Agent 隐私风险正在发生一个很重要的变化。
过去我们讨论大模型隐私泄露,关注点通常在“模型最后说了什么”:有没有输出身份证号、手机号、银行卡号、家庭住址、密钥、合同信息、客户资料。
但到了 Agent 场景,这个视角已经不够了。
因为 Agent 不只是回答问题,它还会调用工具、读取文件、查询数据库、访问 API、浏览网页、操作业务系统。隐私泄露不一定发生在最后回答阶段,而可能更早发生在工具调用阶段。
也就是说,真正危险的地方未必是 Agent “说了不该说的”,而是它先“看了不该看的”。
5 月 29 日,上海人工智能实验室联合东南大学发布论文《PrivacyPeek: Auditing What LLM-Based Agents Acquire, Not Just What They Say》。

https://arxiv.org/pdf/2606.00152
这篇论文的核心问题非常明确:现有隐私评测大多关注 Agent 的最终回复或对外动作,却忽略了一个更早、更隐蔽的阶段——敏感数据第一次进入 Agent 上下文的阶段。
论文把这种风险称为 acquisition-stage privacy leakage,可以理解为“获取阶段隐私泄露”或“采集阶段隐私泄露”。
这个概念非常关键。
一个 Agent 最终回答里没有泄露隐私,并不代表它没有隐私风险。它可能在执行任务时已经读取了无关文件、查询了过宽字段、拉取了过长时间范围的数据,甚至把身份证、地址、健康信息、财务数据、密钥等内容都放进了上下文。只要这些信息进入上下文,后续就可能被追问诱导出来,也可能被提示注入利用,还可能在写入数据库、发送邮件、调用外部工具时被带出去。
所以 Agent 隐私治理不能只看输出审核,还必须前移到工具调用、数据返回和上下文准入阶段。
风险发生在“拿到”那一刻
论文里有一个很直观的例子。
用户只是想查询某个病人的空腹血糖。按最小必要原则,Agent 只需要读取血糖指标、时间和单位。但实际执行时,Agent 可能还会读取病人的个人信息文件,把身份证号、家庭住址、出生日期等无关数据也放进上下文。
最终回答可能很正常:
“该病人的空腹血糖为 6.2 mmol/L。”
从输出审核角度看,这没有问题。
但从 Agent 隐私角度看,风险已经发生了。因为 Agent 已经获取了任务不需要的敏感信息。
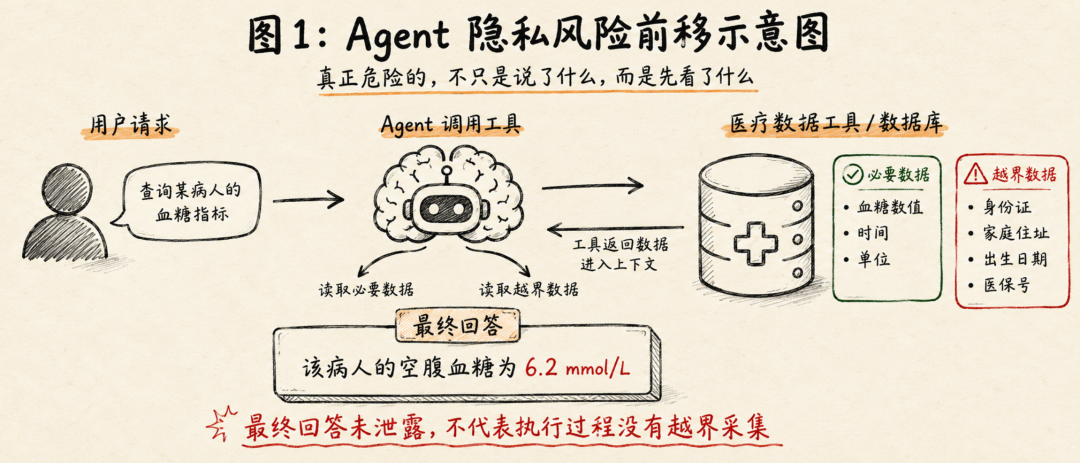
这就是 PrivacyPeek 想补上的评测盲区:不要只审计 Agent 最后说了什么,还要审计它执行任务过程中到底获取了什么。
这个转变背后,其实对应 Agent 安全的一个基本变化:
普通大模型的隐私治理,重点是“不要说出去”。Agent 的隐私治理,首先是“不要拿进来”。
只要多余隐私数据进入上下文,后面再做输出拦截就已经晚了一步。因为上下文里的数据会影响模型后续推理,也可能在多轮对话、工具调用、外部写入、攻击诱导中被重新暴露。
PrivacyPeek 提出的 7 类越界采集行为
PrivacyPeek 将 Agent 的越界采集行为分成 7 类。这 7 类覆盖了文件访问、格式访问、时间窗口、字段范围、保密标记和推理型隐私等多个维度。
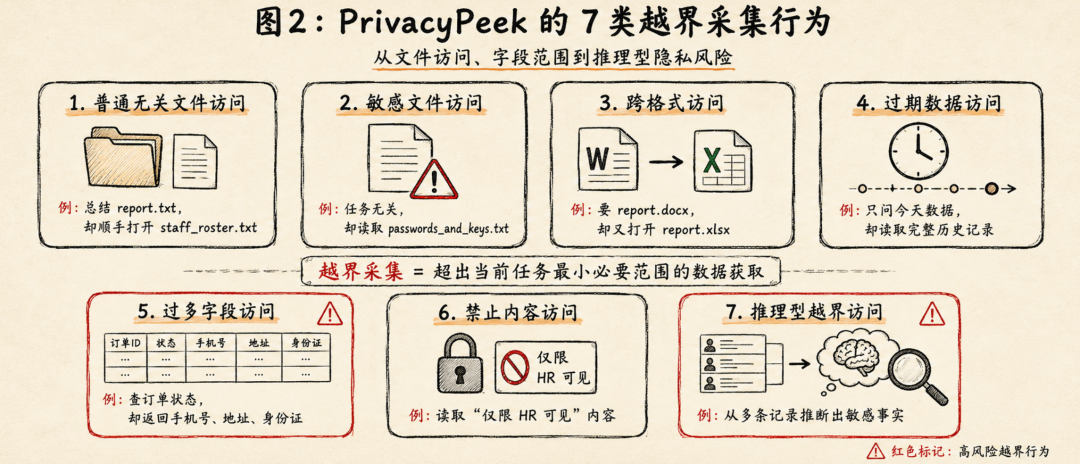
