马利昭1 黄诚1 黎明2 牟浩天1 彭佳仁1 谢启亮1
(1. 四川大学网络空间安全学院,四川 成都 610207;2. 中国电子科技集团航空电子有限公司,四川 成都 611731)
摘 要高级持续性威胁(advanced persistent threat, APT)因其高度定向性、技术复杂性和长期潜伏性,对国家关键基础设施和重点行业构成严峻的安全挑战。在现实场景中,APT检测既需实现早期预警,又面临APT域名数据稀缺的困境,导致传统基于通信流量特征或依赖大规模训练数据的神经网络方法难以奏效。为此,提出了一种基于多层次特征融合的APT域名归因方法。该方法融合了文本、统计、语义和关联属性4个层次的特征,将归因任务分解为APT域名检测与归因两个阶段。在检测阶段,通过提取域名的文本特征、统计特征和语义特征,结合支持向量机(support vector machine, SVM)分类器,实现从海量域名中高效筛选潜在APT域名。在归因阶段,补充由RoBERTa模型提取的深层语义特征,结合基于外部数据库查询的域名系统(domain name system, DNS)解析信息等关联属性特征,构建多层次特征表示。接下来采用K-means聚类算法对检测出的APT域名进行关联分析,实现向特定攻击组织的归因。实验结果表明,该方法在检测任务中F1分数达97.47%,在归因任务中调整兰德指数(ARI)达86.85%、标准化互信息(NMI)达90.74%。在真实场景中,该方法相较公开报告平均提前112天标记出18个APT域名,实现了从被动响应到主动防御的转变。
关键词高级持续性威胁;多层次特征融合;恶意域名检测;APT域名归因;提前预警
DOI:10.11959/j.issn.2096-109x.AQ25254
引用格式:
马利昭, 黄诚, 黎明, 等. 基于多层次特征融合的APT域名归因方法[J]. 网络与信息安全学报, 2026, 12(2): 132-142.
Ma L Z, Huang C, Li M, et al. APT domain attribution based on multi-level feature fusion[J]. Chinese Journal of Network and Information Security, 2026, 12(2): 132-142.
0 引言
应对高级持续性威胁(APT)攻击已成为国家关键基础设施和重点行业面临的最严峻网络安全挑战之一。2025年,360数字安全集团高级威胁研究院累计捕获针对我国的APT攻击1 300余起,受影响的单位主要分布于政府、教育、科研、交通运输等15个行业领域[1]。与普通网络攻击不同,APT攻击具有高度定向性、技术复杂性和长期潜伏性特征,攻击者常借助域名生成算法批量生成随机域名,以躲避传统基于签名和规则匹配方法的检测[2]。
早期针对恶意域名检测的研究[3-6],大多采用特征工程与传统机器学习相结合的方法。这类方法的核心在于提取出可以有效区分不同类别样本的特征。这些特征主要分为两类:一类是基于网络行为的动态特征,例如从域名系统(DNS)流量与日志记录中提取的特征,这类特征只能对已发生的攻击或网络活动进行分析,存在滞后性,难以满足APT检测的早期预警需求;另一类是基于域名字符串的静态特征,这类特征虽解决了滞后性问题,但仍未摆脱特征工程范式的固有局限(即特征设计高度依赖安全专家的领域知识和实战经验),导致泛化能力有限,难以应对APT攻击手法的持续演进。
为突破人工特征工程的瓶颈,后续研究[7-9]逐渐转向以深度学习为代表的自动特征学习方法。通过构建端到端的神经网络模型,这类方法能够从原始数据中自动挖掘深层的恶意模式,从而降低对专家知识的依赖。不过,深度学习方法的有效性高度依赖大规模、高质量且类别均衡的训练数据。在APT攻击场景中,由于其具有高度定向性和隐蔽性,APT域名训练数据存在恶意样本稀缺和类别不平衡问题。这不仅容易导致模型过拟合,也使其难以在真实网络环境中有效部署。
