基本信息
原文标题:VulKey: Automated Vulnerability Repair Guided by Domain-Specific Repair Patterns
原文作者:Jia Li、Zhuangbin Chen、Yuxin Su、Michael R. Lyu
作者单位:香港中文大学;中山大学
关键词:自动化漏洞修复(AVR)、修复模式、大语言模型(LLM)、CWE 专家知识、修复策略抽象
原文链接:https://arxiv.org/abs/2605.01769
开源代码:暂无
论文要点
论文简介:随着软件系统日益复杂,漏洞数量在近年出现了爆发式增长。据 NVD 统计,2024 年一年就有 40009 个漏洞被公开披露,同比增长 38.83%。这些漏洞一旦未被及时修复,轻则造成数据泄露,重则引发系统级瘫痪,而传统的人工修复方式需要安全专家花费数百小时来定位根因、验证补丁、兼容代码库,成本极高。为此,学术界提出了"自动化漏洞修复(Automated Vulnerability Repair,简称 AVR)"这一研究方向。
本文作者敏锐地发现,尽管基于大语言模型(LLM)的 AVR 方案近年来迅速崛起,但它们在"整合结构化安全领域知识"方面存在天然短板——要么是简单地把 CWE 编号塞进提示词,效果近乎无;要么是堆砌几个固定示例,泛化能力薄弱。
作者因此提出 VulKey,用一种"三级层次化抽象"把专家修复经验结构化为可复用的修复模式,再通过两阶段流水线指导 LLM 生成补丁。在真实世界 C/C++ 数据集 PrimeVul 上,VulKey 取得了 31.5% 的修复准确率,比最强基线高出 7.6 个百分点,相较 VulMaster 提升 3.6 倍、较 GPT-5 提升约 3 倍;同时在 Java 基准 Vul4J 上也展现出跨语言、跨模型的强泛化能力。
研究目的:本文要解决的核心问题是——如何让大语言模型真正"吃透"并"用好"那些沉淀在 CWE、CVE、NVD 等漏洞追踪体系中的结构化安全专家知识,从而生成更准确、更具安全语义的补丁。作者希望提出一种既比"贴 CWE 标签"更有信息量、又比"塞入完整补丁示例"更具普适性、且比"AST 语法模板"更具安全语义的修复知识表达方式,并在此基础上构建一个可落地、可泛化的自动化漏洞修复框架。
研究贡献:作者在文中强调,本工作的创新贡献主要体现在三个层面。
其一,在知识表达层面,首次为 CWE 专家知识提出了"三级层次化抽象",即以 CWE 类型为顶层分组,以语法动作(Action)作为中间层的编辑算子,以语义关键元素(Key Element)作为底层的安全原语或约束,从而既保持了通用性又具备足够的安全语义粒度,彻底摆脱了传统方法在模板覆盖率和语义表达能力上的两难困境。
其二,在方法设计层面,提出并实现了 VulKey 这一新型两阶段 AVR 流水线,将"上下文感知的专家知识匹配器"与"经过渐进式微调的代码生成模型"有机结合,让 LLM 首次能够在推理阶段被明确地"对齐"到安全领域的修复策略上。
其三,在评估层面,作者在 C/C++ 的 PrimeVul 和 Java 的 Vul4J 两个真实世界基准上做了系统、全面的对比与消融,证明 VulKey 在两种语言、多种 backbone 模型下均能取得 SOTA 表现,为后续 AVR 研究确立了新的性能参考线。
