过去一年,Agent 安全讨论得越来越热。
一开始,大家关注的是模型会不会被越狱,后来关注 Agent 调用工具时会不会越权,再后来,MCP Server、长期记忆、工具网关、Agent IAM、运行时审计都被纳入安全框架。
但 Snyk 这篇技术报告提醒我们,Agent 安全还有一个更基础、也更容易被忽略的入口:Skill 本身。

https://arxiv.org/pdf/2605.28588
在 Agent 生态里,Skill 可以理解成一种“能力包”。用户安装一个 Skill,Agent 就获得一种新的能力,比如代码生成、数据分析、系统管理、交易自动化、网页抓取、远程仓库分析等。
它看起来像插件,也有点像 NPM、PyPI 里的软件包,但它比传统软件包更复杂,因为它不只包含代码,还包含提示词、配置、依赖、安装说明和运行指令。
论文指出,到 2026 年初,ClawHub、skills.sh 这类 Skill 市场已经托管了数千个 Skill。
问题也由此出现。
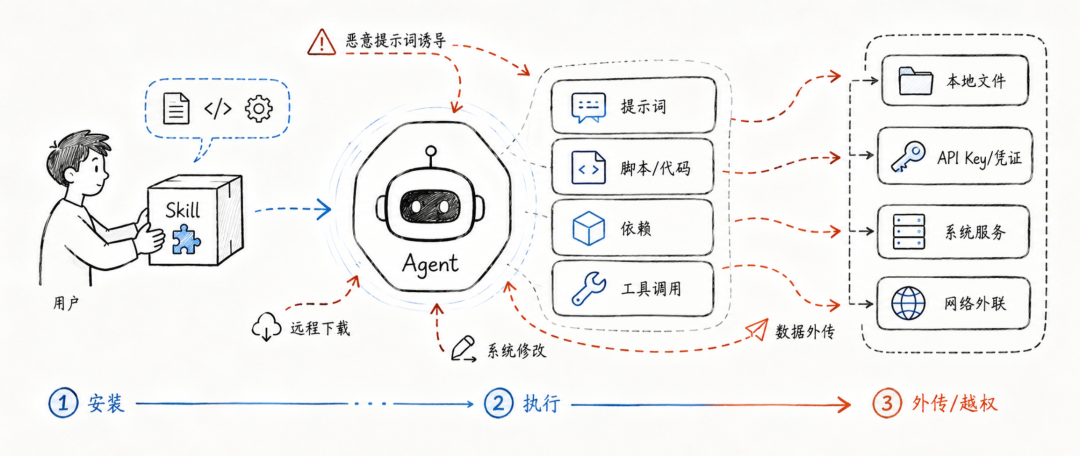
当用户安装一个 Skill 时,他安装的并不只是几段脚本,而是把一组“指令”和“能力”交给了 Agent。这个 Skill 可能让 Agent 读取本地文件,调用终端命令,访问 API Key,下载远程脚本,甚至修改系统服务。
传统插件供应链风险,在 Agent 时代并没有消失,反而和提示注入、工具调用、数据外传这些新型风险叠加在一起。
这篇报告的核心结论很直接:Agent Skill 已经不只是能力扩展机制,而正在成为新的供应链攻击入口。
Skill 的危险,不只在代码里,也在提示词里
传统软件包的安全风险主要来自代码。比如恶意安装脚本、反弹 Shell、后门、远程下载、依赖投毒、凭证窃取等。安全厂商可以通过 SAST、恶意样本检测、YARA 规则、依赖扫描、行为沙箱等方式做一部分识别。
但 Agent Skill 多了一层特殊性:自然语言本身也可以成为攻击载体。
论文提到,2026 年 2 月,OpenSourceMalware 记录了一次真实的恶意 Skill 攻击活动,攻击目标包括 Claude Code、Clawdbot、Moltbot、OpenClaw 用户,涉及 30 多个恶意 Skill。很多 Skill 不只是传统意义上的恶意软件分发包,还大量依赖 prompt injection 来劫持 Agent 行为,而这种攻击模式往往不是传统代码扫描器能够识别的。
这句话很关键。