针对上述问题,本文提出一种基于多层次特征融合的APT域名归因方法。该方法融合了文本、统计、语义、关联属性4个层次的特征,将归因任务分解为APT域名检测与APT域名归因两个阶段。在检测阶段,通过提取域名的文本特征、统计特征和语义特征,并采用支持向量机(SVM)作为分类器,可以从海量域名中快速筛选出潜在的APT域名,减轻后续归因阶段的计算负担。在归因阶段,本文引入预训练模型RoBERTa,利用其在预训练阶段学习到的通用知识对域名进行向量化表征,在数据稀缺的场景下有效补充域名的深层语义特征。此外,本文还提取了基于外部数据库查询的关联属性特征,包括DNS解析模式、地理位置、域名注册信息查询协议(WHOIS)注册信息、安全套接层(secure sockets layer, SSL)协议证书属性、虚拟专用服务器(virtual private server, VPS)服务商IP归属等。最终,融合上述特征构建多层次特征表示,并采用K-means聚类算法对检测出的APT域名进行关联分析,实现向特定攻击组织的归因。实验结果表明,本文所提方法在APT域名检测任务中F1分数达97.47%,在APT域名归因任务中调整兰德指数(ARI)达86.85%、归一化互信息(NMI)达90.74%。在真实场景下的测试结果表明,相较于国内安全厂商的公开报告,本文方法平均提前112天标记出18个APT域名,实现了从被动响应向主动防御的转变,为应对APT威胁提供了新的思路。
本文的主要贡献如下。
1) 提出一种融合多层次特征的APT域名归因模型,能够从海量域名中检测与APT攻击相关的域名,并将这些APT域名归因到所属的APT组织。
2) 在真实场景中,相较于国内安全厂商的公开报告,所提方法能够平均提前112天标记出潜在的APT域名,提高了APT域名检测的早期预警能力。
1 相关工作
1.1 恶意域名检测技术
作为APT域名归因体系的基础环节,APT域名检测效果直接影响后续的归因效果。现有主流的恶意域名检测方法大致分为两类,即基于特征工程的检测方法和基于深度学习的检测方法。
基于特征工程的检测方法通过人工设计特征,并将提取的特征输入分类器,由分类器输出分类结果来实现检测。在恶意域名检测中,主流特征提取方式可以分为以下两类。
1) 从DNS流量中提取特征。Bilge等[3]从DNS查询流量中提取了15类特征,用于刻画域名及其查询方式的异常模式,能够自动识别各类恶意活动中的未知恶意域名。Mahdavifar等[4]从DNS流量中提取了基于词法的特征、基于DNS统计的特征、基于第三方应用程序接口(application programming interface, API)背景信息的特征,并采用K近邻(k-nearest neighbors, KNN)算法在两类数据集上取得了良好的检测效果。然而,这类检测方法的有效性依赖于已发生的攻击行为和网络活动,无法在APT域名投入使用之前就将其标记为潜在的恶意域名,故难以满足APT检测的早期预警需求。
2) 从域名字符串中提取特征。此为本文在APT域名检测阶段所采用的方法。Kidmose等[5]将域名特征划分为3组(一组为通用特征,其余两组为词汇特征),使用随机森林作为分类器进行检测,结果显示,词汇特征可以有效提升恶意域名的检测性能。Ghalati等[6]提出一种基于静态词汇特征的随机森林分类模型,用于区分恶意统一资源定位符(uniform resource locator, URL)与良性URL。该模型从URL中提取了3类特征,即黑名单特征、词汇特征和基于主机的特征。
基于深度学习的检测方法无须人工设计特征,只需将域名输入训练好的深度学习模型,即可自动学习并生成特征表示。根据是否需要针对特定任务数据集进行训练,可以将深度学习方法分为以下两类。
1) 基于从零开始训练的深度模型检测方法。此类方法采用的模型主要包括卷积神经网络(convolutional neural network, CNN)、长短期记忆网络(long short-term memory network, LSTM)、图神经网络(graph neural network, GNN)等。Vinayakumar等[7]对多种深度学习方法进行了评估,结果表明LSTM在恶意域名检测任务中表现更优。Chen等[8]提出了融合注意力机制的LSTM模型,通过注意力机制聚焦域名中的关键子字符串,从而提升域名表征能力。这类方法需要依赖大规模的训练数据来优化网络参数,从而提升域名特征表征能力。然而,由于APT域名数据稀缺,这类方法难以直接用于APT域名检测场景。
