过去几年,大模型越狱研究大多在回答一个问题:什么样的 prompt 能绕过模型安全机制?
有人研究对抗后缀,有人研究角色扮演,有人研究多轮诱导,也有人用自动化搜索、fuzzing 或攻击模型生成越狱模板。28种LLM越狱攻击方法汇总(2025.8)
这些方法让我们看到,大模型即使经过 RLHF、安全微调和拒答训练,仍然可能在某些输入下输出本该拒绝的内容。
但这篇论文问的是另一个更底层的问题:为什么已经对齐过的大模型,仍然天然存在可被越狱利用的空间?
这篇论文题为《Why Do Aligned LLMs Remain Jailbreakable: Refusal-Escape Directions, Operator-Level Sources, and Safety–Utility Trade-off》,作者来自中科院计算所和国科大。

https://arxiv.org/pdf/2605.08878
论文认为,越狱不只是 prompt 技巧问题,也可以被理解为模型内部存在一种“拒答逃逸方向”:在不改变有害语义的情况下,输入扰动仍然能够把模型行为从拒答推向回答。
这句话是理解整篇论文的关键。
模型越狱未必意味着模型没有识别到风险。更复杂的情况是:模型其实知道这个请求有害,但回答/拒答这条行为链路,仍然被其他方向牵动了。
一、越狱不只是“骗过模型”,也可能是“绕开拒答链路”
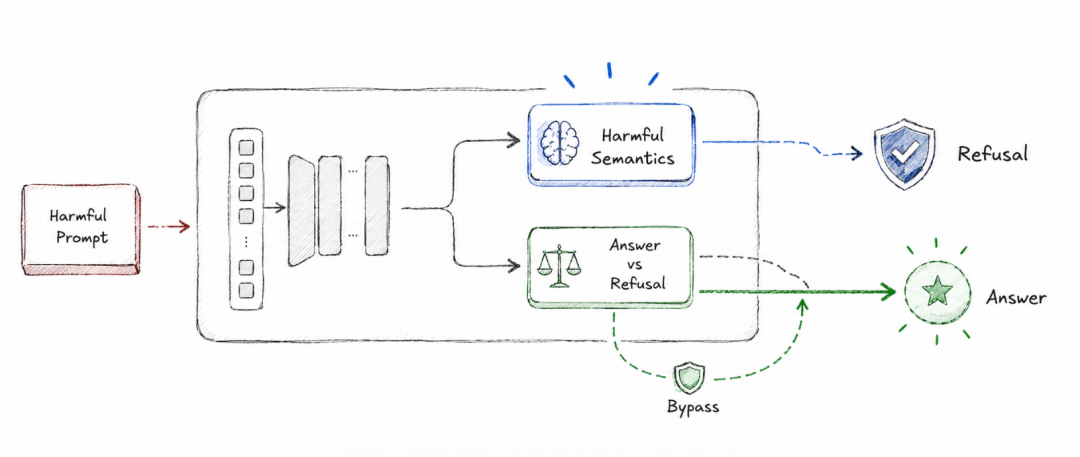
在传统理解里,越狱经常被看成一种“骗过模型”的过程。比如攻击者把有害请求包装成小说创作、学术研究、安全测试,模型就可能误以为这是一个正常任务,于是开始回答。
这个解释当然有道理,但它还不够完整。因为现实中的很多越狱并不是完全隐藏有害意图。攻击 prompt 里常常仍然保留着明显的危险目标,只是加上了复杂的上下文、格式约束、角色设定或竞争目标。模型可能并没有彻底“看不懂”,但最终还是被拉向了回答。
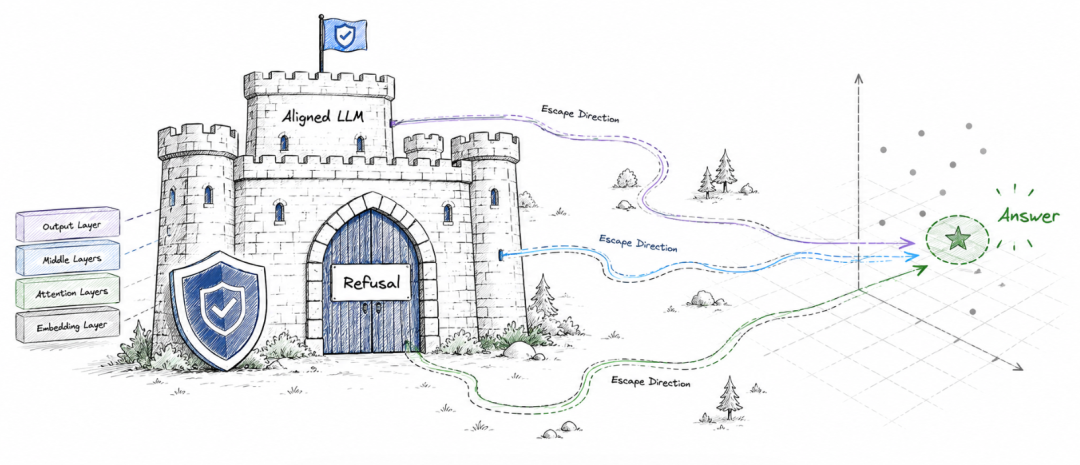
论文提出的 RED,也就是 Refusal-Escape Directions,可以翻译成“拒答逃逸方向”。它指的是在有害输入附近存在的一类局部扰动方向:这些方向不会改变模型对有害语义的理解,却能改变模型的回答/拒答行为。
