
原文标题:We Have a Package for You! A Comprehensive Analysis of Package Hallucinations by Code Generating LLMs
原文作者:Joseph Spracklen, Raveen Wijewickrama, A H M Nazmus Sakib, Anindya Maiti, Bimal Viswanath, Murtuza Jadliwala发表会议:USENIX Security Symposium笔记作者:龙函城主编:黄诚@安全学术圈
研究概述
随着代码生成式大语言模型在软件开发中的广泛应用,其输出已从示例代码逐渐演变为可直接运行与部署的工程代码。这一趋势使得模型生成结果与现代软件供应链(如 PyPI 与 npm)之间形成了前所未有的紧密连接。然而,现有关于 LLM 安全的研究主要聚焦于文本幻觉、隐私泄露与越狱攻击,而对于模型在依赖推荐层面引入的供应链风险缺乏系统性分析。
本文系统研究了一种安全威胁:Package Hallucination(包幻觉)。该现象指 LLM 在生成代码时推荐了现实世界中并不存在的第三方包名。在普通软件工程视角下,这只是“模型出错”;但在安全视角下,它构成一个可被直接武器化的攻击面,攻击者可以在 PyPI 或 npm 中抢先注册这些幻觉包名并植入恶意代码,当开发者照抄模型生成的 pip install 或 npm install 命令时,即会下载并执行攻击者的恶意依赖,从而形成一种新型的供应链投毒攻击,其流程如图一所示。
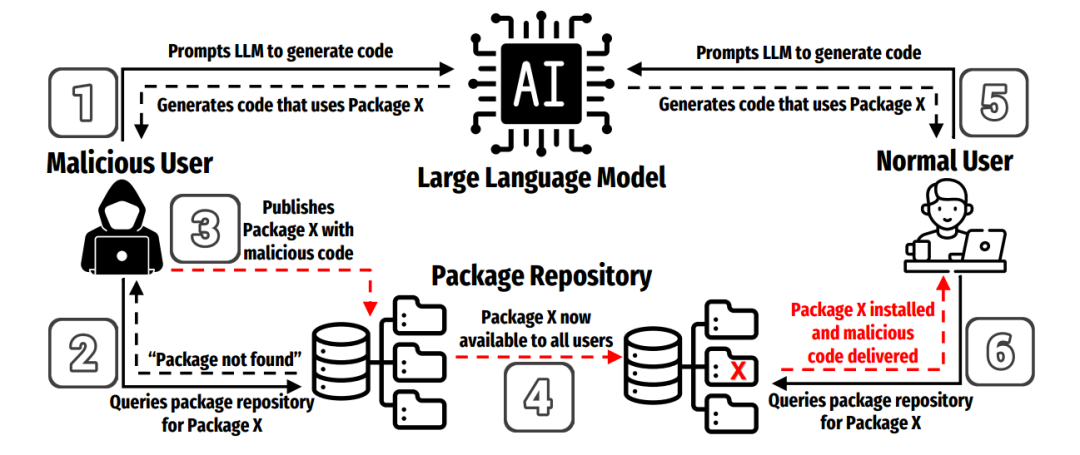
图 1 利用包幻觉
为系统刻画这一风险,作者构建了两个大规模、接近真实开发场景的数据集:(1)来自 Stack Overflow 的真实开发者提问,用于反映真实工程需求;(2)基于 PyPI 与 npm 热门包官方描述自动生成的任务提示,用于覆盖更广泛的 API 与功能空间。同时,为分析训练语料滞后性与新知识对模型行为的影响,作者将数据划分为 recent(2023 年) 与 all-time(2023 年之前) 两类。
在此基础上,论文对 16 个主流代码生成模型(涵盖商用与开源)在 Python 与 JavaScript 两大生态下进行系统评测,总计生成 57.6 万条代码样本。作者自动抽取生成代码中的依赖包名,并在 PyPI/npm 中校验其是否真实存在,从而对包幻觉的发生率、重复性、跨模型共现、字符串相似度、跨语言混淆以及历史删除包等维度进行系统分析。
实验结果表明,包幻觉是一种普遍存在且具有结构性的现象。模型不仅会生成大量现实世界中不存在、但看起来合理的依赖包名,而且这种行为还具有显著的持久性:同一模型在多次生成中会反复输出同一幻觉包名,使攻击者能够提前锁定高频幻觉目标并进行抢注投毒。进一步地,作者发现大部分幻觉包名并非简单的拼写错误,而是模型凭空构造的新名称;同时还存在一定比例的跨语言混淆现象,例如 Python 代码中生成合法的 npm 包名。这些发现表明包幻觉根源于模型对跨语言、跨库语义知识的错误泛化,而非简单的字符串扰动。
在防御层面,作者评估了多种缓解策略,包括 RAG、自我反思迭代、监督微调与集成策略。实验表明幻觉率可以显著降低,但与此同时会对代码的通过率产生负面影响,揭示出安全性与可用性之间的现实权衡。
贡献分析
贡献点1论文在 Python 与 JavaScript 两大主流代码语言中,对LLM 的包幻觉现象进行了大规模、系统化量化分析,证明该问题在商用与开源模型中均普遍存在,并形成了可被攻击者利用的供应链攻击面。
贡献点2作者深入分析了包幻觉的特征,包括其持久性、跨模型一致性、字符串相似度与跨语言混淆等,为后续检测与防御机制的设计提供了关键依据。
贡献点3论文系统评估了多种缓解策略(RAG、自我反思、微调与集成),揭示了降低包幻觉与保持代码正确性之间的现实权衡,为工程化防御提供了重要启示。