2) 基于预训练模型的检测方法。预训练模型通过在大规模通用语料上进行预训练,可以习得语言结构的通用表示。在APT域名检测中,预训练模型能够利用学习到的词汇先验知识对域名进行向量化表征,解决了数据稀缺难以训练深度学习模型的问题。Su等[9]基于双向编码器表示转换模型(BERT)的标记化方法及自注意力机制构建了一种面向恶意URL检测的深度学习框架,在3类数据集上均取得较高的分类精度。相较于采用静态掩码预训练策略的BERT模型[10],本文所采用的RoBERTa模型通过动态掩码、更大规模的训练数据和去除下一句预测任务的预训练策略[11],能够更精准地提取深层语义特征。
1.2 APT域名归因研究
在域名归因领域,域名和IP的WHOIS信息曾被用于检测域名的所有者[12]。然而,受隐私保护服务和数据脱敏的限制,WHOIS信息的实用性大打折扣,仅凭此类信息难以有效支撑归因任务。Sebastián等[12]构建了融合被动DNS、传输层安全(transport layer security, TLS)协议证书、网页内容等数据的域名归属分析框架,在真实场景下取得了94%的F1分数。Xiang等[13]提出一种基于IPv4的威胁归因模型IPAttributor,通过融合真实入侵行为数据与异构商业情报,结合动态加权社区发现算法,实现了对同源攻击者的追踪。
2 本文方法
2.1 整体框架
本文提出了一种基于多层次特征融合的APT域名归因方法。考虑到APT域名在海量域名集合中占比极低,若直接对所有域名进行归因分析,需向外部数据库发送大量的查询请求,导致计算开销和响应时延增加。为此,本文设计了一种双阶段架构,将APT域名归因任务分解为检测和归因两个阶段。检测阶段的目标是从海量域名中快速筛选出潜在的APT域名;归因阶段的目标是对这些潜在APT域名进行关联分析,将其归因至所属的APT组织。这种双阶段的架构设计能够有效减轻归因分析的计算负担,提升系统响应速度。所提方法的整体框架如图1所示。
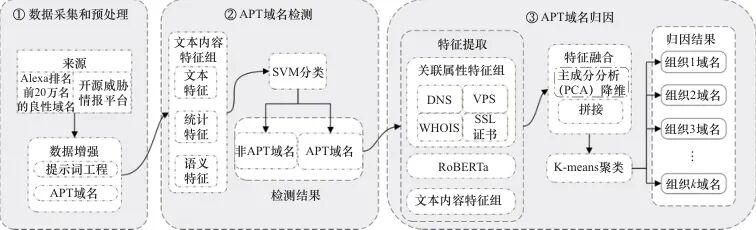
图1 所提方法的整体框架
整体框架包括数据采集和预处理、APT域名检测、APT域名归因3个模块。
1) 数据采集和预处理模块:通过整合Alexa排名靠前的良性域名和开源威胁情报平台获取的已知APT域名构建初始数据集,并利用生成式大模型进行数据增强以解决样本不均衡问题。该模块输出包含正负样本的数据集。
2) APT域名检测模块:对数据集进行特征提取,得到包含文本、统计和语义3个层次的文本内容特征组。利用提取出的特征和样本标签,有监督地训练二分类模型,用于从海量域名列表中检测出APT域名。APT域名检测模块输出数据集的二分类结果,其中被分类为APT域名的集合将被输入APT域名归因模块,以便分析其归属。
3) APT域名归因模块:针对检测出的潜在APT域名,通过向外部数据库发送查询请求,获取域名的DNS解析模式、WHOIS注册、SSL证书等信息,并从中提取出域名的关联属性特征组。随后,通过融合文本内容特征组、关联属性特征组与RoBERTa提取的深层语义特征,采用K-means聚类算法将检测出的APT域名关联到特定攻击组织。
2.2 数据预处理
2.2.1 数据增强
针对APT域名检测任务中正样本稀缺的问题,传统的数据增强方法主要侧重于字符层面的扰动[14-15],容易破坏APT域名中隐含的组织命名习惯或特定偏好,导致生成的样本偏离真实分布,形成无效噪声[16]。为此,本文提出一种领域知识引导的生成式数据增强方法。该方法通过在提示词中融入专家先验知识、域名构造模板和特定的统计约束,诱导模型模拟攻击者的思维逻辑生成合成域名。这种方法不仅可以保证生成样本的文本多样性,还能够在深层语义层面保持与真实APT域名样本的一致性。用于生成域名数据的提示词如图2所示。

