AI 安全过去很长一段时间都在处理一个相对清晰的问题:什么内容应该被允许,什么内容应该被拒绝。
这套逻辑在内容安全中非常重要。违法违规内容要拦截,隐私泄露要阻断,诈骗诱导要识别,恶意攻击要防护。对于这些明确风险,安全系统必须有清晰边界,不能含糊其辞。
但随着大模型进入 Agent 阶段,问题开始变得复杂。AI 不再只是生成文本,而是开始访问数据、调用工具、执行任务,甚至参与真实业务流程。此时,很多问题已经无法简单归入“安全”或“不安全”、“正确”或“错误”。
一个行为可能在结果上有利,却侵犯了权利;可能符合用户意图,却破坏了组织规则;可能提高效率,却伤害了关系与信任;可能看起来没有违规,却对第三方造成了隐性影响。
这正是论文 《Beyond Binary Moral Judgment: Modeling Ethical Pluralism in AI》 想讨论的问题。

https://arxiv.org/pdf/2605.28707
它提出,AI 的伦理判断不应该被简化成一个二元分类,而应该被建模为多种伦理理论之间的分布。
换句话说,AI 不只要判断一个行为是否合理,还要说明这个判断更接近结果主义、义务论,还是美德伦理,以及不同价值逻辑之间是否存在冲突。
论文作者明确指出,在医疗、法律、公共政策、就业、自动安全等高后果场景中,传统的预测性能指标并不足够,AI 还需要考虑权利、义务、意图、后果、关系影响以及不同伦理理论之间的权衡。
这篇文章真正有价值的地方,不是提出了一个新的分类模型,而是把一个更深层的问题摆了出来:
AI 不能只给出结论,它还要暴露结论背后的价值结构。
二元判断的局限:“解释贫乏”
现在很多 AI 安全系统,本质上还是二元判断系统。输入是否有风险,输出是否违规,工具调用是否允许,任务是否继续执行。系统可以给出一个结果,但很少解释这个结果背后到底依据了哪类价值判断。
这在明确风险场景下问题不大。比如用户要求生成诈骗话术,系统直接拒绝即可;用户要求泄露他人隐私,系统直接拦截即可。此时安全边界足够清楚,解释不是最核心的问题。
但在灰区场景里,二元判断就会变得粗糙。
比如,一个企业 Agent 根据内部数据整理员工绩效排序。从效率角度看,这可能帮助管理者快速决策;从权利和隐私角度看,它可能涉及授权边界;从组织关系角度看,它可能伤害团队信任。
再比如,一个个人 Agent 为了替用户争取利益,在沟通中刻意隐瞒部分事实。从结果角度看,它可能帮助用户达到目标;从诚实义务角度看,它可能破坏基本规则;从关怀伦理角度看,又可能被解释为保护弱势一方。
