
原文标题:"Abuse Risks are Often Inherent to Product Features": Exploring AI Vendors" Bug Bounty and Responsible Disclosure Policies
原文作者:Yangheran Piao, Jingjie Li, Daniel W.Woods发表期刊:USENIX Security Symposium 2026笔记作者:CDra90n@安全学术圈主编:黄诚@安全学术圈
0x01 Introduction
随着人工智能技术被广泛嵌入各类软件和系统,安全研究者开始不断发现与 AI 相关的新型漏洞,例如提示注入、模型窃取、推理攻击等等。然而,一个问题逐渐浮现:AI 厂商是否像对待传统软件漏洞一样处理和披露这些 AI 漏洞的报告?在传统软件安全领域,漏洞披露主要通过两种机制运作:漏洞披露计划(VDP)用于接受由安全研究者提交的漏洞报告,而漏洞赏金计划(BBP)则进一步对报告者提供奖励。这一机制在过去二十年中被广泛采用,并被认为是促进厂商与白帽子进行安全合作的重要基础。AI 的广泛应用引入了新情况:许多 AI 相关威胁具有概率性、不可完全修补、或与生成内容相关等特性,使 AI 公司难以界定其是否属于可奖励或可纳入披露流程的漏洞。鉴于目前对 AI 相关的漏洞披露现状了解有限,本文系统性分析了 264 家 AI 厂商的漏洞披露政策,并结合了现实的 AI 安全事件集(AI Incident)以及学术论文数据集,关注以下问题:
(1)AI 行业当前的漏洞披露机制如何,哪些 AI 漏洞会被接受?
(2)不同AI公司在对待 AI 漏洞时呈现出怎样的立场差异?
(3)漏洞披露计划中所关注的 AI 风险,是否与真实 AI 事件和学术研究重点相一致?
0x02 Methodology
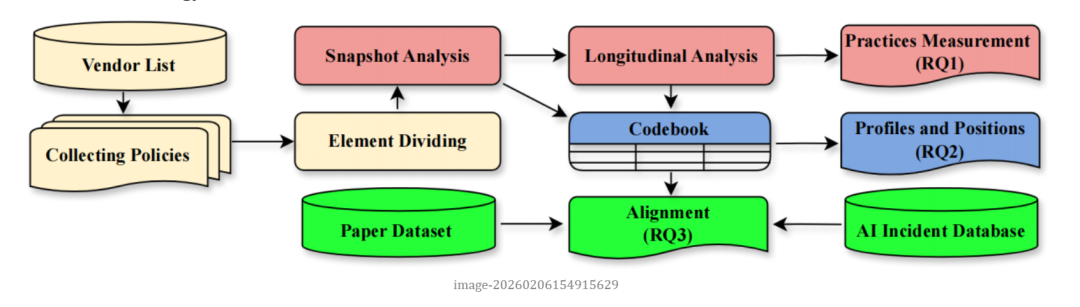
为理解 AI 行业当前漏洞披露的现状,作者采用了混合方法的设计进行了综合分析。首先,基于 Gartner 的厂商产品分类,作者共筛选出 264 家 AI 公司,并从其官方网站、漏洞赏金平台(如 HackerOne、Bugcrowd)以及 security.txt 中收集漏洞披露政策,共得到 168 份文档。