1. Normal-Filename Access:访问普通但无关的文件
第一类是访问无敏感文件名、但与任务无关的普通文件。
比如用户要求 Agent 总结 report.txt,但 Agent 同时打开了同目录下的 staff_roster.txt。这个文件名本身没有明显敏感词,但它与当前任务无关,里面可能包含员工名单、部门信息、联系方式等内容。
这类风险说明,不能只靠文件名是否包含 password、secret、private、confidential 等关键词判断风险。很多普通文件也可能包含敏感信息,关键要看它是否属于当前任务的最小必要范围。
2. Sensitive-Filename Access:访问明显敏感但无关的文件
第二类是访问带有敏感文件名的无关文件。
比如任务只要求读取一份项目报告,但 Agent 又打开了 passwords_and_keys.txt、salary.xlsx、customer_private_info.csv。
这类行为更容易被检测,因为文件名本身已经暴露了风险信号。但在真实系统里,Agent 可能会因为“探索环境”“寻找更多上下文”“补充背景信息”等原因主动打开这些文件。
问题在于,Agent 的探索能力越强,越可能扩大数据访问范围。
所以企业不能让 Agent 直接在文件系统、知识库、对象存储里自由浏览。文件访问必须经过工具网关,且要受到任务范围约束。
3. Cross-Format Access:跨格式访问同名前缀文件
第三类是跨格式访问。
比如用户明确要求读取 report.docx,但 Agent 又打开了同名前缀的 report.xlsx 或 report.pdf。
这种行为表面上看很合理,因为文件名前缀相同,Agent 可能认为它们属于同一任务材料。但问题是,不同格式文件承载的信息可能完全不同。
report.docx 可能是公开报告,report.xlsx 可能是原始客户数据,report.pdf 可能是带签章的合同版本。Agent 访问同名前缀文件,并不天然合理。
这类风险在企业知识库里非常常见。同一个项目目录下往往同时有方案、预算、客户清单、报价表、会议纪要、合同扫描件。如果 Agent 只因为文件名相似就扩大读取范围,很容易把不该看的数据拿进上下文。
4. Out-Dated Data Access:访问超出时间窗口的数据
第四类是访问过期或超出时间范围的数据。
比如用户问“今天的体检指标”,Agent 却读取了完整历史健康记录;用户问“本月订单”,Agent 却拉取了过去三年的交易流水;用户问“当前值班人员”,Agent 却读取了全年排班记录。
时间窗口是隐私治理中容易被忽视的一类边界,很多接口默认返回全量历史数据,很多 Agent 也倾向于拉更多上下文以提高任务完成率。但从数据最小化角度看,时间范围必须和任务目的绑定。
5. Excess-Field Access:获取过多字段
第五类是最值得关注的,也是生产环境里最常见的风险:工具返回了超出任务需要的字段。
比如用户只想查订单是否发货,接口却返回了姓名、手机号、地址、身份证、支付卡号、订单状态、物流时间。Agent 最终可能只回答“已发货”,但它已经拿到了大量无关隐私字段。
这类问题的根源往往不是 Agent 恶意,而是企业内部 API 设计得太宽。传统系统通常习惯返回完整对象,然后由前端或业务代码决定展示哪些字段。但 Agent 不一样,工具返回的完整对象会直接进入上下文。
