最近讨论 Agent 安全时,很多人还是习惯从提示注入、越狱、恶意网页、工具滥用这些具体问题切入。
这些问题当然重要,但它们只是表层现象。
真正的变化在于,Agent 已经不再只是一个会聊天的模型。它开始访问本地文件,调用外部工具,安装第三方 Skill,连接邮箱、日历、代码仓库和企业系统,甚至维护长期记忆,并在用户没有逐步确认的情况下连续执行任务。
当一个系统开始替用户调度任务、访问资源、管理状态、执行工具、连接外部世界,它就不再只是一个“大模型应用”,而更像一个小型操作系统。
这正是论文《Toward Securing AI Agents Like Operating Systems》想表达的核心判断:Agent 安全不能只靠模型拒答、提示词约束或提示注入检测,而应该像保护操作系统一样,重新设计 Agent 的运行时安全边界。

https://arxiv.org/pdf/2605.14932
论文认为,Agent 和操作系统面临非常相似的问题:都要隔离资源、分离权限、控制通信,并阻止数据和权限越过不该越过的边界。
这篇文章的价值,不在于又列举了几个 Agent 攻击案例,而在于给 Agent 安全提供了一个更底层的解释框架。
Agent 已经从助手变成了执行系统
论文讨论的是一类 OpenClaw-style Agent,也就是开放、可扩展、运行在用户环境里、能够接入本地文件和外部服务,并且可以通过第三方 Skill 扩展能力的 Agent 系统。
这类 Agent 的危险性很高,因为它同时具备三个特征。
它有执行能力,可以调用工具、执行命令、读写文件;它有环境连接能力,可以接触用户账号、API key、消息通道和外部服务;它还有扩展能力,可以安装第三方 Skill,甚至在某些场景下修改自己的能力边界。
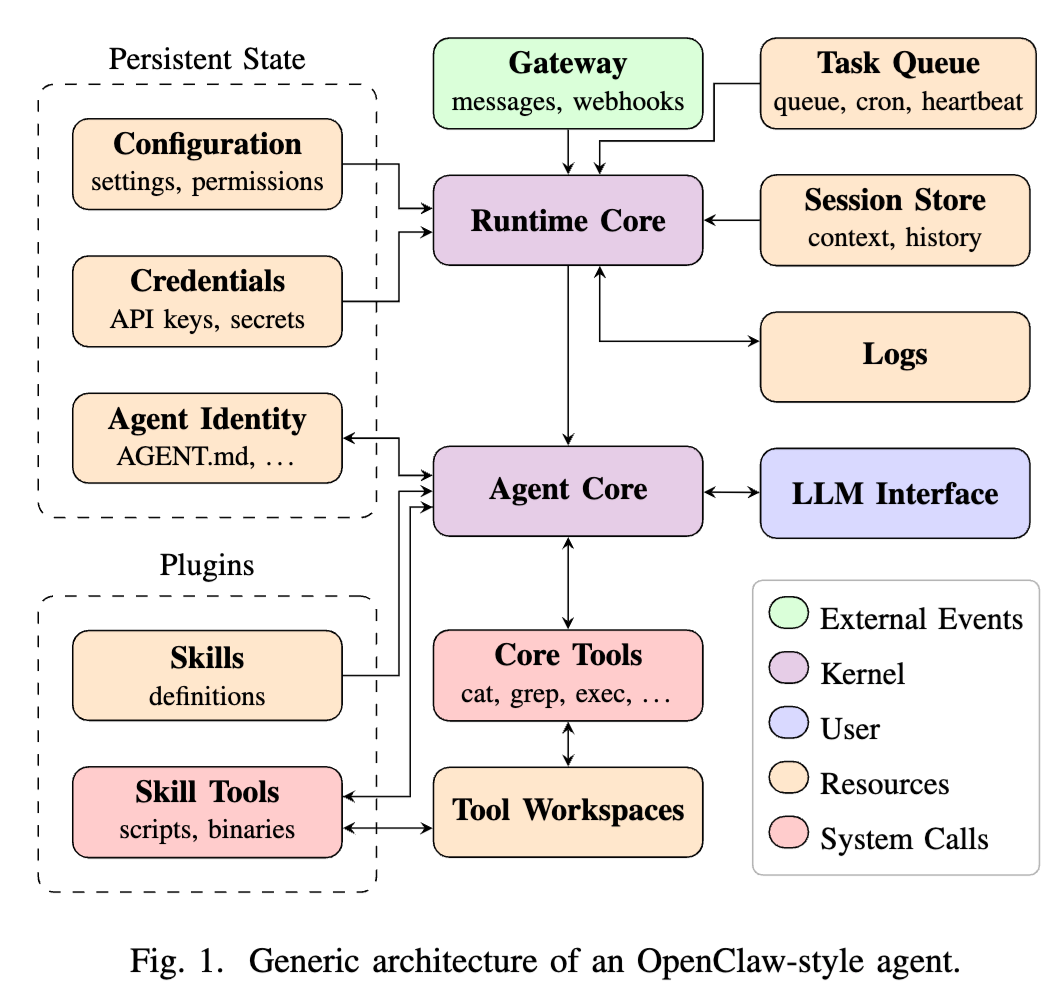
论文指出,OpenClaw-style Agent 的攻击面来自工具访问、运行时扩展、持久化状态、第三方代码和敏感用户上下文的组合。提示注入只是这个大攻击面中的一种表现形式,并不能代表 Agent 安全的全部问题。
这句话非常关键。
如果一个 Agent 只会回答问题,那么安全问题主要集中在输出内容是否合规、是否有害、是否泄露隐私。但如果一个 Agent 能够调用工具、访问文件、连接账号、发送消息、安装 Skill,那么安全问题就进入了系统安全层面。