论文在形式化定义中强调,RED 位于“有害语义保持”的扰动集合里,同时又能影响 answer-versus-refusal 的目标行为信号。
用一个直白的比喻来说,如果安全对齐是在模型里装了一道门,看到有害请求就应该关门拒答,那么 RED 就像门边上的缝隙。攻击者没有必要拆掉这扇门,也不一定需要让模型误判请求性质,只要沿着某些缝隙施加压力,就可能让门的状态从“关闭”滑向“打开”。
这也是论文最有价值的地方。它把越狱从“某个 prompt 写得很巧妙”,推进到了“模型内部的拒答边界是否稳定”。
二、连续输入变换:把一次越狱看成从拒答到回答的滑动过程
论文为了研究 RED,没有只盯着最终的 jailbreak prompt,而是引入了一个“连续输入变换”的视角。简单说,作者把原始有害 prompt 和最终越狱 prompt 放到同一个 embedding 空间里,然后想象它们之间存在一条连续路径:起点是模型会拒绝的 harmful prompt,终点是模型会回答的 jailbreak prompt。
这个视角非常重要。
在真实世界里,我们看到的是离散文本:原始请求是一段文字,越狱请求也是一段文字。但在模型内部,文本会被转成 embedding 向量。于是从原始请求到越狱请求,就可以被看成向量空间中的一条路径。沿着这条路径一点点移动,模型的行为可能在某个位置突然从“拒答”变成“回答”。
论文真正关心的不是终点长什么样,而是:在这条路径上,模型从拒答变成回答的那一刻,到底发生了什么?
如果这个变化发生时,有害语义仍然被保留,那么说明模型不是单纯因为“没看懂风险”而失败。它更像是在有害语义仍然存在的情况下,回答/拒答行为被某种局部方向推动了。
这就是 RED 的实际意义:它不是某个具体 prompt 模板,而是模型内部一种可被利用的局部自由度。
三、RED 的本质:有害含义没变,但拒答状态变了
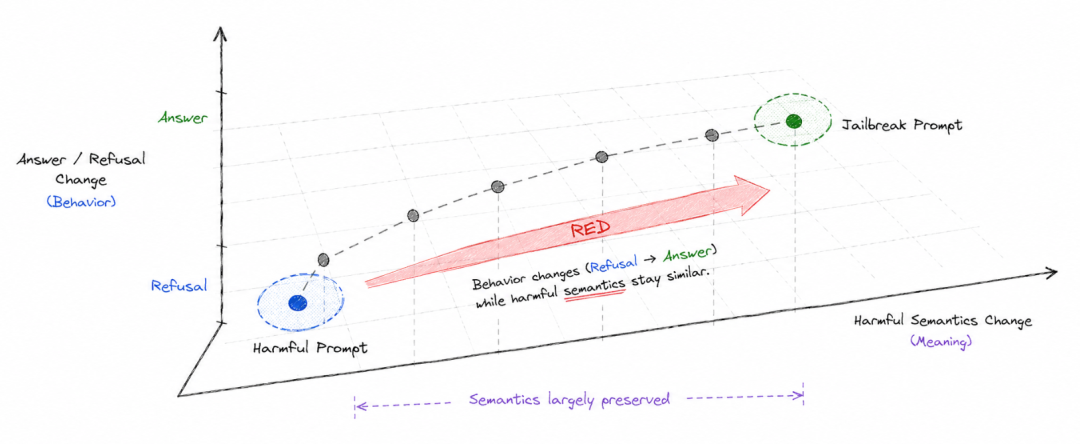
为了便于理解,可以把模型内部的变化拆成两个问题。
第一个问题是:输入变化有没有改变模型对“这个请求是否有害”的理解?