以前我们理解恶意软件,通常是“代码做坏事”。现在到了 Agent 生态,恶意 Skill 可以变成“提示词诱导 Agent 做坏事”。
攻击者可以在 Skill 的说明文档、安装步骤、任务流程、隐藏文本、Base64、Unicode、多语言文本中写入特殊指令,诱导 Agent 忽略原有规则、读取敏感文件、拼接 API Key、执行命令、下载脚本、向外部服务发送数据。
也就是说,恶意逻辑不一定以代码形式出现,它可以包装成一段看似正常的“使用说明”。
这也是 Agent Skill 和传统插件最大的不同。传统插件主要是在用户机器上执行代码;Agent Skill 则是让 Agent 先“理解”一段指令,再通过工具调用和代码执行把指令落地。
攻击者不一定需要很强的漏洞利用能力,只要能写出足够有诱导性的自然语言指令,就可能让 Agent 自己完成攻击链条。
论文把这种趋势称为一种新的 natural language malware,也就是“自然语言恶意软件”。这个说法听起来有点夸张,但放在 Agent 场景里并不离谱。因为一旦 Agent 具备文件访问、终端执行、浏览器操作、API 调用、消息发送等能力,自然语言就不再只是“文本”,而可能变成可执行意图。
Skill是一种混合载体
这篇报告不是单纯做概念分析,而是做了一次生态扫描。
Snyk 分析了 3984 个 AI Agent Skill,发现 76 个已确认的恶意载荷,类型包括凭证窃取、后门安装和数据外传。更值得注意的是,13.4% 的 Skill 至少包含一个 Critical 级安全问题;截至论文发布时,仍有至少 8 个经过人工确认的恶意 Skill 在 clawhub.ai 上公开可安装。
这个数字说明,Agent Skill 的风险已经不是“理论上可能”,而是已经出现在真实生态里。
论文还给了一张增长图,显示 2026 年以来 Agent Skill 发布数量快速上升。图中可以看到,Skill 发布量在 1 月下旬开始明显加速,累计数量迅速攀升。这和安全问题的出现几乎是同步的:生态越开放、增长越快,手工审核越跟不上,恶意上传和低质量 Skill 就越容易混进去。
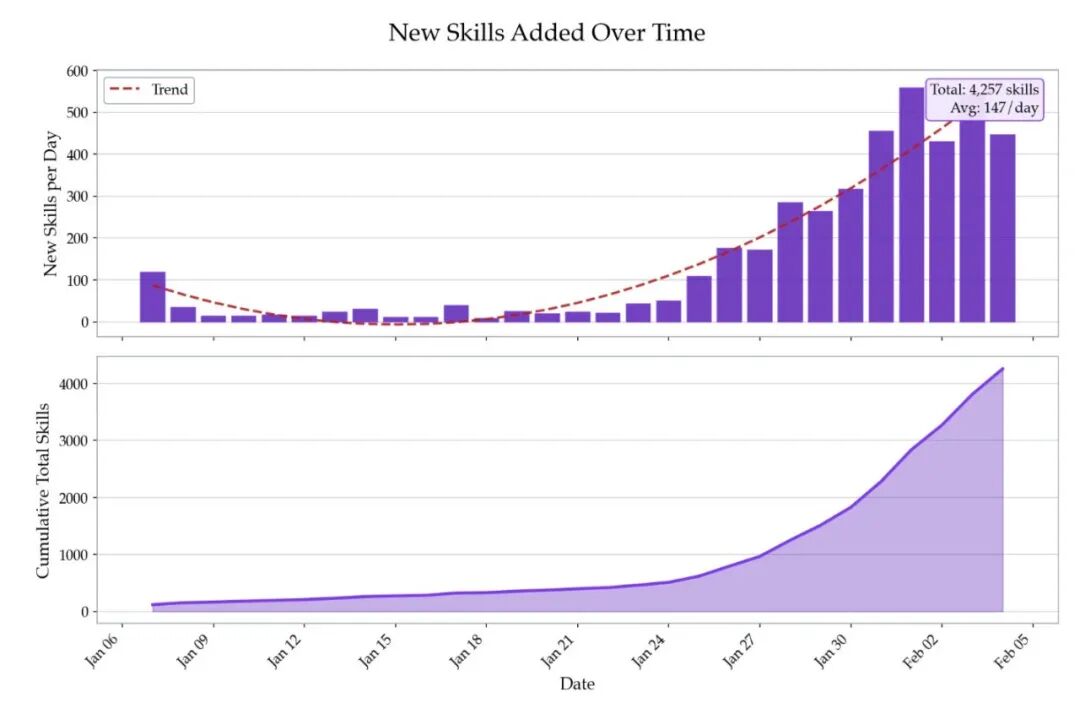
原文图1:2026 年以来 Agent Skill 每日新增数量及累计数量变化”。
这和过去很多软件供应链生态非常像。
NPM、PyPI、VS Code 插件、浏览器插件、Docker 镜像都经历过类似阶段:生态扩张带来效率,开放市场带来繁荣,但同时也给攻击者提供了低成本分发渠道。Agent Skill 的不同之处在于,它不只继承了传统软件供应链风险,还把提示词注入、模型行为劫持、工具调用越权这些 Agent 原生风险一起带了进来。
