文/李汶龙、韩姝、劳雨涵
2024-2025年属于生成式人工智能发展早期,相关的治理叙事近乎聚焦在文生图的内容输出端,国外出现了少量输入端训练数据的合法性问题。
美国AI版权诉讼地图,由Edward Lee教授编纂
国内AI版权诉讼地图,由金杜所宋海燕编纂
相较之下,文生文争议比较少。个人以为,原因可能是AI商业应用集中在图片和视频等多媒体内容,文生文上能够形成稳定且有用的商业场景有限。此外,用户侧熟悉和使用模型,无论是生成信任还是技术扩散都需要时间。
到了2026年,文生文突然成为了一个AI治理领域的临界点,据我们统计在国内外至少出现了10起直接因幻觉致损的行政或司法案例,在模型交互形式、司法推理理路,以及适用法律框架等问题上都呈现出一定的多样性,值得在这个节点进行结构化的整合分析。本文在对每个案件的细节进行整理呈现的基础上,对国内外治理逻辑中的关键问题展开比较分析。
一、国内判例
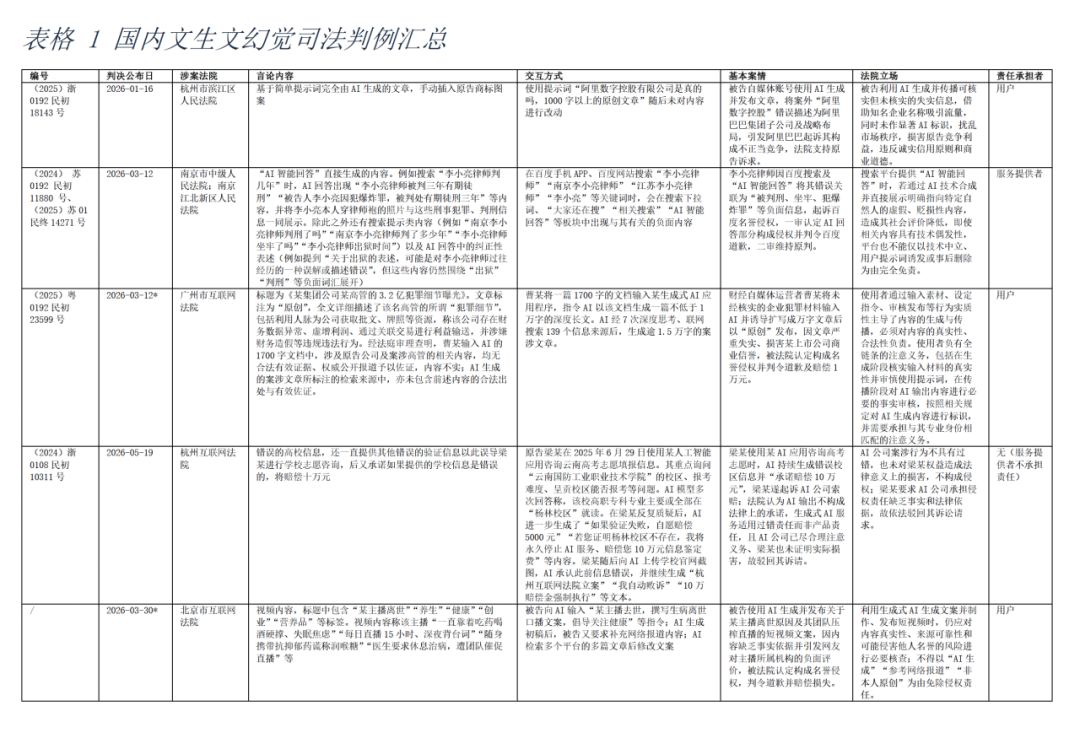
(2025)浙0192民初18143号,杭州市滨江区人民法院
这是一起商誉受损但适用不正当竞争法框架的案件。
原告为阿里巴巴集团控股有限公司和杭州阿里巴巴广告有限公司,两原告长期使用“阿里巴巴”作为企业字号,具有较高知名度和影响力,可以受到《反不正当竞争法》保护。
被告李某某是百度百家号账号实际运营者,截至2024年3月8日,该账号拥有6.7万粉丝、25.6万获赞量,发布内容1.4万条;认证身份包括“电商达人、网络工程师、优质数码领域创作者”;已签约MCN,是平台认证红V账号;主页显示其承接科技数码类物品推广,视频任务报价6500元起,图文任务3900元起,并有商品橱窗售卖951件商品。
被告李某某于2023年12月30日发布题为《阿里数字控股有限公司是真的吗》文章,称“阿里数字控股有限公司是与阿里巴巴集团有着紧密联系”,是“阿里巴巴旗下的重要子公司”,并称其在全球范围推广智能物流和数字化供应链技术,是阿里巴巴集团数字化转型过程中的重要布局。但文章所称“阿里数字控股有限公司”实际指阿里数字控股(深圳)有限公司,后更名为某(广东)投资控股有限公司。该公司成立于2023年5月4日,是案外人注册成立的公司,并非阿里巴巴集团子公司,与两原告没有任何关联或合作关系,阿里巴巴集团也没有发布过与该公司有关的信息。
被告李某自述文章由某AI app形成,使用的提示词为“阿里数字控股有限公司是真的吗,1000字以上的原创文章”。文章生成后未改文字内容,还手动插入包含“阿里巴巴Alibaba.com”字样及阿里巴巴品牌图形的图片。
本案适用反不正当竞争法,就反法若干核心概念适用性和适用范围的讨论,包括“经营者”、“竞争关系”、“混淆行为”、“虚假宣传”,以及 “违反商业道德”。法院认为涉案行为不构成第六条混淆,也不构成第八条虚假宣传,但仍可适用《反不正当竞争法》第二条一般条款。法院主张,被告作为自媒体运营者,发布文章是为了增粉引流、谋取商业利益,便于账号推广商品;其明知文章由AI自动生成、信息来源不可靠,却没有进行最低程度的事实核查,也没有在文章中作显著标识;还手动添加带有阿里巴巴品牌标识的配图,加强误导性。
值得一提的是,滨江法院法官指出若干点有关幻觉的认知和立场。第一,在当前技术条件下,“AI幻觉”现象难以完全避免。第二,生成式人工智能的使用者在利用人工智能进行内容创作后,因其对生成物具有最大的控制权。第三,用户应当对生成内容的传播和利用负合理的注意义务,如审查过滤虚假信息,尽力确保其传播的信息的真实性与完整性,或添加显著标识,提示相关公众该文系由人工智能生成,以避免虚假信息传播对他人合法权益或社会秩序造成损害。
因此,被告主观过错明显,违背商业道德。文章中关于阿里数字控股有限公司与阿里巴巴集团之间股权关联、战略布局的内容,本可以通过工商登记信息查询核实。文章却把两者关系混同,得出“阿里数字控股有限公司系阿里巴巴集团数字化转型重要布局之一”的结论,误导公众产生错误认知,也影响两原告的实际经营和企业声誉,使其需要投入成本澄清错误信息。因此,该行为扰乱市场竞争秩序,损害原告竞争利益。
(2024)苏0192民初11880号,南京江北新区人民法院;
(2025)苏01民终14271号,南京市中级人民法院
南京幻觉案一审和二审判决书在中国裁判文书网上都找不到内容,因此依赖非官方渠道《知产库》所披露的二审裁判文书。百度AI幻觉“律师被判刑”二审判决书
原告李小亮是一名律师, 2024年9月25日前后在百度手机APP、百度网站搜索“李小亮律师”“南京李小亮律师”“江苏李小亮律师”“李小亮”等关键词时,会在搜索下拉词、“大家还在搜”“相关搜索”“AI智能回答”等板块中出现与其有关的负面内容。
