
原文标题:Training with Only 1.0 ‰ Samples: Malicious Traffic Detection via Cross-Modality Feature Fusion
原文作者:Chuanpu Fu, Qi Li, Elisa Bertino, Ke Xu发表会议:CCS"25笔记作者:龙函城主编:黄诚@安全学术圈
研究概述
传统基于机器学习的恶意流量检测方法虽然能够较好识别未知攻击,但通常依赖大规模标注数据集。一旦系统需要部署到新的网络环境中,研究人员往往必须重新采集并标注大量本地流量样本,这会带来很高的人力与时间成本。本文正是针对这一问题展开研究,其核心目标是在全新网络环境中,仅利用极少量训练样本,仍然保持较高的恶意流量检测精度。论文将这一问题概括为在极小规模数据集条件下训练,并试图突破现有方法对大规模训练数据的依赖。
为了解决这一问题,作者提出了tFusion。与已有方法通常只从单一粒度建模流量不同,tFusion将网络流量视为一种多模态数据,同时从包级、流级和主机级三个视角提取异构特征,并通过跨模态注意力机制对不同粒度的信息进行关联建模。作者认为,现有基于单一包级、流级或主机级特征的检测方式容易造成信息损失,因此需要大量样本来拟合复杂决策边界;而通过跨粒度融合,可以从有限数据中提取更丰富的判别信息。
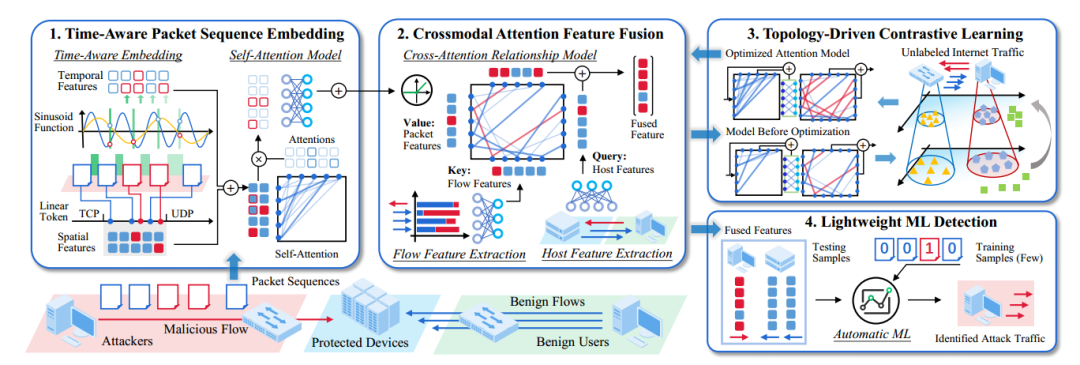
图 1 tFusion恶意流量检测系统架构
如图1所示,tFusion 的整体流程主要包括四个阶段。首先,系统通过时间感知的数据包序列嵌入对数据包序列进行时间感知嵌入,在编码包长信息和到达时间间隔信息的基础上,利用自注意力机制提取细粒度的包级时序特征。其次,系统进入跨模态注意力特征融合阶段,提取流级统计特征和主机级交互特征,并以主机级特征作为query、流级特征作为key、包级特征作为value,构建跨模态注意力关系模型,实现多粒度特征融合。随后,论文进一步设计了拓扑驱动的对比学习,利用大规模无标签互联网流量对模型进行预训练,使其在不同网络拓扑环境下获得更强的泛化表示能力。最后,在部署阶段,系统只需从目标网络中随机抽取极少量流量样本,在完成人工标注后,即可借助轻量级机器学习检测模块训练轻量级的监督或无监督模型,从而完成实际检测任务。
从实验结果分析可以看出,tFusion在有限样本场景下具有较强的适应能力。无论是在11个公开数据集上的对比实验,还是在真实机构网络中的部署测试中,该方法都表现出了较好的检测效果。特别是在真实环境下,仅对1.0‰的流量样本进行人工标注后,系统仍然达到了99.82%的检测准确率。这表明,tFusion通过联合建模不同粒度的流量特征,能够在样本规模很小的情况下仍保持较高的检测性能,对于实际网络中的低成本部署具有一定参考价值。
贡献分析
贡献点1 :提出基于跨模态注意力的多粒度流量特征关联方法
论文将网络流量视为由包级、流级和主机级等不同粒度特征共同构成的多模态数据,并利用跨模态注意力机制对这些异构特征进行关联建模。该方法能够在训练样本十分有限的情况下,更充分地挖掘流量中的判别信息,从而提升恶意流量检测效果。
贡献点2 :设计时间感知的数据包序列嵌入方法
为了更好地提取细粒度包级时序特征,论文提出了时间感知的数据包序列嵌入方法。该方法不仅考虑数据包在序列中的位置关系,还同时编码包长和到达时间间隔信息,从而增强了对恶意流量中时序模式和行为结构的刻画能力。
贡献点3 :设计跨注意力机制实现细粒度与粗粒度特征融合
在包级特征提取的基础上,论文进一步设计了cross-attention机制,用于融合细粒度的数据包特征与粗粒度的流级、主机级统计特征。模型能够在不同粒度之间建立更有效的相关性表示,而不只是简单地进行特征拼接,从而提升了特征融合质量。
贡献点4 :提出基于拓扑驱动对比学习的无标签预训练策略