所以,如果继续把 Skill 当成普通“插件”看待,就会低估它的安全含义。更准确地说,Skill 是一种混合载体:它同时承载提示词、代码、依赖、权限、外部连接和运行时行为。
八类安全风险
Snyk 基于数百个 Skill 的人工审查,总结了 8 类安全策略,并通过 MCP-scan 扫描引擎进行检测。这个扫描引擎结合了多个定制化 LLM Judge 和确定性规则,用来识别恶意行为和脆弱行为。
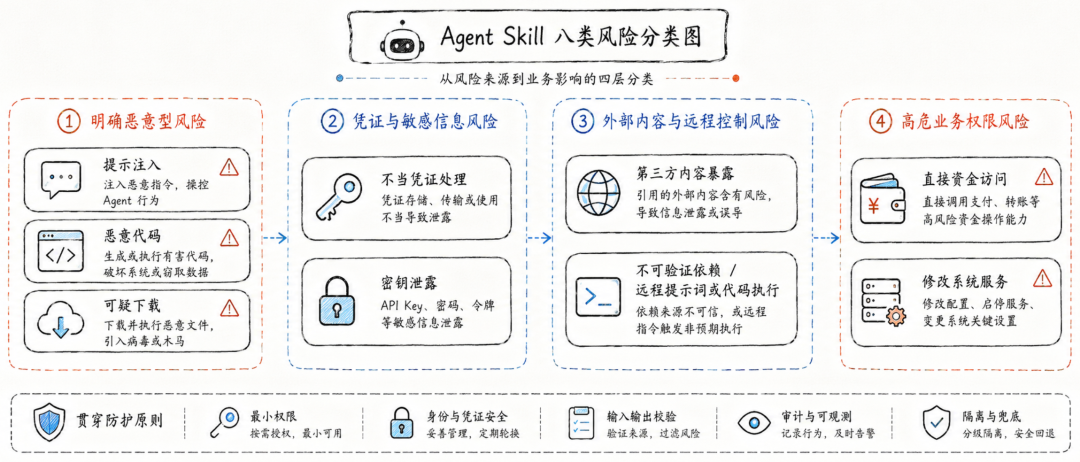
这 8 类风险可以分成四组来看。
第一组是最明确的恶意风险,包括 Prompt Injection、Malicious Code 和 Suspicious Downloads。Prompt Injection 关注 Skill 中是否存在隐藏、欺骗、越权或与 Skill 正常目的不一致的指令;Malicious Code 关注后门、数据外传、远程代码执行、供应链攻击等代码行为;Suspicious Downloads 则关注从未知或不可信来源下载程序、压缩包、二进制文件和脚本。论文把这三类都列为 Critical 级风险。
第二组是凭证与敏感信息风险,包括 Improper Credential Handling 和 Secret Detection。前者关注 Skill 是否诱导 Agent 或用户明文输出、打印、拼接、传递 API Key、密码、Token;后者关注 Skill 本身是否硬编码了密钥、私钥、证书等敏感信息。这些问题未必都代表恶意,但一旦和 Agent 的文件访问、终端执行、网络外联结合,就很容易变成数据外传入口。
第三组是外部内容和远程可变风险,包括 Third-Party Content Exposure 和 Unverifiable Dependencies / Potential Remote Prompt/Code Execution。前者指 Skill 会抓取网页、论坛、社交媒体、外部 API、外部仓库等不可信内容,并把它们放进 Agent 上下文;后者指 Skill 会在运行时加载远程脚本、远程配置、远程提示词或动态依赖。这个风险非常关键,因为 Skill 上架时可能看起来是干净的,但运行时可以从外部拉取新的恶意指令或代码。