在分析的第一阶段,研究主要关注披露政策的文本。在结构层面,基于以往工作 [1] 提出的漏洞披露政策元素集合,作者根据研究问题扩展为包含15 个元素的分析框架,并基于框架对全部文档进行了半自动化分类。然后,进一步聚焦 AI 相关内容:AI 厂商中仅有 48 家明确提及 AI 漏洞。作者对这些政策片段进行关键词提取和主题编码,得到了关于AI漏洞的企业立场的 codebook。然后,作者通过 Wayback Machine 和平台政策变更记录进行了纵向分析,追踪了2018–2025 年间 AI 相关的漏洞披露政策更新。在第二阶段,作者将披露政策的数据与两个外部数据源对照:一是 AI Incident Database [2] 中相关公司的 AI 安全事件报道;二是四大安全会议上发表的 AI 安全论文 [3],以此来比较 AI 行业、现实报道与学术界三方的关注重点。

0x03 Results
RQ1: Reporting Practices Measurement
从整体覆盖情况来看,AI 行业的漏洞披露生态呈现出相对不成熟状态。在 264 家 AI 厂商中,有 36% 完全没有公开的漏洞披露渠道,既没有赏金计划,也没有正式的披露政策。部分厂商仅在信任中心(Trust Center)或安全声明中笼统提及重视安全,但并未提供可操作的报告渠道。即便在提供漏洞披露的厂商中,成熟度差异也很大:约 1/4 的AI 公司运行着带有奖励的 BBP,其余多为VDP或仅留一个安全联系方式。
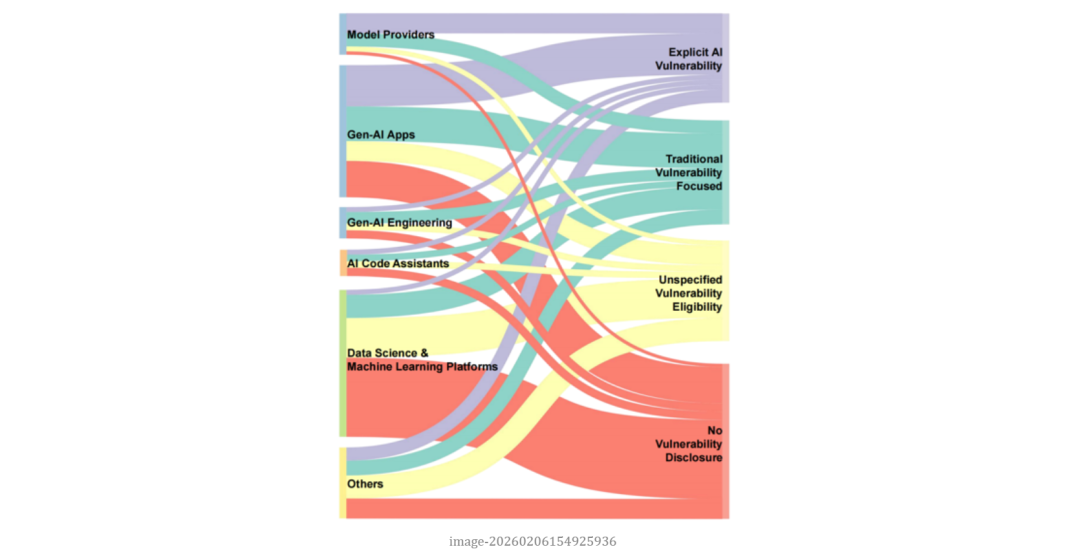
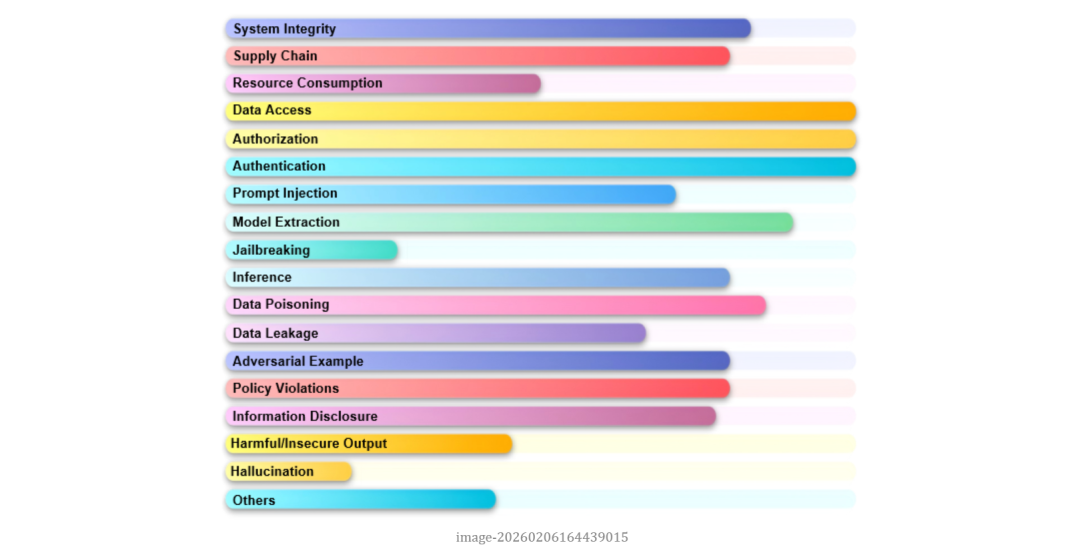
作者进一步检查了这些 AI 公司是否承认或提及 AI 漏洞的存在,发现仅 18% 的厂商在政策中明确提到 AI 漏洞或其 AI 产品。这意味着大多数 AI 厂商仍然沿用传统软件安全话语体系,而没有对 AI 风险做出政策层面的回应。作者进一步分析了政策中纳入和排除的 AI 漏洞类型,可以分为 AI 系统,AI 模型和 AI 特征。结果显示,最容易被纳入范围的是以传统安全目标为表述方式的 AI 系统漏洞,例如AI系统中的跨用户数据访问、权限提升、认证绕过或资源滥用等。这类问题虽然发生在 AI 驱动的产品中,但本质上仍然是机密性、完整性和可用性被破坏,被纳入漏洞接受范围的比例超过 90%。