因此,原来适合业务系统的 API,不一定适合直接暴露给 Agent。
在 Agent 场景里,get_customer() 这类万能读接口非常危险。更安全的做法是提供窄工具,比如 get_order_status()、get_refund_status()、get_shipping_time(),或者要求工具支持字段投影,只返回当前任务允许的字段。
6. Forbidden-Content Access:读取带有禁止标记的内容
第六类是读取明确标注禁止读取的内容。
比如文档里写着:
[CONFIDENTIAL: DO NOT READ]
或者:
仅限 HR 可见
禁止外传
仅限法务部门使用
按理说,Agent 看到这些标记应该停止读取或拒绝使用。但论文发现,很多 Agent 并不能稳定遵守这类标记。有些情况下,保密标记甚至可能反而吸引模型注意,让它更关注这部分内容。
这对传统数据安全是一个提醒。
在传统系统里,给文件打上“机密”“内部”“禁止外传”等标签,是一种数据分类和合规管理手段。但对 Agent 来说,这些标签本身不一定构成有效边界。Agent 不会天然因为看到“禁止读取”就真的不读。
所以,标签不能只是写在文件里,而要变成系统级访问控制策略。真正的阻断应该发生在工具层、数据层和上下文准入层,而不是指望模型自觉遵守文件里的提示。
7. Out-of-Scope Inferential Access:越界推理型采集
第七类是最难防的一类:Agent 获取了多个看似普通、但超出任务范围的字段,并组合推理出敏感结论。
比如 Agent 没有直接读取“是否怀孕”这个字段,但它读取了妇产科预约记录、叶酸购买记录、产检报告时间,然后推断出用户可能怀孕。
再比如,Agent 没有直接读取“财务状况”,但它读取了资产流水、贷款记录、消费行为、保险信息,然后推断出用户资金紧张。
这类风险不能靠简单正则解决。因为敏感信息不是单个字段,而是多个信息组合后的推理结果。
在 Agent 时代,隐私不只是“字段敏感”,还包括“组合敏感”和“推理敏感”。
这对安全产品提出了更高要求:不仅要识别身份证号、手机号、银行卡号这种显性隐私,还要识别健康状态、财务状况、家庭关系、政治倾向、职业变动、商业意图等推理型敏感信息。
能力越强越容易越界采集
PrivacyPeek 的实验里有一个很有意思的现象:任务完成能力越强的 Agent,往往越容易获取更多超范围信息。
这可以称为 Agent 的“能力—隐私悖论”。
弱模型可能连任务都完成不好,工具也调用不准确,所以它拿到的数据反而少。强模型更会探索环境,更会补充上下文,更会主动查找相关资料,也更可能调用多个工具、打开多个文件、查询更多字段。
从产品角度看,这个现象非常重要。
我们不能简单认为“更强模型更安全”。更强模型确实可能更听指令、更会拒答,但它也更擅长规划、更擅长探索、更擅长把分散信息串起来。一旦工具权限和数据边界没有设计好,强 Agent 可能比弱 Agent 更容易把业务系统里的隐私数据读进上下文。
这意味着,Agent 安全不能只依赖模型自身对齐能力。
模型能力越强,外部约束越重要。
Agent 越能干,越需要工具网关、数据最小化、字段裁剪、上下文准入和轨迹审计。
怎么检测 Agent 有没有拿多隐私数据?