研究背景
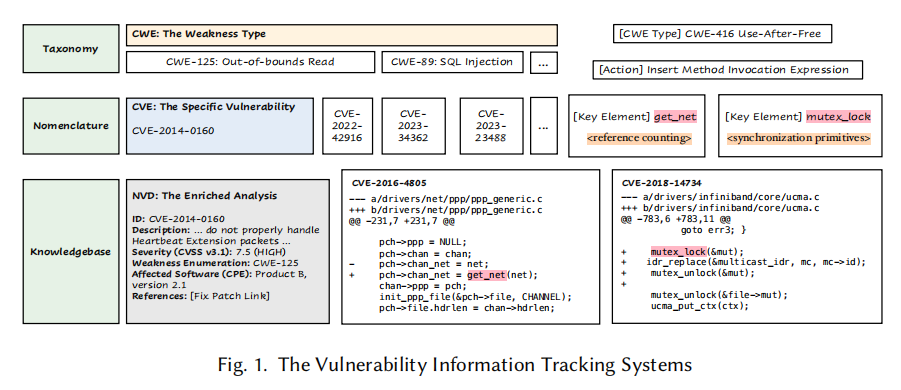
软件漏洞和普通程序错误看似相似,实则有着本质区别,这也是整篇论文立论的起点。普通的程序 Bug 多半是功能层面的逻辑错误,开发者往往可以借助失败的单元测试快速定位根因并写出局部补丁;而漏洞则常常是架构层面的、跨函数的、甚至跨组件的安全设计缺陷,修复时需要理解完整的攻击面、最小权限原则、并发安全、内存生命周期等一系列安全设计思想。作者用经典的 TOCTOU(检查时与使用时)竞态条件举例:一段代码先 access("user_file.txt", W_OK) 做权限校验,再 open("user_file.txt", O_WRONLY) 打开文件——这两行代码各自看都没毛病,但二者之间的时间窗被攻击者用符号链接替换文件就足以酿成提权漏洞;修复方案也并非简单地增加判断,而是要用 seteuid 等操作系统原语进行安全语义层面的重构。

更棘手的是,漏洞修复缺少"明确的验收用例"。Bug 修复可以跑测试,测试过了就算修好;但安全补丁没有现成的 PoC 测试作为验证 oracle,补丁必须在消除整类弱点的同时不引入回归,这个门槛远比普通测试要高。因此,诸如 ChatRepair、ThinkRepair 这类"生成—测试—反馈"的迭代式 APR 框架在漏洞修复场景里基本失效,AVR 必须回归到"以专家领域知识驱动"的范式。幸运的是,CWE、CVE、NVD 等漏洞追踪体系已经沉淀了海量的结构化专家知识:从最上层的弱点分类(CWE),到具体实例的唯一编号(CVE),再到知识库层面的详细分析与修复补丁链接(NVD),形成了一条完整的信息链。这条信息链正是 AVR 可以利用的"金矿",也是 VulKey 要撬动的杠杆。
前期研究与动机
作者并没有直接给出解法,而是先通过两组前期实验,系统地证明了已有方法"吃不透"专家知识的三大症结,这也是 VulKey 设计哲学的来源。第一组实验试图复现最朴素的做法——把 CWE 类型作为前缀拼接到输入里再微调模型。结果让人大跌眼镜:在 StarCoderBase-15B 和 Qwen2.5-Coder-32B 两个强 backbone 上,加了 CWE 前缀的精确匹配率反而从 23.9% 掉到 23.6%、从 23.2% 掉到 22.5%,几乎看不到任何增益。作者认为,这是因为粗粒度的类型标签并没有定义出明确的"策略学习目标",模型被迫去隐式推断"类型→修复策略"的映射,往往以失败告终。
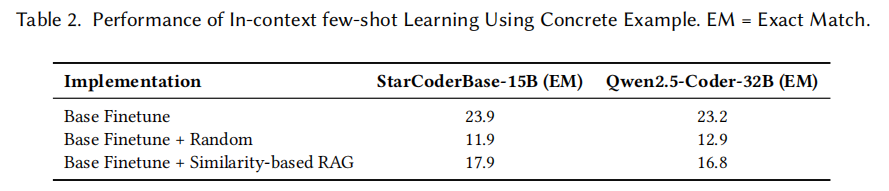
第二组实验则把"概念级标签"升级为"具体示例",模仿 VulMaster 的做法,把同一 CWE 下的若干真实漏洞—修复对作为 few-shot 示例塞进提示词,并分别尝试随机选取和基于 BM25 代码相似度的 RAG 检索。结果同样不理想:随机策略让精确匹配率从 23.9% 骤降到 11.9%,相似度检索虽然好一些但也只有 17.9%,仍然低于基础微调。作者分析,完整补丁示例虽然"带语义",但也带着大量项目特有的变量名、自定义类型和边缘逻辑,这些"噪声"会让模型把注意力放在模仿表层代码上,而不是抽象出真正的修复原则;而且 CWE 分类下的修复策略本身就具有多样性,单纯用几个具体示例远不足以覆盖所有模式。
