工作来源
arXiv:2601.21051
工作背景
以 DeepSeek-R1 与 OpenAI o1 为代表的原生推理模型引领了大模型技术的新范式,通过逐步推理来提升“智能”表现,但这种推理方法在网络安全领域尚不成熟。现有的安全大模型处理直接查询时表现尚可,面对需要多步逻辑分析的复杂任务(威胁情报分析、漏洞评估、事件响应等)时往往力不从心。
在网络安全领域中,“如何得出结论”和“结论本身”一样重要。业界需要一种能够“三思而后行”且提供可审计逻辑链的安全大模型,这样才能增强对其输出结果的可信度。思科的 Foundation AI 团队顺势而为,在 2026 年年初发布了全球首个专门为网络安全领域打造的开源原生推理大模型。
工作准备
基于 Foundation AI 此前发布的基座模型 Foundation-Sec-8B,该模型基于 Llama-3.1-8B-Base 且在 80 亿 token 的私有网络安全语料库上预训练而来。
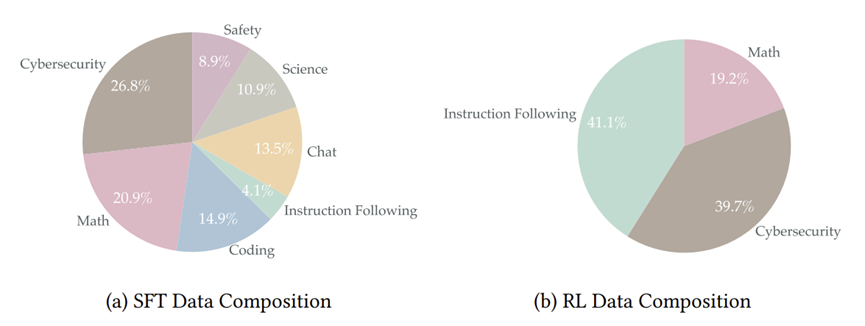
研究人员又利用 Gemini-2.5-Flash 构建 Agent,生成了约 200 万个合成数据样本,从而进行第一阶段的微调。这 200 万数据中并非完全是网络安全相关语料,网络安全语料只占到 26.8%。