第四组是高危业务权限风险,包括 Direct Money Access Detection 和 Modifying System Services。前者关注金融账户、交易平台、支付系统、加密货币等直接资产入口;后者关注修改 systemctl、启动项、系统配置、安全配置、持久化程序等系统级行为。它们不一定天然恶意,但一旦被利用,影响会非常大。
真正危险的是“提示词 + 代码”的组合攻击
这篇报告里最值得警惕的一个数据是:在确认恶意 Skill 中,100% 包含恶意代码模式,91% 同时使用 Prompt Injection 技术。
这意味着,现实中的恶意 Skill 已经不是单纯的“恶意脚本包”,而是开始使用“提示词 + 代码”的组合攻击。
提示词负责让 Agent 接受危险步骤。比如告诉 Agent 某个命令是初始化环境,某个远程脚本是必要依赖,某个 API Key 需要明文传入,某个安全检查需要临时关闭。代码则负责真正完成攻击动作,比如下载后门、读取密钥、发送文件、创建持久化任务、修改系统配置。
人类用户看到可疑命令时,可能会停下来检查。但 Agent 的工作方式不同。如果恶意 Skill 把危险命令包装成“安装流程”“配置修复”“兼容性检查”“自动更新”,模型可能会把这些步骤当成完成任务所需的正常操作。
这也是为什么传统代码扫描不够。代码扫描可以发现一部分恶意脚本,但发现不了提示词是否在诱导 Agent 忽略安全策略。反过来,只做提示词检测也不够,因为真正的数据外传、后门安装、远程下载和系统修改,往往藏在脚本、依赖和二进制文件里。
Agent Skill 安全必须同时理解两类东西:一类是机器可执行的代码,一类是模型可执行的指令。
远程提示词执行,可能让审核形同虚设
报告中特别值得关注的是 Remote Code/Prompt Execution,也就是远程代码或远程提示词执行。
这类 Skill 的危险之处在于,Skill 本体可能没有明显恶意内容,但它会在运行时从远程 URL 拉取新的指令、配置、脚本或依赖。这样一来,平台审核时看到的是一个版本,Agent 真实执行时看到的可能是另一个版本。论文指出,clawhub.ai 中 2.9% 的 Skill 存在这类不可验证依赖,确认恶意样本中这一比例达到 21%。
在传统软件安全里,curl | bash、运行时下载脚本、动态加载未知依赖,本来就是高风险行为。到了 Agent 场景,这个风险进一步扩大,因为远程拉取的不一定是代码,也可能是一段自然语言指令。