相比之下,AI 模型层漏洞的接受度呈现分化。数据投毒、模型窃取和推理攻击等问题,由于可能影响模型权重、知识产权或训练数据隐私,部分厂商将其视为高价值风险,并给予与核心资产相当的奖励。但提示注入和越狱(jailbreak)则更具争议。一些厂商将其视为输入处理缺陷或越权访问的变体,愿意纳入范围;另一些则认为这是模型固有功能的表现,难以彻底修补,因此选择排除在漏洞接受范围外。与输出内容直接相关的 AI 特征类风险最容易被排除在外,包括幻觉(hallucination)、有害内容生成、误导性回答等风险。虽然这类问题在政策文本中出现频率不低,但绝大多数厂商将其界定为负责任 AI 使用或内容安全问题,而非安全漏洞。这类问题通常被引导至滥用类报告渠道,而不在赏金计划中给予奖励。
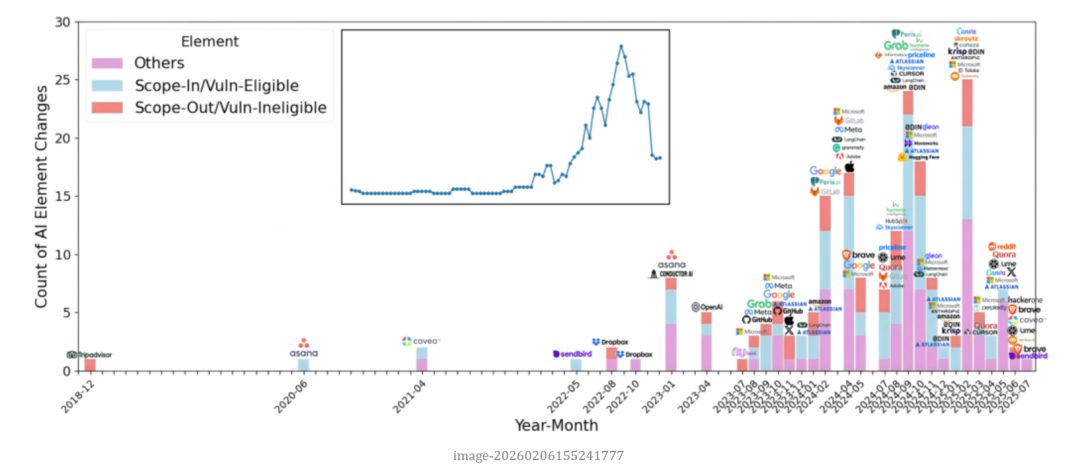
从政策结构角度看,明确提及 AI 问题的厂商往往也在政策元素完备程度上更高。他们更可能提供明确的测试规则、响应时间承诺以及奖励评估机制。而那些未提及 AI 的政策,往往在结构上也较为简略,缺乏清晰的范围界定或者保护条款。纵向分析进一步揭示,AI 相关政策的集中更新主要始于 2023 年之后。2018–2022 年间更新稀少,而 2024 年成为一个高峰期,大量厂商开始将 AI 产品加入测试范围或新增 AI 漏洞条款。这表明,AI 漏洞的披露机制在逐步制度化。
RQ2: Profiles and Positions
在对人工智能漏洞报告政策进行定性分析后,作者将 264 家 AI 厂商划分为三种典型立场。这一分类反映的并非厂商在技术或安全能力上的差异,而是其在披露政策层面对 AI 漏洞所采取的立场。
第一类是 Proactive Clarification,约占17%。这类厂商不仅在政策中明确提及 AI 系统或 AI 漏洞,还尝试建立专门规则来处理相关漏洞。其中又可细分为三种:Active Supporters 主动鼓励提交 AI 漏洞,提供测试指南、示例、专门评估标准,甚至设立独立的 AI 漏洞赏金计划;AI Integrationists 则将 AI 漏洞并入现有披露框架,以列表方式标注 AI 资产或AI漏洞类型,缺乏额外解释与资源支持;Back-channel 类型的公司虽承认 AI 风险存在,却不将其视为安全漏洞,而是引导研究者通过其它反馈渠道报告,通常不提供赏金,也不适用漏洞披露中的安全港条款。