代码分析
代码链接
GitHub:https://github.com/Spracks/PackageHallucination
Zenodo:https://zenodo.org/records/14676377
使用类库分析:该项目整体基于 Python 开源科研生态与主流大模型推理框架实现,属于典型的“开源模型推理 + 脚本化大规模测量 + 结果统计复现”工程形态。其依赖体系主要用于支撑多模型批量代码生成、跨语言依赖解析、包名真实性对照以及实验结果的聚合与可视化,不依赖任何闭源核心组件,具备良好的可复现性与可扩展性,适合用于开展面向 LLM 供应链安全的大规模实证研究。
代码实现难度与工作量评估:从工程复杂度来看,该项目的实现难度处于中等偏上,工作量较大。其难点并不在于单个模型或算法的实现,而在于需要支撑一个 “多模型 × 多语言 × 多参数 × 多评测维度” 的系统化实验平台。
代码关键实现功能:结合代码结构与论文的实验设计,该项目的核心功能可以拆分为以下 5 个模块:
(1)数据集与提示管理模块:负责管理论文使用的各类提示数据,并按语言与来源进行组织。该模块确保不同模型在相同输入分布下进行测试,是保证实验公平性与可比性的基础。
(2)代码生成模块:在统一的提示输入与解码参数设置下,对不同代码生成模型进行批量推理,生成大规模 Python 与 JavaScript 代码样本。该模块将模型输出标准化存储,为后续依赖分析与统计提供统一数据源。
(3)依赖抽取与包幻觉检测模块:从生成代码中解析出模型实际推荐的第三方依赖,并通过与官方包仓库的有效包名列表对照,判断哪些依赖是真实存在的,哪些属于包幻觉。该模块通过语言定制化解析与统一的判定口径,将模型输出转化为可量化的安全风险指标。
(4)统计分析与结果汇总模块:对大量样本的检测结果进行聚合,计算论文中的核心指标(如包幻觉率、重复性、跨模型分布、相似度特征等),并生成用于绘制论文图表的结构化统计数据。
(5)缓解策略评测模块:在同一实验框架下集成多种防护与缓解方案,对比它们在降低包幻觉与保持代码可用性之间的权衡。
论文点评
总体来看,本文在代码生成大模型安全方向上提出了一个非常关键且长期被忽视的问题:LLM 在推荐第三方依赖时产生的“包幻觉”并不仅是普通生成错误,而是可以被攻击者直接转化为现实世界的软件供应链攻击。通过将模型生成虚构包名与 PyPI/npm 中的包抢注与投毒行为相结合,论文给出了一个高度现实且低门槛的攻击模型,使该问题具备了明确的安全威胁属性,而不再只是模型可用性问题。
在实验与工程实现方面,作者通过大规模多模型、多语言测量框架,对包幻觉的发生频率、重复性、与模型参数和训练数据时效性的关系进行了系统分析。尤其是论文揭示了包幻觉具有显著的持久性和可预测性:同一模型会反复生成相同的虚构包名,这使攻击者可以提前锁定高价值幻觉目标并进行投毒,显著放大了风险的可利用性。"
在缓解策略方面,论文并未停留在简单过滤不存在包名的层面,而是系统评估了RAG、自我检测与微调等方法,并量化了它们在降低幻觉率与保持代码可用性之间的权衡关系,体现了较强的工程现实感。
论文文献
Spracklen J, Wijewickrama R, Sakib A H M N, et al. We have a package for you! a comprehensive analysis of package hallucinations by code generating LLMs[C]//34th USENIX Security Symposium (USENIX Security 25). 2025: 3687-3706.
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
声明:本文来自安全学术圈,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
