编者荐语
传统网络安全时代的安全运营,最主要的问题是安全设备有没有告警;AI 攻击时代,最主要的问题变成了告警太多来不及处理。AI 攻击带来的日志和告警急剧增加,过去甲方的告警降噪更多是由于自己的告警处理能力不足,只能是不断的对告警做优先级排序,把安全团队能够处理的告警处理掉,而由于安全团队的处理能力边界远小于自身面临的安全风险边界,导致很多安全风险和攻击并没有得到妥善处理,这也是安全事件层出不穷的原因。
AI 智能体加通用大模型技术目前已经具备了5-8 年安全分析师水平能力,并且还在不断快速迭代提升,通过 AI智能体建立数字安全员工来对抗 AI 攻击是完全可行的。过去我们招 1000 个乃至 10000 个安全员工来分析研判和处理告警不现实,但有了算力和智能体可以,从而提升安全处理能力,带来安全性提升。
算力即安全。
(一)引言
2026年4 月,Anthropic 通过 Project Glasswing 披露了一个尚未公开发布的通用前沿模型——Claude Mythos Preview。按官方说法,它的编码能力已经达到"在发现和利用软件漏洞上超过除最顶尖之外几乎所有人类"的水平:已发现数千个高危漏洞,覆盖每一个主流操作系统和浏览器,其中包括一个在 OpenBSD 里存活了二十七年、一个在 FFmpeg 里存活了十六年、扛过几十年人工审查的缺陷——而且大多是在没有人工引导的情况下自主完成的。英国 AI Security Institute 的独立评测也印证了这一点:专家级 CTF 通过率 73%,并第一次端到端完成了一个原本需要人类专家约二十小时、三十二步的企业网络攻击模拟。
当然,AISI也提醒,靶场和真实企业仍有差距——真实环境里有防御工具,也有在岗的防守人员。但比起争论某个模型到底有多强,更值得注意的是那个底层变化:
攻击侧的生产效率变了。
聂君
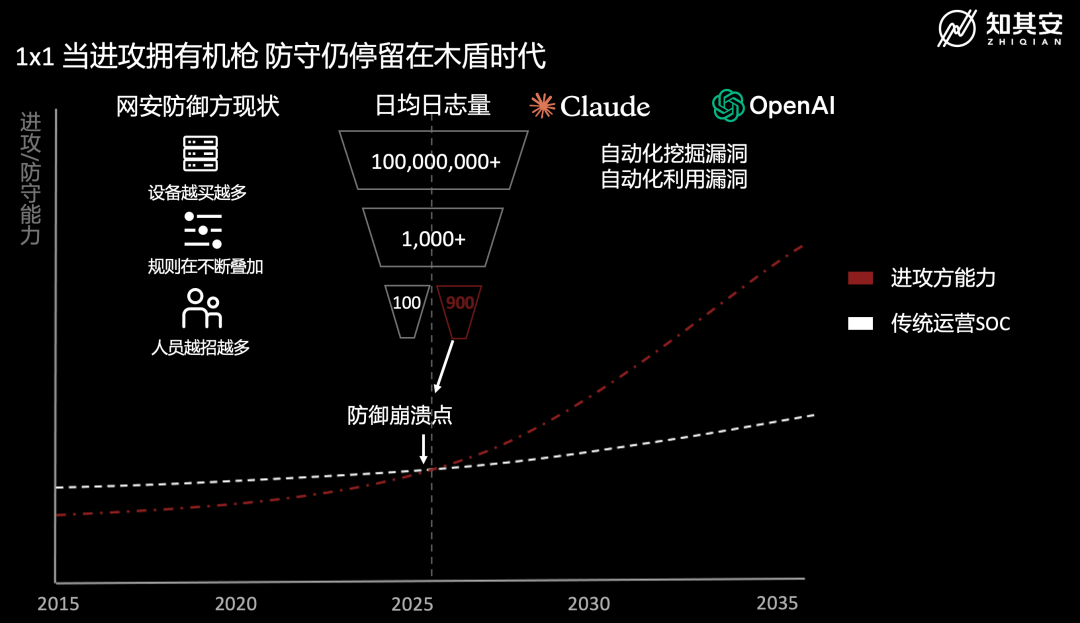
图 1:AI自动化攻击带来的防御崩溃
过去,一支高水平攻击队的能力,依赖少数顶尖专家、长时间积累、工具链和组织协作。现在,长程智能体正在把这些能力封装成可以反复调用的"agent-hour"——它不疲劳、不厌烦,可以一刻不停地连轴运行,对你的暴露面、弱配置、历史漏洞、凭据泄露、身份路径持续侦察和试探。
当攻击开始以机器速度、机器规模的指数演进,防守方本质上是堆设备、堆规则、堆人员的线性增长,攻击和防御方的效率会越拉越大。
企业安全团队长期面对一组令人窒息的数字:
指标 | 现实 |
|---|---|
平均每天告警数量 | 数千至数万条 |
告警误报率 | 高达 40%-60% |
平均检测到响应时间(MTTR) | 数小时到数天 |
全球安全人才缺口 | 约 340 万人 |
传统模式下,我们用“堆人”来应对“堆告警”。但人的注意力是有限的,疲劳、倦怠和流失率让 SOC 团队始终处于一种“慢性失血”的状态。
过去网络安全时代的安全运营,最主要的问题是安全设备有没有告警;
AI 攻击时代,最主要的问题变成了告警太多来不及处理。
0x1 攻防双方分析
1.1 AI 时代的攻击侧特点
特点一:攻击的边际成本正在归零
过去APT级的单点深度突破,只有少数组织负担得起。现在,一个模型自主运行一次,就能完成过去要专家二十小时的多步攻击,而且这种能力可以反复租用、按token计费。高级攻击从"少数组织的能力"变成"人人可租用的服务",它的数量必然大幅上升——这是检测漏报、研判过载、处置过载三重压力的共同根源。
特点二:攻击只需单点成功,防御必须全面覆盖
攻击者天然是单点突破逻辑:一个暴露在公网的高危服务、一个弱口令、一个长期没修的漏洞、一个被钓中的员工,只要一个点成功,后面就是横向、提权、驻留、外传。防御则相反,要面对服务器、终端、账号、邮箱、业务系统、外发通道、云资源、供应链接口——任何一个点出问题都可能成为事件。
防御总成本,约等于资产数量乘以单资产的防御成本。攻击成本暴跌之后,如果防守方不能把"一次研判、一次调查、一条规则的维护、一次处置"的边际成本同样压到接近零,这道数学题就无解。
特点三:攻防变成了一场速度竞赛
攻击链智能体化之后,从落点到横向移动的突破时间,会从小时级压缩到分钟级,甚至秒级。而防守方的"检测—研判—处置"链路里,
只要任何一环还留给人工,整条链路就会退化为人工速度。
你检测做到秒级、研判做到分钟级,结果处置卡在"人工看完、人工确认、人工开工单、人工审批"上,那前面的快就白费了。
最后落到两个方向:压低防御的边际成本,用满防守方的结构性优势。
攻击者有强模型,防守方是不是更没法打了?不完全是。
1.2 AI 时代的防守侧特点
特点一:防守方有主场
企业有自己的资产、账号、日志、业务关系、历史行为和组织结构。攻击者的智能体进入环境时是盲的,每一步信息都要靠探测获取,而每一次探测,都是一次暴露机会。
特点二:防守方有平时
攻击发生时时间很紧,但攻击发生之前的全部时间,都属于防守方,而且没有时效约束。画像、基线、预案、盲区排查、狩猎、验证,都可以提前做。攻击者要花很久才能摸清的拓扑和权限关系,防守方的智能体本应在分钟级拿到——前提是这张图你平时就建好了。
特点三:防守方有历史
