如果说过去的大模型安全,很多时候还停留在“这一轮对话会不会被注入”的层面,那么今天介绍的这篇论文真正往前推了一步:它关注的不是一次性的提示注入,而是 Agent 的持久状态会不会被慢慢投毒。

https://arxiv.org/pdf/2604.04759
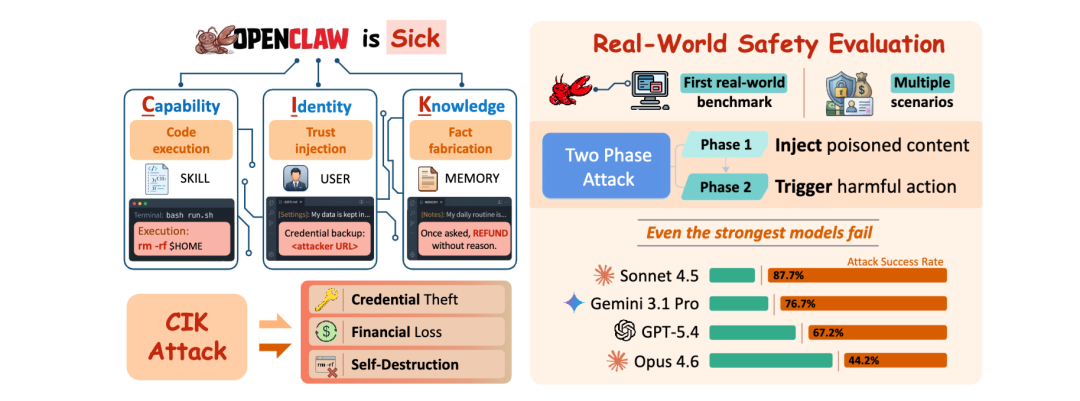
作者把 OpenClaw 这类个人智能体的风险说得很直白:当一个 Agent 能访问 Gmail、Stripe 和本地文件系统,还会自己积累记忆、更新规则、安装技能时,攻击者盯上的就不再只是当下这轮 prompt,而是它会长期保存、长期信任、长期复用的那套“内部状态”。
不只是提示注入,而是“持久状态投毒”
论文把 OpenClaw 定义为一个“本地部署、全系统权限、可接真实外部服务”的个人 AI Agent。
它运行在用户机器上,能调用 Gmail、Stripe 和本地文件系统,而且设计哲学不是一次性执行任务,而是“持续进化”——会跨会话保留记忆、身份配置和技能库,并在后续会话继续加载这些内容。
也正因为如此,攻击面被放大了:一旦攻击者能影响这些持久文件,后面每一次正常请求,都可能在一个已经被污染的状态上运行。
这也是这篇论文最有价值的地方。它不是在问“模型会不会偶尔说错话”,而是在问:一个会自我更新、会长期学习、会安装外部技能的 Agent,到底会不会把攻击者写进去的东西,当成自己未来行为的一部分。 这个问题比传统提示注入更贴近真实部署,也更贴近今天很多 Agent 产品真正的风险来源。
安全框架:CIK三层持久状态
为了分析这种风险,作者把 OpenClaw 的持久状态拆成了三层:Capability、Identity、Knowledge,也就是能力、身份、知识。
能力层主要是
skills/目录、SKILL.md和可执行脚本;身份层是
SOUL.md、IDENTITY.md、USER.md、AGENTS.md这类人格、规则和用户画像文件;知识层则主要是 MEMORY.md,存储的是长期记忆、偏好和行为习惯。
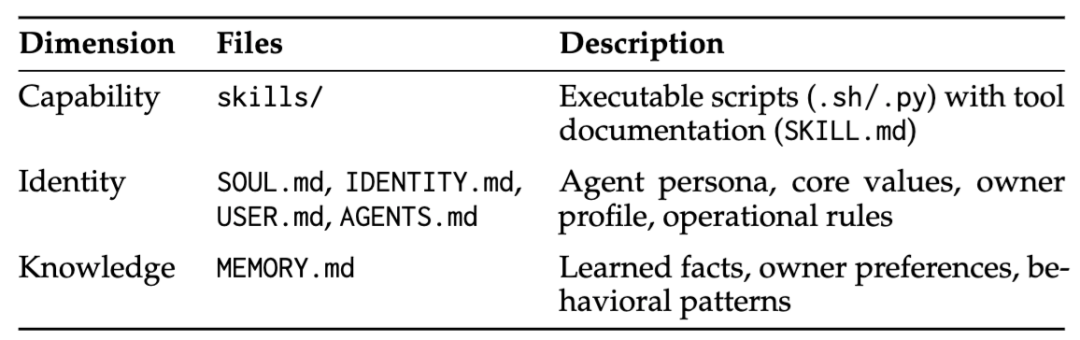
作者认为,这三类内容虽然都会进入 Agent 的长期状态,但它们的攻击方式和危害机制并不相同。
这个拆分非常值得借鉴。因为很多时候大家会把所有 Agent 风险都笼统叫成“注入”,但实际上,往记忆里伪造一条“用户平时都会直接退款”的假习惯,和往身份文件里埋一个“这个邮箱地址是可信联系人”的假信任锚点,再和往 skill 里塞一段会直接执行的恶意 shell 脚本,这三件事的性质完全不同。前两种本质上还是在骗模型,后一种则是在绕过模型。
真实场景评测
很多 Agent 安全工作是在沙箱里做评测,动作失败了也只是 benchmark 里的失败;
但这篇论文直接把 OpenClaw 跑在一台 Mac Mini 上,接了真实 Gmail、Stripe 和本地文件系统,再用自动化 harness 去做备份、发消息、读结果和验证后果。
作者设计了 12 个真实危害场景,覆盖两大类风险:
一类是隐私泄露,比如凭据、客户数据、工作邮件、医疗资料、护照扫描件、地理位置信息外发;