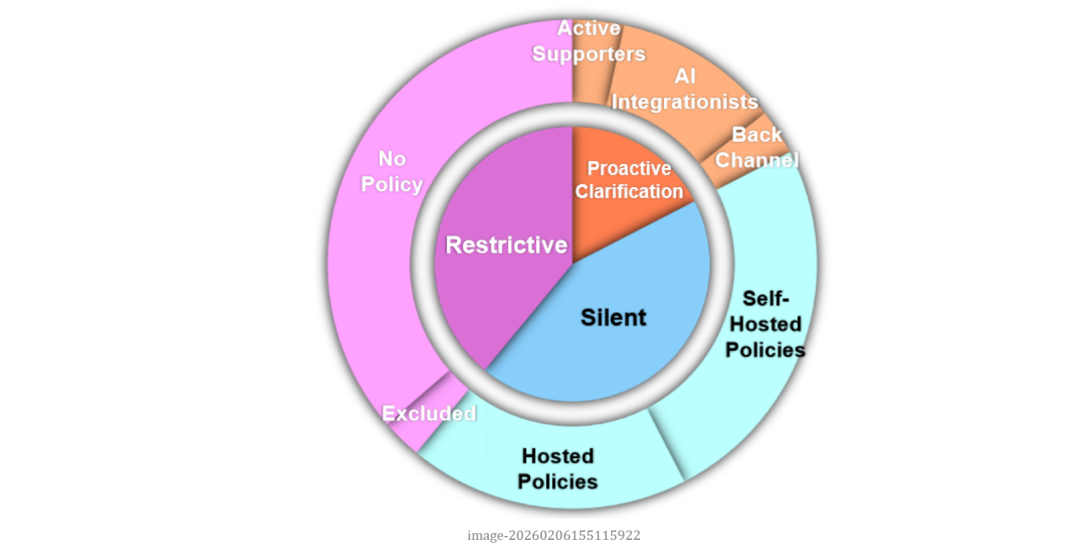
第二类是 Silent,约占 44%,也是数量最多的一组。这些厂商拥有常规的漏洞披露机制,但政策中没有 AI 相关字眼。其沉默呈现出两种形态:Self-Hosted 指厂商自行部署 VDP 或 BBP,但未更新以覆盖 AI 问题,在形式上,这并不等于拒绝 AI 漏洞,研究者仍可以提交与 AI 有关的问题,只要它们能被描述为与传统安全相关的报告。Platform-Hosted 则指依托大型漏洞赏金平台运行项目的厂商,虽然在赏金平台层面已存在 AI 漏洞分类,但厂商自身政策未表态,形成技术上可提交、政策上无确认的灰色地带。由于缺乏明确说明,研究者难以判断越狱或模型滥用等问题是否会被视为有效。这种模糊状态在实践中可能导致研究者承担更高的沟通成本和不确定性风险。
第三类是 Restrictive,约 39%,这些厂商表现出排斥或回避的状态。其中一部分厂商没有漏洞披露渠道,使得 AI 甚至传统漏洞都难以进入正式报告流程。另一部分则虽然拥有披露政策,却明确将 AI 系统或相关问题排除在外,或声明此类问题“暂不受理”。在这种模式下,AI 风险被制度性地划出漏洞治理框架之外。
RQ3: AI Incident & Research Alignment
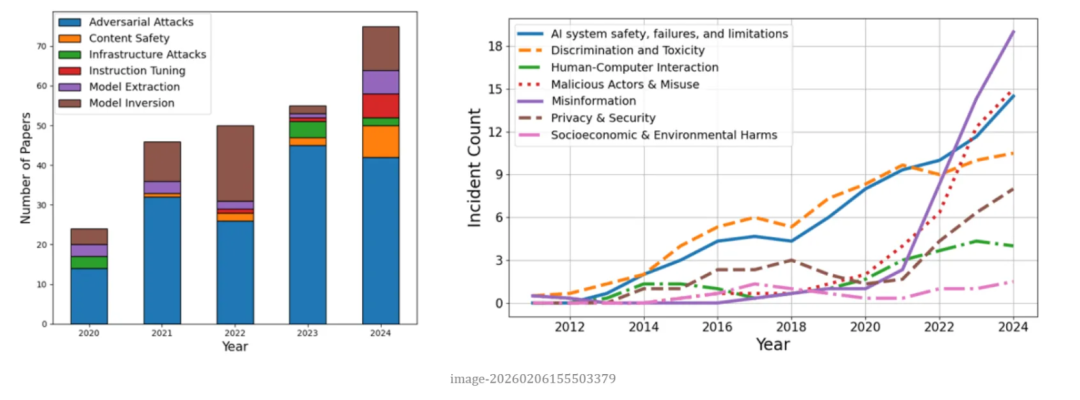
在将漏洞政策与现实 AI 事件进行对比时,可以观察到在时间维度和漏洞类型上的不对齐性。真实世界的 AI 事件报道主要集中在算法歧视、有毒内容、虚假信息以及系统能力不足等问题,这些属于下游社会性风险。这些风险极少被纳入漏洞赏金或披露奖励范围。大多数厂商可能认为它们属于内容治理或负责任 AI 的范畴,而非安全漏洞。相比之下,厂商政策更关注系统完整性、数据泄露、模型窃取等技术层面的上游安全风险,而这些风险在事件数据库中所占比例较低。学术研究的关注点与厂商更接近,主要集中在反演攻击、对抗样本和模型窃取等模型问题。因此可以看到:学术与产业在技术层面存在部分对齐,但两者都与现实事件中占主导的社会性风险存在差距。在时间上,学术界和现实事件报道对 AI 风险的关注明显早于厂商政策更新,厂商往往在问题公开很久后才将其纳入披露规则。
