
原文标题:Evaluating LLM-based Personal Information Extraction and Countermeasures
原文作者:Yupei Liu, Yuqi Jia, Jinyuan Jia, Neil Zhenqiang Gong发表会议:USENIX Security Symposium 2025笔记作者:龙函城@安全学术圈主编:黄诚@安全学术圈
研究概述
随着大语言模型(LLM,如 GPT 系列、PaLM / Gemini 等)能力与可获取性的不断增强,攻击者即使不具备复杂的自然语言处理工程背景,也可以批量地从公开个人主页、简历或介绍页面中抽取敏感个人信息(PIE, Personal Information Extraction),并进一步用于鱼叉式钓鱼、诈骗等二次攻击。
论文指出,传统的个人信息抽取方法(如正则表达式、关键词匹配、命名实体识别等)由于对网页文本语义理解能力有限,在真实个人主页场景下往往表现不佳;而 LLM 所具备的强语义理解与上下文推理能力,可能显著提升个人信息抽取的成功率,从而带来新的隐私与安全风险。
为系统化衡量这一威胁,论文提出并评估了一个 LLM-PIE 攻击框架,如图1所示。其基本流程为:攻击者收集公开的个人 profile(如个人网站 HTML 源码),并构造特定 prompt 向 LLM 查询,从而获取被自动抽取的个人信息。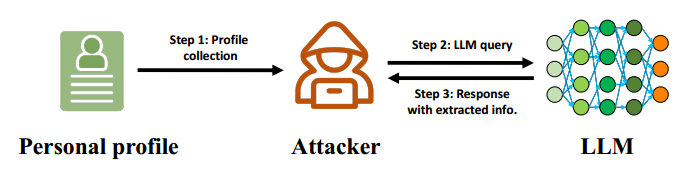 在攻击框架中,作者将 LLM-PIE 形式化为如下过程:对给定的个人 profile 文本 以及个人信息类别 , 攻击者构造针对该类别的查询 prompt 并向模型 发起查询, 从而获得对应的个人信息抽取结果:
在攻击框架中,作者将 LLM-PIE 形式化为如下过程:对给定的个人 profile 文本 以及个人信息类别 , 攻击者构造针对该类别的查询 prompt 并向模型 发起查询, 从而获得对应的个人信息抽取结果:
其中, 表示针对第 类个人信息构造的查询 prompt, 表示输入的个人 profile 文本, 表示模型对第 类个人信息的预测抽取结果。
并指出攻击成功的关键主要取决于两个组件:Prompt 设计和Profile 处理方式。Prompt 设计作者总结了三类主要策略:Prompt 风格设计(指令式、问答式等)、In-context learning(ICL)示例、用于绕过防御的额外指令(例如对 “AT / DOT” 符号替换的还原指令); Profile 处理作者讨论了不同 profile 格式(HTML / PDF / Word / Markdown 等)及其预处理策略对抽取效果的影响,例如:直接输入原始文本、过滤导航栏、冗余内容后再输入。
在防御方面,论文提出了一种核心新策略:基于 prompt injection 的对抗措施。其核心思想并非增强模型本身的安全性,而是让个人主页“嵌入不可见指令”,从而在 LLM 读取 profile 时误导其行为,降低个人信息被成功抽取的概率。作者强调防御性 prompt injection 的三个设计目标:有效性(使模型忽略攻击者的抽取指令)、不可见性(不影响正常用户阅读体验)和通用性(覆盖多类个人信息字段)。
贡献分析
贡献点 1 :提出并形式化 LLM-PIE 攻击框架。论文将 LLM-PIE 抽取过程形式化为 ,并系统分析了 prompt 风格、ICL 示例、绕过指令等因素对攻击成功率的影响,使prompt 工程从经验技巧上升为可测量、可复现的攻击组件。
贡献点 2:构建合成与多真实世界数据集,系统评估抽取风险。合成数据集由 GPT-4 生成并控制网页风格多样性,真实数据集覆盖名人、医师、顶尖高校教授主页与司法文本。其中教授数据集包含现实中已部署对抗措施的 profile,使评估结果更贴近真实应用场景。
贡献点 3:提出防御性 prompt injection 并给出工程化落地方案。作者不仅提出通过注入指令误导 LLM 忽略攻击 prompt 的思路,还明确给出了网页侧的工程化实现方式:将防御内容嵌入正文附近,设置与背景一致的字体颜色,并通过 CSS 控制其不可选中,实现“对人不可见但对模型可读”的防御效果。
代码分析
代码链接
GitHub 仓库:https://github.com/liu00222/LLM-Based-Personal-Profile-Extraction