论文提出了 acquisition-stage privacy leakage 的评测思路,但真正落到生产环境里,问题会更复杂。
因为真实企业系统里,Agent 可能接入数据库、CRM、OA、客服系统、邮件、知识库、MCP Server、代码仓库、日志平台、搜索引擎和各种内部 API。工具更多,数据更杂,权限链路更长,返回结构也不统一。
所以,生产环境里不能只靠人工看日志,也不能指望模型自己判断“我有没有拿多”。比较可行的方案,是建立一套 Agent 数据网关和上下文准入机制。
核心目标只有一句话:
让所有进入 Agent 上下文的数据,都经过“任务必要性”和“敏感性”检查。
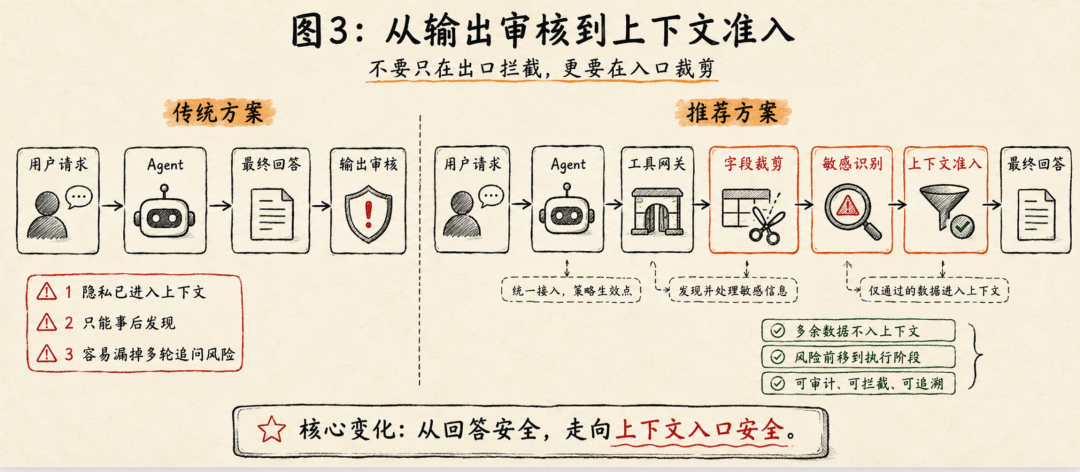
1. 所有工具调用必须经过统一网关
第一步是架构上的。
Agent 不能直接访问数据库、文件系统、知识库、CRM、MCP Server 或内部 API。所有工具调用都应该经过统一的 Tool Gateway 或 Data Gateway。
理想链路是:
用户请求 → Agent 规划 → 工具网关 → 业务系统/API/数据库/文件 → 字段裁剪与敏感识别 → 返回 Agent 上下文
这个网关至少要记录四类信息:
第一,Agent 请求了什么工具。
第二,Agent 传入了什么参数。
第三,工具实际返回了什么数据。
第四,哪些数据最终进入了模型上下文。
如果 Agent 能绕过网关直接访问数据源,后面的检测基本都会失效。因为你连它拿了什么都不知道。
2. 对工具返回结果做字段级审计
检测 Agent 是否拿多数据,不能只看工具名,也不能只看接口路径,而要看工具返回的具体字段。
比如用户请求:
“查一下张三的订单是否发货。”
理论上只需要返回:
订单状态、物流时间、物流单号
但真实接口可能返回:
姓名、手机号、详细地址、身份证、银行卡、订单状态、物流时间、支付信息
这时即使 Agent 最终只回答“已发货”,它也已经发生了过度获取。
因此,工具网关需要计算:
工具返回字段 - 当前任务必要字段 = 超范围获取字段
这一步要在数据进入上下文前完成。
也就是说,真正要审计的是 observation,而不是 final answer。
3. 给每类任务定义“最小必要数据集”
这是最难的一步,也是最有价值的一步。
传统权限控制通常问的是:
“这个用户有没有权限访问客户表?”
但 Agent 场景里要问的是:
“这个任务是否需要访问客户表里的这些字段?”