在垂类大模型的训练中,最害怕由于喂了太多网络安全知识,导致模型连最基础的代码和数据逻辑都遗忘了。所以数学和编程数据占到了约三分之一;剩下的则是指令遵循、通用对话、科学和安全对齐数据。
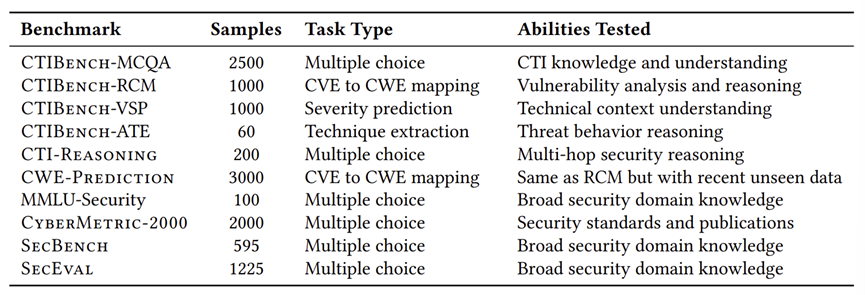
用到的网络安全相关评估 Benchmark:
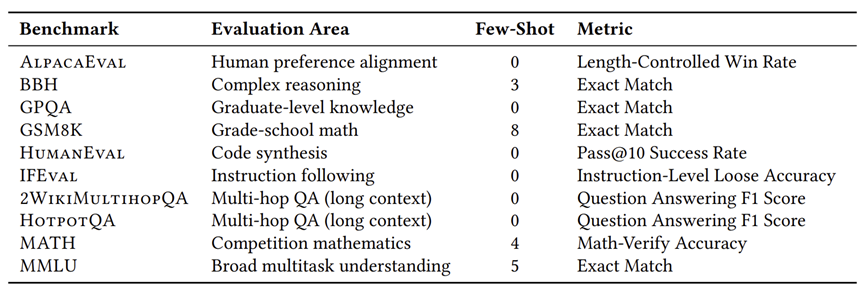
用到的通用评估 Benchmark:
工作设计
与传统的指令微调不同,研究人员采用两阶段推理训练模式:
阶段 ① 监督微调(SFT)植入推理本能
在 200 万合成数据上进行 3 个Epoch 的微调,使模型学会原生推理行为。之后模型在输出最终答案前,会生成显式的推理轨迹。
阶段 ② 可验证奖励强化学习
使用组相对策略优化(GRPO)算法,为每个 Prompt 生成 5 个回答,通过任务验证给出二元奖励。研究人员也解决了强化学习中两个常见的痛点:
数据异构性:不同任务的输出长度差异巨大,如果简单地将长回答的所有 Token 损失求平均,会导致模型在弱势任务上输出冗长、重复的废话来降低 Loss。而 Dr.GRPO 提出的“样本级损失聚合”方法,可以确保长序列和短序列对梯度更新的贡献公平。