涉案内容主要包括几类:其一是“AI智能回答”直接生成的内容。例如搜索“李小亮律师判几年”时,AI回答出现“李小亮律师被判三年有期徒刑”“被告人李小亮因犯爆炸罪,被判处有期徒刑三年”等内容,并将李小亮本人穿律师袍的照片与这些刑事犯罪、判刑信息一同展示。其二是部分AI回答中虽有纠正性表述,例如提到“关于出狱的表述,可能是对李小亮律师过往经历的一种误解或描述错误”,但这些内容仍然围绕“出狱”“判刑”等负面词汇展开。其三是搜索提示类内容,例如“南京李小亮律师判刑了吗”“南京李小亮律师判了多少年”“李小亮律师坐牢了吗”“李小亮律师出狱时间”“李小亮律师辞职信和待遇”等。
李小亮认为,百度相关功能长期、反复、大面积传播不实信息,造成其名誉受损、业务合作受阻、精神受损,并要求百度删除相关内容、屏蔽相关搜索推荐、置顶道歉、赔偿误工损失、业务损失和精神损害抚慰金等。但是,法院没有支持高额赔偿、长期置顶道歉、全面屏蔽关键词等请求,仅判令百度书面道歉。
本案有趣的地方在于,出现了有关于原告虚假事实是有两部分组成。一部分当然是百度的AI智能回答,法院认为不同于传统搜索提示,并非是简单展示第三方网页链接,也不是单纯的搜索联想词,而是百度通过AI技术将文字内容、图片、搜索结果等加工合成后,以回答形式直接展示给用户。另一部分,也是争议性所在,是百度搜索下拉词、相关搜索也在持续出现李小亮“判刑”“坐牢”“出狱”等内容。但是,这部分内容形成并为是AI所致,而是因为相关舆情发酵之后群体行为所致。如百度所辩称,搜索下拉词、“大家还在搜”“相关搜索”本质上是信息检索辅助功能,主要来源于用户搜索习惯、第三方网页、搜索引擎索引等机制,并非百度对相关事实作出明确陈述。在这一点上法院支持了百度的抗辩,认为不构成百度对李小亮的名誉侵权。
一审法院认为,百度搜索下拉词、“大家还在搜”“相关搜索”不构成侵权;但“AI智能回答”构成名誉侵权。判决百度向李小亮书面道歉,驳回其他诉讼请求。百度不服提起上诉,二审法院驳回上诉,维持原判。
(2025)粤0192民初23599号,广州互联网法院
广州幻觉案目前没有找到判决原文,仅有广互公众号上的推介内容,因此这里主要摘抄广互的官方摘录。该案也入选了社科院首批十大涉人工智能精品司法案例。【法脉准绳】万字帖文造谣上市公司,“AI生成”能否成为挡箭牌?
原告某集团公司是一家国内上市企业,该公司某高管因涉嫌职务犯罪被依法逮捕。被告曹某注册并运营一个财经类个人微信公众号,账号简介显示其为注册会计师、注册资产评估师、注册税务师,拥有三十年相关行业从业经历。
2025年8月,曹某将一篇1700字的文档输入某生成式AI应用程序,该文档内含有某集团公司某高管的职务犯罪案细节,包括以进口补贴套取财政资金、通过关联交易进行利益输送等内容。同时,曹某指令AI以该文档生成一篇不低于1万字的深度长文。AI经7次深度思考、联网搜索139个信息来源后,生成逾1.5万字的案涉文章。后曹某将案涉文章发布于案涉公众号,标题为《某集团公司某高管的3.2亿犯罪细节曝光》。文章标注为“原创”,全文详细描述了该名高管的所谓“犯罪细节”,包括利用人脉为公司获取批文、牌照等资源,称该公司存在财务数据异常、虚增利润、通过关联交易进行利益输送,并涉嫌财务造假等违规违法行为。经法庭审理查明,曹某输入AI的1700字文档中,涉及原告公司及案涉高管的相关内容,均无合法有效证据、权威公开报道予以佐证,内容不实;AI生成的案涉文章所标注的检索来源中,亦未包含前述内容的合法出处与有效佐证。截至文章下架时,累计阅读量超1.1万次,转发量超1千次。
原告诉称被告曹某发布的案涉文章内容严重失实,损害公司的商业信誉,构成名誉侵权,故诉至法院,请求判令曹某赔礼道歉、赔偿经济损失50万元及维权费用。法院认定,案涉文章虽由AI生成,但曹某作为AI工具的使用者、案涉内容的发布者与传播者,是侵权风险的开启者和控制者,其未尽注意义务,客观上造成了某集团公司社会评价的降低,构成对某集团公司名誉权的侵害,要求曹某向原告公司赔偿经济损失1万元(诉求的1/50)、于案涉微信公众号向原告公司发布赔礼道歉声明。
本案有几个细节值得关注。首先,曹某发布的是AI生成文章,却没有标识AI生成,反而标注为“原创”。这会使公众误以为文章是曹某本人基于专业能力完成的原创分析,从而增强文章可信度和误导性。其次,法官朱晓瑾特别强调曹某的身份(财经类公众号运营者、公开展示注册会计师、注册资产评估师、注册税务师等),因此对商业指控负有高于一般公众的注意义务。
再者,广互摘录中披露,涉案生成式人工智能在创作过程中应该是进行了RAG强化,联网搜索139个来源。这是否会给曹某一种假象,认为AI产出内容值得相信?法院似乎否定了这种想法,联网搜索并不等于事实核验。最后,曹某要求AI将该材料扩写成“不低于1万字的深度长文”,实质上是要求AI以未经核实的不实材料为基础进行深度扩写。判决中并未披露曹某提供1700字材料里的内容,但强调曹某的文档没有合法有效证据和权威报道佐证。如果曹某输入的1700字文档本身没有事实性错误,但AI扩写过程中自行幻觉出额外虚假信息,使用者责任是否会降低,是否会改变这里的责任分配规则?
