
论文题目:Fuzz4All: Universal Fuzzing with Large Language Models
论文作者:Chunqiu Steven Xia, Matteo Paltenghi, Jia Le Tian, Michael Pradel, Lingming Zhang发表会议:3ICSE IEEE/ACM International Conference on Software Engineering主题类型:漏洞检测笔记作者:代吉富@Web攻击检测与追踪主编:黄诚@安全学术圈
研究概述
模糊测试是发现各类软件系统中的漏洞和缺陷的有效方法。它通过生成异常的输入来暴露软件中的潜在错误,有许多研究人员和工程师已经构建出多种实用的模糊测试工具,在实际系统中发现了大量缺陷和漏洞。其中一个重要的系统类别是以编程语言或形式语言作为输入的系统,如编译器、运行时引擎和约束求解器等,这类系统通常是各种软件系统的基础构件,因此在编译器或运行时引擎中发现缺陷非常重要,因为这些缺陷或错误可能影响到所有的下游应用程序。传统的模糊测试其可以分为生成模糊器和变异模糊器两类,但这两种方法目前都面临高度依赖目标系统和语言、缺乏对系统演化的支持、生成能力受限的问题。基于此背景,本文提出了一种能够支持多种输入语言和语言特性的通用模糊测试框架Fuzz4ALL。该框架使用LLM作为输入的生成与变异引擎,结合自动提示与迭代模糊测试循环自动生成高质量、具有多样性的测试输入。
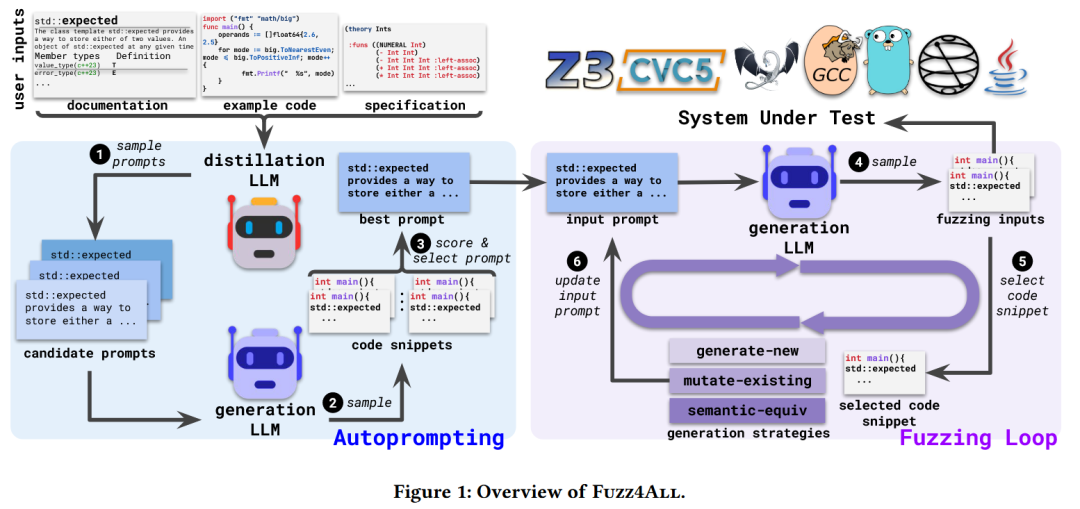
图1 Fuzz4ALL整体框架图
Fuzz4ALL框架的整体架构如图1所示,其主要包括自动提示和模糊测试循环两部分。自动提示阶段,框架接收系统文档、语言规范、示例代码等结构松散、冗长的数据作为输入,使用精炼大模型(GPT-4)对其进行摘要和提取,生成多个候选提示词。将这些候选提示词用于生成大模型(StarCoder)输出代码片段,再根据代码片段的质量选取一个最佳提示,供后续使用。
在模糊测试循环阶段,Fuzz4ALL使用选定的最佳提示词作为输入,通过代码生成模型生成系统的输入用例,交由系统运行,判定是否触发崩溃、断言失败或其他异常行为。之后进入模糊测试循环,从已有的有效模糊输入中随机选择一个代码片段示例,并结合一种生成策略(生成全新示例、基于示例进行变异、语义等价变换),对输入提示词进行更新,然后传入代码生成模型用于产生新的模糊测试输入用例,并交由系统运行,检测相关错误或异常。该循环过程会一直进行,直到超时或超过输入数量限制,模糊测试中导致程序崩溃的信息都会被收集以用于最终的异常分析。
贡献分析
贡献点1:论文针对现有模糊器强依赖于相关特定语言和特性的问题,提出利用LLM的多语言理解特性,实现通用模糊测试,能够生成广泛的有意义的输入用例。
贡献点2:论文提出使用精炼大模型来蒸馏系统的冗杂、松散的输入,以得到有效的候选提示词,用于生成通用、有效、有针对性的输入用例。
贡献点3:论文使用LLM来驱动模糊测试循环过程,通过使用随机选择的输入示例、生成策略来迭代修改输入提示,以生成新的测试用例,提高覆盖率。
贡献点4:论文通过对六种流行的编程语言和九个编译器进行实验,相比现有的模糊测试器,本文的方法显著提高了覆盖范围。并且发现了98个错误,其中64个被证实是之前未发现的错误。
代码分析
代码链接:https://github.com/fuzz4all/fuzz4all
1. 代码使用类库分析,是否全为开源类库的集成