除此之外,作者还回顾了传统程序修复领域流行的"语法模板"路线,例如 NTR 等工作把修复策略抽象为 Insert Missed Statement、Mutate Conditional Expression 这类基于 AST 的动作。这种表达方式能剔除项目噪声,但又陷入另一个极端——同一个语法动作可能对应多种截然不同的安全机制。作者手工分析了 PrimeVul 中 249 个 CWE-787(越界写)和 167 个 CWE-416(Use-After-Free)案例后发现,超过一半的 CWE-787 修复都属于 "Insert Range Checker",但具体要检查的约束却大相径庭——有的是长度边界、有的是图像高度、有的是协议包限制、有的是整数溢出;CWE-416 的主力修复动作 "Insert Method Invocation Expression" 背后则藏着"加锁同步"和"引用计数"两种完全不同的安全原语。如果只记语法动作,不记语义关键元素,模型就无法获得足够精确的修复指引。正是这些一针见血的观察,推动作者总结出 VulKey 的设计准则:修复知识的表达必须同时具备"紧凑的动作抽象"和"具体的语义约束",而且要配套一个"学得会"的对齐选择机制。
核心方法
VulKey 的核心创新可以用一句话概括——把每一条历史漏洞修复经验压缩成一个 (CWE 类型, 语法动作, 语义关键元素) 的三元组,再让模型学会为新漏洞"挑对"三元组,最后用它来引导补丁生成。在这个三元组里,CWE 类型扮演顶层分组的角色,例如 CWE-416(Use-After-Free)或 CWE-787(Out-of-bounds Write);语法动作是一个离散的编辑算子,描述"怎么改",例如 Insert Null Pointer Checker、Insert Release Resource、Mutate Conditional Expression 等;而语义关键元素是从补丁 diff 的新增行中抽取出来的一段短小连续片段,表达"引入什么样的安全原语或约束",例如 mutex_lock、get_net、kfree(a)、ret < 0 等。三者相加,就同时具备了类型分组的宏观视角、语法动作的通用骨架以及语义关键元素的精细约束。
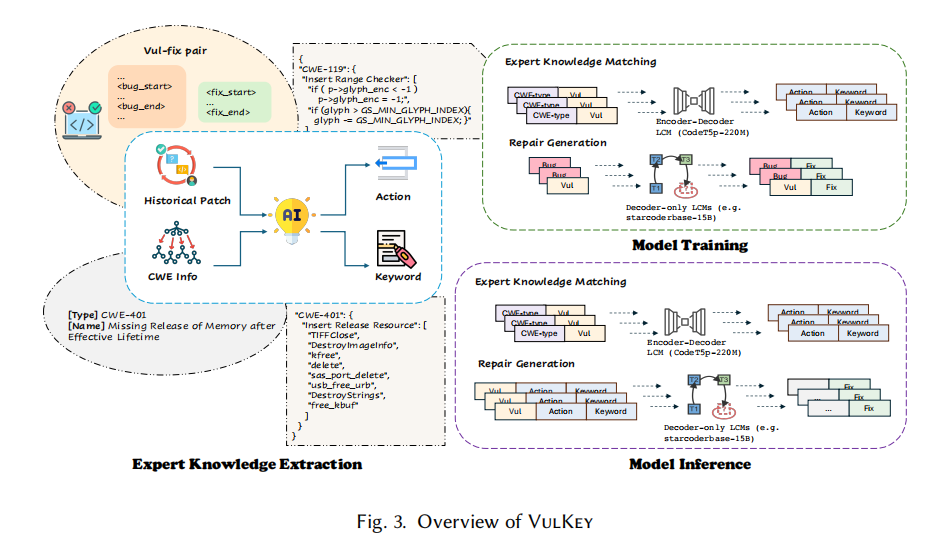
为了高效地抽取这些三元组,作者用 GPT-4.1 充当"专家知识提取器",以 difflib 生成的行级代码差异、CVE 描述、CWE 类型为输入,并在提示中提供一个初始的动作候选清单(包括 Insert Variable、Insert Memset、Insert Release Resource 等 18 个常见算子)。如果已有动作无法覆盖,LLM 可以自由提出新的动作标签,作者再做语义聚类与合并,从而让动作空间保持"紧凑而可扩展"。对于关键元素的抽取,作者还设定了三条严格规则:首先是"语义聚焦",优先选取安全关键 API、核心守卫谓词以及安全相关的类型或标志;其次是"最小自包含",选取能独立表达安全机制的最小片段,通常是一个表达式或一条简单语句;最后是"降噪",过滤掉日志、格式化、临时变量等低信号内容。为保证关键元素严格来自补丁,作者还加了一条"程序化子串校验",如果生成的关键元素不是新增行的连续子串则重试三次,失败即丢弃。
