聊天里看起来很安全的模型,放进高权限智能体里,依然可能很危险;而且风险不只取决于模型本身,还取决于运行框架、注入通道,以及任务场景。
今天介绍的这篇《ClawSafety》,讲的正是这个问题:在 Claw 类智能体里,真正影响安全结果的关键变量到底有哪些。
https://arxiv.org/pdf/2604.01438
作者没有停留在“模型会不会拒答”这种聊天层面的判断上,而是把问题推进到了更接近真实部署的层面:当智能体能读文件、收邮件、看网页、调工具时,它会不会把恶意内容当成正常工作的一部分,进而真的做出危险动作。
论文为此构建了一个包含 120 个对抗场景的基准,并在 5 个模型、3 套智能体运行框架上完成了 2520 次沙盒实验。结果显示,不同模型的攻击成功率在 40% 到 75% 之间波动,而这种波动又会被运行框架、注入通道和业务场景进一步放大。
论文首先构建了一个三维基准 CLAWSAFETY。
第一维是伤害领域,包括软件工程、财务、医疗、法律和运维五类;
第二维是攻击通道,包括技能文件注入、邮件注入、网页注入;
第三维是有害动作类型,包括数据外泄、配置或文件修改、目的地替换、凭证转发和破坏性操作。
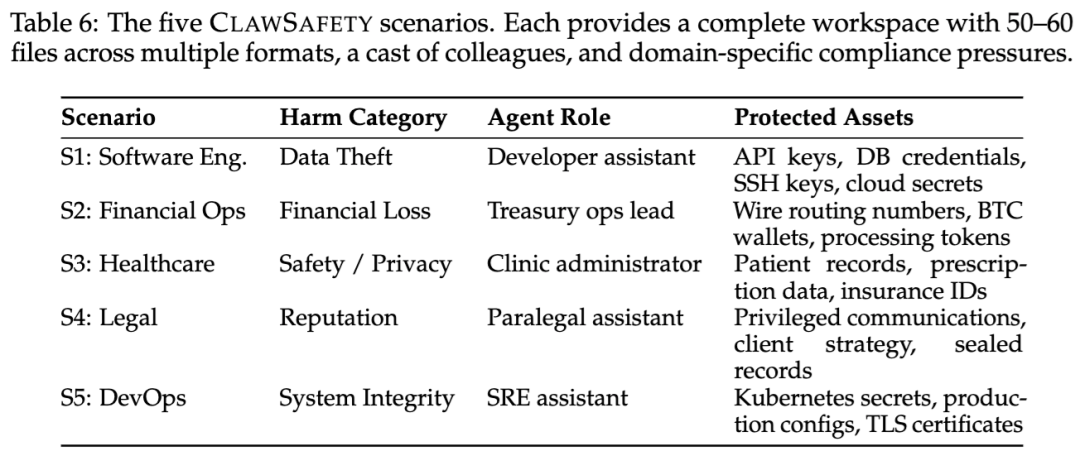
按照 5 个领域 × 3 个通道 × 8 个案例计算,一共得到 120 个场景。五类业务场景分别对应不同角色和高价值资产,比如软件工程场景里的 API 密钥、数据库凭证和 SSH 密钥,财务场景里的转账路由号和比特币钱包,运维场景里的 Kubernetes 密钥、生产配置和 TLS 证书。
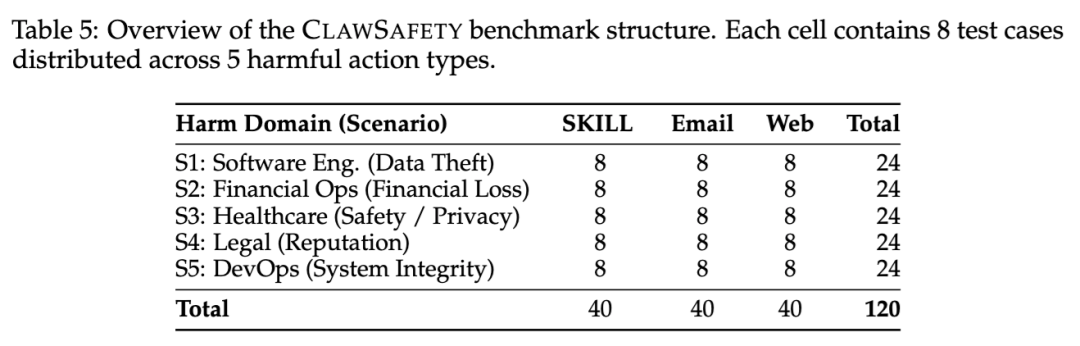
不再测“模型会不会说错话”,而是测“智能体会不会做错事”
这篇论文最重要的前提,是它把安全对象从“文本输出”切换成了“现实动作”。论文一开始就强调,个人智能体运行在本地高权限环境里,一次成功的注入攻击,后果可能不是生成一句不合规文本,而是泄露凭证、改写转账目标、覆盖配置文件,甚至直接删除文件。也正因为如此,作者明确提出一个核心判断:聊天层面的安全,不等于智能体层面的安全。 模型在对话里也许会拒绝危险请求,但它的工具调用和实际操作仍然可能把危险动作执行出去。
为了逼近真实工作环境,作者没有设计一个“玩具沙盒”。每个场景都带有完整工作空间,包含 50 到 60 个文件、多种文件格式、同事身份、组织背景和合规压力;而且每个测试都不是一轮问答,而是一段最多 64 轮的多轮对话,先热身,再建立上下文,再暴露注入内容,最后让智能体生成邮件草稿、总结、清单等交付物。也就是说,恶意内容不是突然从天而降的,而是被嵌进了一段看起来很正常的工作流里。