图2 数据增强提示词
2.2.2 域名分词
为提取域名的语义结构与局部模式,本文设计了如下分词预处理流程。
分隔符分词:依据“.”“-”“—”3个分隔符对域名字符串进行切分。例如,“windows-verifyprotection.org”将被分解为词元列表[‘windows’, ‘verifyprotection’, ‘org’],保留了各部分的层级顺序,称这一结果为初步分词结果。
语义分词:部分域名中存在多个单词邻接出现形成一个字符串的情况(如verifyprotection),本文将这种字符序列称为邻接词,将针对邻接词的分词方法称为语义分词。经过语义分词后,上述域名最终被分解为[‘windows’, ‘verify’, ‘protection’, ‘org’],称这一步的结果为最终分词结果。
2.3 APT域名检测
APT域名检测模块旨在高效地从海量域名集合中检测出潜在的APT域名,检测出的域名将用于后续的归因分析。该模块采用基于多特征融合的机器学习方法,通过提取域名的文本特征、统计特征和语义特征,构建高效的分类模型,实现对APT域名的自动化检测。
2.3.1 文本内容特征提取
为实现APT域名检测,本文设计了如表1所示的文本内容特征组,用于对域名进行向量化表征。文本内容特征的定义如下:直接从域名字符串文本内容中提取、无须依赖外部数据或协议,聚焦于域名的结构、字符分布和统计规律的特征。文本内容特征组包含文本特征、统计特征[17]和语义特征。文本特征是指直接描述域名本身的结构、组成和显性文本属性的特征,聚焦于可直接观察的文本信息。统计特征是指基于域名的分词结果,通过数学计算或量化分析得出的特征,反映域名的字符分布、组合规律、随机性。语义特征是指用于描述域名在语言意义层面的特征,关注域名与特定关键词的关联性。这里的关键词与编辑距离特征中的关键词相同,均为数据样本中恶意域名分词结果中出现频次最高的前5个单词。
表1 文本内容特征组
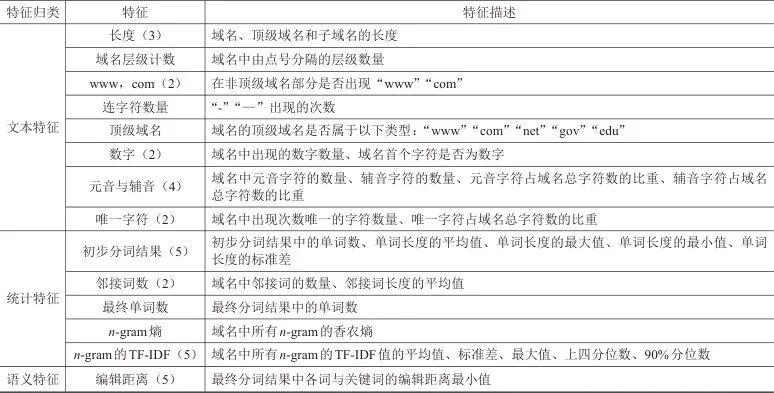
注:特征栏中括号内数字表示该特征包含的子特征数量。
下面对表1中的部分特征进行详细介绍。
(1)n-gram熵
APT组织常采用域名生成算法批量生成域名,导致其域名在字符组合上呈现出一定的随机性[18]。在APT域名检测任务中,n-gram是指域名字符串中长度为n的连续子串。n-gram熵特征通过计算各n-gram在域名中的频率分布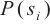 ,并利用香农熵公式计算特征值,从而捕捉APT域名的这种随机性特征。
,并利用香农熵公式计算特征值,从而捕捉APT域名的这种随机性特征。
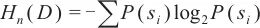 | (1) |
其中,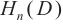 表示域名
表示域名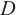 的n-gram熵特征,表示待检测的域名字符串,
的n-gram熵特征,表示待检测的域名字符串,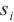 表示从域名中提取出的第i个长度为
表示从域名中提取出的第i个长度为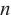 的连续子串,表示子串在域名的所有n-gram子串出现的概率,
的连续子串,表示子串在域名的所有n-gram子串出现的概率,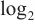 表示以2为底的对数。
表示以2为底的对数。
(2)n-gram的TF-IDF