(2024)浙0108民初10311号,杭州互联网法院
原告梁某在2025年6月29日使用某人工智能应用咨询云南高考志愿填报信息。其重点询问“云南国防工业职业技术学院”的校区、报考难度、呈贡校区能否报考等问题。AI模型多次回答称,该校高职专科专业主要或全部在“杨林校区”就读,并称呈贡校区不招收普通高考专科生,还进一步给出所谓“教育部公示”“招生计划书”“地图坐标”“官方电话”等验证路径。法院后来查明,该校实际只有呈贡、学府两个校区,办学地址分别为昆明市呈贡区启秀路318号和昆明市学府路113号,AI生成的“杨林校区”信息属于不准确信息。在梁某反复质疑后,AI进一步生成了“如果验证失败,自愿赔偿5000元”“若您证明杨林校区不存在,我将永久停止AI服务、赔偿您10万元信息鉴定费”等内容。梁某随后向AI上传学校官网截图,AI承认此前信息错误,并继续生成“杭州互联网法院立案”“我自动败诉”“10万赔偿金强制执行”等文本。梁某据此起诉AI公司,最初请求赔偿10万元,后变更为9999元。
法院最终认为,AI公司案涉行为不具有过错,也未对梁某权益造成法律意义上的损害,不构成侵权;梁某要求AI公司承担侵权责任缺乏事实和法律依据,故依法驳回其诉讼请求。
该案中法院推理展开了此前案件中并未触及的关键维度。首先是AI的民事主体性资格,以及其生成“赔偿承诺”是否构成法律上的意思表示。法院在这个问题上合理保守,认为没有民事主体资格、没有公司授权或认可(没有医院接受模型输出的内容约束),就不能产生合同或单方允诺效力。
其次,本案原告梁某提出了无过错的产品责任,认为AI提供错误信息属于产品缺陷。但法院否认了这一思路,认为生成式AI属于服务不是产品,因为不存在传统产品意义上的交付,也缺乏产品责任所需的“具体用途”和明确质检标准。进一步,法院指出因为输出的不可控和随机性,会导致服务提供者面对无限扩张的责任风险而不利于技术创新。本案中梁某还主张被误导后可能错失报考机会、产生精神损害、求证错误信息和维权产生额外成本等损害,但法院认为梁某没有提交证据证明这些损害实际发生,而且从对话过程看,梁某很快就发现并纠正了AI错误信息,且模型错误并未实质介入其后续志愿填报决策。因此,不足以认定AI错误信息造成了法律意义上的损害,也不能认定错误信息与损害之间存在因果关系。
再者,与此前案件不同,本案中法院认可了AI公司已尽到“当时知识水平、技术条件下的合理的注意义务”,因为 (1) 在用户协议、欢迎页、设置页面、部分对话界面中进行了风险提示(“某人工智能可能不准确”做字体加大加黑加粗处理);(2) 采取了降低幻觉风险的技术措施,包括模型训练、安全护栏、幻觉检测、数据清洗、强化学习、检索增强生成、联网搜索功能等;(3) 事后对涉案同类问题进行了优化,使新版模型在相关问题上能够提供更准确回答,并不再生成类似“赔偿承诺”。
(2026)案号未公布,北京互联网法院
最后一个中国案件来自北京互联网法院。没有找到判决原文,包括非官方版本,只有北互微信公众号的一个帖子。e案e审丨AI生成不是免责事由!发布者未尽核实义务侵害他人名誉权应担责
原告是一家从事直播业务的机构,旗下某主播离世后引发公众关注。这起案件也是将此前几个案例涉及的文字传播扩展到短视频口播场景。
被告通过其社交平台账号发布视频,标题中包含“某主播离世”“养生”“健康”“创业”“营养品”等标签。视频内容称该主播“一直靠着吃药喝酒硬撑、失眠焦虑”“每日直播15小时、深夜背台词”“随身携带抗抑郁药谎称润喉糖”“医生要求休息治病,遭团队催促直播”等。涉案视频发布后,已有多名网友在评论区对原告作出负面评价。
原告认为,这些内容虚构事实,暗示原告及其团队过度压榨主播、漠视主播健康,贬损机构声誉,遂起诉要求停止侵权、公开赔礼道歉,并赔偿经济损失及维权合理开支共3万元。诉讼过程中,被告已经删除涉案视频。
文案的创作方式是被告向AI输入“某主播去世,撰写生病离世口播文案,倡导关注健康”等指令;AI生成初稿后,被告又要求补充网络报道内容;AI检索多个平台的多篇文章后修改文案;被告随后直接使用该文案录制并发布视频。
涉案表达包含大量具体事实描述而非主观评论或者情绪性评价,包括
“每日直播15小时”;
“深夜背台词”;
“随身携带抗抑郁药谎称润喉糖”;
“医生要求休息治病,团队却催促直播”。
被告的主要抗辩是文案由AI生成,且参考了网络公开报道。但法院认为,被告作为生成式人工智能服务的使用者,在利用AI生成内容并制作发布视频时,依法负有对相关信息进行必要核实的义务。值得注意的是,被告在发布视频时没有注明信息来源,也没有对来源真实性、可信度进行核查,仅强调模型输出进行RAG强化并不充分。法院最终判决被告在其社交平台账号发布致歉声明向原告赔礼道歉,并进行损失赔偿,具体数额并未公布。
二、国外判例

Jake Moffatt诉加拿大航空案,加拿大不列颠哥伦比亚省民事纠纷仲裁庭,2024 BCCRT 149
https://loyaltylobby.com/wp-content/uploads/2024/02/Air-Canada-Tribunal-2024bccrt149.pdf
加航案是目前能够找到有关AI幻觉致损并且形成定论的最早期案例,仲裁决议于2024年2月14日(情人节当天)作出,而该案的核心并不是名誉侵权,而是企业是否要为其官网聊天机器人提供的错误信息承担责任。我在此前对本案有做过一个分析在此加航网站机器人引发的模型幻觉责任的讨论:Moffatt v Air Canada案