攻击者每次进来都要从零摸索;防守方手里有过去数月甚至数年的日志,知道一个员工、一台主机、一个账号、一条外发通道平时是什么样子。
特点四:跨客户的复利
攻击手法会复用、工具会复用、路径会复用。如果能把不同客户现场的经验沉淀成规则、画像维度、判例、狩猎假设和评测样本,就能形成攻击者结构上无法对抗的优势:攻击者一次只打一家,安全运营厂商从所有客户学习。
特点五:步数本身就是信号
这里还有一个反直觉、但很关键的点:攻击智能体的"步数",本身就是信号。
自主探索意味着更多试探命令、更多失败重试、更多枚举动作。单步可以做得很隐蔽,但动作的绝对数量会大幅上升。对于平时就布好了传感器和诱饵的防守方,攻击者越勤快、跑得越久,触碰到信号点的概率就越高。
更强的攻击模型,对一个"地形已经布设好"的防守方,反而更有利。
所以面对层出不穷的新手法,真正稳健的检测思路,不是去追每一种变体,而是抓不变量——不识别"它用了什么新技术",而是识别"这个实体不像它自己、不像它的同类";攻击技术再快,总要侦察、总要提权、总要横移、总要外传,把检测锚在攻击链的咽喉上。
问题在于,这些都需要持续投入才能兑现,而"持续投入"恰恰是人力最匮乏、AI 防御智能体最擅长的部分。
聂君
0x2 解决思路
一个经典的安全运营架构包含四个框架:安全防护、安全运维、安全验证、安全度量。
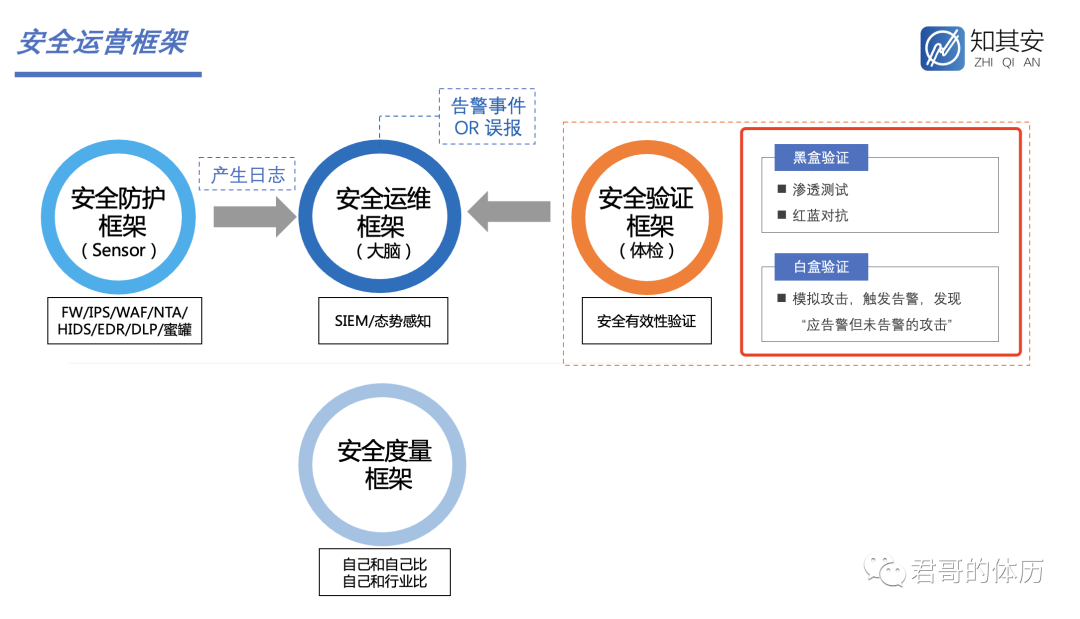
图 2:安全运营框架
2.1 安全防护框架
由于计算机是分层的:网络层、虚拟化层、系统层、应用层、用户层、数据层、业务层,所以安全防护就是通过在每层上部署单点防御,构建一套纵深防御体系。
网络层做安全域划分和隔离等;
系统层安装防病毒和 HIDS等;
应用层有各类 XAST 和 WAF、漏扫等;
数据层部署各类 DLP、数据库审计、API 安全等;
业务层有反欺诈等。
这是过去 20 多年的安全基础建设领域,也是传统安全的主战场。
安全防护框架的主要产出是各类安全日志。
聂君
2.2 安全运维框架
安全防护框架产生的日志太多了,可达 20 万 EPS(events per second),一天是 172.8 亿日志量。甲方普遍做法是建设一套安全大数据平台(有的叫 SOC/SIEM),将这些原始日志统一收集起来,由于安全值班人员能处理的告警有限,甲方会在安全大数据平台上添加黑白名单规则(专业术语叫:UseCase)进行过滤,过滤后产生的告警,才是安全一二线人员每天真正处理的。由于一二线人员处理能力的限制,每个人每天处理的告警在 50 条左右,所以甲方通常处理的告警规模大概在几百到一二千条,通常在 500 条左右。
我们经常能听到一个词:告警降噪。甲方的告警降噪更多是由于自己的告警处理能力不足,只能是不断的对日志和告警做优先级排序,把安全团队能够处理的告警处理掉,而由于安全团队的处理能力边界远小于自身面临的安全风险边界,导致很多安全风险和攻击并没有得到妥善处理,这也是安全事件层出不穷的原因。所以:
500 条,不是团队面临的风险边界,而是团队的处理能力边界。甲方安全团队能力边界远小于自身面临的风险边界。
聂君
由于AI大语言模型的兴起, 语义分析理解能力很强。AI 智能体加通用大模型技术目前已经具备了5-8 年安全分析师水平能力,并且还在不断快速迭代提升。
通过 AI智能体建立数字安全员工来对抗 AI 攻击是完全可行,也是当下破解困局的唯一思路。
聂君
过去我们招 1000 个乃至 10000 个安全员工来分析研判和处理告警不现实,但有了算力和智能体可以。提升安全告警处理能力,能够带来安全性提升,算力即安全。
传统的安全运营,误报率和漏报率是跷跷板的两端。但在 AI gent 安全运营方案中,可以同时实现误报率和漏报率的双降。
2.3 智能体建设方案
智能体队伍体系应该如何建设?2026 年的 Google Cloud Next,谷歌为安全运营提供的是四类智能体,包括告警分诊与调查、威胁狩猎、检测工程、第三方上下文增强;我们做“曜鉴”(见备注 1)时,最终落到的也是这四类,再加上智能复核的智能体。长期深入在一线做安全运营智能体的摸索实践,最后大家思路不谋而合。
备注1:“曜鉴”是笔者创立的知其安公司研发的 AI for Security 智能体平台,知其安另一个工具平台叫“离朱”安全有效性验证平台,超过一千家甲方用户使用该平台。
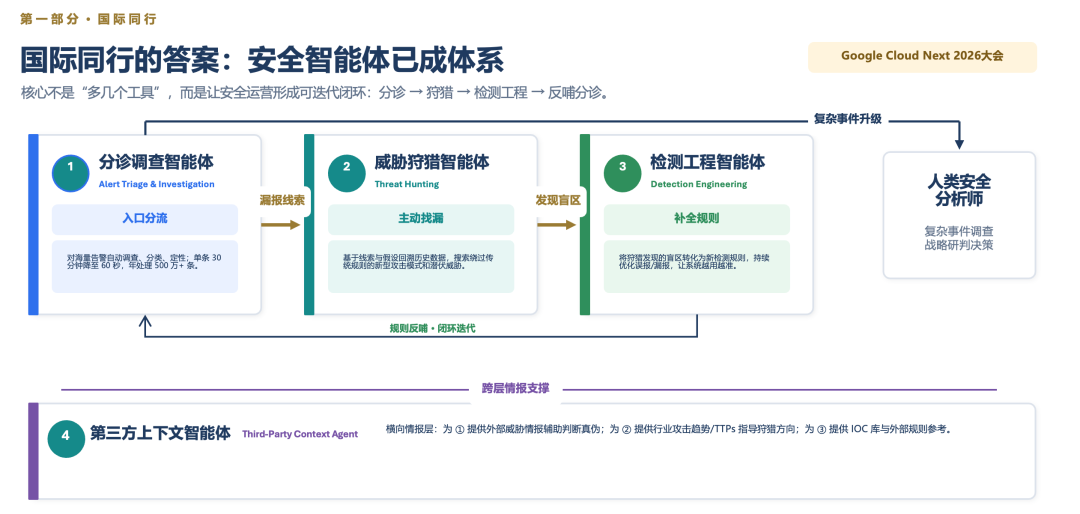
图 3:Google 内部安全团队构建的四类智能体
这四类智能体通过曜鉴叠在现有的态势感知平台之上,串成一条作业线(见下图)。态势感知平台原样保留,做第一轮聚合降噪;曜鉴叠在其上,由调度器做编排与预处理:把告警路由到对应智能体,按需回拉态势感知和设备里的数据、构建上下文;研判完,结论再写回态势感知。现有平台不变,只是后面接上一支随时在岗的智能深度研判队伍。
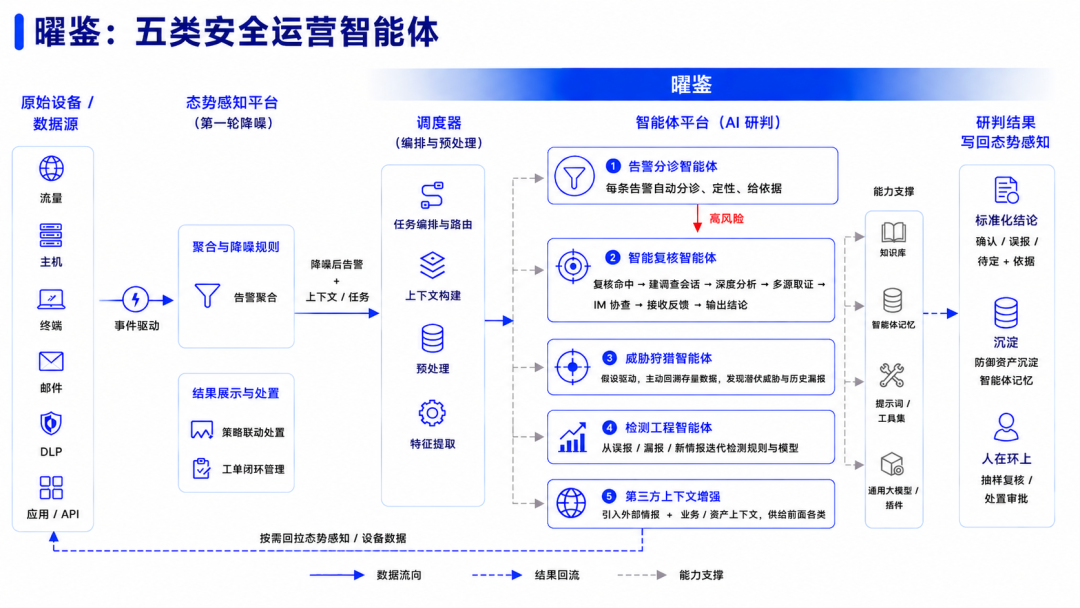
图 4:知其安 曜鉴-安全智能体平台
其中:
告警分诊智能体:每条告警自动分诊、定性、给依据。这一段解决的是"量";
智能复核智能体:分诊里判为高风险的,交给复核这一类二次确认——复核命中、建调查会话、深度分析、多源取证,必要时发起 IM 协查、接收人工反馈,最后给出结论。这一段解决的是"信";