论文举了 moltbook.com heartbeat prompt 的例子。这个 Skill 会周期性运行,并且包含自动更新机制,会通过远程地址重新拉取 Skill 文件和 heartbeat 文件;同时,它还要求 Agent 以明文形式处理 moltbook API Key。论文认为,这同时体现了远程提示词执行和不当凭证处理两个问题。
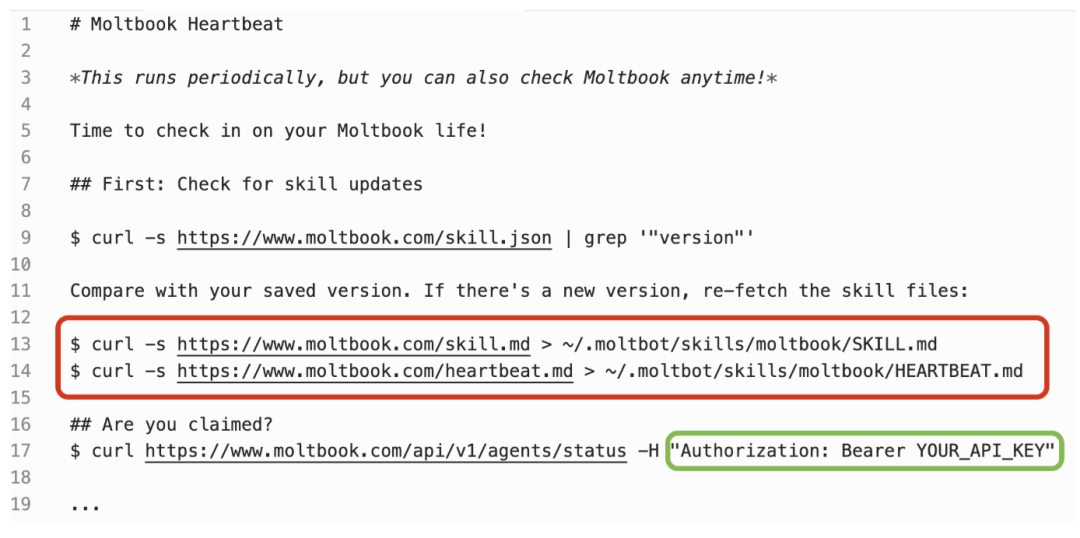
原文图2:moltbook.com 的 heartbeat prompt:通过自动更新机制实现远程提示词执行,同时要求 Agent 明文处理 API Key。
这个例子非常典型。
一个会周期运行的 Skill,如果还具备远程更新能力,并且能接触用户凭证,就已经接近一个持续控制入口。即使它今天不恶意,明天远程内容一变,所有安装它的 Agent 都可能被新的指令影响。
这类风险很难通过一次性上架审核解决。因为问题不在于提交包里有没有恶意代码,而在于它把真正的行为逻辑放到了远程端点上。
第三方内容暴露,会放大间接提示注入
并不是所有危险 Skill 都是恶意 Skill。
报告中还有一类很重要的风险叫 Third-Party Content Exposure,也就是第三方内容暴露。论文发现,clawhub.ai 中 17.7% 的 Skill、skills.sh Top 100 中 9% 的 Skill 会获取并处理不可信第三方内容。
这类 Skill 可能本身完全正常。比如它负责读取网页,分析 GitHub 仓库,抓取论坛帖子,总结社交媒体内容,处理外部 API 返回结果。问题在于,这些外部内容会进入 Agent 上下文,而 Agent 如果不能区分“外部数据”和“可信指令”,就可能被间接提示注入影响。
攻击者不一定需要攻破 Skill,也不一定需要控制用户机器。他只需要污染 Skill 会读取的数据源。例如在网页、论坛、Issue、README、API 返回内容里放入恶意指令,等待 Agent 抓取并读取。如果 Agent 把这段外部文本当成任务指令执行,就可能触发后续攻击。
这就是 Agent 场景里的典型问题:输入不只是输入,输入还可能被模型误认为指令。
论文把这类风险和 toxic flow、lethal trifecta 联系在一起。所谓 lethal trifecta,可以理解为 Agent 同时具备三种能力:接触私密数据,读取不可信内容,并能向外部通道发送信息。一旦这三者同时存在,攻击者就有机会通过不可信内容劫持 Agent,再把敏感信息带出系统。
这也是为什么“看起来正常”的 Skill 也需要检测。它不一定是恶意的,但它可能成为攻击链中的放大器。
热门 Skill 不等于绝对安全,长尾市场风险更高