这时候,问题不再是“模型会不会说错话”,而是“模型被诱导之后,系统会不会真的执行危险动作”。
这也是为什么论文把 Agent 类比成操作系统。
在传统操作系统里,用户程序不能直接访问硬盘、网卡和内核数据结构。它必须通过系统调用,由内核负责权限检查和资源隔离。用户可以输入错误命令,程序也可能存在漏洞,但操作系统不能因此失去边界。
Agent 也是一样。LLM 可以被提示注入诱导,可以误解用户意图,可以在复杂上下文中做出错误判断。但 Agent runtime 必须保证:即使 LLM 出错,敏感文件、凭证、日志、跨用户数据、网络出口和高危工具也不能被随意访问。
LLM 是不可信用户,Runtime 是内核
这篇论文最有启发的地方,是把 Agent 系统中的关键组件映射到了操作系统概念上。
LLM 对应的是“不可信用户”,它负责理解任务、生成计划、选择工具,但不能被默认视为安全决策者。
Agent runtime 对应的是“内核”,负责调度、权限判断、资源隔离和策略执行。
Tools 对应系统调用,是访问文件、网络、Shell、数据库和外部 API 的受控接口。
Skills 对应程序,是可以被安装和运行的能力单元。
LLM Context 对应内存,里面既有可信信息,也可能混入来自网页、文档、消息和工具输出的不可信内容。
Files 对应持久化存储,Gateway 则对应网络通信边界。
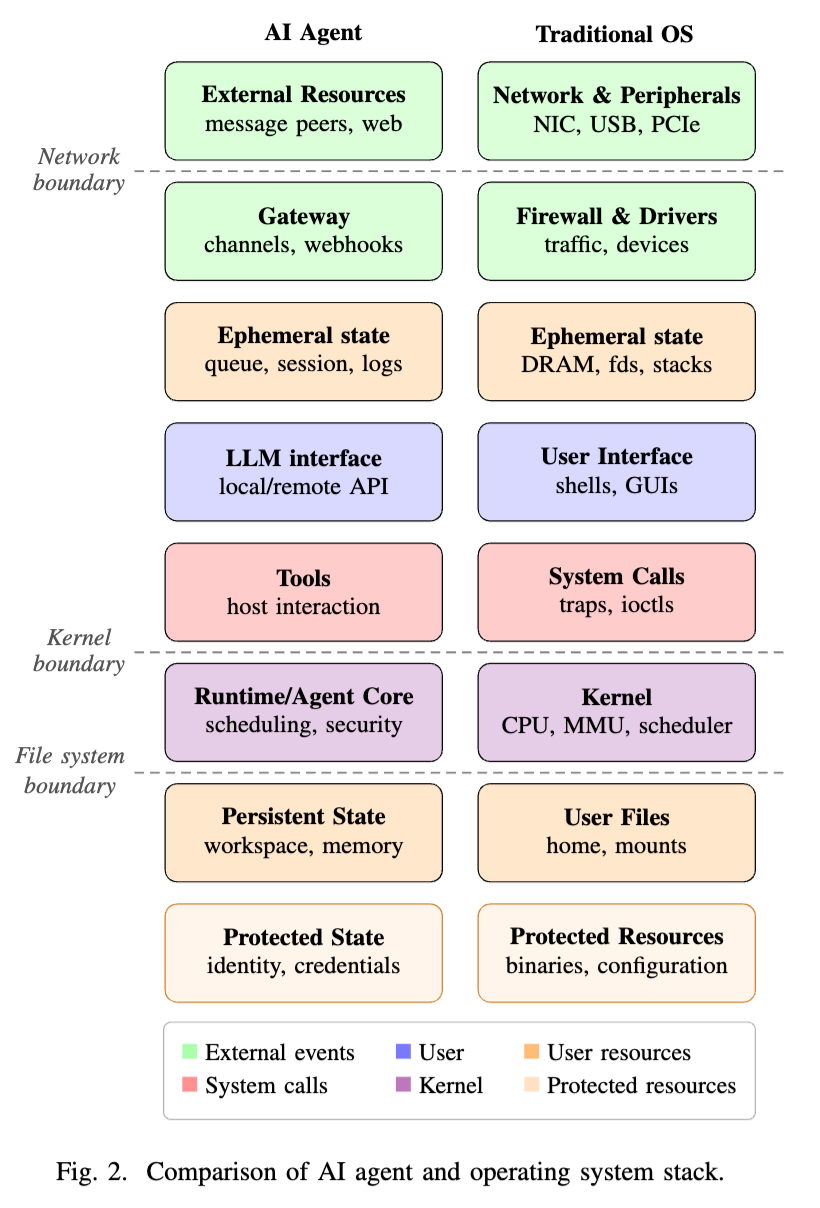 这个类比一旦成立,很多 Agent 安全问题就会变得非常清晰。
这个类比一旦成立,很多 Agent 安全问题就会变得非常清晰。
现在很多 Agent 的问题是,它们把 LLM、工具、Skill、上下文、文件访问、记忆更新放在了同一个信任域里。模型看到什么、工具输出什么、Skill 写入什么、上下文保留什么,往往都混在一个连续对话流里。
这就像早期没有进程隔离的系统:不同程序共享内存,一个程序写坏了数据,另一个程序就会被影响;一个恶意程序读取了不该读的区域,系统也拦不住。
在 Agent 里,对应的问题就是:一个网页里的恶意文本可能污染上下文,一个工具输出可能诱导后续工具执行危险命令,一个 Skill 可能读取另一个 Skill 的临时文件,一个用户的会话数据可能被另一个用户间接访问,甚至 Agent 的日志和配置也可能被自身工具改写。