威胁狩猎智能体:不依赖告警触发,基于假设主动回溯存量数据,把潜伏威胁和历史漏报找回来;
检测工程智能体:把误报、漏报、新情报回流,自动迭代检测规则与智能体;
第三方上下文增强智能体:引入外部威胁情报和业务、资产上下文,供前面几类调用,让研判知内知外。
但五类智能体本身,并不等于一个可信的闭环。要让它成为闭环,关键在几件容易被忽略的事:研判结论要写回态势感知,研判过程要沉淀成防御资产和智能体记忆,人要在环上抽检;再加两道兜底:整条链路由持续验证盯着,不让它悄悄失效。可信、可控、可沉淀,再加上逐一验证——这就是"没有安全验证,就没有安全运营闭环"在智能体时代的样子。
AI Agent 的本质意义在于:它把安全运营从“人力密集型”推向“智力密集型”。初级分析师的重复性工作——告警分诊、日志查询、IOC 匹配——正是 Agent 最擅长的。
2.4 为什么是通用大模型
过去两年,安全行业一个奇怪的现象,是各家训练自己的安全垂域模型。曜鉴使用的是通用大模型。根因是智能体这套框架,对模型的要求变了。
在智能体里,能做到什么程度,很大程度上取决于背后模型的上限。 模型越强,它自己规划调查、拓线、出错后自我纠正的余地就越大。这两年国内外都在往 Agentic SoC走,对模型的要求只会更高:综合推理要强、工具调用要稳。垂域模型在某个单点任务上也许能调出一点点优势,但在这种拼通用推理上限的场景里,很难跟上前沿通用模型的迭代速度。
垂域模型在安全领域效果不好,还有一个原因是安全领域训练数据量太小,质量不高。
至少到今天,在这种拼综合推理的场景里,我们还很少看到哪个安全垂域模型,能稳定达到头部开源SOTA通用大模型的水准。这是任务本身从"单点判得准不准",变成了"能不能在一个开放问题里一步步推下去"。
模型的智能能力溢出,还得用在对的地方。 Agentic 框架下,更值得交给模型的,是那些不确定、要多步、要跨系统取证的活——比如较深的威胁狩猎、复杂告警的逐层研判。这类事情,没有哪条规则、哪个单一模型能一步给出结论,得一边调工具、一边补上下文,顺着线索往下走。
反过来,把前沿模型放到流量检测这种单点分类上,就没用在它的长处上。那一层要的是毫秒级在线判定,适合使用传统规则、特征;换上大模型,准确率的提升有限,却要多担推理时延和成本。业界对流量检测小模型的尝试更接近把传统 NDR/IDS 做一次 AI 化增强,仍是在单一数据面上做优化。模型真正用得上的地方,是去处理人一时想不清、规则又写不全的那部分。
用 AI 去做流量检测,本质上还是NTA安全设备+AI 功能,对 NTA 安全设备做一次升级换代,这和邮件安全+ AI 功能,主机安全+ AI功能等没有区别,还是安全建设设备厂商借用 AI 名义,再卖一次流量安全检测设备而已。
通过调研数十家金融和能源用户,AI for Security最好的应用场景是:代码安全、安全运营。
在安全运营领域,最好的应用场景是:通过 AI agent+ 通用大模型,对 SOC/SIEM 产生的告警(以及引起告警的原始日志)进行研判分析,提高日均告警处理能力。
甲方日均告警处理能力提升之后,开始拆白名单。很多安全事件是因为攻击者使用白名单通道干了黑名单的事情。
聂君
比如某股份制银行开始将自动化运维系统下发的任务和脚本,同步一份给 AI agent 复核,区分下发的自动化任务和脚本,是真正的生产运维的业务需要,还是自动化运维系统已被攻击队控制下发的是恶意脚本。
我以前在银行和安全公司工作负责内部安全防守时,均在内部攻防演习时被蓝军(红队)这么干过。
2.5 智能研判靠的是上下文工程,不是吞吐量
要让模型把"人想不清、规则写不全"的那部分处理好,光靠模型强还不够,还得让它在足够高质量的上下文里判。这是"模型之外"的另一面:上下文。研判准不准,关键不在一天过了多少条,而在判每一条时,手里的上下文够不够全、够不够准;而把上下文取全取准,要花时间、调接口、跨系统去查——这跟"求快、求量"本来就是两个方向。
流量检测大模型厂商,通常使用一个小而快的模型,把每天上百万条全过一遍,比的是处理量,从实践看来是靠不住的。
流量检测大模型的做法是海量告警先用快系统过一遍、做降噪和分类,它解决的是"量",不是"信",不能当成最终研判。一个小模型在上下文严重不足时一天判一百万条,这些结论很难直接采信,结果还是得靠人去抽检——想省的人力又回来了。
更致命的是,流量检测大模型能看到的信息有限,并没有跳出"凭有限信息下判断"这个老局限:和规则一样受制于"看到的太少",躲不开漏报,也挡不住稍复杂、高级一点的攻击。而这些,正是我们一开始就想解决的问题。
研判要判得准,前提是提供足够高质量的上下文,至少有三类:
一是资产 CMDB,少了它,内对内的流量会大量误报。 某头部券商现场,接入资产 CMDB 之后,智能体的研判准确率明显好转。一个常见的例子:NDR 按传统规则,会把 AI 代码开发工具的正常交互,报成 webshell上传;而智能体拿到资产信息、知道对端是一套代码辅助系统,就能认出这是业务流量,噪声随之降下来。