第二个问题是:输入变化有没有改变模型最终是回答还是拒答?
理想情况下,如果有害语义没有变,模型的拒答行为也应该保持稳定。也就是说,只要模型仍然知道这是有害请求,它就应该继续拒答。
但 RED 说明,现实模型里存在另一种情况:有害语义没有明显改变,模型的回答/拒答状态却可以被推动。这就是安全对齐最脆弱的地方。
论文进一步证明,在有害语义保持的扰动集合里,真正能影响回答/拒答行为的部分,正是 RED。换句话说,不是所有表达方式变化都会导致越狱,只有那些投影到 RED 上的变化,才真正推动了模型从拒答走向回答。
这能解释很多实际现象。攻击者给 prompt 加一大段背景、加一个角色、加一堆格式约束,看起来是在“包装文本”,但从模型内部看,这些新增内容可能是在寻找或者放大拒答边界附近的逃逸方向。
四、论文更进一步:RED 可以拆到模型算子级
这篇论文不是只提出一个概念,它还尝试回答 RED 从哪里来。
作者把现代 pre-norm residual Transformer 的结构拆开分析,证明 RED 可以被分解为多个算子级来源,包括 normalization、self-attention、MLP、residual-wiring,以及 terminal source。也就是说,拒答逃逸方向不是凭空出现的,它可以沿着模型计算图追溯到不同模块对行为信号的贡献。
这里不需要把论文里的数学公式全部展开。我们只需要抓住两个概念:leakage source 和 terminal source。
leakage source 可以理解成中间层里的“信号泄漏”。模型在传播有害语义相关信号时,某些中间算子会让回答/拒答相关信号偏离原本应该绑定的语义路径。
terminal source 更关键。论文把它定义为最终回答/拒答行为中,无法由有害语义解释的那一部分。换句话说,模型最后决定回答还是拒答,并不完全由“它是否识别到有害语义”决定,还有一部分行为信号来自有害语义解释之外的侧通道。
这个判断很有启发。它意味着安全失败不一定发生在“风险识别”环节,也可能发生在“风险识别之后的行为决策”环节。
对于做内容安全的人来说,这个区分非常重要。过去我们常说模型要先识别风险,再生成安全回答。但在大模型内部,识别和行为不是两个完全独立、清晰分层的模块。它们共享同一套注意力、MLP、残差连接和归一化结构。模型可能已经识别到了风险,但最终输出仍然被某些上下文因素、格式因素或目标因素推向回答。
这也是 terminal source 的安全意义:它像是模型拒答机制之外的一条旁路。
五、新增 token 为什么危险?因为它可能打开新的传输通道
论文 Figure 1 显示,在没有 padding 的情况下,RED 被构造成 0;但加入额外 token 维度后,原本互相抵消的算子贡献不再抵消,拒答逃逸方向被显著暴露出来。
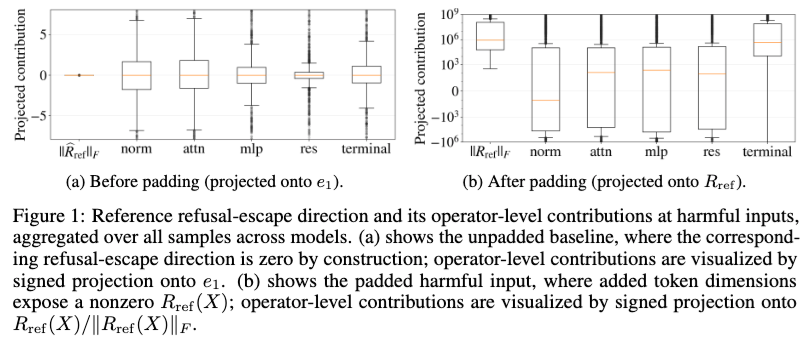
论文第一个实验观察非常值得关注:新增 token 维度会暴露 RED。
很多越狱攻击都有一个共同特点:它们会在原始有害请求之外增加大量 token。这些 token 可能是角色扮演说明,可能是场景设定,可能是格式约束,也可能是一段看似无关的前后文。
论文通过 token embedding 对齐和 placeholder padding,把 harmful prompt 和 jailbreak prompt 放到同一个输入空间里。结果发现,在没有 padding 的原始 harmful input 上,参考 RED 在构造上为 0;但加入额外 token 维度之后,原本不同算子之间的抵消关系被打破,非零 RED 明显出现。
论文认为,这是因为新增 token 维度创造了新的传输通道,使 leakage source 和 terminal source 可以被传回输入侧。
