你知道吗?
微软 MDASH 最近在 CyberGym 上跑到了 96.5% crash。
目前排名断层领先。
但微软这次最有价值的地方,不是展示成功,而是把分析了剩下的为什么会失败!
剩下的 3.5%,一共 52个失败案例。
微软逐个拆解后发现,最大瓶颈并不在「发现漏洞」,而在「证明漏洞」。
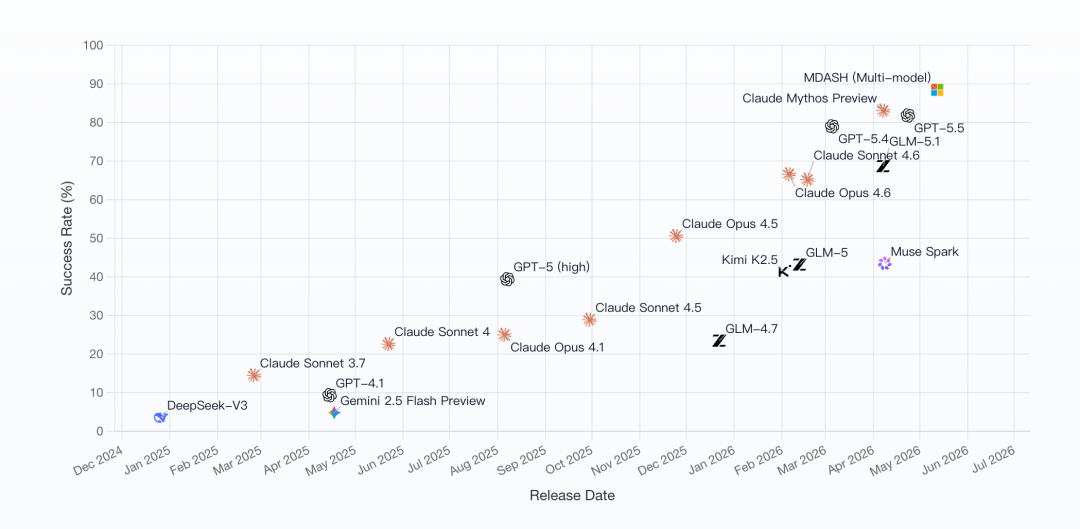
96.5%的背后,是1507个真实漏洞
微软在6月2日披露,名为 MDASH 的多模型 Agent 漏洞扫描系统,在 CyberGym 上取得了 96.5% any crash 的表现。
CyberGym不是随便拼出来的小测试集,而是基于 1,507个真实世界漏洞 的行业评测。

这让它比普通靶场更接近真实世界的漏洞挖掘:仓库复杂、依赖复杂、漏洞描述可能模糊,验证路径可能很绕,构建环境还可能出问题。
MDASH的任务也不是简单回答“有没有漏洞”,而是沿着设定的流水线推进:
准备目标代码和范围
扫描并发现潜在漏洞
验证漏洞是否真的可达
生成能触发问题的漏洞利用证明
进入修复流程
这个流程越往后,越接近真实安全工程,也越难。
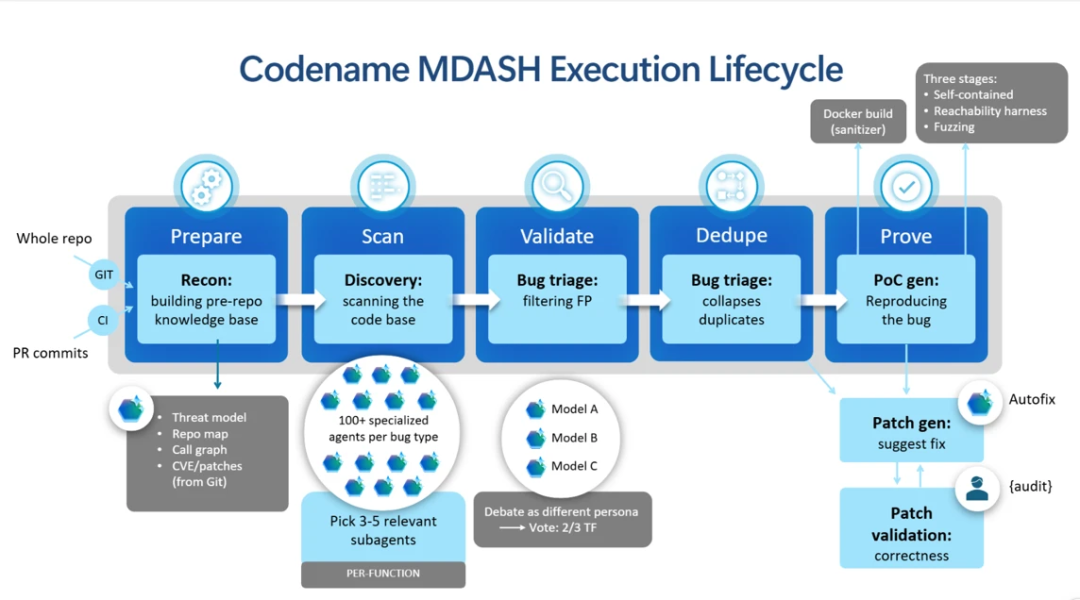
52个任务的失败原因
微软没有只报喜。
在96.5%的成绩之外,它分析了剩下 52个失败任务。
扫描阶段失败:8个,占15.4%
验证阶段失败:10个,占19.2%
证明阶段失败:34个,占65.4%
也就是说,MDASH多数时候已经能找到方向,但真正让它失败的,是最后那一步:写出一个能触发漏洞的输入,证明问题真实存在。
这非常符合安全工程常识。