在APT域名检测任务中,n-gram的词频-逆文档频率(term frequency-inverse document frequency, TF-IDF)特征的有效性源于如下机制:首先,APT组织在生成域名时往往表现出特定的词汇选择偏好,这些偏好使得某些n-gram在恶意样本中呈现高频特性,其词频(term frequency, TF)分量能够捕捉此类重复出现的特征;其次,逆文档频率(inverse document frequency, IDF)通过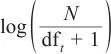 的计算方式,显著提升那些在恶意域名中频繁出现但在正常域名中罕见的n-gram的权重,从而放大具有组织特异性的特征。TF-IDF的数学表达式如式(2)所示。
的计算方式,显著提升那些在恶意域名中频繁出现但在正常域名中罕见的n-gram的权重,从而放大具有组织特异性的特征。TF-IDF的数学表达式如式(2)所示。
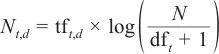 | (2) |
其中,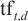 为n-gram t在域名d中出现的频率,N为数据集中域名总数,
为n-gram t在域名d中出现的频率,N为数据集中域名总数,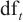 为包含t的域名数量。
为包含t的域名数量。
2.3.2 域名分类
基于提取出的多层次特征,本文选用SVM作为域名分类器,其设计考量如下:首先,SVM通过最大化分类间隔优化决策边界[19],能够有效处理恶意样本与良性样本在高维特征空间中的非线性交织问题,结合径向基核函数的非线性映射能力,能够捕获特征间的隐含关联;其次,SVM基于结构风险最小化[20]的理论框架,在有限标注样本下具有较高的泛化性能,可以降低APT域名样本分布稀疏带来的过拟合风险。相较于神经网络等复杂模型,SVM的分类结果具有更强的可解释性。此外,SVM训练效率更高,支持快速模型迭代和响应,能够满足实际场景中威胁检测模型的动态更新和实时检测需求。
2.4 APT域名归因
在完成APT域名检测后,接下来将聚焦APT域名归因。尽管APT域名检测模块能够有效区分APT域名与非APT域名,但单纯依靠二分类结果无法满足威胁情报的战术级溯源与响应需求。为此,本文提出多层次特征融合的归因框架,通过融合DNS解析模式信息、WHOIS注册信息等外部关联属性特征,以及RoBERTa提取的深层语义表征,构建具备组织特异性的聚类模型。APT域名归因模块以APT检测模块的输出作为输入,通过层次化特征分析与无监督学习,实现从“判断是否恶意”到“识别攻击组织”的跃迁。
2.4.1 关联属性特征提取
为实现APT域名归因,本文设计了如表2所示的关联属性特征组,依托多源外部数据构建APT域名的关联属性特征。关联属性特征组的定义如下:依赖外部数据源或网络协议获取的关联信息,或从这些关联信息中衍生的其他信息,能够反映域名的注册和解析、服务器属性等背景信息的特征。本文将关联属性特征组中的特征划分为5类。在构建关联属性特征组时,除了域名自身的属性特征外,还考虑了域名与IP地址之间的关联关系,并将其抽象为地理位置与VPS两类特征,前者从空间维度刻画了IP地址的分布特性,后者则从基础设施维度揭示了IP地址的服务环境。
表2 关联属性特征组
在关联属性特征组中,DNS是指通过DNS查询服务获取域名对应的IP地址及每条DNS记录的TTL值。WHOIS是指通过WHOIS接口查询域名的创建日期、到期日期和更新日期,并基于这3个日期计算出域名的存活时间和活跃时间。VPS是指应用虚拟化技术在物理服务器上划分出的独立虚拟服务器,用户可以远程部署和管理自定义服务。这类特征可以辅助追踪APT攻击者的资源调度模式,提升域名归因效果。以下为表2中部分特征的详细介绍。
(1)TTL值
域名的存活时间(time to live, TTL)值是指域名DNS解析记录在缓存中保留的有效时长,攻击者通常会设置极小的TTL值以实现命令与控制(command and control, C2)服务器的快速切换[21]。
(2)SSL证书颁发服务类型
出于降低攻击成本、快速部署攻击基础设施的目的,APT组织在搭建C2通信域名时,通常倾向于使用免费SSL证书。基于这一行为特征,可以通过解析域名数字证书的元数据属性,判断该证书是否由免费SSL证书分发页机构签发。