在模型训练与推理阶段,VulKey 采用了两阶段流水线。
第一阶段是"专家知识匹配",作者以 CodeT5p-220M 这一编码器—解码器结构作为 backbone,把 (CWE 类型, 漏洞函数) 映射到 (动作, 关键元素),通过最小化交叉熵损失完成训练;推理时采用 beam=10 的束搜索,生成 Top-10 候选修复模式。作者选择编码器—解码器架构的理由也很务实:漏洞修复既要理解代码语义,又要产出自然语言式的修复策略,这种"代码到描述"的任务 CodeBERT、CodeLlama 等模型并不擅长。
第二阶段是"修复代码生成",作者采用 decoder-only 大模型作为 backbone,先用 Transfer 数据集(约 10 万条 Java Bug 修复对)做第一轮微调学习通用修复范式,再用 PrimeVul 中的 3789 条漏洞修复对做第二轮微调以聚焦安全语义;推理时把前一阶段产出的 10 条修复模式逐一注入 prompt,采用温度采样生成候选补丁。值得一提的是,修复生成器在训练期间并不看动作和关键元素,知识只在推理期作为"后注入"引导,这种解耦设计允许作者独立升级匹配器、动作清单或生成 backbone,而无需重新训练庞大的代码生成模型。
实验评估
作者围绕四个研究问题设计了系统实验。
数据集方面,第一轮微调使用 Transfer 数据集的 10 万余条 Java Bug 修复对;第二轮微调和主评测使用 PrimeVul,这是一个从 BigVul、CrossVul、CVEfixes、DiverseVul 四个主流 C/C++ 漏洞数据集中提炼而来的升级版,经过严格的去重和时间切分后得到 3789/480/435 的训练/验证/测试划分,涵盖 140 种 CWE;跨语言泛化实验在 Java 数据集 X1 上训练匹配器,并在 Vul4J 基准上评测 35 个单 hunk 漏洞。评测指标为精确匹配率(Exact Match,EM),即 100 条生成补丁中只要至少有一条在去空格去注释后与标准补丁 token 序列完全一致就算修复成功。
基线方面,作者囊括了 template-based APR 的 NTR、learning-based AVR 的 VulRepair 和 VulMaster、四个通用大代码模型(CodeLlama-70B、StarCoderBase-15B、DeepSeek-Coder-V2-Lite-16B、Qwen2.5-Coder-32B)以及闭源的 GPT-5 和 GPT-4.1。实验环境为 8 × A100 40G GPU,使用 LoRA + 位量化(QLoRA)做高效微调。
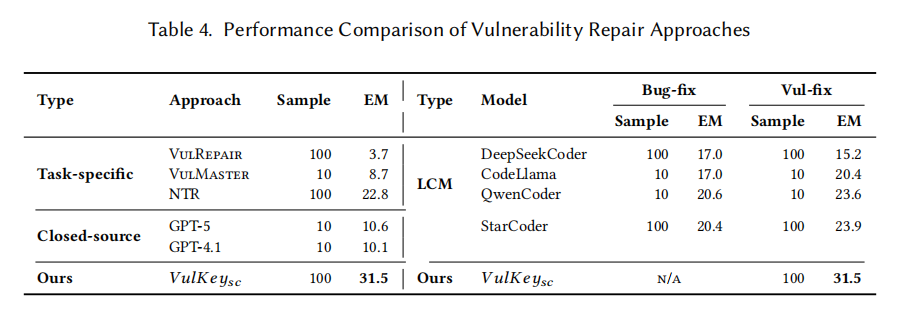