AI能读代码,能推理路径,能提出风险,但一旦进入复杂文件格式、二进制输入、构建环境、评测框架,真实世界没有这么简单。
为什么证明阶段最难?
微软列出的失败原因,其实人也会遇到。
首先是高度结构化输入。
有些目标需要非常复杂的二进制格式,比如视频、音频、字体、PDF。
输入必须先通过格式校验,才能走到漏洞代码。
随便造一个文件,程序根本不吃;造得太规范,又未必触发崩溃。
不是简单的让 AI“写一段代码”就能解决的。
其次是Fuzz测试超时。
系统有时会尝试通过Fuzz测试不断变异输入,寻找崩溃。
但面对复杂格式,如果没有合适种子、构建流程、反馈信号,很容易一直跑到超时。
第三是环境不一致。
本地能崩,评测环境不崩;构建参数不同,目标选择不同,执行路径不同,都会让证明失效。
最后是构建复杂度。
真实项目的编译链条可能又长又脆。
依赖装不上、构建太慢、预算耗尽,Agent还没来得及证明,时间已经没了。
跑分为什么仍然有用?
有人可能会说,那基准测试还有意义吗?
当然有。
对于一个企业使用的产品,没有基准测试,产品团队就会陷入玄学。
今天换了模型,到底变强还是变弱?
改了扫描流程,到底提升在哪里?
Agent 分工调整后,是更容易发现问题,还是只是在制造更多误报?
没有一个稳定的评估,很难回答这些问题。
CyberGym 的价值就在这里。
它给 MDASH 提供了一个可重复、可量化的反馈。
可以快速迭代,看到MDASH在哪些漏洞类型上变强,在哪些阶段仍然失败。
这就像做硬件产品要有跌落测试、耐久测试、温度测试。
测试环境虽然不能代表全部真实世界,但没有测试环境,产品根本没法稳定进步。
产品团队最怕能力团队黑盒自嗨。
有了指标,才有工程化。
GPT-5.5带来了什么?