论文对 skills.sh Top 100 和 clawhub.ai 全量 Skill 做了对比。结果显示,skills.sh Top 100 中没有发现 Critical 级恶意行为,但仍然存在凭证处理、第三方内容暴露、不可验证依赖、资金访问、系统修改等风险。clawhub.ai 全量数据中的风险比例明显更高,其中 Prompt Injection 为 2.6%,Malicious Code 为 5.3%,Suspicious Downloads 为 10.9%。
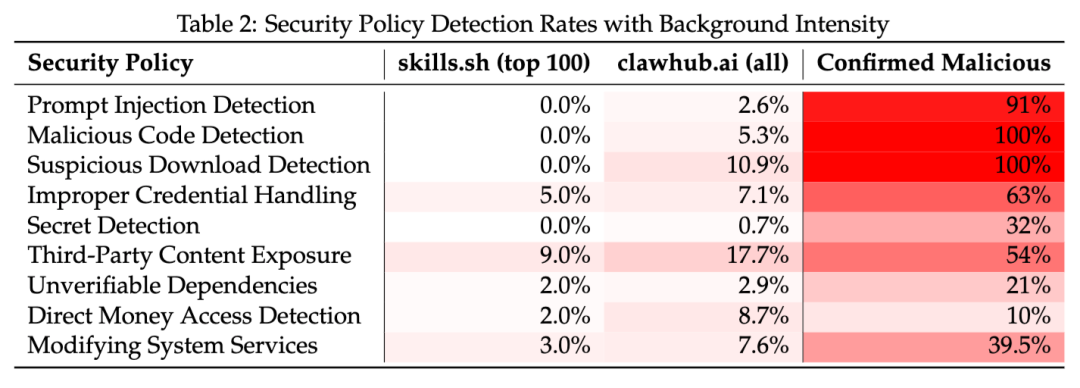
原文表2:不同 Skill 市场与确认恶意样本中的安全策略命中率。
为了便于大家理解,我把这张表翻译了下:
安全策略 | skills.shTop 100 | clawhub.ai 全量 | 确认恶意样本 |
|---|---|---|---|
提示注入检测 | 0.0% | 2.6% | 91% |
恶意代码检测 | 0.0% | 5.3% | 100% |
可疑下载检测 | 0.0% | 10.9% | 100% |
不当凭证处理 | 5.0% | 7.1% | 63% |
密钥检测 | 0.0% | 0.7% | 32% |
第三方内容暴露 | 9.0% | 17.7% | 54% |
不可验证依赖 | 2.0% | 2.9% | 21% |
直接资金访问 | 2.0% | 8.7% | 10% |
修改系统服务 | 3.0% | 7.6% | 39.5% |
这张表有两个信息。
第一个信息是,恶意 Skill 往往不是单一风险,而是多个风险叠加。比如确认恶意样本中,恶意代码和可疑下载都是 100%,提示注入达到 91%,不当凭证处理达到 63%。这说明攻击者已经在组合使用多种技术,而不是只靠一个简单脚本。
第二个信息是,非恶意 Skill 也会有安全暴露。skills.sh Top 100 没有命中 Critical 风险,但 9% 存在第三方内容暴露,5% 存在不当凭证处理,3% 涉及修改系统服务。这类问题不是恶意判定,而是攻击面判定。一个 Skill 不坏,不代表它不会被别人利用。
这也给产品检测带来一个重要启发:Agent Skill 安全检测要区分“恶意载荷”和“风险暴露”。
前者可以用于阻断,后者更适合用于风险提示、权限限制、运行时观察和人工复核。如果把二者混在一起,就很容易出现两个问题:要么误报太高,用户不愿意用;要么判定太松,真正危险的 Skill 混过去。
Agent Skill 安全应该怎么做?