奖励破解与格式退化:模型也会发现损失会随着输出长度增加而减小,于是为了“偷懒”,它可能只输出最终正确答案,而把思考过程缩短为
No 。研究人员在奖励函数中硬编码了格式惩罚,强制要求模型输出的推理思考,必须有实质性内容。从而降低了模型用短答案或者毫无意义的长废话来骗取奖励所带来的影响,这也是训练垂类小模型需要注意的地方。
工作评估
网络安全基准测试
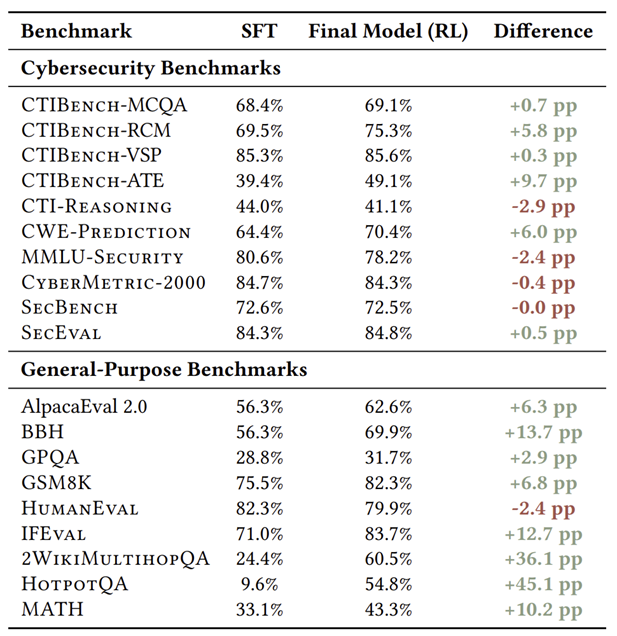
在 CTIBench-RCM 这个极其考验底层安全推理的任务上,该模型取得了 75.3% 的好成绩,不仅超过了指令微调版(70.4%),甚至超越了参数量大 15 倍的 GPT-OSS-120B(71.2%)以及 Llama-3.3-70B-Instruct(68.4%)。值得注意的是,在其他几个数据集上,该模型未能与其他表现较好的开源模型拉开差距,并且被商业模型 GPT 大幅领先。
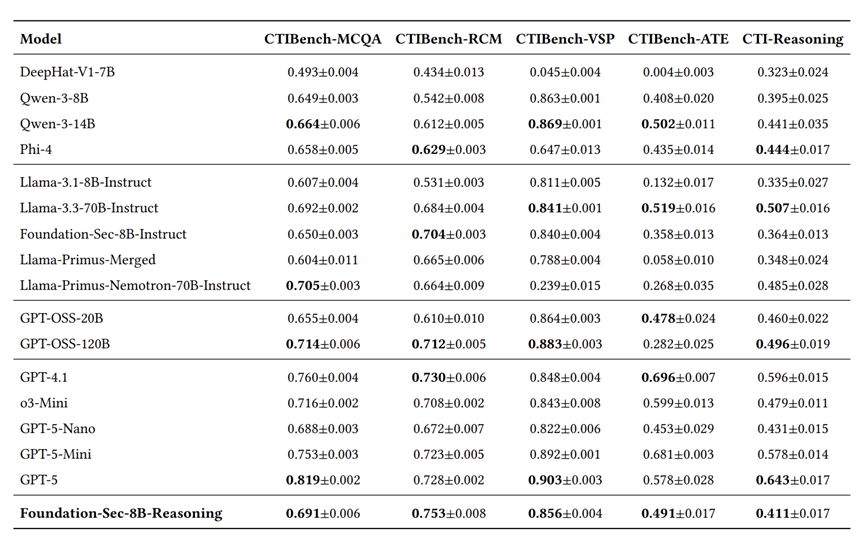
在最新的未见漏洞预测集 CWE-PREDICTION 上,同样拿下了 70.4% 的高分。在其他数据集上的表现也是平平无奇,更是比商业模型差很多。
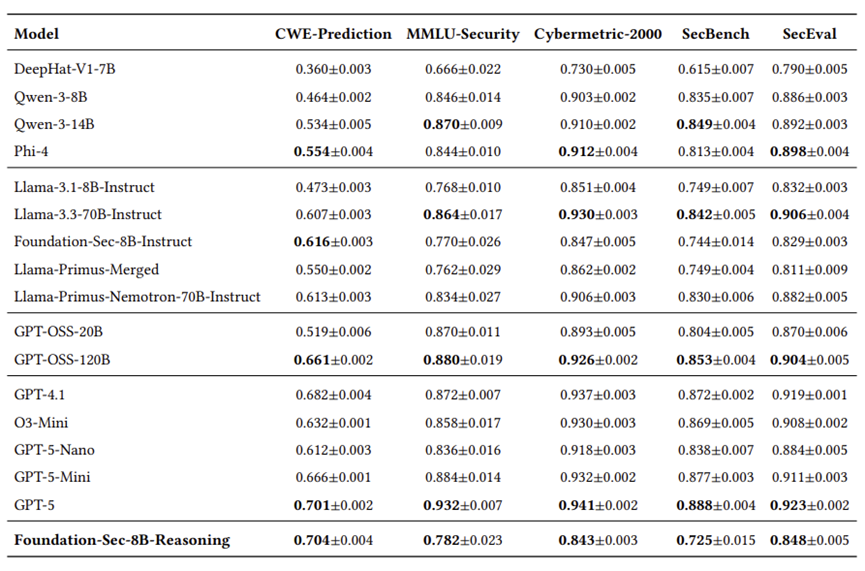
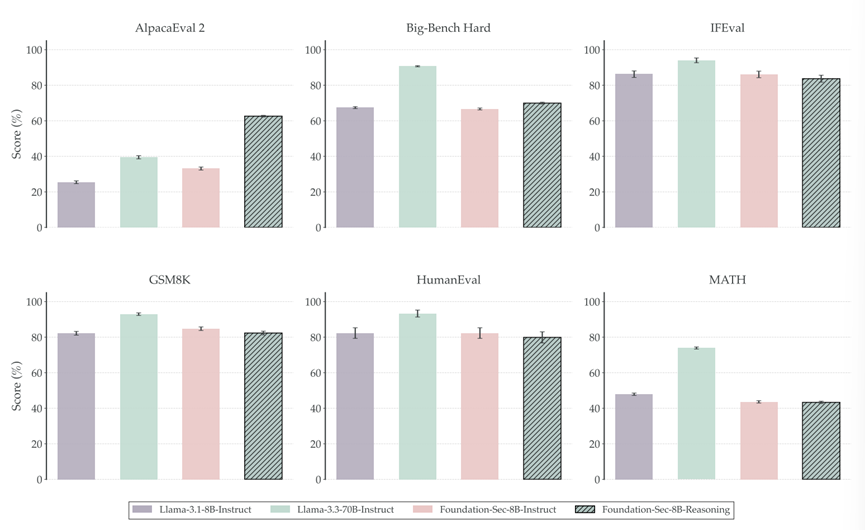