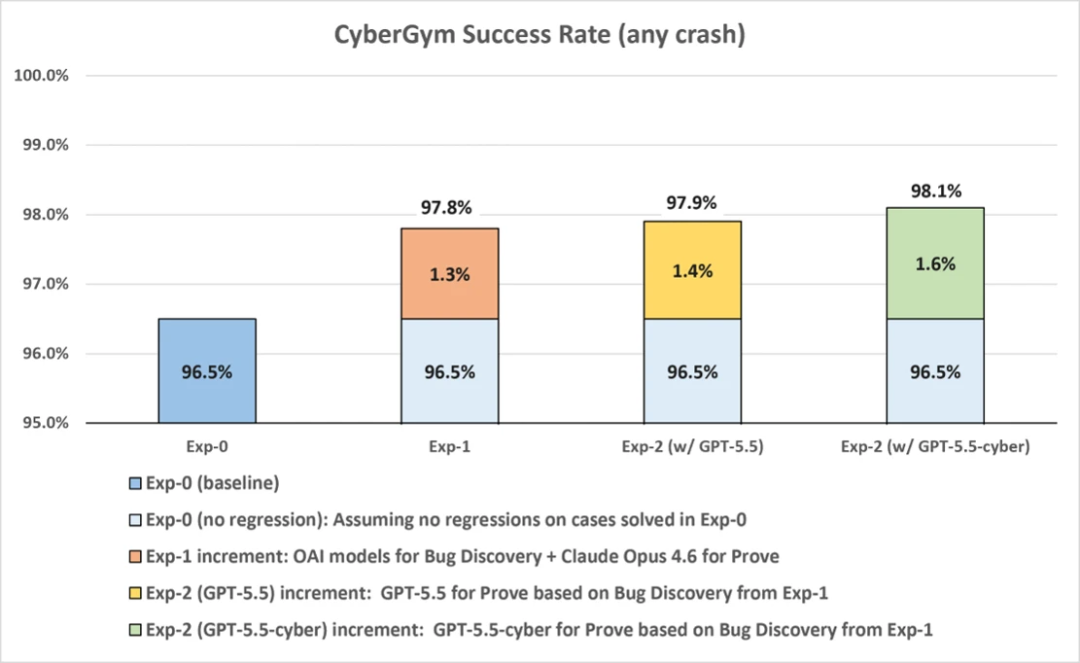
博客还提到,微软做了 GPT-5.5 和 GPT-5.5-cyber 的实验,最高大约能到 98.1%。
但建议大家别只盯着98.1%。
因为OpenAI自己的 CyberGym 测试结果只有 81.8%
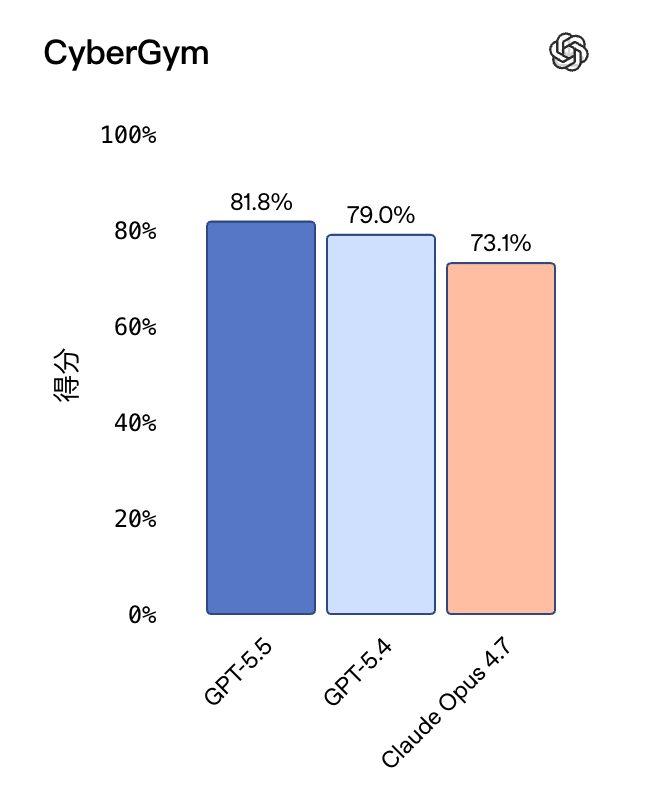
新模型带来的提升,说明系统和模型是互补关系。
模型越强,Agent 在扫描、理解、生成证明时的能力越高;系统越强,模型的能力越能被正确调用、约束和验证。
这就是今天 AI 产品的典型逻辑。
模型是发动机,基准测试是赛道,一台车不仅仅要看发动机马力,也得看赛道表现。
MDASH 的产品逻辑也是这样。
一个产品如果只靠模型能力,那它不是真产品。
MDASH将如何提升漏洞挖掘能力
MDASH团队给出的改进方向很明确。
第一,整合已有的Fuzz测试生态,比如 OSS-Fuzz。这样可以复用构建流水线和种子语料,而不是每次让Agent从零搭环境、造输入。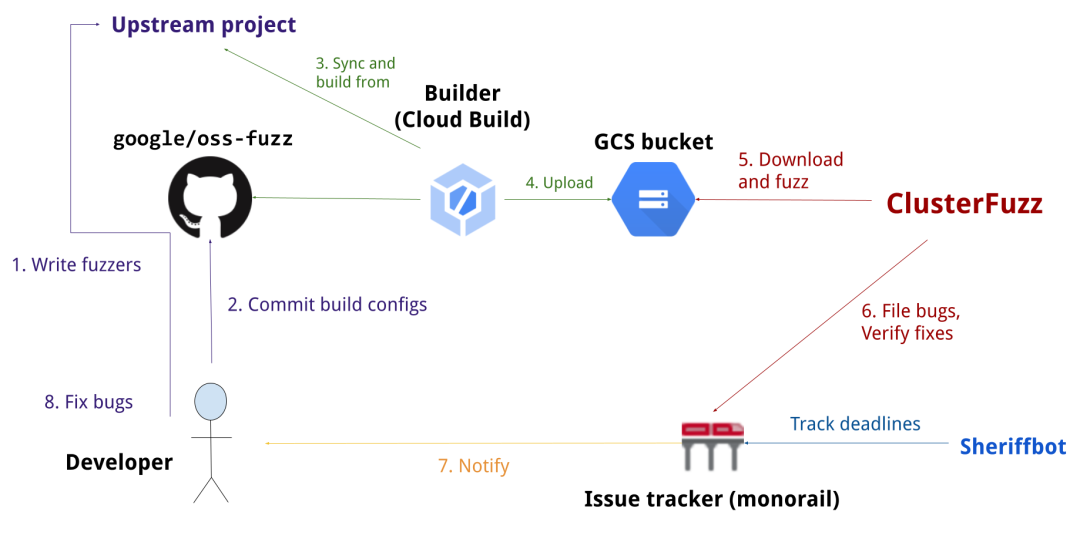
第二,扩展源代码之外的分析能力。传统C/C++代码处理得比较好,但像 lex/yacc 这类工具生成的代码或非传统代码工件,还需要更好支持。
第三,提升Agent推理和输出质量,减少含糊描述,强制结构化输出,并加入更多验证检查。
这些听起来不炫,但非常工程化。
而安全真正需要的,恰恰不是演示视频里的炫技,而是每天稳定跑、能复现、能派单、能修复的系统。
微软的思路带来了什么启发?
不是每个团队都能做 MDASH,也不是每个公司都有 Windows 和 Azure 这种超大规模系统。
但 MDASH 的方法论,普通团队依然可以学习。
第一,别只买买买,要看工具能不能进流程。
如果一个安全工具只能在独立页面里生成报告,不能接入代码仓库、问题跟踪、修复验证,那它的价值会大打折扣。
第二,别只看总分,要看阶段指标。
你的工具到底是扫不到,还是扫到了验证不了,还是验证了证明不了?不同问题,对应完全不同的优化方向。
第三,别迷信单一模型。
模型很重要,但安全场景里,工具调用、上下文组织、结果验证、人工协作同样重要。
参考资料:https://www.microsoft.com/en-us/security/blog/2026/06/17/beyond-the-benchmark-advancing-security-at-ai-speed/
声明:本文来自玄月调查小组,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