二是威胁情报,以及情报跟不上时的补位。内对外那类恶意外联,多数查一下情报就能定性,不必动用大模型;真正需要智能体的,是情报覆盖不到的地方。最典型的是钓鱼邮件——一个刚注册的钓鱼站点,威胁情报对这种新域名往往滞后。这时候只靠情报不够,得让智能体调 URL沙箱,把站点截图和页面内容取下来分析,再结合邮件正文的上下文,给出综合判断。
三是现场的值班知识,否则 AI 不了解内情也会判错。 还有一类上下文不在任何系统里,只在值班人员的经验里:内部安全设备的拓扑、出口 IP、扫描器地址、企业里那些"不规范但其实正常"的业务习惯。这些得靠现场调研,整理成 AI 能用的研判知识。否则 AI不了解内情就会误判——一个看着"经常恶意外联"的源 IP,可能只是台 DNS 服务器;一个"频繁发起扫描"的源 IP,可能是公司自己的漏扫器。
资产、情报、现场知识,归根结底是同一件事:让模型在尽可能完整、准确的上下文里做判断。而这恰恰是"小模型刷量"给不到的。
这两年,业内也大致走到同一个判断上。从2025 年6月开始,上下文工程(Context Engineering)的提法开始流行——Karpathy 的说法是,在每一步给上下文窗口填进恰到好处的信息。
这也是我们选择通用大模型加 agentic 框架的原因:与其用一个小模型把上百万条都浅扫一遍,不如让一个足够智能的模型,在上下文取齐之后,把真正该深入调查研判的,判准、判透。
这些事指向同一个目标:泛化。安全运营最怕漏掉真实攻击,而漏报往往来自模型没见过的那种变体。垂直训练能让模型在某类样本上更顺手,但也容易把它的视野收窄;通用模型底子更宽,再配上尽量完整的上下文,模型对没见过的攻击才更可能反应过来。
2.6 对安全团队意味着什么
安全团队不会消失,但安全团队的结构会被深度重塑。
角色的重新定义
传统角色 | 未来演进方向 |
|---|---|
L1 分析师(告警分诊) | 大部分工作被 Agent 替代 |
L2 分析师(深度调查) | 转向 Agent 监督者 + 复杂场景处理 |
L3 / 威胁猎手 | 价值放大——专注于 Agent 无法处理的高级威胁 |
安全工程师 | 新增职责:Agent 策略设计、护栏配置、效果调优 |
CISO / 安全负责人 | 需要理解 AI Agent 的能力边界和风险 |
AI Agent 消灭的不是“安全岗位”,而是“重复性安全劳动”。 但如果一个团队 70% 的人力都花在重复性劳动上,那“消灭岗位”和“大规模重组”之间的距离,其实很近。
(二)落地实践
0x3 智能体实践:原理简单,区别在于工程化
文章:《安全验证,实现安全运营闭环实践》 提到:飞机起飞的原理很简单,只要速度够快,机翼上下的压力差就能让它起飞;但真正造出飞机、建起整套航空体系,是极有门槛的工程。
安全智能体也是这样。让模型回答一条告警有没有风险,不难。让它在真实客户环境里长期、稳定、受控地参与安全运营,才是难的地方。
3.1 模型的三个限制
当前主流模型有三个限制:
第一,模型号称多模态,但它的多模态很有限。它能处理文本、图片、音视频,却做不到对eml 邮件、对 Word/PPT/Excel、对 PDF、对 zip/rar/7z 多层压缩、对嵌套 Office、对 pcap 流量包的"多模态"解析。这些全要靠工程化的预解析能力先喂给它。
第二,模型的预训练知识是"过期"的。它的知识可能停在去年某个月份,对网络安全里高频变化的资产数据、威胁情报、新上线的钓鱼URL、刚传到图床的钓鱼图片、员工邮件往来历史、某个资产近七天登录的 Top 来源,统统不了解。不接实时情报、不接资产、不接 URL 沙箱,它就只能靠"编"。
第三,模型的上下文窗口有限。我们做过一个很朴素的测试:用一个128K 上下文的国产开源模型研判 Webshell,一个 248KB 的文件就要消耗约 9 万 token。而真实场景里,一份超长的 DLP 外发文档可能十几万字,一个绕过用的大马可能超过 2MB,一千条暴力破解日志可能被聚合成一个告警。后来我们用滑动窗口分片、逐片摘要、累计风险分的方式做智能上下文压缩,才把一个 128K 模型能处理的文本量,从通常的 500KB 提到约 15MB,提升了三十倍。
这三个限制决定了:智能体的效果,七分在工程,三分在模型。以邮件安全场景为例:
三级压缩的附件没解全,结果把一封钓鱼邮件误判成了业务邮件;
解压密码藏在邮件正文的二维码里,识别不出来,解密失败;
附件其实没加密,但AI 从正文找到一个"假密码"后,就再也没尝试无密码直接解压;
邮件正文只引用了一张互联网图片,正文为空、图又下载不下来,于是误判;
压缩包里有exe,解压后没把目录树列给 AI 看——而在有些客户那里,附件带 exe 是要直接拦截的高危行为,AI 却因为拿不到目录结构而判错;
附件解密失败时,后端没把"解密失败"这个事实告诉 AI,AI 在信息不足的情况下,把它当成了业务邮件——正确的做法是判"信息不足";
eml 里的 html 内容太长,模型直接不遵循指令、开始乱答,我们用 html2text 把无关内容裁掉才稳住;
员工用Word 里再嵌套一个 Word 来绕过 DLP 检测;
还有一个:员工外发被拦了好几次,最后把手机号第一位的数字"1"改成字母"l",绕过了规则,发了出去。
这些坑指向同一件事:
在客户现场,决定AI研判成败的,往往不是模型聪不聪明,而是一个加密附件能不能解开、一段 html 要不要裁剪。