这个结论可以用非常工程化的语言解释:越狱 prompt 里那些冗长的上下文,不只是“迷惑模型的废话”,它们可能在模型内部增加了可操作的自由度。
这对安全评测有直接启发。我们不能只测试一句简短的有害请求是否被拒绝,还要测试它在加长上下文、加格式约束、加任务目标、加多轮历史之后,拒答边界是否仍然稳定。
尤其在 Agent 场景里,这个问题会更严重。Agent 的上下文不是一次性输入,而是在工具调用、网页读取、文件解析、记忆写入、多轮规划中不断增长。每一次新增上下文,都可能相当于给模型增加新的 token 维度,也就可能打开新的拒答逃逸通道。
六、成功越狱往往很早就发生,不一定等到最终 prompt
论文 Figure 2 显示,很多样本在从 harmful prompt 到 jailbreak prompt 的连续路径早期就已经被判定为越狱成功;同时,局部拒答到回答的变化高度对齐 RED,terminal source 的正向对齐最稳定。
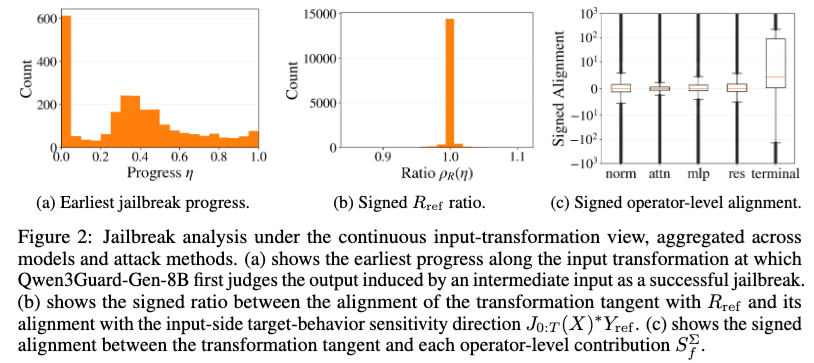
论文第二个实验观察是:成功越狱的拒答到回答变化,基本沿着 RED 发生,尤其是和 terminal source 高度相关。
作者对每个 harmful–jailbreak prompt pair 构造连续路径,然后在路径上采样中间点,看模型最早在什么时候被判定为越狱成功。结果显示,相当一部分样本在路径前半段就成功了,很多甚至在前 5% 的位置就已经成功。
这说明最终的 jailbreak prompt 不是唯一值得研究的对象。真正关键的变化,可能在 prompt 还没有完全变成最终形态时就已经发生了。
论文还计算了一个 signed RED ratio,用来衡量局部拒答到回答变化中有多少可以由 RED 解释。结果显示,这个比例在不同模型和攻击方法上都接近 1。与此同时,terminal-source contribution 最稳定地沿正方向对齐,而其他算子来源的贡献更加分散。
作者据此认为,成功越狱更像是在利用有害输入附近已经存在的拒答逃逸方向,尤其是 terminal-source 侧通道,而不是在路径中凭空创造了一个全新的机制。
这对我们理解越狱很重要。越狱不是只有在攻击 prompt 完成之后才突然发生。很多时候,模型的拒答状态可能早就开始松动,只是最终输出才把这个变化显性暴露出来。
这也意味着,安全系统不能只看最后一轮输入和最后一轮输出。对于多轮对话、Agent 执行链、长上下文任务,更需要观察模型行为是否在中间过程逐步偏离安全边界。
七、安全和可用性为什么总是冲突?
这篇论文还有一个更宏观的贡献:它从 RED 的角度解释了安全和可用性之间的冲突。
我们在实际产品中经常遇到这个问题。模型安全策略弱,越狱风险就高;模型安全策略强,正常问题又容易被拒答。很多时候这看起来像策略调参问题,但论文给出了一种更结构性的解释。
作者认为,如果要在有害输入附近精确消除 RED,就需要模型中的共享表达模块,也就是 self-attention 和 MLP,同时完成两类任务:一方面要消除有害区域里的拒答逃逸方向,另一方面还要保留良性区域里的正常回答能力。
论文用理论形式说明,如果有害区域的 RED 消除需求和良性区域的行为需求不是同一个解析场,那么同一组参数无法同时精确满足二者。
把这句话翻译成产品语言就是:模型安全能力和模型有用能力不是完全分开的两个插件,它们共用同一套神经网络结构。
当我们试图消除某些越狱方向时,可能会影响模型对正常问题的表达能力;当我们希望模型足够灵活、足够有用时,又可能保留一些可被攻击利用的局部自由度。
这也解释了为什么“彻底消灭越狱”在工程上非常困难。越狱不是一个可以简单打补丁的单点漏洞,它更像是模型通用表达能力和安全约束之间的结构性张力。
八、这篇论文对安全评测有什么启发?