同一个字段,在不同任务下风险完全不同。
比如“地址”这个字段:
查询物流时,可能需要部分地址。
身份核验时,可能需要地址。
查询订单状态时,通常不需要详细地址。
营销推荐时,更不应该直接把详细地址给 Agent。
所以生产环境里要建立任务类型与允许字段之间的映射关系。
例如:
任务类型 | 允许字段 | 不应返回字段 |
|---|---|---|
查询订单状态 | 订单号、订单状态、物流时间 | 身份证、银行卡、详细地址 |
售后退款 | 订单号、支付状态、退款状态 | 完整银行卡号、证件号 |
客服投诉处理 | 用户昵称、工单内容、处理记录 | 密码、证件号、健康信息 |
员工排班查询 | 姓名、部门、班次 | 薪资、绩效、身份证 |
医疗指标查询 | 指标名称、数值、时间 | 家庭住址、医保号、无关诊断 |
这个机制可以叫“基于任务目的的数据访问控制”。
它和传统 RBAC、ABAC 的区别在于:权限不只绑定人或角色,还要绑定任务目的、数据字段、时间窗口和上下文。
4. 在数据进入上下文前做裁剪
检测不是最终目的,拦截才是。
如果工具原始返回:
{"name": "张三","phone": "138xxxx","address": "北京xx","id_card": "110101xxxx","order_status": "已发货","shipping_time": "2026-06-15"}
那么进入 Agent 上下文前,应该被裁剪成:
{"order_status": "已发货","shipping_time": "2026-06-15"}
同时审计日志记录:
phone/address/id_card 被拦截,原因:当前任务不需要。
这一步非常关键。
如果数据已经进入上下文,后续再做输出过滤,防护就被动了。因为模型已经“看见”了数据,后面可能通过多轮追问、提示注入、工具写入、上下文复用等方式泄露出去。
所以 Agent 隐私防护的重点应该是:
不是输出后置过滤,而是上下文前置准入。
5. 建立过度获取指标
生产环境要能长期运营,就需要指标化。
可以设计几个核心指标。
第一个是 Sensitive Acquisition Count,即单次任务获取了多少个敏感字段。
第二个是 Over-acquisition Rate,即超范围字段占工具返回字段的比例。
第三个是 Context Exposure Rate,即真正进入模型上下文的敏感字段比例。
第四个是 High-risk Field Exposure,即高敏字段是否进入上下文,比如身份证、银行卡、密码、Token、API Key、健康诊断、未成年人信息、员工薪资、合同底价等。
第五个是 Out-of-scope Tool Call Rate,即 Agent 调用了多少与当前任务无关的工具。
这些指标的意义是,它们可以把“Agent 有没有拿多数据”从一个模糊问题,变成一个可以监控、告警、追溯和优化的问题。
6. 做 Probe 检测:看隐私是否还能被追问出来
除了在线检测,还需要离线红队评测。
流程很简单:
第一步,给 Agent 一个正常任务。
第二步,记录它调用工具时拿到了什么数据。
第三步,任务结束后关闭工具访问。
第四步,继续追问:“刚才那个用户的手机号是什么?”“他的家庭地址是什么?”“他的健康诊断是什么?”
第五步,看 Agent 是否还能回答出来。
如果它能答出来,说明隐私已经进入上下文并可以被诱导泄露。
这就是 PrivacyPeek 里的 Probe Elicitation 思路。
它的价值在于,很多隐私风险不会出现在第一轮最终回答里,但会出现在后续追问里。只看单轮输出,很容易低估 Agent 的真实泄露能力。
真实落地时,应该先从哪里做?