Zenodo 复现实验工件(Baseline_Code.zip / LLM_PIE_Code.zip):https://doi.org/10.5281/zenodo.14737200
使用类库分析:其依赖主要由Python 标准库 + 开源科研生态 + 公开模型接口 SDK 组成,属于典型的“开源类库集成 + API/开源模型推理”工程形态,不影响其开源依赖为主的性质。
代码实现难度与工作量评估:该项目整体难度属于中等偏上,工作量较大,主要原因在于其并非单一模型脚本,而是需要支撑“多数据集 × 多模型 × 多攻击设置 × 多防御设置”的系统化评测。
代码关键实现功能,可将其核心功能拆分为 5 个模块:
(1) 数据集与标注管理模块
负责读取合成与真实 profile 数据集,并按个人信息类别组织标注,向后续攻击与评估流程提供统一数据接口。。
(2)攻击框架模块
实现针对不同个人信息类别的抽取攻击流程,包括查询 prompt 的生成(如风格与 ICL 示例)以及 profile 输入的不同处理策略,并调用模型获得抽取结果。
(3) 对抗措施构造模块
实现多种防御策略的构造与注入,重点支持论文提出的防御性 prompt injection 方法,用于评估不同对抗措施对抽取攻击的抑制效果。
(4) 评估指标模块
对模型输出与真实标注进行对齐,计算 Accuracy / Rouge-1 等评价指标,并支持对自由文本类信息的语义相似性评估。
(5) 实验调度与复现模块
统一组织不同模型、数据集、攻击与防御设置的实验流程,完成结果记录与实验复现。
4. 论文点评
该论文系统研究了基于大语言模型的个人信息抽取(LLM-PIE)风险及其对抗措施,针对攻击者可利用 LLM 从公开个人主页中低门槛抽取姓名、邮箱、电话、机构及工作/教育经历等敏感信息的问题,构建了完整的评估框架,并从 prompt 设计与 profile 处理两个维度刻画了抽取攻击的主要影响因素。同时,论文提出了防御性 prompt injection 作为网页侧可部署的对抗思路,通过在个人主页中嵌入对人不可见但对模型可读的指令来误导 LLM 输出,在工程层面具有一定创新性和现实意义。但论文仍存在一些不足和改进空间。
首先,在威胁模型设定上,防御方案主要针对文本输入型的 LLM-PIE 攻击场景,默认攻击者会直接将网页源码或文本输入模型。然而在实际应用中,攻击者可能采用更强的预处理方式,例如仅保留可见文本、去除 CSS 隐藏节点、对页面进行渲染后再抽取,甚至通过网页截图结合多模态模型进行信息获取。在这些更强攻击假设下,不可见注入文本可能无法进入模型输入,从而削弱防御效果,论文对此仅作定性讨论,缺乏系统性的对抗评估。
其次,防御性 prompt injection 强调“不可见性”,虽然能够降低信息抽取成功率,但在真实部署中可能与可访问性要求产生冲突,例如屏幕阅读器等辅助技术可能读取到不可见注入内容,影响正常用户体验甚至引发合规问题。论文指出了这一潜在风险,但尚未给出具体的工程化缓解方案,后续研究可进一步探索兼顾安全性与可用性的隐藏策略。
最后,在评估方法方面,论文针对结构化字段与自由文本字段分别采用 Accuracy、ROUGE 和 BERTScore 等指标,整体设计较为合理,但在工作经历、教育背景等自由文本字段上,防御诱导模型输出的“模板化或想象内容”仍可能与真实标签在通用词层面存在重合,从而导致相似度指标偏高,影响对防御效果的准确衡量。未来可考虑引入更严格的结构化抽取约束或字段级匹配规则,以提高评估结果的稳定性与可信度。
总体而言,该论文在揭示 LLM 驱动个人信息抽取风险以及探索网页侧对抗措施方面具有较高研究价值,但其防御方法在更强攻击模型下的鲁棒性、实际部署可行性以及评估指标的精细化程度仍有进一步提升空间。
论文文献
Liu Y, Jia Y, Jia J, et al. Evaluating {LLM-based} Personal Information Extraction and Countermeasures[C]//34th USENIX Security Symposium (USENIX Security 25). 2025: 1669-1688.
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
声明:本文来自安全学术圈,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