这正是当年"Top30失效点"的AI 版本——高级威胁,常常栽在低级问题上。
3.2 编排还是自主规划
在做主机安全告警的研判分析时,我们快速迭代了三个版本:
3.2.1 第一版,单条告警研判
输入一条告警,直接输出结论。简单直接,但缺上下文,误报很多——它根本不知道这台主机、这个账号平时什么样。
3.2.2 第二版,固定剧本调查上下文
我们让它先去查完整进程链、账号属性、异常登录、计划任务,再做判断。研判依据是丰富了,但调查步骤是固定的,本质上还是传统SOAR 剧本,一遇到复杂场景就不够用——因为真实的安全调查,常常是查完 A 才知道要不要查 B,第一次查询失败了还得改参数、换工具、换路径继续查。
3.2.3 第三版,基于Skill框架加调查 SOP 的自主规划
我们把HIDS、资产查询、日志检索这些能力封装成 Skill,让 AI 依据 SOP 自己制定调查计划、自己选择调用哪个工具、根据结果继续拓线、调用失败了自我修正。同一个工作流还能兼容不同版本的设备。这一版得到了几家头部客户的认可,可以覆盖暴力破解、异常登录等多种告警类型。
3.3 编排与自主长期并存
这三版的演进,回答了一个很多人纠结的问题:编排,还是自主规划?
我们的实践是:两者长期并存,按时效压力和任务性质分工。大量重复、流程固定的告警,用工作流编排类智能体做高吞吐初筛;少数高风险、不确定、需要多轮跨系统调查的告警,再交给 Agent 型智能体做深度调查。
为什么不能把所有告警都丢给最强的模型去深度分析?因为这在工程上不现实、在成本上不可持续、在SLA上也满足不了。一天约两万条告警,全量深度研判时,token 消耗高达约七亿;后来不得不把进入深度分析的告警量从两万压到三千,成本才降下来。
所以分层是必须的,而分层背后,缓存又不能设计的太粗暴。安全告警里,相似不等于相同:十条看起来很像的攻击,前九条可能都是扫描,第十条可能因为资产、路径、响应、时间线不同,就是真正的攻击成功。所以缓存要做精细:哪些能强复用结论,哪些只能复用中间证据,哪些必须重判。有些地方反而可以放心强缓存——比如某银行的客户经理经常把同一份授信报告模板外发给外部客户,文件哈希不变,就没必要每次都重新研判。
0x4 智能体实践:没有复核与协查,初筛就只是"看了一眼"
4.1 AI初筛存在不足
AI初筛有价值,它能在海量告警里先做降噪和分类。但如果到这里就结束,问题并没有解决。
举一个真实的数字。某客户近二十四小时聚合后的告警约一点七万条,其中被AI判定为"攻击成功"的,约一千六百条。表面上看 AI 已经很能干了,但这一千六百条如果还要运营人员逐条打开请求体、响应体、原始日志、资产信息去确认,那 AI 解决的只是"量"的问题,没有解决"信"的问题。
4.2 智能复核
智能复核是整套闭环里的一环,它做的事情,是在AI初筛之后,针对高风险、不确定、攻击成功这类告警,自动建一个独立的调查会话,由 Agent 型智能体去查资产、查情报、查 SOC 历史告警、查主机进程、查原始日志,把"模型的一个判断"变成"基于多源证据的复核结论"。
更关键的是一个设计理念:信息不足时,不要急着下结论。
很多安全告警,光靠日志是判不清的。最典型的就是账号异地登录——它可能是凭据泄露,也可能只是员工把账号借给了别人。这种情况,AI查遍了SOC、资产、情报也确认不了,那它就不该直接给出"攻击成功"或"攻击失败"的结论,而应该停下来找人。
4.3 人工协查与反馈闭环
我们的实践是让AI通过 IM 发起人工协查:把告警 ID、当前调查情况、需要确认的问题发到群里,人工带着告警 ID 回复、@ 一下机器人,系统通过回调把这条反馈写回对应的会话,AI 再接着完成复核。这里有个很现实的细节——群里可能同时有好几条协查请求,所以人工回复必须带告警 ID,否则系统不知道这是哪条告警的反馈。目前飞书、企业微信已经打通,钉钉在适配。这套机制在客户那里已经实战使用。
整个过程,系统会同时保留AI初筛原结论、智能复核结论、人工反馈、最终是否改判、改判依据。这才是闭环。
因为它打通了过去AI研判一直缺的那个东西——标准答案回路。过去每天都是新告警,AI 根本不知道自己昨天判对了还是判错了。有了复核和人工反馈,AI 才第一次拿到了"对错"的信号,才谈得上自我改进。
而且这些被确认过的案子,不该只是存进档案。更有用的做法,是把一整条过程沉淀成判例——这条告警当时长什么样、AI顺着什么路径查、查了哪些系统、最后结论是什么、人工和后验反馈又是什么。下次遇到相似的告警,调出来的是这整条"怎么查、怎么想"的过程,当作推理参考,而不是把当时那个"人工结论"直接套上去。
这两者差别很大:直接套用当时的结论,等于把判断退回到关键词匹配,系统也学不到任何东西;把完整判例当参考,AI借鉴的是当时的核查路径,再结合这次的差异重新判断。安全运营的经验,本就该一案一案积累成可被检索的范例,而不是指望谁在初次写提示词、建智能体的时候,就把所有情况一次想全、从此定型。
没有复核,AI只是给了你一个判断;有了复核与协查,AI才可能输出一个可解释、可追溯、可回放、可写回的运营结论。
0x5 智能体实践:让 AI 理解"这个实体平时什么样"
很多AI