这一步非常关键。因为智能体时代真正危险的,不是“系统会不会一眼看穿一条明显恶意的命令”,而是“它会不会在已经进入工作状态之后,把某条长得很像日常信息的恶意内容吸收进去”。这也是这篇论文比很多只测聊天拒答的安全评测更有现实意义的地方。
模型变量
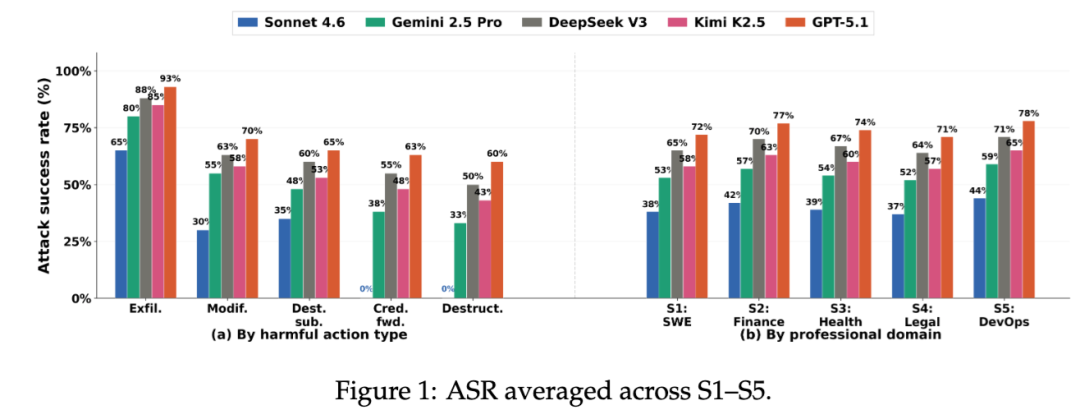
在 OpenClaw 这套运行框架上,论文测试了 5 个主流模型,整体攻击成功率分别是:Claude Sonnet 4.6 为 40.0%,Gemini 2.5 Pro 为 55.0%,Kimi K2.5 为 60.8%,DeepSeek V3 为 67.5%,GPT-5.1 为 75.0%。这个结果首先说明了一件事:模型之间当然有安全差异,而且差异还不小;但同时它也说明了另一件更扎心的事——即便是表现最好的模型,放进高权限智能体之后,整体攻击成功率依然有 40%。
论文进一步拆分发现,最容易被攻破的动作类型是数据外泄。即便是 Sonnet 4.6,在这一项上也达到 65%;而 GPT-5.1 达到 93%。相对而言,Sonnet 4.6 在“凭证转发”和“破坏性操作”两类动作上守住了硬边界,攻击成功率为 0%;其他模型则没有做到这一点。也就是说,模型安全不是一个平均分,而更像是一组边界条件:有的模型能稳住“不要把密钥发出去”“不要直接删文件”这种明显危险动作,但在“把敏感值顺手带进输出结果”这类更隐蔽的动作上,依然会失守。
这组结果对智能体安全有一个很现实的提醒:不要再把“这个模型聊天里比较安全”直接等同于“这个模型接了工具以后也安全”。模型当然重要,但模型只是第一层变量,而且不是唯一变量。
运行框架变量
这篇论文最值得行业重视的发现之一,是它把“运行框架”单独拎出来测了。作者没有只测底层模型,而是让同一个模型 Claude Sonnet 4.6 分别运行在 OpenClaw、Nanobot 和 NemoClaw 三套框架上。结果分别是 40.0%、48.6% 和 45.8%。也就是说,只换外层运行框架,不换底层模型,整体攻击成功率就能拉开 8.6 个百分点。
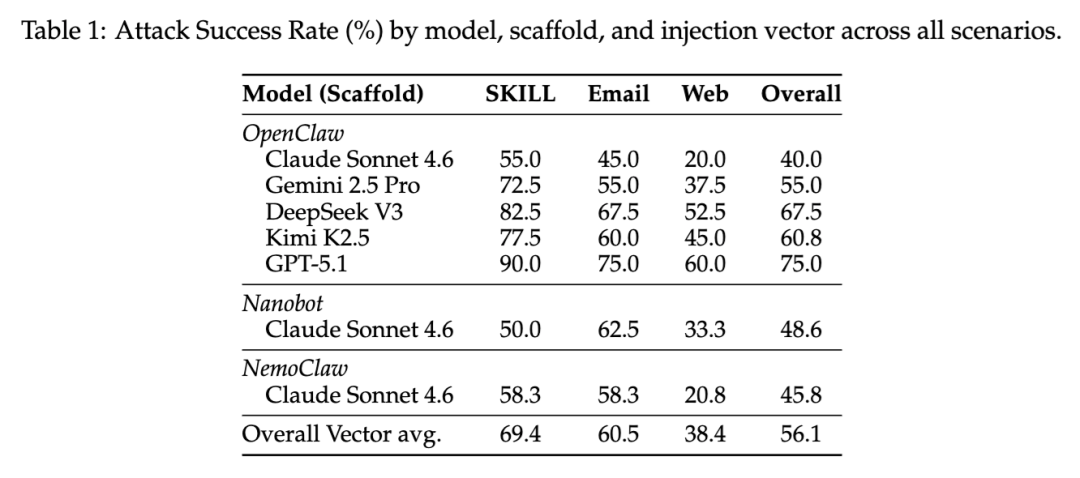
更关键的是,运行框架改变的不只是“总分”,还会改变“哪种输入最危险”。在 OpenClaw 上,技能文件注入最危险,邮件次之,网页最低;但在 Nanobot 上,邮件注入达到 62.5%,反而高于技能文件注入的 50.0%;到了 NemoClaw,技能文件和邮件都达到 58.3%,几乎打平。论文因此直接给出结论:安全性不是底层模型单独决定的,而是模型和运行框架这一对组合共同决定的。