Fuzz4ALL完全基于开源生态构建,主要使用Python语言进行开发。使用的开源类库如transformers、datasets(数据处理)、torch等,项目中也使用了openai和huggingface等社区提供的模型接口,可以便捷与大模型进行交互。
2. 代码实现难度及工作量评估
Fuzz4ALL的实现涉及多个复杂组件集成,包括自动提示生成、LLM 驱动的模糊测试循环、跨语言支持等。项目整体结构清晰,模块划分合理,如Fuzz4All/target/ 目录下包含了对不同语言的适配器模块。Fuzz4ALL由于功能的复杂性和跨语言的支持,代码实现具备一定的工作量,且相关模块的实现有一定的难度。
3. 代码关键实现的功能(模块)
(1)自动提示生成模块:该模块负责从文档和示例中使用精炼大模型来蒸馏输入,得到相关的候选输入,并对候选输入生成代码进行评分,最终得到最佳提示输入。
(2)LLM驱动的模糊测试循环流程:该模块通过迭代更新输入提示词,结合生成新用例、变异现有用例和语义等价变化等策略,持续生成高质量的测试用例。并设置超时时间和迭代次数,持续循环测试,提高覆盖范围,发现并分析程序的崩溃信息。
(3)多语言支持模块:在Fuzz4All/target/目录下,项目为C、C++、Go、Java、SMT等语言实现了特定的适配器,确保多语言的适用性。
论文点评
(1)生成输入的有效性偏低:相较于传统模糊测试工具,Fuzz4ALL生成的fuzzing inputs数量较少,且平均有效性(C语言)仅为40.58%,在其他多种语言上的有效输入比例也明显偏低。大模型生成的这种低效的输入可能会浪费大量的计算资源,且容易带来误报和无效测试路径。未来可以在框架中引入语法和语义检查器对生成的输入进行快速预筛选,提高输入质量。同时,结合静态分析器或符号执行来对无效的输入进行诊断、修复和再生成。
(2)功能测试能力强,逻辑语义错误捕捉能力较弱:Fuzz4ALL在检测编译器崩溃、断言失败等异常方面效果显著,但对于更加细微的逻辑错误或误编译支持不足;同时对于编译结果错误、性能退化、边界行为异常等问题难以覆盖。未来可以考虑加入差分测试、形式验证等技术手段以提升检测深度,同时也可加入代码执行轨迹比较和运行时检测模块。
(3)自动提示策略可控性弱,评价标准单一:Fuzz4ALL框架中的自动提示模块当前是黑盒评估形式,缺少用户可视化与干预能力,且给出的提示缺乏相关可解释性、多样性、覆盖面等多维度的评估。未来可以丰富自动提示的评估指标,如引入语义复杂度、覆盖分布、结构差异等指标。也可以引入提示剪枝、合并与去噪机制,提升提示的简洁性和生成效率。
(4)评估体系与应用场景单一:论文的实验中仅以模糊测试覆盖率和错误数量作为衡量指标,未涉及工业部署实践、系统稳定性等更广泛层面。未来可以在真实的CI/CD系统中集成Fuzz4ALL,对其稳定性、自动化能力进行长周期评估;同时可以引入一些下游任务,如程序修复建议、Oracle自动合成等,以扩展系统功能边界。
论文文献
Xia C S, Paltenghi M, Le Tian J, et al. Fuzz4all: Universal fuzzing with large language models[C]//Proceedings of the IEEE/ACM 46th International Conference on Software Engineering. 2024: 1-13.
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
声明:本文来自安全学术圈,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