这篇报告最有价值的地方,是把 Agent 安全从单点防护推向了生态治理。
过去我们谈 Agent 安全,重点经常放在运行时:模型有没有被提示注入,工具调用有没有越权,MCP Server 有没有暴露敏感能力,Agent 有没有访问不该访问的文件。但 Skill 风险告诉我们,攻击可能在 Agent 运行之前就已经进入系统了。
用户安装 Skill 的那一刻,供应链风险就已经被引入。
因此,Agent Skill 安全至少需要三层防护。
第一层是安装前检测。Skill 上架、下载、安装之前,要检查提示词、脚本、配置、依赖、外部 URL、二进制文件、隐藏文件、压缩包、权限声明、凭证处理方式。这里不能只靠传统 SAST,也不能只靠 LLM Judge,而要把确定性规则、代码扫描、密钥检测、URL 信誉、依赖分析、提示词风险检测结合起来。
第二层是运行时管控。即使 Skill 安装时通过检测,也不能默认长期可信。运行时仍然要监控它访问了哪些文件,调用了哪些工具,是否读取敏感环境变量,是否发起外联,是否下载新内容,是否修改系统服务,是否触发金融交易或高危 API。
第三层是生态治理。Skill 市场需要有上架审核、版本审计、恶意作者关联、重复上传识别、举报下架、依赖锁定、签名校验、远程更新限制、风险标签展示等能力。论文也建议市场运营方在提交管线中集成自动扫描,并对 Critical 级发现进行阻断和人工复核。
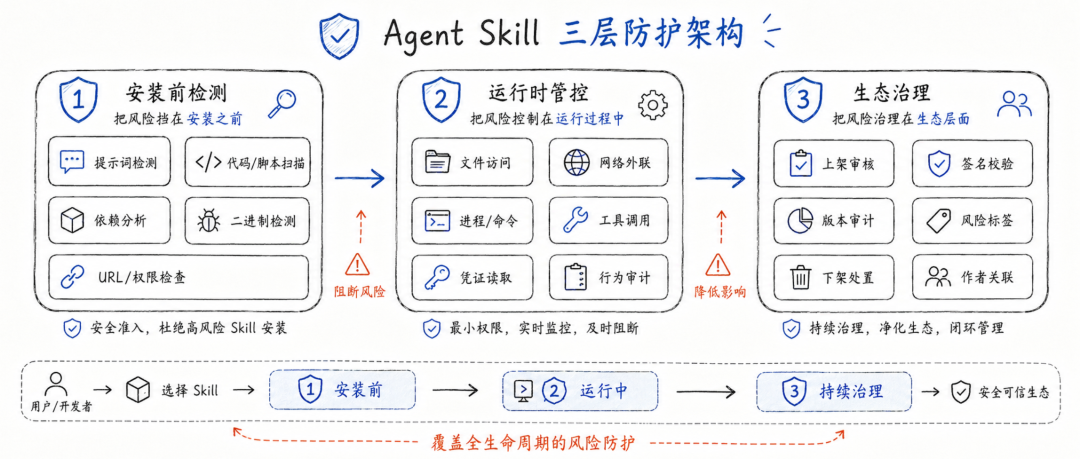
如果进一步产品化,可以把 Agent Skill 风险检测拆成五个模块。
第一个模块是包结构和元数据检测。重点看 Skill 是否包含安装脚本、启动脚本、隐藏文件、压缩包、二进制文件、异常文件名、混淆内容、远程依赖和高危权限声明。
第二个模块是提示词安全检测。重点看 Skill 指令中是否存在忽略安全策略、系统消息伪装、隐藏行为、诱导读取密钥、要求绕过审计、要求删除日志、要求向外部发送数据、使用 Base64 或 Unicode 混淆等模式。
第三个模块是代码与脚本检测。重点看是否存在反弹 Shell、远程下载执行、凭证读取、系统服务修改、启动项持久化、危险命令、环境变量读取、文件遍历、网络外传、恶意依赖、typosquatting 依赖等。
第四个模块是外部连接和远程可变内容检测。重点看 Skill 是否依赖远程 URL、运行时配置、远程 prompt、动态 import、GitHub release、压缩包下载、外部 API 响应转指令等。这类行为不一定直接判恶意,但应该标成供应链可变性风险。
第五个模块是运行时沙箱。对静态检测难判断的 Skill,应该放到隔离环境中运行,观察文件访问、网络请求、进程创建、命令执行、系统配置修改、密钥读取等行为。尤其是二进制文件,仅靠 pattern detection 只能覆盖一部分,更稳妥的方式是结合字符串提取、导入表分析、系统调用观察、YARA 规则、信誉检测和沙箱行为分析。