论文把这种问题总结为一个结构性缺陷:当前许多 Agent 的安全策略可能写在自然语言提示词里,也可能是一些运行时检查,但它们没有被一个更低权限、更强制的 reference monitor 保护。换句话说,很多 Agent 的安全边界是软的。
为什么只靠“模型安全”不够
这篇论文有一个非常明确的立场:Agent 安全不应该只依赖“让 LLM 表现正确”。
原因很简单,LLM 在 Agent 系统里承担的是规划和决策角色,但它并不是可靠的安全边界。模型可能被恶意上下文诱导,也可能把数据当成指令,还可能因为“帮助用户完成任务”的倾向而忽略潜在风险。
传统操作系统也不会假设用户永远输入安全命令,更不会要求每个程序都永远没有漏洞。操作系统的做法是,无论用户和程序如何行动,敏感资源访问都必须经过内核控制。
Agent 也应该如此。
一个安全的 Agent runtime,不应该把“请不要泄露隐私”“请不要执行危险命令”“请不要访问无关文件”只写进系统提示词里。它应该在工具调用前做权限检查,在文件访问前做路径和数据域判断,在网络请求前做出站控制,在上下文写入前做来源标注,在日志记录后保证不可篡改。
论文在辅助实验中还观察到,换用 Gemini-2.5 和 GPT-5.5 后,许多攻击仍然可以发生。部分更强模型会识别某些隐私风险并拒绝输出明文,但它们可能已经执行了前面的危险步骤。
论文因此认为,稳健防御必须实现在 Agent 自身,不能只依赖模型级拒答。
这对企业落地非常重要。
如果一个企业把 Agent 接入内部知识库、代码仓库、工单系统、邮件系统和办公系统,那么安全目标不能只是“模型不要说出不该说的话”。更重要的是,系统必须保证 Agent 在被诱导时也不能越权读取、越权发送、越权修改、越权安装、越权调用。
一句话概括:模型拒答不是安全边界,运行时强制执行才是安全边界。
把操作系统安全机制搬进 Agent
论文系统梳理了多个操作系统安全机制,并讨论它们如何迁移到 Agent 系统中。
第一类是统一接口。
操作系统通过系统调用把用户程序和底层资源隔开。Agent 也应该有统一的工具调用接口。所有文件读写、网络访问、Shell 执行、凭证使用、消息发送,都应该进入一个受控的 Tool Gateway,而不是让 Skill 自己决定用哪个命令、哪个脚本、哪个浏览器工具、哪个 HTTP client。