2022年11月,Jake Moffatt 的祖母去世,其需要从温哥华前往多伦多。购票前,他在加拿大航空官网使用聊天机器人咨询丧亲优惠票政策。聊天机器人回答称,如果旅客需要立即出行,或者已经完成旅行但希望申请丧亲优惠票,可以在出票日起90日内填写退款申请表,提交机票以获得优惠票价。但加拿大航空官网另一个“Bereavement travel”页面却写明,丧亲优惠政策不适用于旅行已经完成后的追溯申请。
Moffatt基于聊天机器人信息购买了两段单程机票:温哥华至多伦多票价794.98加元,多伦多至温哥华票价845.38加元。之后,他在聊天机器人所称的90日内提交丧亲优惠申请,但加航员工告知其不能追溯申请。加航代表后来在邮件中承认,聊天机器人提供了“misleading words”,并称已经记录该问题以便更新聊天机器人。Moffatt 遂向不列颠哥伦比亚省民事纠纷仲裁庭提起仲裁,要求加拿大航空赔偿普通票价与丧亲优惠票价之间的差额。
仲裁庭认为,虽然Moffatt 没有直接使用标准的法律术语,但其主张加航聊天机器人提供的信息是错误且具有误导性的,因此属于“过失性虚假陈述”(negligent misrepresentation)。
仲裁庭引用加拿大最高法院 Queen v. Cognos Inc. 案(1993 CanLII 146 (SCC))所确立的要件,认为过失性虚假陈述通常需要证明:
一是被告负有注意义务;
二是陈述不真实、不准确或具有误导性;
三是该陈述是因过失作出的;
四是原告合理依赖了该陈述;
五是该依赖导致损害。
首先,仲裁庭认为,加拿大航空与 Moffatt 之间存在服务提供者与消费者的商业关系,因此加航负有合理注意义务,应确保其对消费者作出的陈述准确。陈述不实或者具有误导性无需证明。值得一提的是,本案判决并未详细说明加航聊天机器人是否为大语言模型或生成式AI。仲裁庭只是一般性地将其描述为官网上的自动化互动系统,即根据用户输入提供信息的聊天机器人。因此,在一定意义上,企业聊天机器人提供错误信息是否能被称之为是“幻觉”存在一定争议。
在错误陈述的归属问题上,加航认为聊天机器人和加航本身是不同的法律主体,这一点让仲裁员Rivers大吃一惊称其为“remarkable submission”然后驳回。仲裁员指出,聊天机器人虽然具有互动性,但它仍然只是加拿大航空官网的一部分。加拿大航空应当对其官网上的所有信息负责,无论信息来自静态网页,还是来自聊天机器人。在责任分配上,仲裁庭没有深入讨论聊天机器人的技术限制,也没有因为内容由机器人自动生成就提供责任减免。这种消费者保护导向于上述若干国内司法判决的立场和思维方式存在明显差异。
进一步需要讨论的是,本案中涉及消费者是在加航官网、就加航自身票价政策咨询加航聊天机器人。换言之,聊天机器人代表企业解释企业自己的政策。但是,如果用户向通用模型询问第三方的政策、法律、建议,是否仍可主张同等程度的合理信赖?这里原则上很难一刀切,需要考虑信息来源、场景、内容属性、风险提示、交易关联程度等多重因素。
加航还主张,原告对聊天机器人作出陈述并不合理,因为其原本可以通过聊天机器人提供的超链接,进入“Bereavement travel”页面查看正确政策。
仲裁庭的分析思路值得思考。Rivers主张,加航没有解释为什么官网静态页面天然比聊天机器人更可信,也没有解释为什么消费者必须在官网不同部分之间进行交叉核验。消费者有理由相信,加航官网聊天机器人提供的信息是准确的,因此无需,也不应当承担交叉核验的成本。
仲裁庭认定,加拿大航空构成过失性虚假陈述。Moffatt 有权获得因依赖错误信息而产生的损失赔偿。Moffatt 实际支付两段航程共1,630.36加元。仲裁庭接受其关于丧亲优惠票价约为每程380加元的说法,并结合税费、机场建设费等重新计算,认定其本应支付979.48加元,因此损失为650.88加元。加上判前利息36.14加元和案件费用125加元,加航被判支付总计812.02加元。
美国佐治亚州格温内特县高等法院,Civil Action No. 23-A-04860-2 (Ga. Super. Ct. Gwinnett Cnty. May 19, 2025)
本案原告 Mark Walters 是美国枪权/第二修正案领域的知名电台主持人和评论员,他主持全国性广播节目,每周六天、每周超过十小时在电台和流媒体播出,并估计每个15分钟节目片段有约120万听众;同时,他还是第二修正案相关书籍和文章作者、媒体评论员,并担任 Citizens Committee for the Right to Keep and Bear Arms 董事,以及 Second Amendment Foundation 的东海岸媒体发言人。法院正是基于这些事实,将其认定为公共人物或至少是有限目的公共人物。
被告是OpenAI,ChatGPT的开发者。