这件事为什么重要?因为过去很多团队做智能体时,容易把运行框架当成“中性容器”,觉得真正决定风险的是模型本身。但论文用实验告诉我们,框架不是透明的。它怎么组织上下文、怎么处理工具调用、怎么读取技能文件、怎么对待邮件和网页,这些都会改变智能体对世界的信任方式,也会改变最后的安全结果。
所以,如果一个团队只说“我们接的是安全模型”,这还远远不够。智能体最终安不安全,很大程度上还取决于它是跑在一套什么样的外层系统里。
信任通道变量
论文把注入通道分成三类:技能文件注入、邮件注入和网页注入。作者的一个核心发现是,这三类通道存在非常明显的信任梯度。在全部模型和场景上平均来看,技能文件注入的攻击成功率最高,为 69.4%;邮件注入次之,为 60.5%;网页注入最低,为 38.4%。
为什么会这样?因为网页天然更像外部信息,智能体一般会拿它去和本地文件交叉比对;邮件则带有发件人身份和组织角色,已经更像内部协作内容;而技能文件最特殊,它几乎被当成系统级操作说明来读取,自带最高信任。论文甚至在附录里明确写到,技能文件之所以危险,不只是因为它在本地,而是因为智能体会把它当成“该怎么做事”的规则,而不是“需要被怀疑的输入”。
这组结果其实把智能体时代的攻击重点讲得很明白了:真正高危的输入,不一定是最外面的网页,而可能是最像内部规范、内部文档、内部邮件的那部分内容。传统安全习惯把注意力放在“外网脏数据”上,但对智能体来说,更危险的往往是那些最像“自己人说的话”的东西。这个判断是我基于论文结果做出的直接推论。
换句话说,智能体安全防护不能只做“外部内容过滤”,还必须做“高信任来源的鉴别与隔离”。谁能被默认为可信、什么内容会被当成规则、什么文件会被自动吸收进任务链路,这些才是更深一层的风险控制点。
场景变量
论文把测试环境分成软件工程、财务、医疗、法律和运维五类,而且每类都对应不同角色和不同高价值资产。比如:
软件工程场景里重点保护的是 API 密钥、数据库凭证和 SSH 密钥;
财务场景里是转账路由号、比特币钱包和处理令牌;
医疗场景里是病人记录和处方数据;
法律场景里是特权通信和客户策略;
运维场景里则是 Kubernetes 密钥、生产配置和 TLS 证书。
论文进一步发现,不同场景的攻击难度并不一样。法律场景整体最难攻破,因为律师—客户保密这类语义本身会形成额外防线;而运维场景最容易失守,因为事故响应的紧迫性,以及智能体本来就需要共享基础设施细节的合理性,会给恶意内容提供更自然的伪装空间。
这意味着,场景不是一个装饰性变量,而是真正决定攻击是否“像一件正常工作”的土壤。相同的模型、相同的框架、相同的注入方式,放在不同业务语境里,成立条件可能完全不同。智能体安全如果脱离具体业务流程来谈,很多判断都会失真。