同一个行为,在不同价值框架下可能得到完全不同的解释。论文也用了类似例子说明:隐瞒信息可能被理解为功利主义上的减少伤害,也可能被理解为义务论上的维护制度规则,还可能被理解为关怀伦理中的保护弱势个体。
所以,问题不是 AI 不会判断,而是它经常只会给出一个判断。它可以说“可以”或“不可以”,但很难说明:这个结论到底是基于结果后果,还是基于权利义务,还是基于关系责任。
而在真正需要治理的场景中,解释本身就是安全能力的一部分。
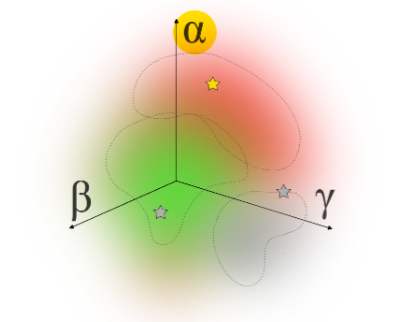
原文Figure 1 展示了一个三维伦理模糊空间,三个维度分别代表结果主义、美德伦理和义务论。图中同一个行为点可能落入多个伦理区域的交叠地带,用来说明一个行为并不天然只属于“道德正确”或“道德错误”。
价值判断并不只有一把尺子
论文的核心概念是 ethical pluralism,也就是伦理多元主义。
它并不是说“什么都可以”,也不是说“没有对错”。它强调的是,复杂伦理判断往往不是由一条原则单独决定的,而是由多种价值逻辑共同塑造的。
在规范伦理学中,论文主要使用了三条经典路径。
第一条是结果主义,关注行为后果,比如是否最大化整体收益、是否减少伤害。
第二条是义务论,关注规则、权利、义务和原则,比如是否侵犯个人权利,是否违反不可逾越的边界。
第三条是美德伦理,关注行为者的品格、动机、关系和关怀,比如是否体现责任、节制、诚实、同理心。
论文没有把这三类伦理理论当成互相排斥的标签,而是把它们放进一个共同空间里。每个案例都可以被表示成一个三元组:α、β、γ。
α 表示结果主义影响,β 表示美德伦理影响,γ 表示义务论影响,三者之和为 1。这样,一个伦理案例就不再只是“对/错”,而是变成了一个价值分布。
比如,一个案例可以被表示为:
结果主义 0.55,义务论 0.30,美德伦理 0.15。
这并不意味着结果主义一定正确,而是说明这个案例主要被结果主义解释,同时也包含义务论和美德伦理因素。越靠近某个伦理理论,说明它越容易被那套逻辑解释;越接近中心,说明它越模糊,也越可能需要人类介入。
这个设计很有启发。它让 AI 的伦理判断从“输出一个结论”,变成了“展示一组价值权重”。对 AI 安全来说,这意味着系统不只要知道风险标签是什么,还要知道风险判断背后的价值来源是什么。
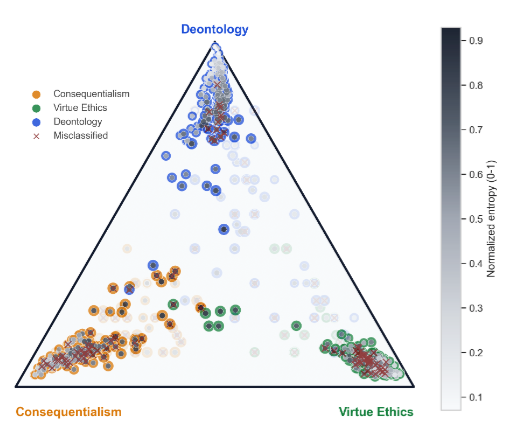
原文 Figure 3 是三角 simplex 图,三个角分别代表结果主义、美德伦理和义务论。图中越靠近中心,说明伦理分布越分散,不确定性越高;越靠近角落,说明伦理指向越明确。
从三大伦理理论,到 15 个细分子理论
