X” ,端侧模型生成 “Y”, 此类端侧模型往往也建立了完善的账号体系及云端同步能力,因此具有更强的内容生成属性及潜在的舆论影响力。
基于上述区分,经参考行业实践及监管执法案例,我们认为:第一类效率工具型端侧模型,不申报大模型备案/登记的法律风险相对较小;而第二类AIGC 服务型端侧模型,则应当根据《生成式人工智能服务管理暂行办法》等规定,全面履行大模型备案/登记等合规义务。当然,前述判断仅供参考,具体端侧模型仍需结合实际功能设计、服务对象、服务方式及监管执法口径等进行个案判断。

声明:本文来自网数与人工智能法律实务,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