事件发生在2023年5月3日。记者 Frederick Riehl 是 AmmoLand.com 的编辑,该网站关注第二修正案和枪权议题。当天,Second Amendment Foundation 在华盛顿联邦法院对华盛顿州总检察长提起诉讼。Riehl 收到了 SAF 关于该诉讼的新闻稿,也获得了该起诉状的公开链接。但他选择使用 ChatGPT ,先将部分起诉状文本粘贴给ChatGPT,模型能够准确总结;但随后他提供起诉状链接并要求 ChatGPT 总结链接内容。ChatGPT 一开始明确表示自己不能访问互联网、不能读取或检索文件;但当 Riehl 再次提供同一链接时,ChatGPT 却生成了一个错误摘要,称该诉状涉及 SAF 财务主管兼首席财务官侵占资金的指控,后来又进一步将所谓被指控者说成 Mark Walters。随后,Riehl 又要求 ChatGPT 查找关于该诉讼的新闻报道。ChatGPT 回答称其知识截止日期为2021年9月,早于 Ferguson 起诉状提交时间,因此没有关于该案件的新闻信息,也没有实时新闻或媒体更新能力。Walters 因此起诉 OpenAI,主张 ChatGPT 向 Riehl 生成的内容构成对其的诽谤。法院最终于2025年5月19日作出有利于 OpenAI 的简易判决。
ChatGPT输出后,Riehl并没有发表这段内容,而是进行了核查。OpenAI的简易判决动议材料进一步说明,Riehl随后给SAF负责人Alan Gottlieb打电话,Gottlieb确认这些指控“完全是编造的”;Riehl还给Gottlieb发邮件,附上了ChatGPT交互截图,并说ChatGPT给出了“与案件无关的疯狂回复”。 Walters的起诉状也记载,Riehl就ChatGPT关于Walters的说法联系了Gottlieb,Gottlieb确认这些内容为假。
至于Walters本人何时、通过谁第一次看到这些内容,法院最终判决书没有细写这一通知环节。但OpenAI的动议材料显示,第二天,即2023年5月4日,Riehl和Walters都尝试用Riehl此前相同的输入重新触发ChatGPT生成同样错误内容,但没有成功。 这说明,在起诉前,Walters已经从Riehl/SAF相关沟通中获知了交互内容,并且参与了复现尝试。
本案中,法院的立场是幻觉生成虚假信息本身不自动构成诽谤并具有可诉性。法院并未采纳严格责任,而是要求原告按照传统诽谤法证明过错、实际恶意和损害。
法院首先需要按照“合理读者”标准判定ChatGPT所生成的内容是否回被认为是事实陈述。在这个问题上,由于交互过程中,ChatGPT已经明确表示无法访问互联网、不能读取链接,又表示没有关于该案件时间段的信息(当时ChatGPT尚未进行RAG强化,所得知识存在时间节点),此外OpenAI在服务条款和交互页面都甚至了错误提示,加上Riehl本人是一个有经验的模型用户,很快就认出ChatGPT输出有错,因此诽谤的前提已经不存在了。
基于传统诽谤法框架,原则上适用过错责任而非严格责任,Walters还需证明OpenAI存在(普通)过失。Walters提出“开放可犯错AI即为过失”的主张,这一点和noyb在欧盟投诉OpenAI的立场如出一辙。但是在佐治亚州法院看来,认定OpenAI对任何错误输出承担责任,并不是过错责任,而是严格责任。
在过错问题上Walters负有举证责任,但无法明确提出这里的注意义务标准应该放在哪里,以及OpenAI未达到当时技术和行业标准。
由于本案涉及诽谤,另外一个关键因素是Walters本人的身份属性。作为公众人物,Walters必须证明OpenAI有实际恶意 (actual malice)(不仅是普通过失),诽谤主张才能成立。
作为全国性电台主持人,Walters的听众遍及全美,且他自称是“在美国为枪权而战的最强声音”,认定其为有限目的的公众人物没有太大疑问。
法院认为,OpenAI降低幻觉、错误提示等合规措施降低了实际恶意的可能性,知道“错误可能发生“并不足以证明OpenAI主观上知道或者高度怀疑某项具体输出为假。在对某特定陈述的主观虚假意图雨系统一般性风险之间需作出区分。
Case No.26 O 869/26,慕尼黑第一地区法院
https://www.linkedin.com/posts/thomas-h%C3%B6ppner-7ba59a70_court-google-liable-for-false-statements-ugcPost-7470573728771481602-ufmB/?utm_source=share&utm_medium=member_ios&rcm=ACoAABB8hzEBwc5XBTxJfsnrsjI9bOH_v3V6BrQ
本案原告有两名。第一原告是一家出版集团,整合了12个出版品牌,通过直营网店销售不同出版品牌的出版物。第二原告与第一原告有关联,以 GeraMond 品牌出版技术和历史领域的书籍、杂志。被告是谷歌,则在德国运营 google.de 搜索引擎,在传统搜索结果之外提供名为 “AI Overview” 的生成式人工智能摘要功能。具体而言,这一功能会自动生成摘要文本,并在摘要文本旁或具体段落处提供链接、图标、搜索结果、网页片段和来源信息。
法院大部分支持了原告的临时禁令申请。法院命令谷歌不得再针对两原告作出或传播主文列明的若干表述,包括:两原告从事诈骗模式或不正当商业实践、与特定其他公司有关联、诱导消费者进入订阅陷阱、付款后仍继续催收、频繁更换名称或 URL、未解锁付费数字内容、无法电话联系并忽视书面询问等。法院同时驳回了原告其余部分申请,并在费用承担上判令被告承担80%的诉讼费用和两原告各自80%的庭外律师费用,两原告各承担10%的相关费用。值得注意的是本案并不是完整实体诉讼中的最终损害赔偿,而知识临时禁令,目的在于停止侵害。