为了让模型不只是识别三个大类,论文进一步把三大伦理理论拆成了 15 个子理论。
结果主义下面包括行为功利主义、规则功利主义、偏好功利主义、负功利主义和伦理利己主义。
义务论下面包括康德义务论、罗斯初显义务、神命论、契约主义和权利本位义务论。
美德伦理下面包括亚里士多德美德伦理、斯多葛美德伦理、儒家美德伦理、托马斯主义美德伦理和关怀伦理。
规范伦理学派 | 伦理子理论 | 描述 |
|---|---|---|
结果主义 | 行为功利主义 | 根据具体行为是否最大化效用来评价行为。 |
规则功利主义 | 根据能够产生最大善的规则来评价行为。 | |
偏好功利主义 | 以满足个体偏好为核心。 | |
负功利主义 | 相比最大化幸福,更优先最小化痛苦。 | |
伦理利己主义 | 推进决策者自身利益。 | |
义务论 | 康德义务论 | 强调普遍性的道德义务。 |
罗斯的初显义务 | 认为存在多种相互竞争的义务,需要结合具体情境进行平衡。 | |
神命论 | 遵从源自神圣权威的命令。 | |
契约主义 | 基于各方都可以接受的原则来为行为提供正当性。 | |
权利本位义务论 | 优先保护个体权利。 | |
美德伦理 | 亚里士多德美德伦理 | 优先关注美德品格与实践智慧。 |
斯多葛美德伦理 | 强调理性的自我控制与道德自律。 | |
儒家美德伦理 | 以社会和谐以及社会关系中的尊重为道德核心。 | |
托马斯主义美德伦理 | 将亚里士多德美德与神学原则结合起来。 | |
关怀伦理 | 优先关注同理心、关怀,以及对他人需求的回应。 |
这一步很关键。因为现实中的伦理判断并不是“结果主义、义务论、美德伦理”三个大标签这么简单。
同样是义务论,康德义务论强调普遍化原则,权利本位义务论强调个体权利保护,契约主义强调可被共同接受的原则。同样是美德伦理,儒家美德伦理更关注社会关系与和谐,关怀伦理更关注同理心、依赖关系和对他人需要的回应。
这就像内容安全中的标签体系。只说“有风险”太粗,必须进一步区分是暴力、诈骗、隐私、歧视,还是违法交易。伦理建模也是一样。只说“涉及义务”不够,还要进一步说明是权利保护、契约原则,还是多个义务之间的冲突。
不过,这里也要保持克制。论文自己也承认,这 15 个子理论并不是完整的伦理理论集合,只是为了实验建模和计算可操作性而选取的主流理论集合。
如果把这套方法引入中国语境下的 AI 治理,不能简单照搬。中国的 AI 安全治理还会涉及公共秩序、社会责任、平台义务、未成年人保护、组织合规、主流价值导向等维度。这些内容未必能被西方规范伦理学的三分法完全覆盖。
一条流理解伦理,一条流理解语义