Foundation-Sec-8B-Reasoning 模型表现良好,在多个场景下均取得了不错的效果。
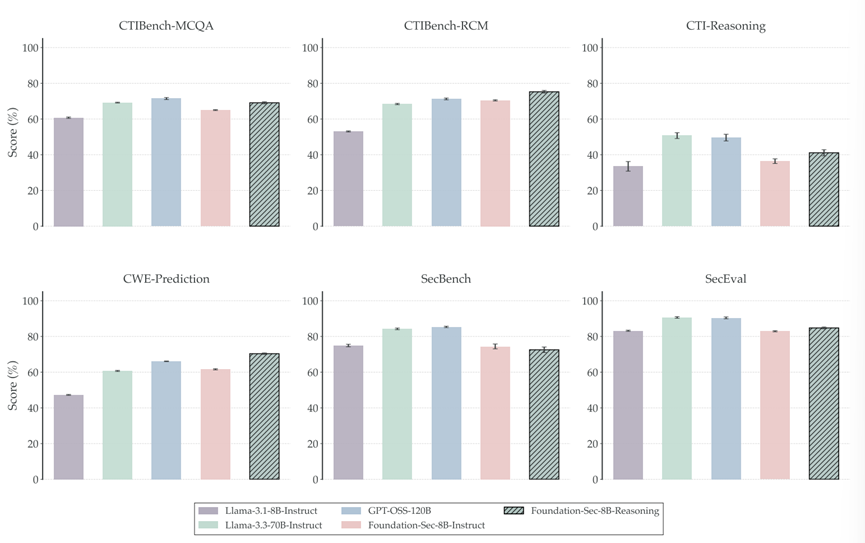
网络安全垂类训练并没有牺牲它的通识能力。经过强化学习训练后,模型在 2WikiMultihopQA 这种长文本逻辑题上实现了较大提升,准确率升至 60.5%。
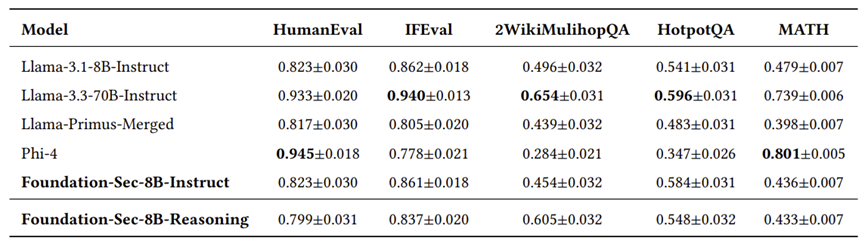
在 AlpacaEval 2场景下,提升了 146%。唯一的微小代价是代码生成(HumanEval)能力略微下降了约 2.4%,但这可以用其他专注于Coding的模型来解决。
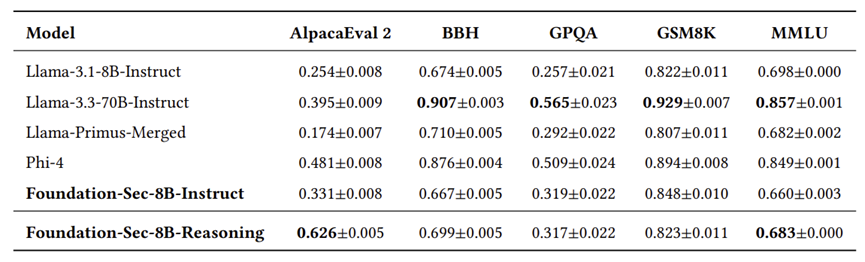
Foundation-Sec-8B-Reasoning 模型表现良好,在多个场景下均取得了不错的效果。
通过消融实验对比发现,仅做监督微调的模型在多跳推理上得分惨不忍睹(如 2WikiMultihopQA 仅 24.4%)。在利用监督微调建立领域知识后,正是强化学习赋予了模型深度解析和指令遵循的能力,让表现得以大幅提升。
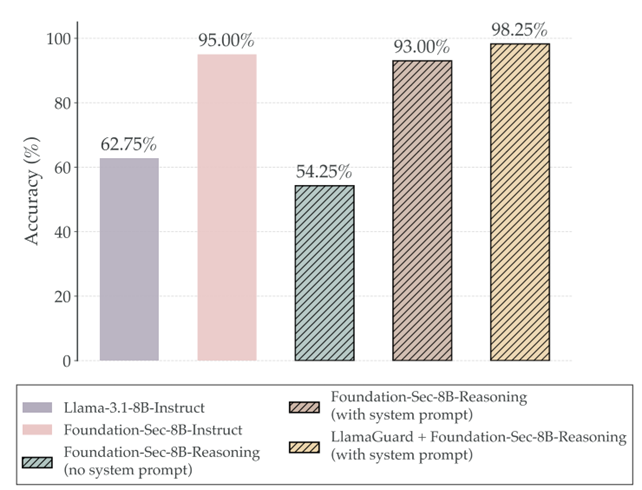