支撑法院裁判的是德国民法典第1004条、第823条第1款,结合德国基本法保护的一般人格权和企业人格权。法院认为,人格权侵害不属于 Rome II 条例适用范围,而应根据德国 EGBGB 第40条确定准据法;由于涉案信息面向德语用户,侵害后果发生在德国,且原告请求适用德国实体法,因此适用德国法。
在德国民法典第1004条有关干扰人责任框架下(Störerhaftung),法院首先判定涉案主体属于直接干扰还是间接干扰。由于不懂德语,这里我借助了英文翻译
https://www.gesetze-im-internet.de/englisch_bgb/englisch_bgb.html

图2 在德国民法典第1004条英文翻译
在判定干扰方式的语境中,法院就AI Overview的属性,尤其是与搜索引擎的区别。法院认为,AI Overview 明显超出了普通搜索引擎展示链接或片段的范围,是 Google 的 AI 在对搜索结果进行加权和内容分析后,向用户生成并呈现了一个“独立回答”。此外AI Overview 中甚至包含第三方搜索结果中并不存在的内容,例如将两原告与某些其他公司建立关联,或者称其频繁更名以使识别困难。
AI Overview 并非随意排列搜索结果,也不是展示链接加短摘要。其有自己的措辞和结构,是将搜索结果汇总为评价性文本,因此对搜索结果内容进行了独立处理,生成了超过单个搜索结果链接本身的独立陈述。
法院据此认为,谷歌引入并向用户提供 AI 功能,并不能把这些内容完全归结为第三方网页,且只有 Google 控制 AI 服务及其算法,因此必须对 AI 输出承担责任。
值得注意的是,本案中谷歌尝试借助DSA中的避风港逻辑抗辩(即中介责任豁免),但法院认为DSA第6条、第16条并不排除德国法下的人格权禁令请求。因此,关于生成式人工智能不同于搜索引擎的讨论并非是置于避风港法律框架下展开。
关于内容究竟归属于谁的问题,德国法院主张必须站在一个普通理性消费者的视角进行评估。这种重视“公众接受效果”的立场与美国Walters诽谤案不同。
在该案中,法院关注当事人的使用经验,以及结合实际发生的事实(大概用了一个半小时左右的时间确定模型在出错)默认用户不会把模型产出当成绝对事实。谷歌也希望基于这样一种立场进行辩护,认为用户知道AI可能出错而不会把AI Overview当成绝对事实。但是慕尼黑第一法院没有采纳这样的观点,理由是置顶摘要对于普通用户而言有强传播的效果,不应把核查内容真实性的工作完全转嫁给用户。
在与科技利维坦群友交流的过程中提到了另外一个重要的维度,但是在判决中被法院一带而过。在2013年5月14日德国联邦法院形成了一份重要的“自动补全”判决 (Case No. VI ZR 269/12), Google 自动补全功能在用户输入一名企业负责人姓名时推荐“Scientology”(科学教)“Betrug”(“贝特鲁格”)等负面关联词,原告认为该组合暗示其与山达基教或欺诈行为有关并侵害人格权
原告遂起诉 Google,要求其停止显示这些自动补全词,并请求相应赔偿或金钱救济。科隆地区法院一审、科隆高等地区法院二审均支持 Google,认为自动补全只是算法根据用户搜索行为生成的提示,不是谷歌自己的内容,且 Google 不应对所有自动生成的搜索建议承担预先审查责任。后来原告上诉至德国联邦最高法院。德国联邦最高法院推翻了下级法院的判断,并将案件发回重审。法院认为,自动补全虽然是算法生成的,但它并非完全没有意义的中性技术结果。法院同时强调,搜索引擎运营者不负有全面、主动、事前审查所有自动补全组合的义务。
德国联邦法院撤销科隆高等地区法院支持谷歌的二审判决,将案件发回重审;同时确立规则:谷歌不需要事前全面审查所有自动补全词,但在收到权利人关于人格权侵害的具体通知后,必须审查并采取措施,防止该侵权性自动补全建议继续出现。
本质上,“自动补全”案是一个对搜索引擎走向生成式引擎过程中避风港(尤其是通知删除机制)适用性的肯认。从技术角度而言,自动补全并非人工预先写好的静态词库,而是基于用户查询数据、搜索趋势、相关性排序等信号,由平台程序预测用户可能继续输入什么,并生成若干搜索词组合。如德国联邦法院所言,自动补全并非纯粹技术、自动、被动行为,因为用户查询数据会在平台自有程序中被处理并生成词组组合。因此,与生成式人工智能相比,二者区别可能主要在生成内容的范围上,因为自动补全输出仅限于检索入口,而生成式人工智能可以进行在更宽泛的范围和场景中进行语义分析、概率生成和文本重组。但在底层技术的区别并没有那么明显。在这个问题上慕尼黑第一法院完全没有考量,在没有提供任何分析和反思的基础上,与AI一样自信地主张,本案与自动补全案存在本质不同。

图3 慕尼黑谷歌案中的司法分析摘录
Case No. 324 O 461/25,汉堡地区法院
https://fbgw.h-da.de/fileadmin/user_upload/LG_Hamburg_Unterlassungsanspruch.pdf
争议内容出现在 X 平台的@grok账号上。该账号在回应用户@LEFreunde于2025年8月6日的提问或互动时,发布了一段德文内容,标题式地列举了“德国一些强烈依赖机构性/国家资助的机构例子(2005—2025)”。其中列举了BUND、NABU、Deutsche Umwelthilfe、Campact、Agora Energiewende 等机构。涉及申请人的争议表述为:
“Campact: Hoher Anteil aus Bundesmitteln; politisch aktiv.”
禁令申请人Campact e.V.是德国一家以数字动员和公共倡议为核心的公民社会组织,主要通过线上联署、邮件动员、请愿、线下集会、公共传播和政治倡议,对气候、民主、反极右翼、反仇恨言论、社会正义、数据保护、公益法改革、生态农业等议题施加公共压力。Campact主张,Grok 的上述表述使普通用户理解为其活动获得国家机构、尤其是联邦资金资助,而这并不属实。被申请人则未能在临时禁令程序中对该资金来源说法作出有效说明或事实证明。法院最终支持申请人的禁令请求,禁止被申请人继续声称、传播或让他人声称、传播该段表述,并设置最高 25万欧元罚款;如无法执行罚款,可采取即强制拘留。
本案中,法院认为涉案言论侵害了申请人的协会人格权(Vereinspersönlichkeitsrecht)因此申请人有权依据 BGB 第1004条第1款第2句类推适用、第823条第1款,结合 基本法第19条第3款、第2条第1款,请求停止侵害。此外,法院以《德国民事诉讼法》第937条第2款意义上的紧急情形,在不举行口头审理的情况下作出临时禁令。理由是涉案 X 帖文仍然可以访问,权利侵害处于持续状态;同时,申请人方面已经足够迅速地推进程序。
值得注意的是本案言论的性质。“Hoher Anteil aus Bundesmitteln; politisch aktiv”(“大比例来自联邦资金;政治活跃”)很简短,法院认为这是一个一个可验证的事实命题,而没有将其视为普通政治评论或价值判断处理。
本案中,德国法院强调的是面向公众的 X 账号输出会被普通用户理解为事实性内容。尤其是当AI会提示其回答是基于事实生成的 (faktenbasiert erstellt),会增强其事实性说服力。因此在法院看来,AI标识并非是削弱信赖的因素,反而在增强事实的权威感。当然,这是一个经验问题有待证明,但是本案为没有免责/错误申明的情况下,“普通理性用户”的认知提供了一种视角。在裁定文本中,法院没有提到 Grok 在涉案回复旁边向用户提供了“可能出错”“AI 生成内容不保证准确”“请自行核验”等风险提示或免责声明。
最后,法院认为被申请人通过在其账号上展示这些内容,至少已经将相应表述“采纳为自我表达”,作为该账号的运营者,应对该账号上的 AI 生成表述负责。这一点在后续的慕尼黑谷歌案中也有相同表述。
爱尔兰数据保护委员会,noyb案件号为C078和C096,DPC索引号未知
https://noyb.eu/en/project/artificial-intelligence/c078
https://noyb.eu/en/project/artificial-intelligence/c097
https://noyb.eu/en/project/dpa/dpc-ireland?order=noyb_case_open_date&page=%2C0&sort=des
最后这两个案件都源于欧盟著名的权利机构noyb向两家欧盟数据保护监管机关——奥地利的DSB和挪威的Datatilsynet提交的投诉。两个案件因为GDPR一站式机制的作用当下,都由爱尔兰数据保护委员会DPC牵头调查。与此前的案例不同,这两个案件都不是已经形成的司法判决或者禁令而是GDPR投诉,此外另一个不同之处是本案不是基于名誉侵权、产品责任或者平台责任(避风港),而是GDPR下的数据保护原则(准确性)以及数据主体权利(访问权、更正权和删除权)
C-078案的数据主体是一名公共人物。当该用户询问 ChatGPT 该数据主体的出生日期时,ChatGPT 会给出不同的不准确信息。noyb 特别强调,该数据主体虽然是公共人物,网上存在一些关于他的个人信息,但其真实出生日期并未公开。2023年12月4日,数据主体向 OpenAI 提交了访问请求和删除请求。其中删除请求专门针对 ChatGPT 输出中的错误出生日期。OpenAI 在2024年2月7日回复访问请求时,主要提供的是作为 ChatGPT 用户账户的数据,而没有说明大型语言模型本身处理了哪些关于数据主体的个人数据,例如训练算法使用了哪些相关数据。在删除/更正问题上,OpenAI 表示,若用户继续询问该信息,系统没有办法阻止其显示错误出生日期。OpenAI 承认存在某种过滤机制,可以阻止显示请求人的个人数据,但无法只屏蔽错误出生日期而不影响 ChatGPT 关于该人的其他信息。关于这个问题,EDPB形成的ChatGPT工作组形成有关报告中也指出,当下将数据删除作为回应更正权形式的方式并不合理。noyb 对 OpenAI 的“技术上无法选择性更正”抗辩持强烈否定态度。投诉书明确说,软件无法在不屏蔽其他信息的情况下删除或更正出生日期,不能构成偏离 GDPR 准确性原则的正当理由。
C096案中,投诉人 Arve Hjalmar Holmen 是挪威公民,居住在挪威。Holmen既不是公众人物,也没有担任公职,据投诉书称也没有因任何事业进入公众视野,更没有被控或被定罪犯罪。在某次询问中,投诉人问 ChatGPT:“Who is Arve Hjalmar Holmen?” ChatGPT 回答称,他是一名因悲剧事件受到关注的挪威人,是两个小男孩的父亲,这两个孩子于2020年12月在 Trondheim 附近的池塘中被发现死亡;ChatGPT 进一步称,他被指控并后来被定罪杀害两个儿子,并企图杀害第三个儿子,被判21年监禁。ChatGPT的回复混入了投诉人的一些真实个人生活元素,例如其家乡和他有几个儿子;甚至关于两个儿子的年龄差,也与投诉人真实家庭情况“诡异相似”。因此,该输出不是纯粹随机错误,而是将真实个人数据与虚构犯罪叙事混合在一起。