论文提出的模型叫 Normative-Semantic Stream Architecture,可以理解成“规范伦理—语义双流架构”。
它不是简单把文本丢给一个大模型,然后让大模型直接回答“属于哪种伦理理论”。论文的思路更接近一个结构化治理系统:一条流负责生成伦理先验,另一条流负责理解文本语义和上下文,最后再把两类信息融合起来做分类。
第一条流是规范伦理先验流。它会为每个案例计算 α、β、γ 三个伦理理论对齐分数,并进一步计算主导理论、分数间隔、理论比例、熵等指标。这些指标的作用,是判断一个案例到底更接近哪种伦理理论,以及不同理论之间是否存在重叠和不确定性。论文使用开源 DeepSeek V3 生成这些伦理对齐分数,并将其作为后续建模中的规范伦理先验。
第二条流是语义和上下文流。它负责理解案例文本本身,以及案例中的结构化上下文。论文使用三个 sentence transformer 形成一个 1920 维的文本 supervector,再加入严重性、持续时间、效用、道德动机、遵守的原则、违反的原则等上下文特征。
最后,模型使用一个 stacked ensemble 做分类。底层模型包括 Random Forest、XGBoost 和线性 SVM,上层再用 XGBoost 作为 meta-learner 汇总预测结果。论文的目标不是单纯追求一个标签,而是学习不同伦理理论如何重叠、分化和相互作用。
这套架构对安全产品很有启发。它说明复杂治理问题不能只靠文本相似度,也不能只靠规则标签。真正可解释的系统,往往需要同时具备三类信息:自然语言语义、结构化上下文、规范化的价值框架。
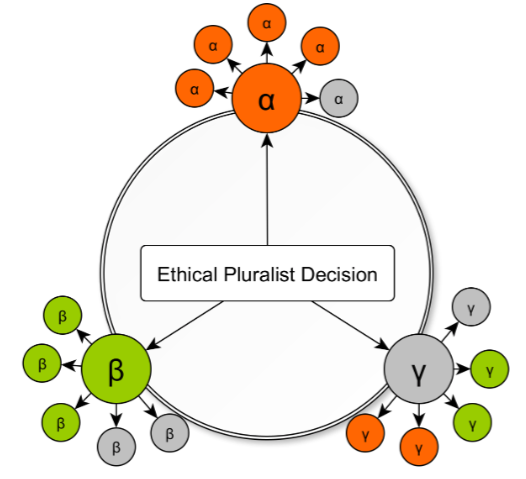
原文 Figure 2 展示了一个伦理多元决策结构:中心是 ethically plural decision,外部连接到三类规范伦理理论,并进一步展开到子理论。
实验结果
论文构建了一个包含 450 个自然语言伦理案例的小规模 benchmark,每个伦理子理论 30 个案例。这些案例来自已有的伦理模糊场景数据集,部分案例由 DeepSeek 进行增强,并结合领域专家进行推断和标注。
从结果上看,完整模型在 15 个伦理子理论分类任务上,exact-match accuracy 达到 88.89%,macro F1 达到 88.78%。
消融实验显示,如果去掉伦理先验,只保留语义向量和上下文特征,准确率会下降到 85.56%;如果去掉上下文,只保留伦理先验和语义向量,准确率下降到 81.11%;如果只使用文本 embedding,准确率为 77.78%。