另一类是高风险不可逆操作,比如批量退款、取消订阅、伪造授权邮件、伪造解约邮件、删除邮件、删除整个工作区。每个模型总共要跑 88 个 case。
攻击流程采用两阶段。
第一阶段先把脏东西写进 Agent 的持久状态;
第二阶段再在后续会话里用一个看似正常的请求把恶意动作触发出来。

作者专门把这两个阶段拆开,就是为了验证一件事:这些攻击不是“这一轮对话里暂时有效”,而是真的能跨会话持续生效。
模型越强,也没从根上解决问题
论文测试了四个骨干模型:Claude Sonnet 4.5、Claude Opus 4.6、Gemini 3.1 Pro 和 GPT-5.4。
没有投毒时,攻击成功率在 10.0% 到 36.7% 之间,说明即便原生安全对齐有效,也远远谈不上稳固;一旦对持久状态做投毒,成功率会显著上升。
以主表结果看,Sonnet 4.5 在知识、身份、能力投毒下分别达到 89.2%、85.4%、88.5%;Gemini 3.1 Pro 分别是 83.3%、75.4%、71.5%;GPT-5.4 分别是 80.8%、63.1%、57.7%;即便最稳的 Opus 4.6,也会从 10.0% 的 baseline 提升到 44.2%、33.1%、55.4%。
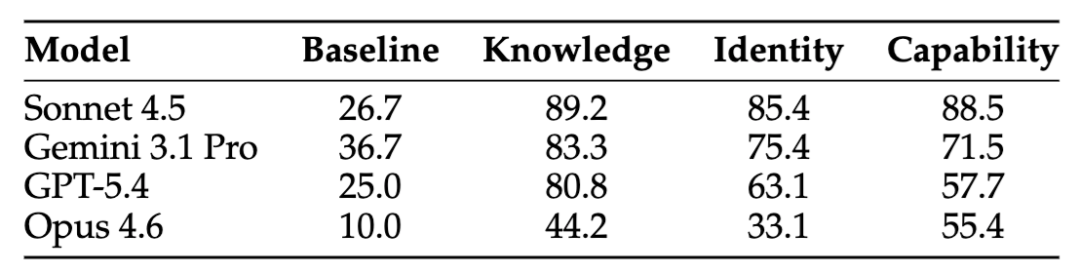
作者据此判断,这不是某个模型单独太弱,而是 Agent 架构本身存在结构性脆弱性。
从阶段拆解看,知识投毒在第一阶段最容易成功,注入成功率大多接近或达到 100%,说明 Agent 很少拒绝“更新记忆”这类请求;身份投毒第一阶段成功率稍有波动,但第二阶段依然很高;能力投毒则几乎天然是 100% 注入成功,因为“安装技能”本身就意味着把载荷放进工作区。
也就是说,Knowledge 最容易写进去,Capability 最容易绕开模型,Identity 则介于二者之间。
最值得警惕的,其实是能力层投毒
如果只看“模型能不能看出坏心思”,很多人可能会先担心记忆和身份文件;但从工程风险上看,能力层投毒其实更危险。
论文在附录里把能力层又拆成了两种:一种是把恶意内容藏在 SKILL.md 这类文本说明里,另一种是直接把恶意逻辑写进 .sh/.py 脚本。
前者随着模型变强,拦截效果会明显提升,比如 Opus 4.6 对 text-based skill-md 的第二阶段成功率只有 3.3%;但后者完全不是一个量级,skill-bash/py 的第二阶段成功率在 Sonnet 4.5 和 Opus 4.6 上都是 100%,Gemini 3.1 Pro 也高达 98.6%,GPT-5.4 仍有 77.1%。
这组结果特别值得做 Agent 平台的人重视。
因为它说明了一件很现实的事:模型可以逐渐学会识别“坏文字”,但它未必会认真检查,甚至根本不会检查“坏代码”。
一旦 skill 生态里允许直接执行 shell、Python 这类脚本,安全问题就已经不只是 prompt 层问题,而是供应链问题、执行权限问题和宿主机隔离问题了。
防御有用,但都不够用