如果 Skill 可以修改 PATH、替换 helper script、注册一个假的工具实现,那么 Agent 以为自己调用的是可信工具,实际执行的可能已经是被篡改的实现。这和操作系统里的 syscall table tampering、confused deputy 问题很像。论文认为,更安全的 Agent 设计应该使用不可变工具注册、工具来源证明、参数校验和运行时工具调用策略。
第二类是进程隔离。
今天很多 Agent 最大的问题,是不同工具调用共享同一个 LLM 上下文。工具 A 的输出、网页里的内容、用户消息、历史记忆和系统提示词混在一起,后续工具调用都可能受到影响。
更合理的方式,是为每次工具调用提供 scoped context,只给它完成任务所需要的数据,并通过显式输入输出通道传递结果。不同用户、不同会话、不同 Skill、不同工具链之间,也应该有独立的 session cache 和 workspace。
第三类是沙箱。
很多人说 Agent 要做沙箱,但论文提醒,沙箱不能只停留在“把 Agent 放进容器”这一层。真正的问题是,Agent 有很多副作用路径:Shell、文件、浏览器、HTTP 请求、MCP 工具、消息通道、环境变量、凭证、日志、配置文件。只要有一条路径没有被纳入策略控制,攻击者就可能从那里绕出去。
第四类是应用权限。
Agent 的 Skill 应该像移动 App 一样声明权限。一个天气 Skill 不应该默认访问邮件,一个摘要 Skill 不应该默认发送外部请求,一个表格处理 Skill 不应该默认拥有无限 Shell 权限。权限还不能只靠用户弹窗,因为用户很快会授权疲劳。更现实的做法,是默认最小权限、按场景分级授权、对高危动作二次确认,并把权限和可审计行为绑定起来。
第五类是网络过滤。
很多 Agent 风险最后都会落到“数据流向哪里”。即使模型没有在最终回答里泄露明文,也可能已经通过 HTTP 请求、消息平台、邮件、Webhook 或第三方工具把数据发出去了。所以 Agent 安全必须管出站流量。谁能发、发给谁、发什么、通过什么工具发,都应该被记录和控制。
第六类是防篡改日志。
Agent 一旦具备执行能力,日志就不只是调试信息,而是安全取证基础。Agent 应该记录输入消息、Gateway 接受和拒绝事件、Prompt 构造、工具调用、权限检查、Skill 安装、凭证访问、记忆更新、网络请求和最终输出。更重要的是,日志不能被 Agent 自己随意改写。否则攻击者完成攻击后,再让 Agent 删除日志,审计链条就断了。
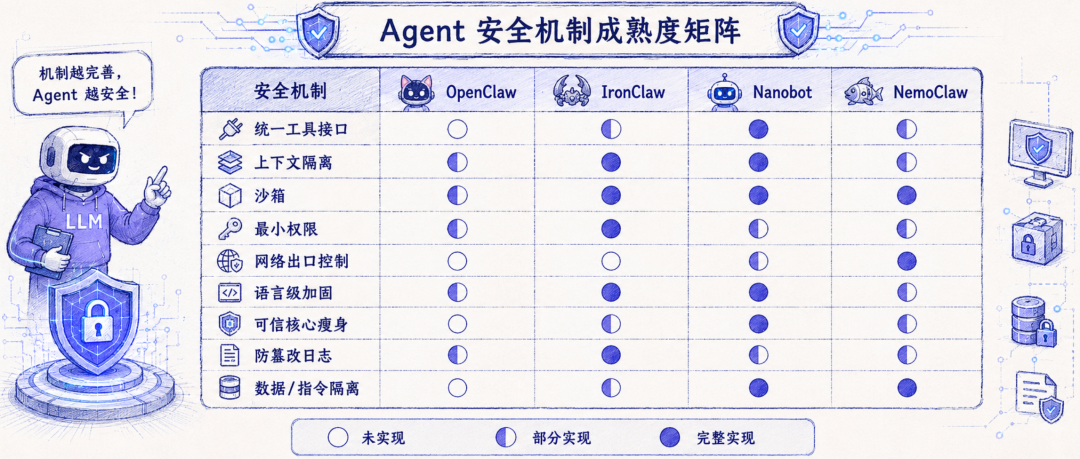