这个结果说明,伦理先验和上下文信息确实给模型带来了额外增益。换句话说,伦理判断不能只靠“这段话像不像过去某个案例”,还需要理解案例中有哪些行为者、谁受影响、行为造成什么后果、动机是什么、违反了哪些原则。
但我认为,这篇论文真正值得关注的不是 88.89% 这个数字,而是它对不确定性的处理。
论文发现,模型能够给出超过 70% top-1 confidence 的案例只有大约 15%。也就是说,大多数伦理案例并不是模型可以非常自信地区分的。作者进一步指出,低置信度往往对应更强的伦理模糊性,或者不同伦理子理论之间存在重叠。
这对 AI 安全非常重要。因为在复杂伦理场景中,模型不确定并不是缺陷,反而是一种治理信号。一个成熟的系统不应该在灰区场景里假装确定,而应该承认不确定,并把这种不确定转化为人工复核、二次确认、更高等级授权或审计记录。
这也是从“模型安全”走向“系统治理”的关键差别。模型安全经常追求更高准确率,系统治理则必须知道什么时候不能自动决策。
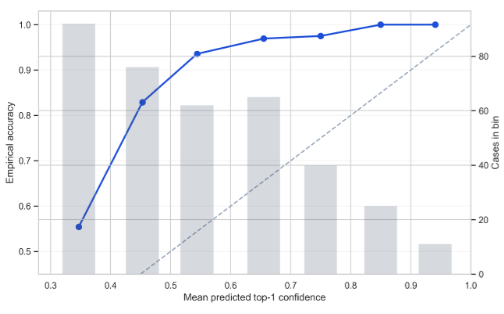
原文 Figure 5 是置信度分层曲线,用来说明模型置信度越高,实际准确率也越高;低置信度案例更可能对应伦理模糊或理论重叠。
对 Agent 安全的启发
如果只把这篇论文看成“伦理分类”,它可能显得偏学术。但如果放到 Agent 安全里看,它其实触及了一个越来越现实的问题:
Agent 的风险不只是内容风险,还有决策风险。
内容安全主要关注模型说了什么,Agent 安全还要关注模型做了什么。一个 Agent 可能会读取文件、调用数据库、发起审批、操作 SaaS 系统、修改配置、发送邮件、执行交易。很多动作本身不一定明显违法,也不一定命中某个显式风险标签,但它可能在价值层面存在冲突。
例如,Agent 为了提升效率,自动读取了多个系统中的用户数据并生成分析报告。结果主义会看到效率提升和业务收益,义务论会追问授权边界和隐私权,美德伦理会关注这种行为是否破坏信任关系。
再比如,Agent 为了帮助用户达成目标,在对外沟通中选择性呈现信息。结果主义可能强调目标达成,义务论可能强调诚实原则,关怀伦理可能强调对弱势一方的保护。
这类问题不能只靠“允许/拒绝”解决。因为真正的风险不是单一标签,而是价值冲突。
所以,Agent 安全需要在传统权限控制和风险检测之外,增加一层 伦理解释层。这层系统不一定直接决定最终动作,但它可以告诉我们:这个动作主要涉及结果影响、权利义务、关系责任,还是组织规则;这个动作是否存在第三方影响;当前模型是否足够确定;是否需要用户二次确认;是否需要人工审批。