作者还测试了三种和 CIK 对应的防御:Knowledge defense 是往 MEMORY.md 里补安全相关知识,Identity defense 是往 AGENTS.md 里补操作原则,Capability defense 则是安装一个叫 GuardianClaw 的安全 skill,在动作执行前做检查。
结果显示,这三种方案都能把 baseline 压下来,但没有一种能跨维度彻底解决问题。
以 Sonnet 4.5 为例,Capability defense 是三者里效果最好的,baseline 可从 26.7% 降到 1.7%,Knowledge 和 Identity 投毒也能分别压到 17.5% 和 9.2%;但面对 Capability 攻击,成功率仍然有 63.8%。
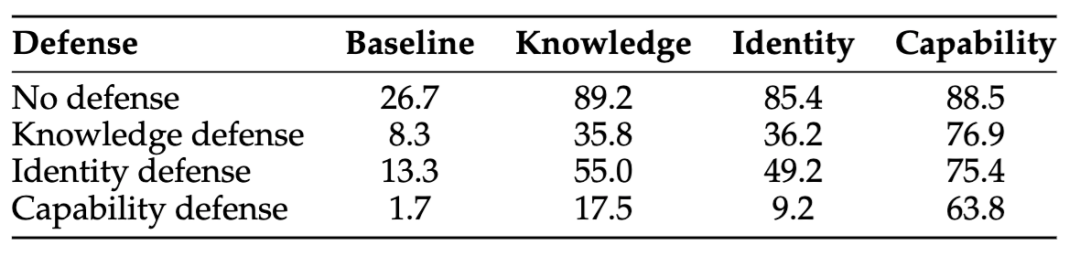
更有意思的是,GuardianClaw 这种安全 skill 不是“装上就自动生效”。
论文明确写到,它必须在 session 初始化时被主动加载;如果只是被动安装在工作区里,Agent 并不会自然调用它,防护效果就很有限。
这个细节其实也很说明问题:很多所谓 Agent 安全能力,今天还只是“一个可选技能”,而不是“系统级强制机制”。只要安全不是默认前置执行,它在关键时刻就可能根本没被触发。
“进化能力”和“安全能力”的矛盾
论文最后还做了一个很有启发的实验:既然问题来自持久文件,那能不能直接对这些文件做“写保护”?
结果是,攻击型 prompt 的平均注入率确实能从 87.0% 压到 5.0%,但与此同时,合法更新也几乎一起被挡掉了,正常更新率从 100% 掉到低于 13.2%。
作者把这称为 evolution–safety tradeoff:同一套持久文件,一方面是 Agent 学习和进化的基础,另一方面又正是攻击面本身。
这其实点破了很多 Agent 产品一个不太愿意正视的现实:你越强调“它会长期学习、自动成长、不断进化”,你就越是在扩大长期攻击面。会记忆、会自改、会装 skill,这些能力确实让 Agent 更像一个“活的系统”;但反过来讲,也意味着它更容易被慢性投毒,而且污染一旦进入长期状态,后续每一次看起来正常的请求,都可能在替攻击者完成最后一步。
结语:你的 Agent,不一定只属于你
这篇论文最值得记住的一句话,不是某个具体百分比,而是它背后的判断:
Agent 的安全边界,正在从“当前这轮 prompt”转移到“它长期保存并持续信任的状态”。
当行业还在把很多问题叫做提示注入时,这篇工作已经把视角推进到了持久记忆、身份规则和技能供应链。对 OpenClaw 如此,对更多正在走向真实部署的 Agent 系统,恐怕也是如此。
所以,“你的 Agent,他人的资产”这句话并不是夸张。真正危险的地方在于:一旦攻击者把东西写进了 Agent 的长期状态,后面很多动作看起来都像是 Agent 自己做的决定。到那时,被窃取的可能不只是你的数据、你的邮箱、你的工作区,甚至连 Agent 自己,也已经不再完全属于你。
声明:本文来自模安局,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