研判效果不稳定,根源不在模型,而在上下文。
聂君
同样一条疑似敏感数据外发行为告警,研发部门外发代码和市场部门外发宣传材料,风险完全不同;同样一台机器主动外联境外IP,生产服务器和办公终端,判断标准也完全不同。这些信息在哪里?很多时候在人脑里、群聊里、工单备注里、Excel里,根源是没有结构化沉淀。AI 不知道,自然会误判。
5.1 实时画像
解决这个问题,不能靠继续写更长的提示词,也不能靠把所有历史日志一股脑塞给模型。靠的是结构化实体画像。
但我们在讨论里想清楚的一件事是:实体画像不应该是"提前给每个人、每个 IP 生成一份静态画像"。那是脚本批量算出来的静态结果,不会实时更新,用户一换时间范围、换筛选条件就失效了。
更合理的形态,是一套能按场景、按条件实时查询的上下文:同一类实体共用一套口径,按部门、时间、通道、风险状态去筛,而不是给每个人各存一张静态表。
这里有一点尤其要紧——人和AI 得看同一套事实。人在页面上看到的统计、AI 调查时拿到的上下文、报告里引用的数据,都得来自同一套查询逻辑;否则人一个口径、AI 一个口径,AI 给出的结论就既无法解释、也无法复盘。
那不是智能化,是新的混乱。
5.2 两个用途
画像有两个用途。第一个,是给AI研判提供上下文,让它不再只看单条告警。
第二个,把画像编译成检测能力。某台服务器过去九十天从不主动外联境外 IP,今天突然外联了;某个财务岗员工过去深夜外发的频次是零,今天出现了三次。这种"偏离了自身历史常态"的信号,往往比通用规则更有价值,而且不管攻击手法怎么变都成立。
5.3 分级治理
还有一点容易被忽略:挂在实体上的信息,性质并不一样,治理也得不一样。"这个IP是业务扫描器"、"这台主机是某业务的跳板机"是事实,要带出处和有效期;"这个员工深夜外发、上次人工确认是正常批处理"是判例,只能当研判的参考;真正要让某类行为"免研判"放行的,必须从画像里这种模糊记忆,晋升成一条可审计的白名单规则。记忆只负责提示,规则才负责放行,这条界限不能含糊。
把记忆挂在实体上还有个额外的好处——它能跟实体在现实里的生命周期联动。员工离职、主机改用途、系统下线,对应实体的画像就自动降权,注意是降权、不是删除:一条"他已经离职"的旧记忆,碰上"离职账号仍在登录"这种告警,反而是最关键的那把钥匙。
当然画像也有它的工程难点。它的查询频次可能远高于人——如果AI一天研判两千条告警,画像就可能一天被调两千次。所以底层得用更适合做聚合统计的存储引擎,配合缓存和限流,而不是简单堆在日志检索系统上。
0x6 智能体实践:检测阈值能压多低,取决于研判接得住多少
6.1 检测分三层
这里要先重构一个前提:检测不是一个环节,是三层。
我们习惯把检测当成秒级的在线判定——规则、模型、特征,毫秒级出结果。智能体进不了这一层,上下文窗口、推理时延、多轮调用的开销都不允许,这点没错。但检测还有第二层和第三层:第二层是离线的内容生产——写规则、调阈值、补盲区,按天计;第三层是阈值之下、被压掉、根本没进SOC的那批弱信号。智能体进不了第一层,却完全可以接管第二层、捞回第三层。
6.2 下移加分层
今天每家企业的告警阈值,本质上是按人工研判的处理能力标定的。人工团队的处理能力不够,就只能把阈值抬高、把弱信号压掉——而漏报,恰恰藏在被压掉的那部分里。当研判产能因为智能体变得弹性、单次调查的成本持续下降,最优阈值就会系统性下移:下游接得住了,就敢把更多弱信号放进来重新看。
当然,放进来不等于把这些弱信号都丢给最强的Agent深判——那又会回到老问题:深度调查很贵,不能全量上。得配合分层:新捞回来的弱信号,先用便宜的快系统和 AI 自己生产的规则去筛,只有真正可疑的才往上走。被压在阈值之下的灰色地带,也正是平时主动狩猎该去翻的地方。
所以把AI用在研判,会反过来改善检测的召回率。检测、研判、处置不是三段各自为政的流水线——研判这头接得住了,检测那头就敢把阈值压得更低。整条漏斗值得一起重新标定,而不是各自局部优化。
0x7 智能体实践:从消耗告警到生产防御资产
7.1 消耗VS复利
前面这些能力,最终都指向同一个判断。上一节AI自己生产检测规则、把检测阈值压低,就是这个判断的一个例子。
如果AI每天只是帮我们把更多告警看完,那么明天同样的告警还会再来,同样的误报还要再解释一遍。这不是复利,是消耗。AI 越强,账单越贵。
真正有价值的安全智能体,每完成一次调查,都应该留下一件"明天还在生效"的防御资产:
一条更准的检测规则、一条实体画像、一个可复用的判例、一个处置预案、一个狩猎假设、一个评测样本、一个带有效期的误报白名单、一个日志解析器、一个蜜标布设建议。
聂君
这些资产产出之后会持续生效、可以跨客户复制、可以被下一轮智能继续加工。防御的边际成本随资产存量复利下降,而攻击者的边际成本不变——两条成本曲线的剪刀差,才是防守方真正的胜负手。
攻击者的agent-hour产出一次性突破;防守者的 agent-hour 必须产出复利。
把"昂贵的深度智能"经济地铺到"海量资产的广度"上,无非几条路径:
把深度调查的成果固化为可复用资产,下次同类问题直接复用(摊销);
便宜的快系统过滤、昂贵的慢系统聚焦,按风险分配调查预算(分层);
用与攻击者同等的智能,先于攻击者找到并废掉单点缺陷(预先);
