
原文标题:Dissecting Real-World Cross-Language Bugs
原文作者:Haoran Yang, Haipeng Cai原文链接:https://doi.org/10.1145/3715777笔记作者:杨浩然@安全学术圈主编:黄诚@安全学术圈
1、背景介绍
跨语言Bug(Cross-Language Bug, CLB) 是指在多语言软件中,由两种或更多编程语言之间错误的跨语言信息流所诱发的代码缺陷。其典型特征是:bug 的成因或表现至少跨越两种语言的边界,仅检查任一侧语言的代码均难以完整诊断。
多语言开发已成为现代软件工程的主流范式。Python/Java 提供高层抽象与丰富生态,C/C++ 提供性能敏感、贴近系统底层的执行能力,二者通过外部函数接口(FFI),例如 Python C Extension 与 Java 本地接口(JNI),实现跨语言交互。这种组合在 PyTorch、TensorFlow、NumPy、SciPy、Android、Tomcat、MySQL 等大量开源项目中被广泛采用。然而,异构语言之间在类型系统、内存模型、异常传播机制等方面的语义差异,使得多语言软件相较单语言软件更具复杂性与缺陷倾向性,CLBs 由此成为一类隐蔽且具影响力的缺陷类型。
尽管近年来已涌现一批面向 CLB 的检测工具(如 PolyCruise、PolyFuzz、PyRTFuzz),但学术界对真实世界 CLBs 缺乏系统性的实证认知:其常见症状、典型位置、表征模式、根因构成与修复策略均未被充分刻画。已有相关研究在三方面存在不足:(1) 多聚焦于单语言软件而非真正的多语言交互;(2) 偶有涉及多语言软件的工作停留在开发者主观感受或统计层面的缺陷倾向分析,未触及代码级真实缺陷;(3) 接口层面的研究多聚焦于跨语言 API 的误用,未覆盖 CLB 的完整生命周期。
为填补这一空白,四川大学杨浩然开展了首项面向真实世界 CLBs 的系统性实证研究。该研究从 GitHub 的 2,428 个 Python-C 与 1,757 个 Java-C 仓库、累计 886,526 个commit中进行筛选与采样,最终人工确认并精细分析了400 个真实 CLBs(200 个 Python-C + 200 个 Java-C),首次系统刻画了 CLBs 在症状、位置、表征、根因、修复策略五个维度上的特征及其相互关联。
2、研究动机:现有工作的三大缺口
在本文之前,关于多语言软件缺陷的研究存在三处结构性缺口:
聚焦单语言而非跨语言交互:诸多被广泛引用的"语言与缺陷关系"研究虽然横跨多种语言,但每种语言均被独立分析,并未真正面向"语言间交互"这一核心问题。
停留在定性与统计层面:少数确实针对多语言软件的工作,或基于开发者主观感受,或仅做"语言组合 ↔ 缺陷倾向"的统计关联,未触及代码级的真实缺陷。
接口研究碎片化:与 CLB 主题最为接近的工作主要聚焦于跨语言 API 误用这一单一维度,缺乏对症状、位置、根因、修复策略以及它们生命周期关系的系统性、整体性剖析。
为此,本文围绕 CLBs 的完整生命周期提出 5 个研究问题:
RQ1:CLBs 有哪些症状(Symptoms)?
RQ2:CLBs 出现在代码的什么位置(Locations)?
RQ3:CLBs 在何种跨语言函数语义中表征(Manifestation)?
RQ4:CLBs 的根因(Root Causes)是什么?
RQ5:CLBs 是如何被修复(Fixes)的?