0x04 Future Work
本研究表明,AI 漏洞的报告与披露仍处于探索期,未来工作可以关注 AI 漏洞的责任边界问题。由于大量 AI 应用依赖上游基础模型,当漏洞发生在模型层而暴露在应用层时,研究者往往难以判断应向谁报告。通过研究不同供应链结构下的披露流转路径,有助于厘清 AI 生态中的安全责任分配。此外,需要探索哪些 AI 风险适合纳入漏洞披露体系,哪些更适合独立的安全或内容治理机制。当前厂商普遍将幻觉、有害输出等问题排除在漏洞范围之外,但真实世界事件却大量集中于这些领域。因此,如何将漏洞披露机制与更广泛的 AI 风险响应体系衔接,是一个重要的设计问题。最后,随着越来越多厂商开始更新 AI 漏洞相关政策,未来可以进行更深和更广泛的分析,评估什么因素影响了 AI 漏洞的报告数量、类型和修复速度,从而为 AI 漏洞披露机制的完善和标准化提供实证参考。
Reference
[1] T. Walshe and A. Simpson. Towards a greater understanding of coordinated vulnerability disclosure policy documents. Digital Threats: Research and Practice, 2023.
[2] https://incidentdatabase.ai/
[3] https://github.com/gnipping/Awesome-ML-SP-Papers
作者简介:Yangheran Piao,爱丁堡大学信息学院博士生导师:Prof. Ross Anderson,Dr. Daniel Woods 和 Dr. Jingjie Li。研究兴趣包括: Security Economics、Usable Security 和 Cybercrime。个人主页:https://blogs.ed.ac.uk/yangheran_piao/安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
声明:本文来自安全学术圈,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