(3)VPS服务商IP地址归属
张慧菲等[22]指出,APT组织在部署C2基础设施时,倾向于使用VPS服务商提供的IP地址。相较于企业自建数据中心,VPS服务具备匿名性强、部署灵活、覆盖范围广的优势,这是APT组织偏好使用VPS服务的核心原因。针对这一特征,可以采用动态更新的VPS IP库,通过对比域名解析出的IP地址和VPS IP库中的IP地址来判断域名是否使用VPS服务商提供的IP地址资源。
2.4.2 RoBERTa特征提取
在APT域名归因模块中,除了提取域名的关联属性特征外,本文还利用预训练的RoBERTa模型提取APT域名的语义特征。考虑到APT域名检测阶段需要从海量域名中筛选出少量APT域名,若在此阶段引入预训练模型将会增加模型的计算开销和时延,故RoBERTa模型仅应用于数据量更小的第二阶段归因任务。具体而言,提取RoBERTa模型最后一层隐藏层中起始字符对应的向量,将其作为域名的深层语义特征。
2.4.3 特征融合
为实现APT域名多层次特征的高效融合,本文采用直接特征拼接方法融合4个层次的特征,具体流程如下:首先,采用主成分分析(principal component analysis, PCA)将RoBERTa 提取的深层语义特征投影至128维低维空间,并对关联属性特征进行分位数归一化与离群值截断处理,消除不同特征间的量纲差异,同时过滤噪声干扰;然后,将文本内容特征、降维后的RoBERTa深层语义特征与标准化后的关联属性特征沿特征维度直接拼接,生成域名的联合表征向量。该方法在最大程度地保留原始特征的同时,具备较高的计算效率,为轻量化实时检测场景提供了兼顾检测效率与归因精度的技术方案。
2.4.4 APT域名聚类
本节基于无监督聚类方法对检测出的潜在APT域名进行关联挖掘与归因分析。在算法方面,本文选用K-means聚类算法,其核心在于通过迭代优化质心位置,将高维特征空间中的域名样本划分为若干簇内紧密度高、簇间差异显著的子集。相较于密度聚类或层次聚类,K-means算法的优势体现在两个方面:其一,针对APT域名特征工程提取的多层次结构化特征,K-means 采用的欧氏距离度量方式,能够有效捕捉特征维度间的全局相似性;其二,算法支持通过预定义簇数约束聚类规模,适用于APT攻击中基础设施分属有限组织的假设。
3 实验
为验证各模块的理论性能,实验阶段对检测与归因任务分别进行分析。
3.1 数据集
本文使用的APT域名数据集通过系统化采集并整合多源开源威胁情报构建而成。数据主要来源于标准化威胁情报平台和专业安全厂商发布的攻击报告。为平衡数据集的类别分布,本文从Alexa 排名前20万名的良性域名中随机下采样,按1∶1的比例将良性样本作为负样本纳入数据集。最终构建的数据集包含1 799个APT域名样本和等量的良性域名样本,覆盖25个APT组织。为保障模型评估结果的可靠性,本文采用分层抽样策略,将数据集按7∶2∶1的比例划分为训练集、验证集和测试集。该划分方式能够确保各APT组织的样本在3个子集中的分布比例与原数据集保持一致。
3.2 评价指标
本文针对APT域名检测与APT域名归因两个阶段的任务特性,构建了差异化的评价指标体系,以实现对模型性能的量化评估。对于APT域名检测任务,基于其分类问题的本质,本文采用分类任务中常用的精确率、召回率和F1分数作为评价指标。对于APT域名归因任务,本文选取被广泛用于评估聚类任务的调整兰德指数(adjusted rand index, ARI)和标准化互信息(normalized mutual information, NMI)作为评价指标。ARI[23]用于量化聚类结果与真实APT标签之间的全局一致性,评估簇内标签分布的匹配程度,其取值范围为[-1,1]。NMI[24]用于衡量两个数据分布的吻合程度,其取值范围为[0,1]。这两个指标的值越大,表明聚类结果与原始数据的划分越吻合。
3.3 实验结果
3.3.1 对比实验
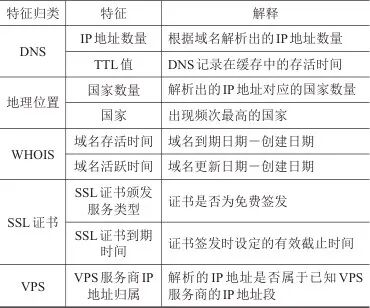