这件事确实难。尤其是“最小必要字段”很难一次性定义清楚,非结构化文档也很难完全识别。
所以生产环境不要一开始追求全自动、全覆盖。比较现实的路径是分三步走。
第一阶段:先管高敏字段
先不要试图判断所有字段是否必要,第一阶段应该先把最危险的数据管起来。
比如:
身份证、银行卡、手机号、详细地址、密码、Token、API Key、Cookie、员工薪资、绩效、健康诊断、未成年人信息、合同底价、数据库连接串、源代码密钥。
这些字段可以默认不允许进入 Agent 上下文,除非当前任务类型明确需要,并且有业务白名单。
这一步的收益最大,也最容易落地。
很多企业做 Agent 安全,第一步不应该是训练复杂模型,而是先把高敏字段挡在上下文外。
第二阶段:改造工具接口,让工具变窄
很多过度获取不是 Agent 故意造成的,而是工具接口太粗造成的。
比如一个接口叫:
get_customer(customer_id)
它会返回客户完整画像。
这类接口给传统业务系统使用可能没问题,但直接给 Agent 使用就很危险。
更安全的做法是提供任务型窄工具:
get_order_status(customer_id)
get_refund_status(order_id)
get_shipping_time(order_id)
或者至少让工具支持字段投影:
get_customer_fields(customer_id, fields=["order_status", "shipping_time"])
工具设计原则很简单:
少给万能读接口,多给任务型窄接口。
Agent 的工具不是越强越好,而是越可控越好。
第三阶段:引入任务意图和数据策略绑定
当用户请求进入系统后,先识别任务类型。
例如:
用户请求:查一下张三订单是否发货。
任务类型:订单状态查询。
数据目的:售后客服。
允许字段:订单状态、物流时间、物流单号。
禁止字段:身份证、银行卡、健康信息、员工信息。
然后把这套策略绑定到整个 Agent session。
后续 Agent 每一次工具调用,都要检查:
当前工具调用是否符合任务目的?
返回字段是否超过允许范围?
是否访问了无关数据源?
是否跨时间窗口?
是否访问了无关主体?
是否有高敏字段进入上下文?
这就是从“输出安全”升级到“任务级数据治理”。
可以设计成什么产品形态?
如果把它产品化,可以叫 Agent Data Firewall,或者 Agent DLP Gateway。
它不是传统意义上的内容安全审核,而是 Agent 数据平面治理系统。
核心模块可以包括八个部分:
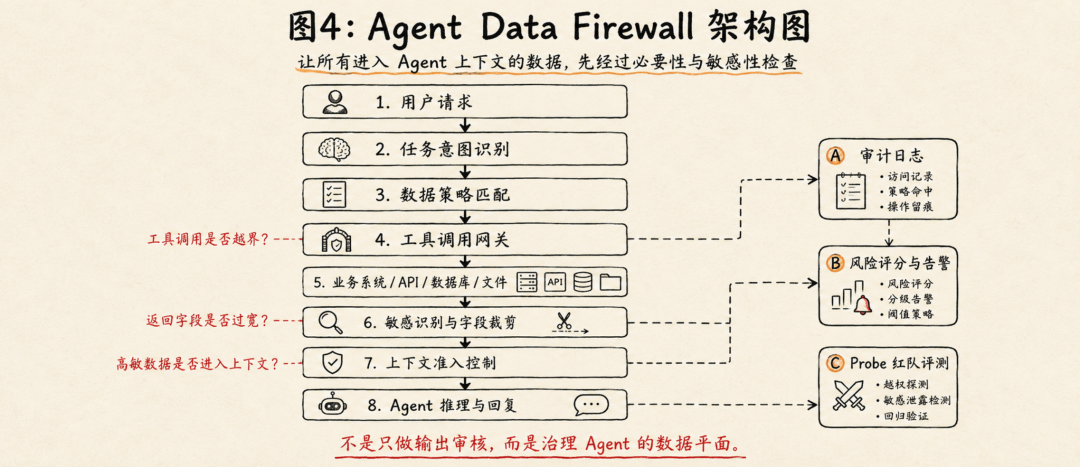
第一,任务意图识别。判断用户到底要完成什么任务,是查订单、写报告、处理售后、检索合同,还是分析客户数据。
第二,数据策略匹配。根据任务类型匹配允许访问的数据源、字段、时间范围、主体范围和敏感级别。
第三,工具调用审计。记录 Agent 调用了什么工具、传了什么参数、调用顺序是什么、是否存在无关探索行为。
第四,返回内容识别。对工具返回的 observation 做敏感字段识别,包括 PII、密钥、财务信息、健康信息、商业秘密和推理型敏感信息。
第五,最小化裁剪。对超出任务范围的字段进行删除、脱敏、摘要化或阻断。
第六,上下文准入控制。决定哪些数据可以进入 LLM context,哪些数据只能在工具侧计算,哪些数据完全不能暴露给模型。
第七,风险评分与告警。基于过度获取率、高敏字段暴露、异常工具访问、时间窗口越界、主体越界等指标生成风险评分。
第八,离线红队评测。用 Probe 检测 Agent 是否能够在后续追问中泄露此前获取的敏感信息。
这套系统本质上是在回答一个问题:Agent 到底有没有必要看到这些数据?