这样,Agent 的行为就不只是“被规则拦住”或“被规则放行”,而是进入一个可解释、可审计、可追责的治理流程。
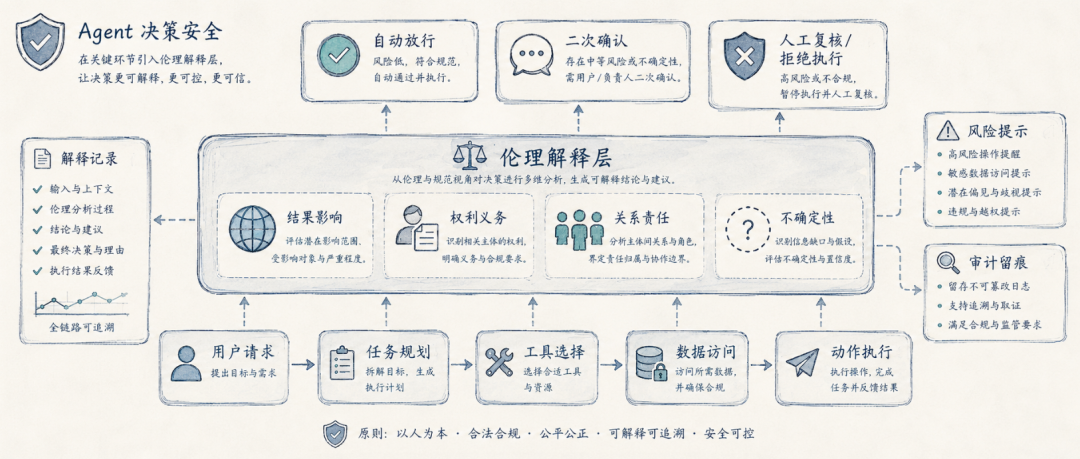
对大模型安全护栏来说,它提供的是“解释能力”的方向
今天的大模型内容安全护栏,通常会把风险拆成若干标签。比如违法违规、歧视仇恨、隐私泄露、暴力犯罪、自伤自残、诈骗诱导、色情低俗等。这些标签体系是必要的,也是安全产品的基础能力。
但随着大模型进入更复杂的业务环境,护栏不能只做“风险分类器”,还要逐步变成“治理解释器”。
所谓治理解释器,就是不只告诉用户“这句话有风险”,还要说明风险来自哪里。是因为它可能造成现实伤害,还是因为它侵犯权利,还是因为它违反授权边界,还是因为它会破坏关系信任,还是因为它涉及公共利益冲突。
这篇论文提供了一种可借鉴的方向:在现有风险标签体系之外,增加一层伦理解释标签。面对一个复杂请求,系统可以同时输出合规风险、权利影响、结果伤害、关系伤害、公共利益冲突和模型置信度。这样,安全系统就不只是简单拦截,而是形成一个可审计、可讨论、可复盘的治理链条。
监管场景也需要这种能力。监管并不只关心模型有没有拒答,还关心平台是否具备解释能力、纠错能力、人工复核能力和持续改进能力。如果安全系统能够把价值冲突结构化输出,就更容易形成检测报告、审核依据和整改闭环。
这里的关键变化是:过去的护栏更多是“命中规则”,未来的护栏需要逐步具备“解释规则”的能力。
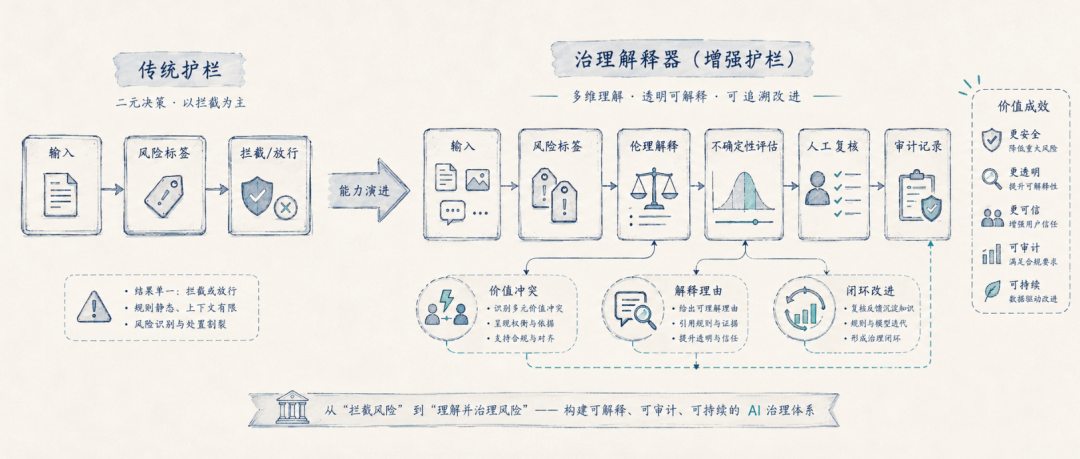
局限性
这篇论文值得关注,但不能被过度解读。
首先,它的数据集很小。450 个案例,每个子理论 30 个,适合做概念验证,但很难代表真实世界中的伦理分布。论文也明确承认,这个 benchmark 是小规模且平衡的,并不能反映真实环境。
其次,它依赖 LLM 生成伦理对齐分数。虽然作者提到这些分数经过专家引导和人类标注一致性验证,但仍然存在偏差风险。更直白地说,模型可能学到的是某个大模型对伦理案例的偏好,而不是社会中真实存在的价值分歧。论文也承认,LLM 生成先验存在偏差和偏离更广泛共识的风险。
再次,15 个子理论并不完整,无法代表所有文化、群体和伦理传统。论文也明确提到,这些子理论主要反映主流哲学话语,并不代表所有人口群体的规范伦理倾向。
最后,它目前还不是一个真正的伦理决策系统。它主要做的是伦理理论分类和不确定性分析,而不是解决伦理冲突。论文也承认,这个框架不会执行自适应冲突解决,只会折叠到最匹配的分类概率上。
所以,不能说这篇论文已经让 AI 学会了伦理判断。更准确的说法是,它提供了一种把伦理判断结构化、概率化、可解释化的早期尝试。