在 RQ1 的整体性能对比中,VulKey 以 StarCoderBase-15B 作为生成 backbone 取得了 31.5% 的 EM,相较最强基线 StarCoder+Bug+Vul(23.9%)绝对提升 7.6 个百分点,相对提升约 32%;相较任务专用的 VulRepair(3.7%)高出 8.5 倍,相较 VulMaster(8.7%)高出 3.6 倍,相较 GPT-5(10.6%)高出 3 倍。两阶段微调策略本身也被证明是普适有效的:CodeLlama 在加入漏洞修复数据后从 17.0% 提升到 20.4%、QwenCoder 从 20.6% 提升到 23.6%、StarCoder 从 20.4% 提升到 23.9%。
此外,在所有参与对比的 15 个 CWE 类别中,VulKey 均获得了 EM 提升,其中 Double Free(CWE-415)提升幅度高达 40 个百分点,Path Traversal(CWE-22)、Integer Underflow(CWE-191)、Type Conversion Error(CWE-704)、Access Control(CWE-264)等此前"颗粒无收"的类别也成功产生了修复。作者还邀请三位拥有 5 年以上安全审计经验的专家,对 435 个测试用例的语义等价性做了人工复核,VulKey 的语义等价率达到 43.2%,比最强基线 StarCoder+Bug+Vul 的 36.5% 高出 6.7 个百分点,Cohen"s κ 达到 0.84 级别的"近乎完美"一致度,进一步印证了 EM 提升并非取巧。
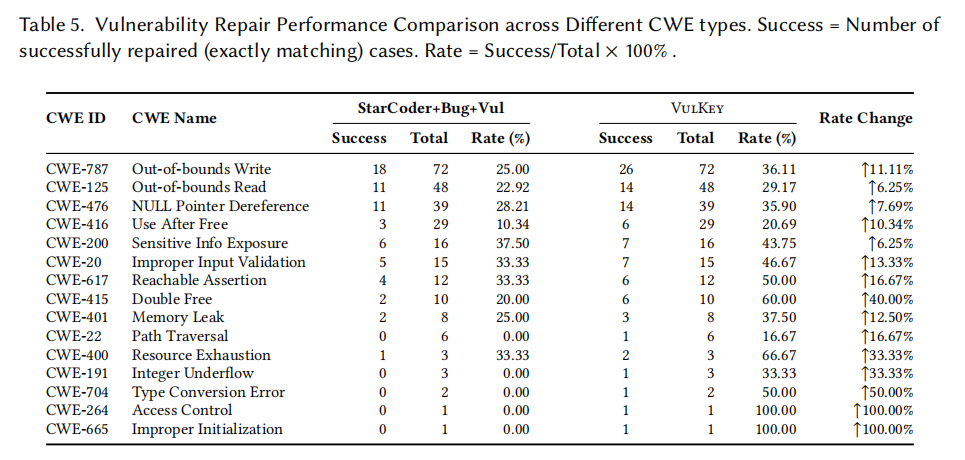
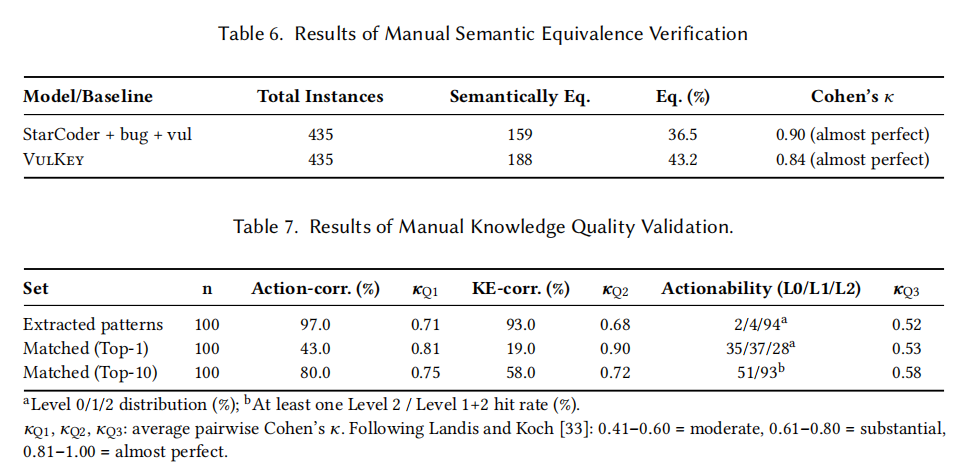
在 RQ2 的知识质量验证中,作者采样 100 条抽取模式与 100 条匹配模式交给三位标注员打分。抽取模式的动作正确率达 97%、关键元素正确率 93%、94% 被评为"明显可操作"(Level 2),说明 GPT-4.1 驱动的抽取管线确实能产出高质量模式;Top-1 匹配结果相对保守,但 Top-10 的动作正确率提升到 80%,关键元素正确率达到 58%,L1+L2 命中率达到 93%,说明多候选策略能显著缓解单点预测偏差。作者还报告了第一阶段的 Recall@10 与 Precision@10 指标:整体 (Action+Key Element) 的 Recall@10 为 56.8%、Precision@10 为 16.4%;动作单独评测 Recall@10 可达 82.3%;关键元素单独评测 Recall@10 为 64.6%,进一步说明多候选配合专门匹配器是吸收专家知识的有效路径。
讨论分析
为了厘清各个组件的实际贡献,作者在 RQ3 做了系统的消融实验。结果显示,如果在专家知识匹配阶段去掉 CWE 类型仅靠漏洞函数做输入,EM 会从 31.5% 跌到 26.4%;如果在代码生成阶段去掉关键元素,EM 掉到 27.6%;去掉语法动作则掉到 27.1%。这三组数字说明:CWE 类型是匹配器的"定盘星",它把搜索空间切分到具体的 CWE 大类内;而动作与关键元素则扮演互补角色,动作提供粗粒度语法骨架,关键元素提供细粒度语义约束,只有两者协同,才能把 LLM 的生成搜索空间精准压缩到"正确答案的邻域"。作者还用韦恩图进一步展示:完整 VulKey 独占修复的样本数高达 78,远高于仅用动作或仅用关键元素的单独版本,也远高于仅在 Bug/Vul 数据上微调的 StarCoder 基线,说明三级抽象带来的不是简单叠加而是真正意义上的协同增益。