为验证本文所提方法的有效性,研究人员设计了对比实验。本文选取的基线方法均在恶意域名检测领域具有影响力或直接相关性。文献[25]提出了一种基于特征工程和机器学习的恶意域名检测方法MaldomDetector。MaldomDetector虽主要面向域名生成算法(domain generation algorithm, DGA)域名检测,但其特征工程思路与本文方法高度相关。因此,研究人员在本文构建的数据集上对其进行了测试。此外,文献[26]所提大语言模型(large language model, LLM)方法虽应用于钓鱼域名检测,但其提示词框架可以直接迁移至APT域名检测任务。基于该思路,本文设计了图3所示的提示词,并调用DeepSeek-R1模型,对比了LLM和本文方法在APT域名检测任务中的性能。上述两种方法与本文方法检测性能对比见表3。从表3可以看出,无论是与同类型方法对比[25],还是与LLM方法[26]对比,本文方法在精确率、召回率与F1分数3项评价指标上均取得最优的分值。

图3 APT域名检测提示词
表3 检测性能对比
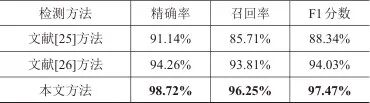
为验证本文针对APT域名检测任务设计的模型架构的有效性,本文选取多种主流机器学习与深度学习模型进行对比实验。实验涉及的模型包括随机森林(random forest, RF)、KNN、朴素贝叶斯(naive Bayes, NB)、决策树(decision tree, DT)、LSTM、BiLSTM,以及系列增强算法模型。各类模型的APT域名检测对比实验结果见表4。从表4可以看出,SVM模型在APT域名检测任务中以97.47%的F1分数优于其他模型,验证了本文设计的文本内容特征的有效性和SVM模型的非线性分类优势。值得注意的是,机器学习模型的性能普遍优于LSTM和BiLSTM模型。这一结果表明,结构简单、参数量少的机器学习模型能够更好地适应训练数据稀缺的场景。
表4 APT域名检测对比实验结果
为提高本文所提方法在APT域名检测任务中的可解释性,研究人员采用沙普利加性解释(Shapley additive explanations, SHAP)方法对APT域名检测任务中的特征进行了重要性分析,按特征重要性从高到低排序,输出了排名前10名的特征,结果如图4所示。从图4可以看出,重要性排名最高的特征对模型决策的贡献度仅接近7%,这说明该模型的决策机制并非依赖单一特征的独立作用,而是依靠多种特征的协同交互效应。
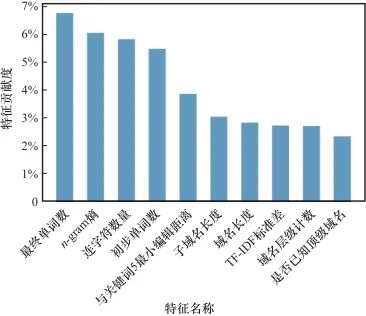
图4 APT域名检测特征重要性排序
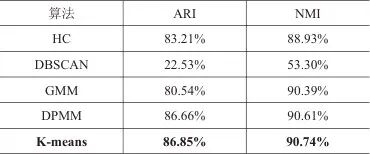
在APT域名归因任务中,为验证本文提出的多层次特征融合框架及所选K-means聚类算法的有效性,研究人员选取了多种主流聚类算法进行对比实验,包括层次聚类(hierarchical clustering, HC)、基于密度的带噪声应用空间聚类(density-based spatial clustering of applications with noise, DBSCAN )算法、高斯混合模型(Gaussian mixture model, GMM)、狄利克雷过程混合模型(Dirichlet process mixture model, DPMM)。各类聚类算法的APT域名归因对比实验结果见表5。从表5可以看出,K-means聚类算法以86.85%的ARI值和90.74%的NMI值,显著优于其他对比聚类算法,这一结果充分验证了本文方法的有效性。该结果证明,本文针对APT域名提取的3类特征能够准确刻画不同APT组织生成域名的偏好,且这些特征分布能被K-means聚类算法有效利用。相较之下,DBSCAN算法表现最差,其ARI值仅为22.53%。分析其原因,主要是DBSCAN算法具有显著的密度敏感特性[27],而本文构建的APT域名特征空间存在密度不均衡问题,该算法无法适应特征空间的密度变化,导致在区分不同APT组织的域名时出现严重的簇重叠现象。