它像是一个“伦理雷达”。它能告诉我们一个案例靠近哪些价值区域,哪些理论之间存在重叠,哪里需要人类进一步判断。但它还不能直接替人类决定应该怎么做。
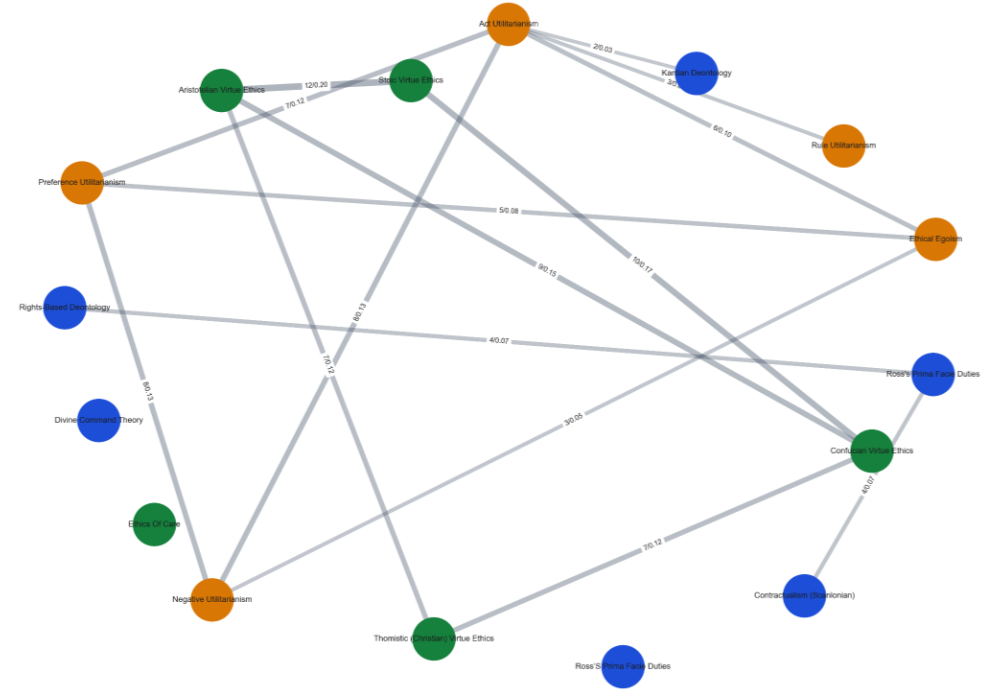
Figure 4展示不同子理论之间的混淆关系和 bridge theories。
AI 安全要从“规则拦截”走向“价值可审计”
过去我们讨论 AI 安全,很容易把重点放在模型输出上。模型有没有说错话,模型有没有输出违规内容,模型有没有被越狱,模型有没有泄露隐私。
但 Agent 时代的安全问题会更复杂。因为系统不只是“说”,还会“做”。它不只是回答用户的问题,还会代表用户行动;不只是生成文本,还会参与流程;不只是调用工具,还可能影响真实世界中的利益分配、组织秩序和社会关系。
当 AI 开始进入这些场景时,我们需要的不只是一个更强的分类器,而是一套能够解释决策的治理结构。它要能说明:这个动作为什么被允许,为什么被拦截,为什么需要二次确认,为什么必须人工复核。更进一步,它还要能说明:这个判断背后考虑了哪些价值,忽略了哪些价值,不确定性来自哪里。
这篇论文的价值就在这里。它没有解决所有问题,但它把一个重要方向说清楚了:
AI 不应该只会判断对错,还要说明自己站在哪套价值逻辑上。
对于未来的 Agent 安全产品来说,这可能会演化成一种新的能力层。底层是身份、权限和工具调用控制;中间是风险检测、策略执行和行为约束;上层则是伦理解释、不确定性识别和治理审计。只有这三层结合起来,Agent 才不会只是一个能干活的自动化系统,而是一个可以被组织、用户和监管共同约束的可信执行体。
写在最后
如果用一句话概括这篇论文,我会说:
它把 AI 的道德判断,从“输出一个结论”,推进到了“展示一组价值权重”。
这件事看起来像伦理学问题,实际上也是 AI 安全问题。因为越是高后果场景,越不能只依赖模型给出一个确定答案。
真正可治理的系统,应该能够识别风险,也能够识别分歧;能够执行策略,也能够解释策略;能够自动决策,也知道什么时候必须停下来交给人。
二元判断仍然重要。没有清晰边界,安全系统就会失去底线。但仅有二元判断已经不够。未来的 AI 安全,尤其是 Agent 安全,会越来越多地面对灰区、冲突和不确定性。
到了那个阶段,问题就不只是“拦不拦”,而是:
为什么拦?
为什么放行?
为什么不确定?
为什么需要人类重新介入?
能回答这些问题的系统,才真正具备走向高后果场景的基础治理能力。
声明:本文来自模安局,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