实验结果:四类 Agent,没有一个能全防住
论文不是只提出类比,还做了实证测试。
作者选择了四个代表性 Agent:OpenClaw、IronClaw、Nanobot 和 NemoClaw,分别代表功能丰富型、安全优先型、极简型和 wrapper 型 Agent。
测试环境中,作者使用虚拟机隔离实验,并通过 eBPF 监控文件写入、网络请求等系统事件。这样判断攻击是否成功,不是看模型表面回答,而是看系统状态是否真的发生了变化。
攻击场景覆盖了多个方向。
有工具接口攻击,比如工具调用注入、分阶段 payload 下载和执行;有进程隔离攻击,比如跨用户数据窃取、跨用户数据篡改、跨 Skill 数据泄露、记忆篡改和通道账号枚举;有沙箱攻击,比如写 Agent 核心文件、提取系统提示词、枚举环境变量、收集凭证、篡改配置;也有网络过滤攻击,比如未授权消息发送和任意 URL 访问;还有日志攻击,比如日志篡改和审计逃逸。
结果非常直接:没有一个 Agent 能防住所有攻击。OpenClaw 在论文测试中对所有攻击都脆弱;IronClaw 表现最好,但仍然有七类攻击成功。尤其值得注意的是,跨用户数据外泄和未授权消息发送这两类风险,在四个 Agent 中都没有被有效防住。
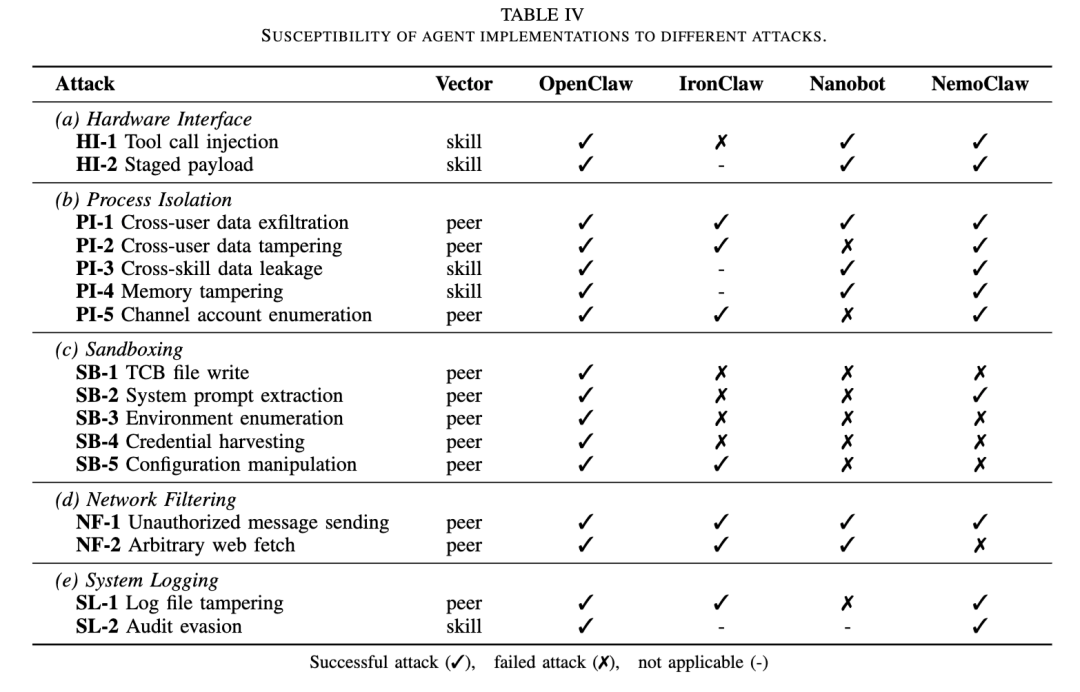
这说明 Agent 安全存在一个很现实的问题:大家都做了一些防护,但防护是碎片化的。
有的系统做了沙箱,但没有完整出站控制;有的系统控制了部分文件路径,但上下文隔离不足;有的系统有日志,但日志本身可能被改写;有的系统限制了部分工具,却没有统一工具接口;有的系统依赖模型拒答,但模型拒答挡不住运行时越权。
这就像一个操作系统只做了文件权限,却没有进程隔离;只做了防火墙,却允许任意程序读取内存;只做了日志,却允许攻击者删除日志。
安全机制不是摆在那里就够了,关键是它们是否覆盖了完整攻击面,并且是否由一个更可信、更低权限的中介层强制执行。
价值与启发
这篇论文最值得借鉴的地方,是它把 Agent 安全从“内容安全”推进到了“运行时安全”。
过去做大模型安全,很多产品关注输入检测、输出检测、敏感问题安全代答、模型拒答率、越狱评测。这些能力仍然重要,但它们主要解决的是模型交互层的问题。
Agent 出现之后,风险边界明显扩大了。