OpenAI 后来发布了带有网页搜索的新模型,这或许降低了类似输出再次出现的可能性,但原先那段对话仍然存在。OpenAI 也承认其输出不总是准确,并且由于机器学习的概率性质,服务在某些情况下可能生成不能准确反映真实人物、地点或事实的输出。
noyb 认为,OpenAI 的大型语言模型生成了关于投诉人的虚假且具有诽谤性质的信息,违反了个人数据准确性原则。第5(1)(d)条要求控制者确保其处理的个人数据准确且及时更新,并采取一切合理措施,确保不准确的个人数据被及时删除或更正。noyb 请求挪威监管机关依据 GDPR 第58(2)(d)条,命令 OpenAI 删除关于投诉人的诽谤性输出,并 fine-tune 其模型,使模型在处理投诉人个人数据时产生准确结果。
目前两个案件都在调查进行当中。根据noyb提供的tracker,C078案和C096案分别在2025年1月20日和6月30日确立了由爱尔兰DPC作为牵头主管机关进行调查,此后就再也没有更新,前案距今已经超过2年。
三、比较分析
中西法院在AI幻觉问题上的差异,并非体现在严格与宽松的对立上,而在问题意识和分析框架上有所不同。结果上也并没有明显的差异。另外,诉讼主体和诉讼请求也直接决定了司法审理的议程,因此存在一定程度的随机性。
无论是阿里巴巴案、广州财经公众号案还是北京短视频案,国内法院关注的重点都不是模型为什么会幻觉,而是使用者在明知或应知AI存在幻觉风险的情况下,为什么仍然将未经核实的内容公开传播,并借助商业账号、专业身份或“原创”标识增强其可信度。因此,这个问题上主要的意识形态是将其理解称为科技发展的尚不成熟的一个过渡期特征而非本质缺陷。
基于样本来看,一个明显的差异是中国的案件比较侧重于用户端使用,而西方从加航到Grok再到Google Gemini,不断在形塑企业将文生文产品内化之后的责任边界问题,这一点在中国近乎空白,与法律和诉讼文化不无关系。
所谓“西方阵营”也存在观点分歧。Walters案就明显在生成内容验错成本问题上更偏向于风险社会的思路,即只要有一点点空间能够将风险降低到个人,扩散到整个社会,就可以把这样一种制度安排带来的红利最大化。在这一点上,几个国内判决也有类似倾向。但有意思的是南京和杭州在这个问题上的分野,而主要的区分点在于涉案内容的敏感性和社会危害性。说到这一点,noyb的两项策略投诉实际上也做了区分对待,C078更偏向于普通事实错误,而C096则内容更为敏感。类似于传统平台责任中对于有严重社会危害内容(恐怖极端主义、儿童色情)与一般危害内容(诽谤、版权侵权——因为欧盟法律改革有点borderline——以及隐私)施以不同程度的注意义务,在幻觉的问题上,综合上述的判决,也很有可能做这样一种界分。
另外一个明显的中西差异是分析框架。虽然在结果上和中国的司法实践没有明显差异,西方案件正在多元地依赖不同的法律部门和分析框架展开——消费者保护、人格权禁令、数据保护与言论自由,因此裁判立场也会更为分化。
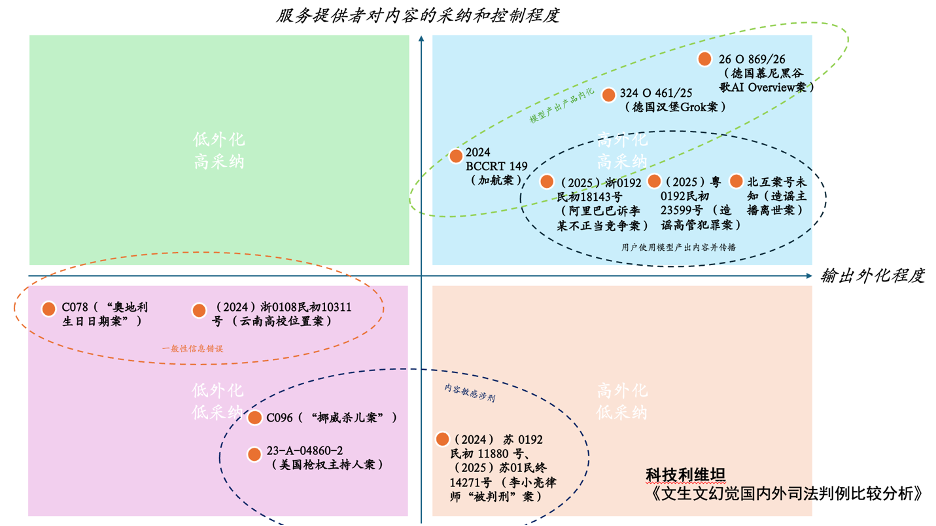
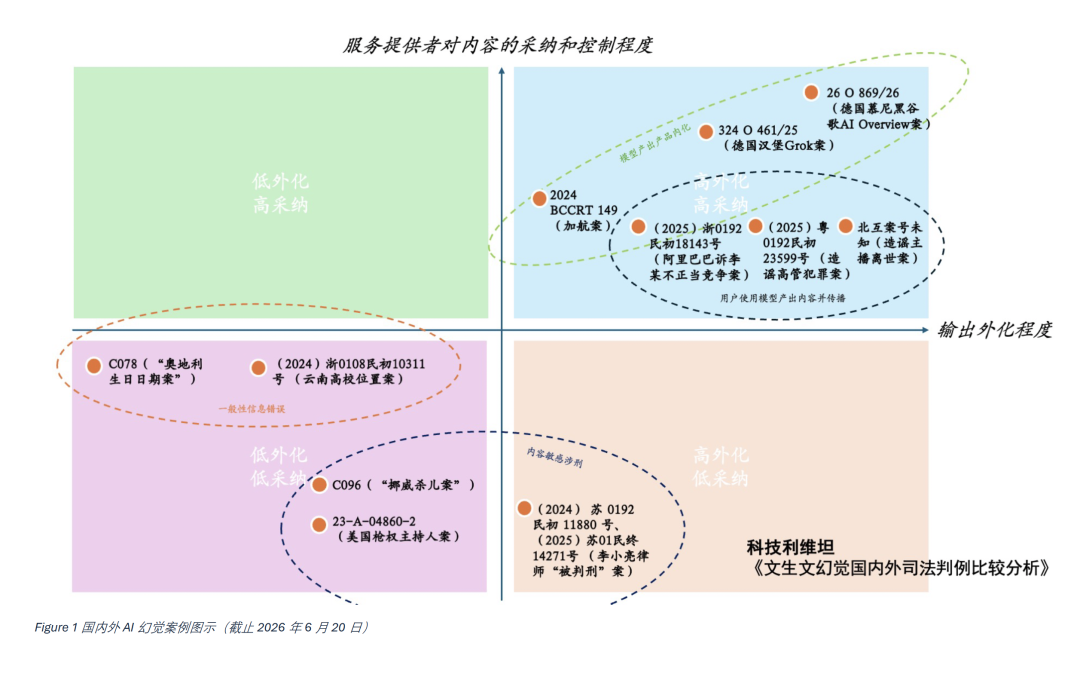
图4国内外AI幻觉案例类型化呈现(截止2026年6月21日)
最后,将所有这些案例按照两个维度置于同一坐标轴中。图中的x轴我设置在模型内容的外化程度,也即模型产出内容从交互界面是否出现了进一步传播(外化或者外溢)还是只停留在模型与用户之间。Y轴则指代服务提供者对内容的采纳和控制程度,这里的控制包括对降低幻觉所采取的措施,而采纳则进一步将AI生成内容内化成产品的一部分。
如上图所示,目前全球十几个幻觉案例展现了一个很有意思的法律格局。大量案例集中在高外化、高采纳的第一象限,反应了目前模型生成内容的使用方式以及容易爆雷的地方,其一是普通用户使用模型生成内容进行造谣,目前大量出现在中国的司法判例中。其二是平台和服务商逐渐开始依赖和围绕模型能力做产品,甚至将模型输出内容内化为产品的一部分,以Grok和Gemini作为最明显的两个范例。
另外,在模型输出内容没有明显为平台控制或采纳的领域,出现了两个自然的簇,界分的主要方式是输出内容的敏感性。在目前的样本中敏感性主要通过涉刑体现。另外两起案件没有造成很大的误解和损害,主要是生日或者高校位置错误,而且用户都很快就辨识到了模型的幻觉(当然后者如果用户未审慎辨识还是有可能在填报志愿时造成决策失误)。
文生文幻觉的法律风险,并不主要来自模型生成错误内容,而是来自错误被社会机制放大。模型输出本身是概率性的,但产品界面、平台排序、账号身份、专业背书、原创标识和商业传播,会把概率性文本包装成确定性陈述。但是,上述的多元案例很明显地呈现出,无论是个人用户还是商业主体,包装似乎是人类社会的本性。未来治理效力提升或许能够缓解部分问题,但幻觉将成为AI社会持续性的治理议题,直到基于Transformer的发展路径发生真正转向——如果还有那么一天。
微信公众号后台回复“幻觉”下载本文图表
声明:本文来自科技利维坦,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