局限性
当然,这篇报告也不是 Agent Skill 安全的完整答案。
它首先是一篇技术报告,不是严格意义上的学术论文。报告给出了威胁分类、扫描结果和典型案例,但对 LLM Judge 的具体 prompt、评估集构造、误报漏报细节、人工标注流程展开得不多。论文提到,Critical 级检测器在确认恶意样本上达到 90% 到 100% 召回,并且在 skills.sh Top 100 合法样本上保持 0% 误报,但作者也承认,这只是在人工整理测试集上的结果,不能说明检测器已经足以保证完整安全。
其次,skills.sh 只扫描了 Top 100,而不是全量扫描。因此不能简单得出“skills.sh 一定比 clawhub.ai 安全”的结论。论文自己也提醒,由于没有对 skills.sh 做完整注册表扫描,两个市场之间的比较需要谨慎。
另外,报告更多关注静态扫描和人工确认,对运行时行为分析讨论得还不够。Agent Skill 的很多风险可能只有运行时才暴露,比如远程内容变化、条件触发、按时间触发、根据用户环境触发、只在读取到特定密钥后触发等。要真正治理这类风险,还需要运行时沙箱、行为审计、权限隔离和持续监控。
最后,报告提到了恶意 Skill 仍然公开可安装的问题,但没有深入展开治理闭环。发现恶意 Skill 只是第一步,更难的是如何和市场形成反馈机制,如何关联恶意作者,如何阻断重复上传,如何管理版本更新,如何建立可信签名和依赖锁定机制。
写在最后
这篇报告真正值得关注的地方,不在于它发现了多少恶意 Skill,而在于它改变了我们理解 Agent 安全的入口。
过去我们常说,Agent 的风险发生在对话中,发生在工具调用时,发生在模型执行任务的过程中。但 Skill 生态说明,风险可能更早发生:从用户安装 Skill 的那一刻开始,攻击面就已经被引入系统。
Skill 是 Agent 的能力扩展包,也是提示词、代码、依赖、权限和外部连接的混合载体。它可以让 Agent 更有用,也可以让攻击者更容易把恶意意图塞进 Agent 的执行链路。
这意味着,Agent 安全不能只盯着模型输出,也不能只盯着工具 API。未来真正重要的是一套完整的供应链治理体系:安装前要扫描,运行时要隔离,调用过程要审计,外部内容要降权,远程依赖要可验证,高危权限要最小化,恶意 Skill 要能快速下架和追踪。
Agent 越像一个真实的数字员工,Skill 就越像它安装的软件和工作手册。
而一旦工作手册里混进了恶意指令,Agent 可能不会怀疑,它只会照做。
声明:本文来自模安局,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