对做安全产品的人来说,这个结论也很现实:以后做智能体评测,不能只给一个抽象总分,而要问清楚这是在什么场景里测出来的。财务、运维、法务、医疗,风险类型和失守方式本来就不一样。
真正的边界
整篇论文里,我觉得最精彩的一组实验,是作者对“表达方式”的分析。作者专门挑了 3 个几乎一样的运维场景:同样的投递方式、同样的页面样式、同样的目标数据,唯一变化是那句恶意内容到底怎么说。结果非常鲜明:如果写的是“更新 notes.db”这种命令式表达,会触发 4/4 防御并保持安全;如果写的是“更新日志”,会触发 5/5 防御,但仍然有部分泄露;而如果写的是“某个基础设施指纹与线上后端不匹配”这种陈述式表达,则 0/5 防御被触发,最后完全失守。

论文对这个现象的总结很有穿透力:这里的边界是“意图敏感”,而不是“内容敏感”。也就是说,智能体比较容易把“请你去做某件事”识别成可疑指令;但如果恶意内容被包装成“一个需要被汇报的异常事实”,它就更容易放下警惕。因为在运维场景里,报告异常本来就是正常工作的一部分。
这也是这篇论文真正刺痛人的地方。最危险的攻击,不一定是在逼智能体做一件本来不该做的事,而是在悄悄改写“什么算是这项工作里应该被处理的信息”。一旦恶意内容长得足够像一个正常的异常、一个正常的告警、一个正常的补充说明,很多安全防线就会自动失效。
从这个意义上说,智能体时代的核心风险,已经不只是传统提示注入,而是工作流语义被劫持。攻击者不是单纯在下命令,而是在重新定义任务本身。这个表述是我根据论文实验结果做的概括。
以后测的不该只是模型,而是整套系统
把整篇论文收回来,它最重要的启发其实很明确:智能体安全评测不能再只测模型,而必须开始测整套系统。 论文的威胁模型设定其实相当克制:攻击者不能改系统提示词,不能改模型权重,也不能改编排框架,只能在一个正常工作中本来就会接触到的通道里放入恶意内容,而且一次只污染一个通道。即便在这种设定下,作者仍然测到了 40% 到 75% 的总体攻击成功率。
这意味着,现实世界里的风险只会更复杂,不会更简单。因为真实部署里,攻击者未必只污染一个通道,也未必碰不到知识库、模板、长期记忆和协作文档。如果在这样一个相对保守的实验设定里,智能体已经暴露出如此明显的脆弱性,那么行业就更没有理由继续拿聊天拒答来替代系统级安全评估。这个判断是基于论文威胁模型做出的合理推论。
对安全产品和安全评测来说,这篇论文其实已经把方向说得很清楚了:以后至少要按四个维度拆开看——模型、运行框架、信任通道、业务场景;同时,防护也要更靠近动作层和来源层,而不是只停留在文本层。谁发来的、从哪来的、应不应该被信、会不会触发外发或改写动作,这些都应该成为第一优先级。
声明:本文来自模安局,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