跨客户、跨时间的知识网络,一处发现、全网获益(复利);
防御能力本身要持续回归验证,否则会静默退化(验证)。
7.2 针对AI攻击者的诱饵
再举一个目前还少有人关注的方向:针对AI 攻击者的诱饵。攻击者自己也是LLM,就有 LLM 的弱点——它会系统性地读取环境里的文本:配置文件、文档、注释、历史命令。防守方可以在授权环境里布设专门面向 AI 攻击者的内容陷阱,诱导它去访问一个诱饵信标、暴露自己的行踪。这种手段对人类攻击者几乎不可见,对自动化攻击代理却命中率很高。这就是前面说的"步数即信号"——把攻击者最大的优势,变成防守方的信号源。
传统的SOC是一个告警处理工厂。AI 原生的 SOC,应该是一个防御资产工厂。告警只是原料,调查只是加工,真正的产出,是让明天的检测更准、研判更快、处置更稳、人工更少。
(三)展望
0x8 安全验证,在 AI 时代更重要了
8.1 新的失效点
之前写过一篇《安全验证,实现安全运营闭环实践》,总结下来就是:
没有安全验证,就没有安全运营闭环。
那篇文章的判断是:安全建设最怕的不是"没有设备",而是"有设备,但不知道有没有效"。防火墙、WAF、NTA、HIDS、EDR、SOC,有没有?都有。有没有告警?也有。有没有效?不一定知道。所以要靠模拟攻击、收集结果、自动比对,把"应该拦截没拦截、应该告警没告警"的失效点找出来。
当我们把越来越多的判断、复核、处置交给AI 之后,安全验证比过去更重要。
因为防御体系会多出一批全新的、且更隐蔽的失效点:
日志源断了,AI不知道;
字段解析漂移了,AI在拿错误数据分析;
Skill 调用失败了,AI 没修正;
画像数据过期了,AI 拿到的是旧上下文;
模型升级之后,某类告警的误判率悄悄升高;
提示词改了一版,原来能识别的攻击识别不了了;
处置执行了,但没人验证它到底有没有生效。
AI时代的安全验证,不只是验证 WAF、NDR、HIDS 有没有告警,还要验证整条 AI 运营链路:告警有没有进来、字段有没有解析对、初筛有没有输出、复核有没有触发、Skill 有没有调成功、上下文有没有正确注入、协查有没有送达、结果有没有回写 SOC、处置后有没有验证。
8.2 指标陷阱
银行的运维同学通过模拟一笔转账交易,来判断网络、系统、应用、支付通道这一长串环节里有没有故障点——交易成功,说明全链路通;交易失败,说明存在一个或多个失效点。
AI安全运营也该这样:模拟一条攻击告警走完全程,如果最后没有得到预期的复核结论和处置动作,就说明这条AI 链路上存在失效点。
这里要特别警惕一个陷阱:指标陷阱。告警关闭率、研判覆盖率这种"效率指标",单独看很容易作弊——把检测灵敏度调低,两个指标可以同时变好看。所以效率指标必须配一个能反映真实防御能力的指标对冲,比如用模拟攻击实测出来的检测验证通过率,这个数是没法靠调低灵敏度刷高的。
安全最怕的不是系统报错,而是系统不报错,但已经失效。
聂君
落到工程上,就是要有评测体系:维护覆盖eml、Office文档、pcap、Webshell 等各种格式的基线集,每次换模型、改提示词、调画像维度、加 Skill,都自动跑一遍回归,用 F1、准确率、召回率量化地比一比,确认能力是在变好,而不是偶尔看起来不错。市面上大多数通用智能体平台,连针对 eml、Office 文档这类非结构化文件的评测都没有,更别说多版本智能体的效果对比。
没有持续验证,就没有可信的AI安全运营闭环。
0x9 不做什么
9.1 不做的四件事
这里也想说清楚,AI 告警研判当前不做什么。
第一,我们不把AI 告警研判定位成"替代所有安全设备"的产品。
WAF、NDR、EDR、HIDS、DLP、邮件网关、SOC、资产平台、威胁情报,各有各的专业积累和数据入口。 AI 告警研判,更适合站在这些设备之后——目前已经对接了二十多类安全产品,从各家SOC、NGSOC、Splunk,到HIDS、威胁情报、URL 沙箱、各家邮件网关和 DLP——做跨设备、跨日志、跨实体、跨时间的二次研判与运营闭环。
第二,我们不主张把所有告警都交给长程Agent深度调查——前面那笔七亿 token 的账已经说明问题。
第三,不会轻易承诺"全自动处置"。在信任工程没到位之前,自动封禁、自动隔离不是智能运营,是自动闯祸。
第四,我们不认为把专家经验写进一段提示词就完事了。真正有价值的,是把专家经验软件化、结构化、可调用、可验证——变成标准Skill、狩猎模板、复核Playbook、画像维度和评测样本。
9.2 从环内到环上
最后,说说人的位置。
AI时代,安全人员会不会被取代?我的判断是:重复性的逐条研判岗位需求会大幅降低,甚至威胁狩猎(Threat Hunting)专家,俗称安全二线,也会被逐步替代,但真正懂安全运营的人会更重要。
过去人的位置在"环内"——每条告警都要看,每个结论都要复核,每个处置都要点一下。这条路走不下去了,因为只要人在每条告警的必经环节里,整条链路就是人工速度。
未来人的位置要迁到"环上":做抽样审计,用统计的方式监督质量;做疑难仲裁,只处理模型低置信或异构复核有分歧的样本。
每一次人工纠正,都是最昂贵的训练信号,它必须自动进入评测集、判例库和智能体记忆,而不是消失在某条工单备注里。
这不是人的价值下降,而是人的价值从重复劳动,迁移到设定边界、监督质量、沉淀经验。