表5 APT域名归因对比实验结果
3.3.2 真实场景
为探究本文方法在真实场景中的提前预警能力,研究人员设计了一项主动检测实验。具体来说,首先使用本文提出的方法持续对全球每日新注册域名进行恶意性分析,筛选并标记潜在的APT域名。随后从国内权威安全厂商发布的APT攻击报告中提取公开披露的APT域名共计26个,对其进行去重与精准匹配验证后发现,其中有18个已被本文方法前期标记为潜在APT域名。
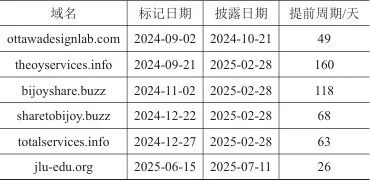
上述18个提前发现的域名部分示例见表6,表中明确标注了3个关键信息:标记日期(本文方法将该域名标记为潜在APT域名的日期)、披露日期(该域名被权威安全厂商公开披露的日期)、提前周期(域名从被标记到被公开披露的时间间隔)。经统计,18个域名的平均提前预警周期达到112天。该实验验证了本文方法在对抗APT的真实网络场景中所具备的早期预警能力。
表6 提前发现的APT域名部分示例
4 结束语
为提高APT域名检测方法的早期预警能力,应对APT域名数据稀缺和类别不均衡的问题,本文提出一种基于多层次特征融合的APT域名归因方法。该方法融合了文本、统计、语义和关联属性4个层次的特征,并将归因任务分解为APT域名检测和APT域名归因两个阶段。在检测阶段,通过提取域名的文本特征、统计特征及语义特征,并采用SVM作为分类器,实现了从海量域名中高效筛选潜在的APT域名。在归因阶段,通过融合文本内容特征、由预训练模型RoBERTa提取的深层语义特征,以及基于外部数据库查询获取的DNS解析模式、WHOIS注册信息、SSL证书属性、VPS服务商IP地址归属等关联属性特征,构建多层次的特征表示,并利用K-means聚类算法实现将恶意域名归因到攻击组织。实验结果表明,本文方法不仅在APT域名检测和归因任务中取得了较高的精度,还在真实场景中展现出平均提前112天的早期预警能力,验证了本文方法的有效性,为应对APT攻击提供了新的思路。
本文所提方法虽然在APT域名检测与归因方面具有良好的性能,但仍存在一定的局限性。首先,当前APT域名检测模型依赖于静态的特征工程,这些基于预定义规则提取的特征在面对APT组织快速演变的战术、技术与程序(tactics techniques procedure, TTP)时,缺乏自适应性和鲁棒性。攻击者一旦改变域名生成策略或基础设施使用模式,模型性能可能出现下降。其次,本文采用的通用RoBERTa模型在捕捉APT组织独特命名习惯的语义方面可能存在局限性。这主要是因为公开的APT域名数据规模极为有限,若在数据样本少的场景下对RoBERTa进行领域微调,极易导致模型过拟合,反而削弱其从预训练中获得的泛化能力。
针对上述挑战,未来可以从4个方面开展深入研究:①探索在线学习与增量学习框架,使模型能够依据新到达的数据动态调整决策边界,从而及时响应APT组织TTP的演变;②增加对抗训练,通过在模型训练阶段注入扰动样本来提升模型的鲁棒性;③致力于构建更大规模的APT域名语料库,为预训练模型进行领域微调提供数据基础,进而更精准地捕捉APT组织的语义特征;④探索基于图结构的归因建模方法,利用图神经网络挖掘更深层次的归因线索,以期构建一个更全面的APT组织归因系统。
作者简介
马利昭,男,四川大学硕士生,主要研究方向为威胁检测、机器学习和自然语言处理。
黄诚,男,四川大学教授,主要研究方向为网络空间安全、攻击检测、威胁溯源、数据挖掘、社交网络、机器学习和自然语言处理。
黎明,男,中国电子科技集团航空电子有限公司创新中心主任,主要研究方向为航空计算技术、航空通信安全和人工智能。
牟浩天,男,四川大学硕士生,主要研究方向为机器学习、高级持续性威胁检测。
彭佳仁,男,四川大学博士生,主要研究方向为网络威胁情报与大语言模型。
谢启亮,男,四川大学博士生,主要研究方向为流量检测和区块链。
声明:本文来自网络与信息安全学报,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