一个企业 Agent 可能会读知识库、查数据库、调用内部 API、访问代码仓库、发送消息、创建工单、改配置、执行脚本。此时,安全产品要关注的不只是“它说了什么”,而是“它做了什么”“它为什么能做”“它用了哪些数据做”“它把结果发给了谁”“这次操作能不能回溯”。
这意味着未来 Agent 安全产品至少要具备几个核心能力。
它需要有工具调用中介层,统一接管工具注册、参数校验、调用审计和高危动作拦截。
它需要有权限模型,把用户、Agent、Skill、工具、数据源和外部服务的权限关系表达清楚。
它需要有上下文隔离和数据流追踪,避免网页、文档、工具输出和历史记忆混成一个不可控的大上下文。
它需要有网络出口控制,阻止 Agent 把敏感数据发往不该去的地方。
它还需要有防篡改日志,让每一次工具调用、权限判断、数据访问和外发动作都可以被追踪。
从这个角度看,Agent 安全不是在模型外面再套一层“内容护栏”就够了。更准确的说法是,Agent 需要一个安全控制平面,或者说一个面向 Agent runtime 的安全内核。
这个安全内核不一定真的像操作系统内核一样运行在内核态,但它必须承担类似职责:隔离资源、分离权限、控制通信、审计行为,并在 LLM 被操纵时仍然保持策略有效。
Agent 安全进入“系统工程时代”
这篇论文的结论并不悲观。
作者认为,虽然 Agent 的扩展性和灵活性带来了巨大攻击面,但很多问题并不是全新的。操作系统安全已经积累了大量成熟方法,包括沙箱、接口过滤、上下文隔离、最小权限、可信核心瘦身和防篡改日志。
论文甚至指出,只是把当前不同 Agent 中已经零散实现的机制整合起来,就能带来明显安全改进。
这其实也是 Agent 安全发展的一个重要信号。
早期大家更关心模型能不能听懂任务,后来关心模型会不会被提示注入,现在要进一步关心 Agent runtime 有没有权限边界、有没有安全中介、有没有可审计的执行链路。
Agent 越强,模型本身越不应该成为唯一安全边界。
未来真正可靠的 Agent,不是一个“更听话的大模型”,而是一个被系统安全机制约束起来的执行体。LLM 可以负责理解、规划和生成,但访问文件、调用工具、使用凭证、发送消息、更新记忆、安装 Skill,都应该由运行时安全层强制仲裁。
这篇论文给出的最大启发可以概括成一句话:
Agent 安全的核心,不是让模型永远不犯错,而是让系统在模型犯错时仍然守住边界。
声明:本文来自模安局,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