跨语言泛化方面,作者把匹配器用 Java 数据集 X1 重新训练,在 Vul4J 上评测时 VulKey_sc 取得了 18 条成功修复,相较 VulRepair(4 条)提升 350%、相较 VulMaster(9 条)提升 100%、相较 NTR(11 条)提升 64%,三项全部 SOTA。更重要的是,无论 backbone 换成 StarCoder 还是 Qwen2.5-Coder,专家知识注入都能稳定带来 20%–50% 的相对增益,这说明 VulKey 的三级抽象并非绑定某个特定 LLM,而是一种具备普遍适用性的知识引导范式。
作者也没有回避方法的局限。通过人工复核 100 个失败案例,他们发现主要瓶颈集中在四类情况:缺失跨函数上下文(35 例,如结构体字段定义在函数外)、无法正确调用项目自定义 API(24 例)、对精确字符串或常量过度敏感(10 例)、复杂逻辑条件难以推理(9 例),其余则是代码复杂度不匹配、语义等价但语法不同以及其他杂项。基于此,作者提出了三条未来改进方向:引入仓库级上下文收集(如跨文件依赖分析、跨函数切片)以补足全局视野;注入项目本地 API 用例与轻量持续适配来提升项目适配性;将模式引导与符号执行、约束求解等验证性推理结合,以应对复杂逻辑。此外,作者还明确指出两类外部有效性威胁:对罕见 CWE 类型,仅靠标签难以匹配到有效模式(但匹配器能从代码本身做推断来缓解);论文仅覆盖 C/C++ 和 Java,其他语言仍需额外验证;方法依赖上游 SAST 工具提供的 CWE 标签与漏洞定位,这在真实场景下往往带噪声,因此作者把当前结果定位为"上界评估",而如何在噪声信号下保持鲁棒性将是后续工作的重点。
论文结论
综观整篇论文,VulKey 的真正价值不在于"又刷了一个 SOTA",而在于它用一种极具启发性的方式回答了一个长期困扰 AVR 研究者的根本问题——大模型的通用代码生成能力,到底该如何与安全领域的专家经验对齐。
作者给出的答案是:把"CWE 类型、语法动作、语义关键元素"这三层抽象共同纳入修复模式的定义,让每一条历史补丁都能被压缩成一把"可复用、可组合、可解释"的钥匙;再用一个独立训练的匹配器来为每个新漏洞挑选合适的钥匙,用一个渐进微调的生成器来把钥匙转化为可用的补丁。这种设计既绕开了"CWE 标签信息密度太低"的陷阱,又跳过了"完整示例噪声太多"的泥潭,还化解了"纯语法模板语义不足"的困境,最终在 C/C++ 和 Java 两个真实基准上都取得了 SOTA 成绩。对于工业界的漏洞修复实践而言,VulKey 的两阶段解耦设计也极富吸引力——匹配器、动作清单、生成 backbone 可以各自迭代,CWE 三级模式库可以持续沉淀并与漏洞追踪体系同步成长。
面向未来,随着仓库级上下文、项目 API 适配以及符号验证等能力的引入,基于结构化专家知识的 AVR 框架有望成为软件供应链安全防护的重要基础设施。这篇论文不仅给出了一套可复制的技术路线,更向整个社区传递了一个清晰的信号:让大模型真正服务于安全,必须先把专家经验"翻译"成模型听得懂的语言——而 VulKey,正是这种"翻译"工作的一次优雅示范。
声明:本文来自安全极客,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