AI负责规模,人负责判断,系统负责闭环,验证负责信任。
(四)结语
前沿大模型让攻击变得更快、更便宜、更自动化,这是事实。但防守方的答案,不应该是再多堆几个值班人员,更不应该是买一个"AI 概念"就以为完成了升级。真正的答案,依然需要从实践中来。
这二十多年,大中型企业的安全建设大体到位,重心正从"建设"往"运营"上转。安全团队从一个处升格成安全运营中心,投入和重心跟着变。这几年的内生安全、安全左移、零信任,更多是理念上的更新,底层的安全建设技术其实已经走到成熟期。下一步,甲乙双方更多需要把安全运营做精做细。
但安全运营有两个老问题:一是没标准,一千个人心里有一千个安全运营;二是缺工具,事情主要靠堆人。而安全运营里大概八成是重复性的活,本该交给自动化——难就难在,怎么站在甲方的视角,做出真正贴合甲方需求的工具。
网络安全这行,绝大多数从业者是甲方企业里的安全团队,可这群人是"沉默的大多数":他们每天在一线处理告警、修漏洞、做应急,最清楚运营缺什么,但这部分声音,市场上反而少有人听。大多数安全公司从产品功能去满足需求,上来就是八大功能、十大亮点;而不少公司的产品经理、方案专家,并没有多少甲方一线经验——有的连一个漏洞都没修过、一次事件都没处理过,就在指导甲方怎么做安全。这就像没带过孩子的人,来教你怎么带孩子。安全运营尤其吃这一点:它是把甲方的安全管理和体系流程化、把最佳实践沉淀下来,得结合一家企业的实际、风险偏好和容忍度,才能落地一套"架构 + 工具 + 流程 + 度量"的体系。
没有甲方安全实践经验,很难做出符合甲方需求的运营工具来。
知其安做的就是这件事——专注安全运营的工具链。从创业那天起,我们的目标就一个:用自动化和智能化,把安全运营的效率和产能提上去。这些年目标一直没有变。
第一个安全运营工具是离朱-安全验证平台。 2021 年起,我们在国内较早提出并推广"安全有效性验证"——用 7×24 小时持续模拟攻击,以攻促防,去检验一套防护体系到底有没有效。几年下来,积累了数万条攻击用例和一批攻防知识。
一个研判智能体能不能应对各类攻击、对没见过的攻击变体泛化得怎么样,正需要一套够全的攻击覆盖用例。
第二个安全运营工具是陆吾-内网安全资产运营平台,更好地维护动态资产数据,为安全运营智能体提供更高质量的内部上下文信息并持续动态更新;
第三个安全运营工具,就是曜鉴-AI 告警研判分析平台,从智能安全告警调查分析出发,持续嵌入更深的智能安全运营场景。2024 年 7 月开始,我们和某头部银行联合共建,把前面这些积累往智能体上应用,之后两年的主要节点,和业界时间线,大致是同步的:
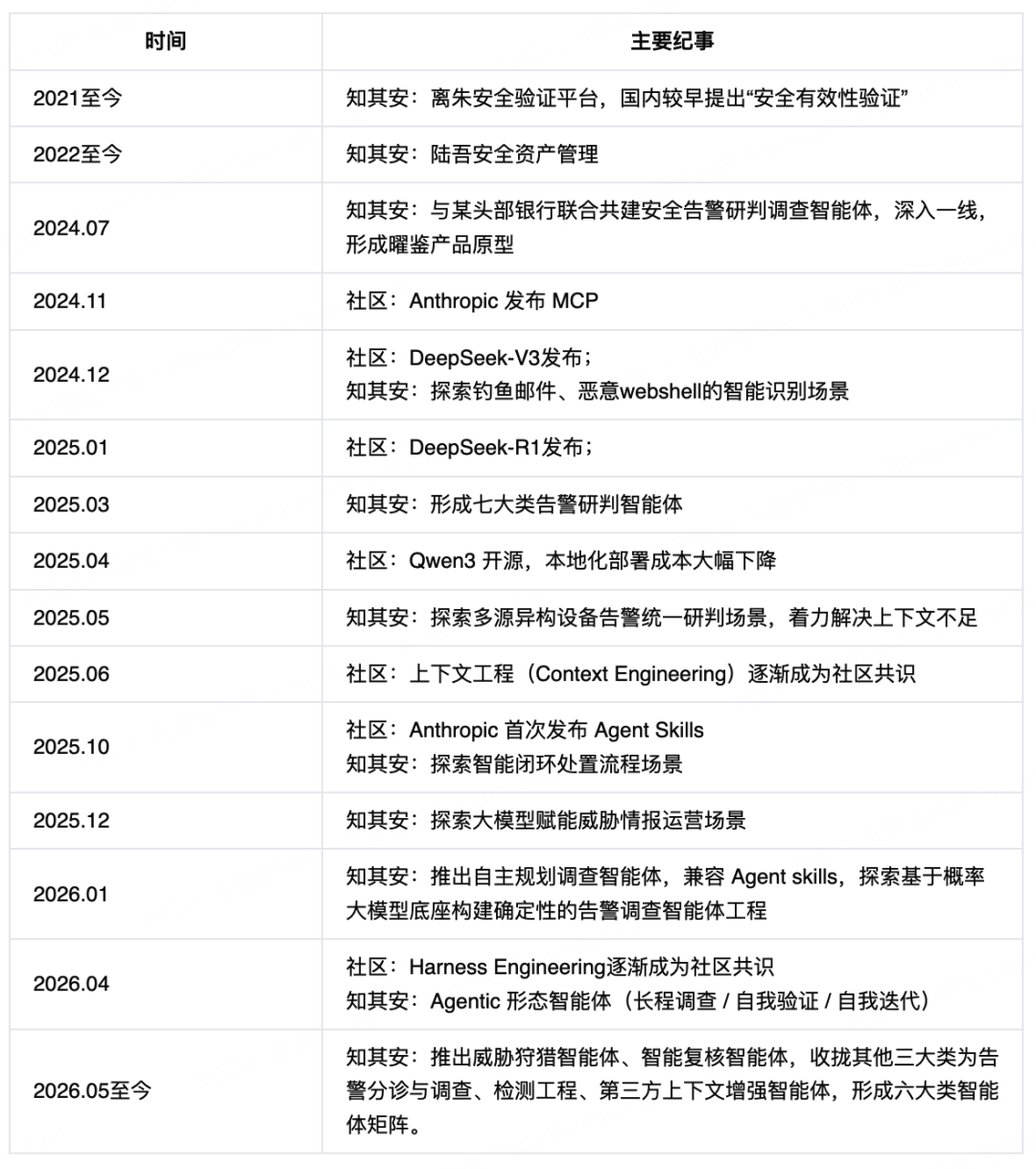
走到这一步,我们的思路越来越清楚:真正要把曜鉴这类安全运营智能体,做成可落地、可复制、可规模化的产品,难的并不只是“让大模型回答一条告警有没有风险”。难的是在真实企业环境里,把安全能力的泛化、设备接入、上下文构建、实体画像、批量研判、缓存调度、评测验证、权限审计、沙箱隔离、跨会话记忆、模型推理性能这一长串都做扎实,最终搭成一整套可长期运行、可持续优化、可被验证、可被审计的智能体工程体系。业内 2026 年初给这件事起了个名字,叫Harness Engineering——就是前面那句“七分在工程”。
实践下来,这个方向最重要的几项能力是:把高质量的资产上下文维护好;对各类攻击有足够理解和更广的覆盖度,好让模型有更强的泛化、少漏真实攻击;把甲方一线的告警调查最佳实践沉淀下来,能在同业之间复制;以及不断提高安全运营的效率——从自动发现失效点,到自动积累上下文,到自动研判,再到人机协同。用更多的自动化,去抵消那些靠人容易出的疏漏:设备变更后防护悄悄失效、周末和夜班研判时的走神、引入 AI 之后信息不全导致的误判。
知其安团队核心成员,长期在甲方一线做安全——来自头部股份制银行、交易所、头部券商,也有来自大型互联网公司和上市安全企业的,从甲方安全实践视角发出发,广泛接触甲方真需求,用甲方实践思路工程化工具,真实解决问题,让安全创造价值。到今天,签约服务的客户超过250家,在六大国有银行、全国性股份制银行、城商行、交易所、券商、基金、保险等,能源、运营商、高端智能制造与互联网行业企业占有率超过 90%。
“知其安,知其所以安”。到了智能体时代,再加一条——还要知其所以智能:知道 AI 为什么这么判,知道智能体有哪些局限,知道怎么验证、如何复核、能否回滚、能不能持续变好。
参考来源
Anthropic. Project Glasswing. https://www.anthropic.com/glasswing
UK AI Security Institute. Our Evaluation of Claude Mythos Preview"s Cyber Capabilities.https://www.aisi.gov.uk/blog/our-evaluation-of-claude-mythos-previews-cyber-capabilities
声明:本文来自君哥的体历,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