由于具备更强的推理能力,该模型如果被黑客利用编写恶意软件将极其危险。为此,团队为其量身定制了名为 "Metis" 的系统提示词,严格框定了它的安全边界。加上 Prompt 后,模型拒绝恶意请求的通过率达到了 93.00%;如果外挂 Llama-Guard-3 护栏,防御率高达 98.25%。
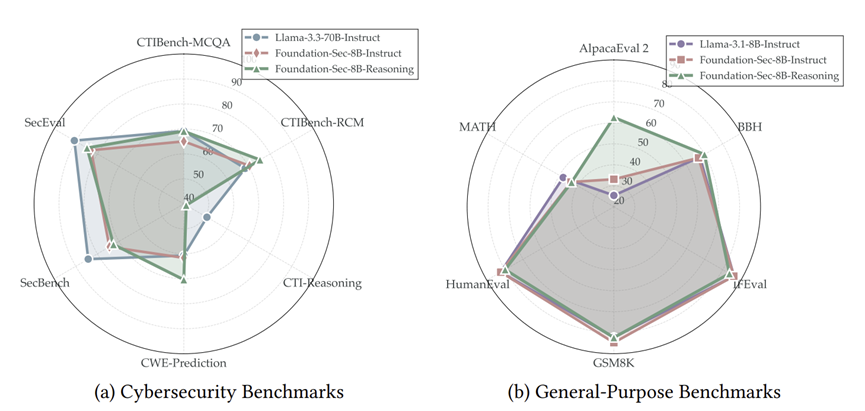
“小模型+强化学习推理”的模式能够在不牺牲广泛通用能力的前提下,在垂类任务上实现对通用大模型的反超。通过将系统提示词设定为“拥有高级网络安全专家经验”的 Metis 角色,并要求其在输出云安全配置等关键信息时必须绝对精准并引用来源,可以进一步锁定模型的专业度与安全性。
工作思考
现今的评测仍然局限在文本形态的一小类(如威胁情报报告),后续将网络安全领域承载更多信息的形态(如网络流量)接入处理,能力范围将进一步扩展。随着大模型能力的进一步提升,Agentic Workflows可能会越来越有用。
一方面如果本地部署的安全模型可以比肩规模较大的云端大模型的效果,那么就可以将调用API的费用省下来,并且能更好的保证数据隐私合规。

声明:本文来自威胁棱镜,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