每个 RQ 不仅独立分析 Python-C 与 Java-C 两种语言组合,还系统比较它们之间的共性与差异,并在此基础上进一步通过关联分析刻画 5 个维度之间的生命周期关系。
3、研究方法:CCC 工具与 CICFG
为从近百万个 commit 中精准识别真实 CLBs,作者设计了一套自动筛选与人工确认相结合的研究流水线,整体流程如下图1所示:
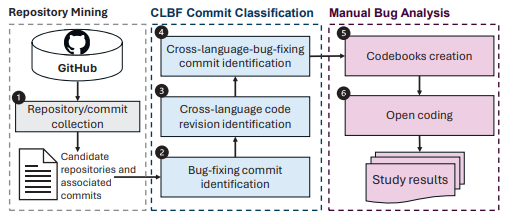 图1 研究方法概述
图1 研究方法概述
整个流水线包含三个阶段:
3.1 仓库挖掘(Repository Mining)
筛选标准为:(1) Python/Java 与 C 代码量合计占比 ≥ 50% SLOC;(2) GitHub Star 数 ≥ 50。最终从 GitHub 收集到 4,185 个候选仓库(2,428 个 Python-C + 1,757 个 Java-C)、累计 886,526 个 commit。
3.2 CLB-Fixing Commit 三级过滤(CCC 工具)
作者自研了CLB-Fixing Commit Classification(CCC)工具,按计算开销从低到高逐级过滤,使最少量的候选进入开销最高的阶段:
第一级:Bug-Fixing Commit 识别 — 利用
error / bug / fix / patch / fault等关键词匹配 commit 关联的 issue 标签。筛后剩余54,356 个 bug-fixing commit。第二级:跨语言代码版本识别 — 构建基于有限状态自动机的 FFI 检测器,判断 commit 所在的项目版本是否真正具备跨语言交互(存在同一项目在不同版本中的多语言属性可能发生变化)。筛后剩余25,120 个。
第三级:CLB-Fixing Commit(CLBF)识别 — 该阶段构成 CCC 工具的核心。作者在 Joern 基础上扩展构建跨语言过程间控制流图(Cross-language Interprocedural Control Flow Graph, CICFG):节点为各语言单元中的语句,边为控制流;跨语言调用边依据各 FFI(Python C Extension、JNI 等)官方规范中的命名与调用约定识别。若 commit 修改的代码行与另一语言的代码实体之间存在通过跨语言 API 的依赖关系,则该 commit 被判定为候选 CLBF commit。筛后剩余5,941个候选 CLBF commit。
3.3 人工分析与开放编码(Open Coding)
为构建5个RQ的codebook,作者首先从候选commit中随机抽取364个(95%置信度、5%误差),由各作者独立编码后通过协商达成一致。随后再随机抽取并人工确认 200 个 Python-C 以及 200 个 Java-C,总共 400 个真实CLBs。CICFG 自动分析中存在的不精确性在该人工阶段通过信息流确认予以修正。
4、五大维度的核心发现
4.1 RQ1 —— 症状(Symptoms):三类共性主症状与两点差异
400个CLBs共归纳出6类症状。Python-C与Java-C的前三类症状高度一致,合计占比超过75%:
Sym1:Incorrect result/output(错误的结果/输出) — 占比最高的症状。
Sym2:Error/warning message(错误/警告消息) — 程序显式抛出无法处理的错误。
Sym3:Crash/abort(崩溃/中止) — 程序非预期终止。
两组语言组合之间存在两点显著差异:
内存泄漏在Python-C中显著偏多:源于Python引用计数机制与C手动内存管理之间的语义不匹配。
性能瓶颈在Java-C中明显更突出:JNI频繁的JVM ↔ Native上下文切换、数据marshaling与同步开销是主要原因。
4.2 RQ2 —— 位置(Locations):赋值与函数调用是共性高发点
CLBs 在函数内的发生位置共 9 类。前三位揭示了两种语言组合的共性与各自特点:
Loc1:Assignment(赋值语句) — Python-C 居首位、Java-C 居第二位。常见模式包括外部数据类型初始化、跨语言运算赋值、外部函数返回值赋值。
Loc2:Local function call(本地函数调用) — Python-C 居第二位、Java-C 居首位。被调函数本身并非跨语言 API,但位于责任信息流之上,通常因被调函数被误用或自身存在缺陷而引发CLB。
Loc3(Python-C 第 3 位):Cross-Language API callsite(跨语言 API 调用点) — Python C Extension中数据类型频繁通过
PyLong_AsLong、Py_DecRef等 API 进行类型转换与生命周期管理,缺陷高发。Loc4(Java-C 第 3 位):Conditional statement(条件语句) — Python与C在操作符语义与类型转换上的不一致使运算符错误在Python-C中更高发。
更具洞察力的发现关于 native(C 侧)与 foreign(Python/Java 侧)代码的 CLB 分布:
CLBs 绝大多数发生在 native(C 侧)代码而非 foreign 侧。这一现象源于两点原因:其一,native 代码承担了不同类型系统与内存模型之间的复杂数据转换;其二,native 组件作为跨语言桥梁,需实现错误倾向性更高的低层接口。
作者还首次明确提出 NAX 函数(Non-API Cross-language Function) 这一概念:指协助跨语言 API 工作但本身不属于公开 API 的辅助函数(如内部数据 marshaling、底层内存或资源管理函数)。NAX 函数在 Java-C 中是 CLB 数量最高的类别,但因不属于正式 API、缺乏官方文档与标准错误报告机制,长期被研究者忽视,构成了一类被低估的缺陷源。
4.3 RQ3 —— 表征(Manifestation):跨语言 API 的功能语义视角
按 CLB 所在信息流路径上跨语言函数的功能语义划分,作者识别出 10 类跨语言 API。前 4 类的差异尤其值得关注:
MC1:Cross-language data parsing(跨语言数据解析) — Python-C 中占首位,主要源于
PyArg_ParseTuple等 API 在跨语言边界进行参数解析与构建的高频需求。MC2:Cross-language objects handling(跨语言对象操作) — Java-C 中占首位(接近一半),涵盖
GetIntField等对外部对象的创建、访问与生命周期管理;在 Python-C 中位居第二。MC3:Cross-language conversion(跨语言数据转换) — Python-C 中位居第三、Java-C 中缺席。该类别集中体现了 Python 动态类型与 C 静态类型之间的不匹配。
MC4:Cross-language memory management(跨语言内存管理) — Python-C 与 Java-C 中数量相当。引用计数误用(如
Py_INCREF未配对Py_DECREF)是该类别的典型,直接导致内存泄漏。
该分布刻画了两种语言组合在跨语言机制层面的本质差异:Python-C 的复杂性主要源于 Python 动态类型与 CPython API 所要求的显式解析、转换;Java-C 则因 JNI 提供的对象直接访问能力,复杂性更多集中在对象生命周期的管理。
4.4 RQ4 —— 根因(Root Causes):逻辑错误占绝对主导
作者共归纳出 18 类(Python-C)与 12 类(Java-C)根因,前两位根因在两种语言组合中完全一致:
RC1:Logic error(逻辑错误) — Python-C 中 49 例、Java-C 中 64 例,数量远超其他类别。最典型的模式是算法在跨语言边界上的不完整实现。
RC2:Boundary conditional error(边界条件错误) — Python-C 中 40 例、Java-C 中 46 例。典型模式是值/大小校验的缺失。
其他高频根因依次包括 Data type error、Reference count misuse、Function misuse、Initialization error 等。值得注意的是,Python-C 中的根因类型比 Java-C 更分散(18 类 vs 12 类),反映了 Python 动态类型与丰富语言特性带来的更广缺陷面。
4.5 RQ5 —— 修复策略(Fixing):补充校验与对齐类型
CLB 修复策略 | Python-C | Java-C |
|---|---|---|
增加必要的检查或输入验证 (FS1) | 19.0% | 18.0% |
使用合适的数据类型与显式转换 (FS2) | 14.5% | 19.0% |
修正条件/循环中的逻辑错误 | 12.5% | 15.5% |
改进内存管理与引用计数 | 18.0% | 11.0% |
更新和修复函数调用与 API | 11.5% | 7.0% |
FS1:Incorporate necessary checks or input validations(补充校验与输入验证) — 居首位的修复策略。典型模式包括 Null 校验与类型校验。
FS2:Utilize appropriate data types and casting(使用合适的数据类型与显式转换) — 位居第二的修复策略。典型场景包括类型不匹配修正以及 Java 与 C 之间的显式强制转换。
两类策略合计修复了 Python-C 中 33.5% 与 Java-C 中 37% 的 CLBs——这意味着仅"补校验"与"对齐类型"两种相对简单的策略即可覆盖三成以上的 CLBs,为未来自动化修复工具的设计提供了清晰的优先级。
5、跨维度关联:CLBs 的生命周期联动
作者使用 Apriori 算法挖掘 5 个维度之间的 if-then 强关联(lift > 1),揭示了 CLBs 内在的因果联动关系。
5.1 根因 ↔ 症状(lift 最高达 10.88)
Memory management error / Reference count misuse → Memory leak(lift > 10):极强关联。观察到内存泄漏症状时,根因几乎可确定为内存管理或引用计数误用。