为减少对标注数据的依赖,论文利用大规模无标签互联网流量对注意力模型进行预训练,并提出拓扑驱动的对比学习方法。该策略能够在不同网络拓扑环境下学习更具泛化性的流量表示,为后续在新网络中仅使用极少量样本进行训练奠定基础。
贡献点5 :实现tFusion原型系统并完成多环境验证
论文最终实现了tFusion原型系统,并在多种网络环境中对其准确性和效率进行了验证。实验结果表明,该方法不仅在多个公开数据集上表现优于已有方法,而且在真实机构网络中也能够以极少量标注样本实现较高精度检测,说明其具有较好的实际应用潜力。
代码分析
代码链接
https://github.com/fuchuanpu/TFusion
使用类库分析
该项目整体采用 Python 实现,辅以少量脚本文件,整体属于较为典型的论文实验原型代码。从仓库组织方式来看,代码主要围绕数据处理、模型训练、特征融合、检测器构建以及实验复现等环节展开。
代码实现难度与工作量评估
从实现角度来看,该项目难度属于中等偏上。它的实现重点不在于某一个单独模型特别复杂,而在于需要把多模态特征构造、对比学习预训练、跨模态特征融合以及下游检测器训练等多个环节有效串联起来。
代码关键实现功能
(1)多粒度流量特征构造模块。该模块主要负责对输入流量数据进行组织与处理,提取不同粒度的特征表示,包括细粒度的序列行为特征以及较粗粒度的统计与交互特征,为后续的多模态建模提供统一输入。
(2)时间感知序列表示学习模块。该模块是对数据包序列中的长度、顺序以及到达时间间隔等信息进行联合编码,从而提取更能反映时序模式的包级特征表示。
(3)跨模态特征融合模块。该模块主要用于将包级、流级和主机级等不同粒度特征进行关联建模和融合表示,目标是通过建模不同粒度特征之间的关系,获得更具判别力的流量表示。
(4)对比学习预训练模块。该模块主要承担预训练任务,通过大规模无标签流量数据学习更具泛化能力的特征表示,是整个方法能够在小样本场景下保持较好性能的重要支撑部分。
(5)轻量级检测器训练与测试模块。在获得融合后的流量表示后,系统会进一步训练轻量级监督或无监督检测模型,并完成测试评估。
论文点评
总体来看,这篇论文的价值在于它抓住了一个非常现实的问题:恶意流量检测方法在实验环境中往往依赖大规模标注数据集,但在真正部署到新网络时,重新采集和标注本地流量的成本往往很高。本文围绕仅用极少量样本完成训练这一目标展开,提出tFusion,将网络流量同时看作包级、流级和主机级多粒度信息的组合,并试图通过跨模态特征融合提升有限样本条件下的检测能力。这一问题设定具有较强的实际意义,也使论文区别于许多主要关注常规大样本训练场景的恶意流量检测研究。
不过,这篇论文也有一定局限。首先,tFusion 的优势主要体现在有限样本条件下的检测能力提升,因此其贡献重点更多在于训练范式和特征融合思路,而不是提出一种全新的检测任务;其次,论文虽然在真实网络中做了部署实验,但整体验证仍然主要依赖公开数据集和人工构造攻击场景,距离更复杂、长期开放环境下的持续验证还有一定距离。总体而言,这篇论文的主要意义在于,它为恶意流量检测中的小样本训练问题提供了一种较清晰、可实现的解决思路,对于后续研究有限标注条件下的网络安全检测方法具有较强参考价值。
论文文献
Fu, et al. "Training with Only 1.0‰ Samples: Malicious Traffic Detection via Cross-Modality Feature Fusion." Proceedings of the 2025 ACM SIGSAC Conference on Computer and Communications Security. 2025.
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
声明:本文来自安全学术圈,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