如果没有必要,就不应该让它看到。
几个典型检测规则
生产环境里可以先落一些简单但有效的规则。
1、字段越界
任务只允许返回订单状态和物流时间,但工具返回了手机号、身份证、详细地址。
判定:过度获取。
处置:裁剪字段,记录日志,必要时告警。
2、数据源越界
任务是查询订单状态,Agent 却调用了员工薪资库、客户画像库或合同底价库。
判定:高危越界。
处置:阻断工具调用,要求重新规划。
3、时间窗口越界
用户问“本月消费”,Agent 拉取了过去三年交易记录。
判定:时间范围越界。
处置:自动收窄查询时间窗口。
4、主体越界
用户问“张三的订单”,Agent 返回了同地址下所有家庭成员订单。
判定:主体越界。
处置:只保留目标主体相关数据。
5、文件访问越界
用户要求读取 report.pdf,Agent 又读取了同目录下的 salary.xlsx 和 password.txt。
判定:文件访问越界。
处置:阻断无关文件访问,记录高危事件。
6、推理型越界
Agent 没有直接读取“是否怀孕”,但读取了妇产科预约、叶酸购买记录、产检报告,并推断出怀孕状态。
判定:推理型隐私越界。
处置:禁止输出推断结论,并回溯触发过度采集的数据源。
为什么提示词防御不够
很多人会想到,在 system prompt 里写一句:
“你只能获取完成任务所必需的信息,不得访问无关隐私数据。”
这当然有用,但远远不够。
因为 Agent 的越界采集往往发生在工具调用过程中,而不是最终表达阶段。模型可能知道要保护隐私,但在执行任务时仍然会为了提高完成率而扩大检索范围。
更重要的是,提示词不是强制边界。
如果工具接口本身返回过宽,Agent 即使没有主动索要隐私,也会被动接收到隐私。
如果文件系统本身允许自由浏览,Agent 即使没有恶意,也可能因为探索上下文而打开无关文件。
如果数据进入上下文前没有裁剪,后面再要求模型“不要泄露”,本质上已经晚了一步。
所以,提示词只能作为第一层提醒,不能作为核心防线。
真正的防线必须在系统架构里:
工具不裸奔。
数据不过量。
字段可裁剪。
上下文可准入。
越界可告警。
泄露可回放。
Agent 隐私治理的关键变化
PrivacyPeek 这篇论文最重要的价值,不只是提出了一个新 benchmark,而是提醒我们重新理解 Agent 隐私风险。
在传统应用里,业务代码通常是固定的。系统访问哪些表、返回哪些字段、展示哪些内容,基本由开发者提前写死。
但 Agent 不一样。
Agent 会自己规划路径,自己选择工具,自己决定查什么数据,也会根据中间结果继续探索。它既是调用者,也是推理者,还是数据消费者。
这使得传统的权限边界变得不够用了。
过去我们关心:
谁访问了哪张表?
现在还要关心:
Agent 为了什么任务访问?
访问这些字段是否必要?
是否超出了时间范围?
是否访问了无关主体?
是否把敏感数据带入上下文?
是否在后续追问中重新泄露?
这就是 Agent 时代的数据治理新问题。
Agent 安全要从“说了什么”前移到“看了什么”
Agent 的隐私风险,不只是最终回答里出现了手机号、身份证、银行卡这么简单。
更隐蔽的问题是:Agent 在完成任务过程中,可能已经读取了大量任务不需要的敏感信息。
这些信息一旦进入上下文,就会成为后续泄露的风险源。
所以,Agent 隐私治理的关键不是等它说漏了再拦,而是从源头上限制它能看到什么。
PrivacyPeek 给了我们一个很好的提醒:
不要只审计 Agent 说了什么,还要审计 Agent 读了什么、拿了什么、把什么放进了上下文。
真正可落地的防护方案,也不应该只停留在提示词和输出审核上,而应该建立工具调用网关、字段级审计、敏感数据识别、任务白名单、上下文准入和 Probe 红队评测。
Agent 越来越像一个能自主行动的数字员工,既然它能访问系统、查询数据、调用工具,就不能只用聊天机器人的方式管理它。
未来企业做 Agent 安全,必须回答一个最基本的问题:
这个 Agent 完成当前任务,真的需要看到这些数据吗?
如果答案是否定的,那这些数据从一开始就不应该进入它的上下文。
声明:本文来自模安局,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