Null pointer dereference → Crash(lift = 4):空指针解引用与崩溃之间存在中等强度关联。
Logic error / Boundary conditional error → Incorrect result/output:呈现多对一关联,表明仅凭"错误输出"这一症状难以反推具体根因。
5.2 根因 ↔ 表征(lift 最高达 6.10)
Reference count misuse ↔ Cross-language memory management(lift > 6):呈现双向强关联,构成一条清晰的因果链:引用计数误用 → 跨语言内存管理语义异常 → 内存泄漏症状。
多种根因(null pointer dereference、memory management error、boundary conditional error 等)均指向 Cross-language objects handling 这一表征类别,表明跨语言对象操作是诸多根因的共同表现层。
5.3 位置 ↔ 症状
Return / Conditional expression → Incorrect result/output:返回语句与条件表达式是"输出错误"的高发位置。
上述关联分析的核心价值在于:当观察到内存泄漏症状时,可直接顺着"内存管理 → 引用计数"这条因果链进行回溯诊断,而无需从头开始全面分析。这为 CLB 检测与调试工具的设计提供了重要的优先级指引。
6、案例剖析:Java-C 中的 AES-GCM 密钥长度缺陷
为更具体地说明上述发现,下面分析一个根因为边界条件错误的真实修复案例,如图 2 所示:
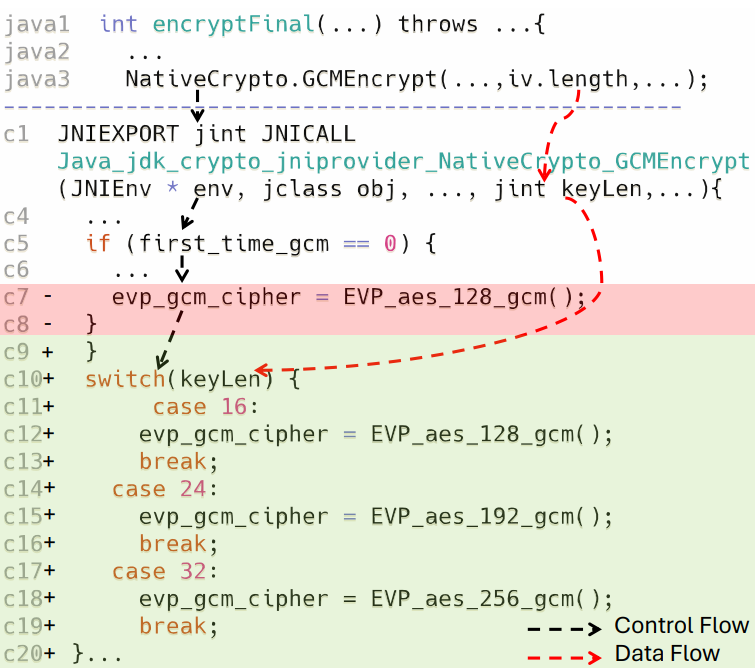 图2 Java-C CLB 案例
图2 Java-C CLB 案例
场景:Java 层调用 JNI 函数 Java_..._NativeCrypto_GCMEncrypt,在对 evp_gcm_cipher 指针赋值时**固定使用 EVP_aes_128_gcm()**,未根据调用方传入的 keyLen(实际可能为 16/24/32 字节)选择对应版本。
未修复版本:无论调用方提供 256-bit 还是 128-bit 密钥,C 侧均按 128-bit 算法执行。该缺陷在加密语义上属于典型的边界条件错误,直接破坏密码学正确性。
修复版本:在 JNI 函数中引入 switch-case 结构,根据 keyLen 选择对应的 EVP_aes_128_gcm() / EVP_aes_192_gcm() / EVP_aes_256_gcm()。
该案例呼应了本文的核心论断:CLB 并非某一侧语言独有的缺陷,而是 Java 层的语义假设与 C 层的实现细节之间的契约不一致。这种契约不一致难以通过任一侧的单语言静态分析或测试手段发现,凸显了跨语言信息流分析的必要性。
7、总结与展望
本文的核心贡献可概括为三点:
首项系统性的 CLBs 实证研究:覆盖 400 个真实 CLBs、5 个生命周期维度、2 种主流语言组合,全面揭示了 CLBs 的共性特征与组合差异。
可复用的工具链与数据集:基于 Joern 扩展实现的 CICFG 构建模块、CCC 自动分类工具,以及高质量 CLB 数据集均已开源。
可操作的工程化建议:从预防、检测到修复,给出了基于实证数据的优先级指引。
对跨语言安全研究的启示:本文识别的若干 CLB 模式,尤其是引用计数误用、边界条件错误、跨语言类型不匹配。这意味着本文实际上为后续基于 LLM 的代码审计、跨语言模糊测试、跨语言污点分析等漏洞挖掘研究提供了实证依据:应优先关注哪些代码位置、何种语义场景、哪类根因模式。
未来值得关注的研究方向至少包括:(1) 扩展到 Rust-C、Go-C、Kotlin-C 等新兴语言组合;(2) 将 CICFG 升级为包含跨语言数据流的程序依赖图;(3) 将本文的根因/修复模式知识库与 LLM 和 agent 结合,实现自动化的 CLBs 检测与修复。
作者团队介绍
论文第一作者
Haoran Yang(杨浩然)毕业于Washington State University(华盛顿州立大学),现就职于四川大学。主要研究方向为多语言软件分析、跨语言 Bug 检测与定位,已在 ICSE、FSE 等 CCF-A 类会议上发表多篇代表性论文。 https://yhryyq.github.io/通讯作者
Haipeng Cai教授现任University at Buffalo, SUNY(纽约州立大学布法罗分校)副教授,长期从事软件分析、多语言软件工程、AI for SE、软件供应链安全等方向的研究。其团队近年来在跨语言软件分析方向产出了一系列代表性工具,覆盖了从静态/动态分析到模糊测试的多个跨语言安全研究环节。本文则在此基础上提供了实证层面的基础性贡献。
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
声明:本文来自安全学术圈,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