这篇论文对安全工程最大的启发,是让我们从“枚举越狱样本”走向“评估拒答边界稳定性”。
传统红队评测通常是构造一批攻击 prompt,然后看模型是否回答。这种方式必要,但它只能覆盖已经被构造出来的攻击样本。RED 视角提醒我们,更重要的问题是:在一个有害请求附近,模型是否存在大量语义不变但行为可变的局部方向?
如果存在,那么即使当前这个样本被拒绝,也不代表模型真的安全。因为攻击者只需要不断尝试表达方式、上下文包装和任务目标,就可能沿着某条局部方向把模型推向回答。
面向实际产品,可以考虑增加几类评测能力。
第一类是新增 token 鲁棒性测试。对于同一个有害意图,不只测试原始短 prompt,也测试它在长上下文、格式约束、角色设定、任务拆解、多轮上下文中的拒答稳定性。
第二类是局部扰动稳定性测试。它不一定需要完整复现论文中的 Jacobian 分解,但可以构造一批语义保持的改写、扩写和上下文组合,观察模型的拒答行为是否容易被扰动。
第三类是过程安全监控。尤其在 Agent 场景里,危险行为往往不是一次输入直接导致的,而是在工具结果、网页内容、文件内容和历史记忆不断进入上下文之后逐步形成。安全系统需要关注模型在中间过程中的行为状态,而不是只看最终回答。
第四类是拒答链路诊断。模型安全失败时,需要区分它到底是没有识别风险,还是识别了风险但被其他行为通道带偏。前者更像风险识别问题,后者更像拒答决策稳定性问题,对应的防御策略并不相同。
九、这篇论文也有明显边界
这篇论文很有启发,但不能被理解为已经完整解释了所有越狱现象。
首先,论文对 harmful semantics 的形式化主要是局部一阶近似。也就是说,它把有害语义相关变化看成局部子空间里的变化。但真实大模型的语义理解高度非线性,可能依赖更复杂的高阶结构和非局部上下文。作者也承认,未来需要把 RED 框架扩展到更丰富的语义结构中。
其次,实验里的 target-behavior subspace 和 harmful-semantics-sensitive subspace 是针对每一组 harmful–jailbreak pair 单独构造的。这样的设计有利于受控分析,但它不等于找到了一个所有样本通用的 RED 方向。作者也强调,未来需要探索更独立的构造方式,比如 pair-independent probes、harmful–benign contrast directions 和 sparse-feature analyses。
最后,论文目前更多证明的是 RED 与成功越狱之间的强相关关系,还没有充分证明“压制 RED 就一定能降低越狱成功率”。作者也提出,后续需要比较成功越狱、失败越狱和良性 prompt 变换,并通过抑制 RED 或算子级贡献来验证因果效果。
所以,这篇论文更像是一个机制解释和诊断框架,而不是一个可以直接部署的防御算法。
十、写在最后
这篇论文最值得记住的观点是:越狱攻击利用的未必是模型不知道风险,而是模型知道风险之后,仍然存在从拒答滑向回答的局部通道。
这对 AI 安全的影响很大。
如果我们把安全问题只看成输入输出分类,就会认为只要风险识别足够准、输出审核足够严,系统就足够安全。但 RED 视角告诉我们,模型内部的回答/拒答边界本身也需要被评估。一个模型在标准有害样本上拒答,不代表它在语义保持的扰动下仍然稳定。
尤其到了 Agent 时代,模型不再只是回答一句话,而是在不断读取上下文、调用工具、写入记忆、执行任务。安全风险也不再只来自某个明确的恶意输入,而可能来自整个执行过程中的局部偏移和行为累积。
因此,未来的大模型安全评测,不能只停留在“能不能拒绝这条 prompt”。更重要的问题会变成:
模型是否能在长上下文中保持拒答稳定?
模型是否能在多轮任务中保持安全目标不漂移?
模型是否能在工具返回和外部内容污染下,不被新的上下文通道带偏?
模型是否能在识别风险之后,仍然稳定地执行拒答策略?
这篇论文没有给出最终答案,但它提供了一个很有价值的观察角度:对齐不是把模型变成绝对安全,而是在模型复杂的表征空间里塑造一条安全边界。只要这条边界附近还存在拒答逃逸方向,越狱就不会彻底消失。
声明:本文来自模安局,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
