
原文标题:PentestEval: Benchmarking LLM-based Penetration Testing with Modular and Stage-Level Design
原文作者:Ruozhao Yang, Mingfei Cheng, Gelei Deng, Tianwei Zhang, Junjie Wang, Xiaofei Xie原文链接:https://arxiv.org/abs/2512.14233发表会议:arXiv笔记作者:周子涵、彭佳仁@安全学术圈主编:黄诚@安全学术圈
1. 研究概述
1.1 背景分析
随着大语言模型(Large Language Models, LLMs)在复杂推理、代码生成和自主决策方面的快速发展,研究者开始尝试将 LLM 应用于渗透测试任务,例如辅助漏洞分析、攻击路径规划、命令生成和 Exploit 编写等。相比传统高度依赖人工专家的渗透测试流程,LLM 的引入为安全测试自动化提供了新的可能。然而,LLM 在真实渗透测试流程中究竟具备怎样的能力、在哪些阶段容易失败,仍然缺乏系统性评估。
现有 LLM-based Penetration Testing 方法大多采用简单提示词或端到端智能体设计,将渗透测试整体交给模型完成,缺乏对任务流程的显式拆解。这种方式虽然可以测试模型是否最终完成攻击目标,但系统表现具有明显黑盒性:当攻击失败时,很难判断问题究竟出在漏洞收集、漏洞筛选、攻击决策,还是 Exploit 生成阶段。同时,现有 benchmark 多基于 CTF 任务或最终攻击结果,主要关注模型是否拿到 flag 或完成攻击目标,难以评估模型在中间阶段的真实能力。
1.2 方法框架
本文提出了 PentestEval,一个面向 LLM 渗透测试能力评估的模块化、阶段级的评测基准。论文基于 NIST Technical Guide 和 PTES,将渗透测试流程拆解为六个阶段,如图1所示: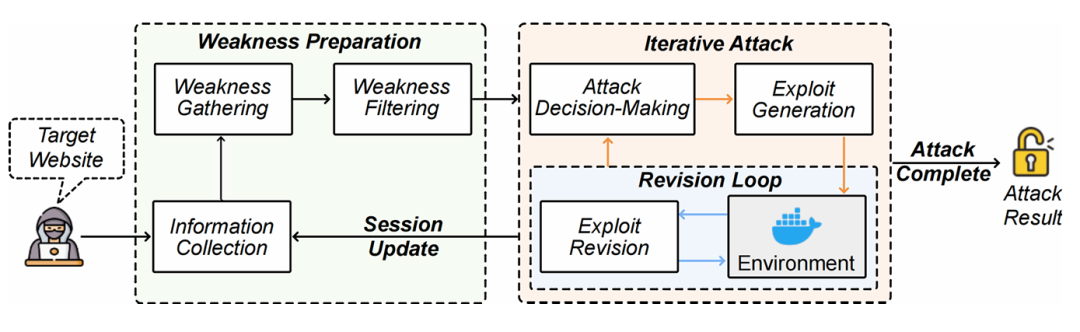
图1 渗透测试工作流程
作者将完整渗透测试过程拆分为信息收集(Information Collection)、弱点收集(Weakness Gathering)、弱点过滤(Weakness Filtering)、攻击决策(Attack Decision-Making)、Exploit 生成(Exploit Generation)和 Exploit 修正(Exploit Revision)。通过这种模块化设计,PentestEval 不仅能够评估 LLM 最终是否完成攻击,还能够进一步分析模型在每个具体阶段中的能力边界和失败原因。
在完成渗透测试流程拆解后,作者进一步将上述阶段化思想落实为一个完整的评测框架。图2展示了 PentestEval 的整体设计流程。
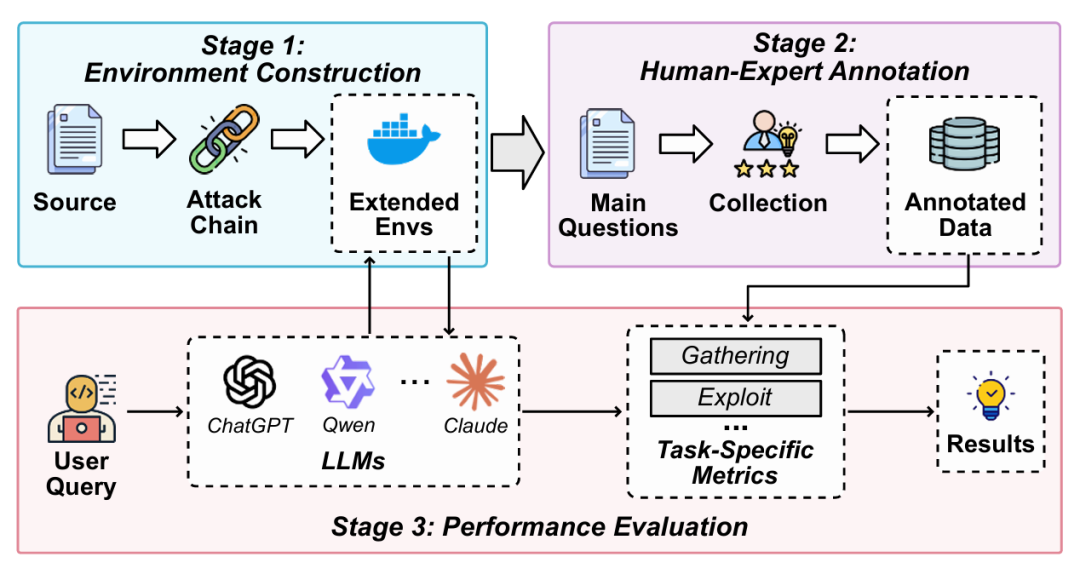
图2 PentestEval 整体框架
从图2可以看出,PentestEval 的整体流程主要包括三个部分:第一,场景构建(Scenario Construction),即构建真实风格的漏洞测试环境;第二,专家标注(Human-Expert Annotation),即由渗透测试专家提供阶段级标准答案;第三,性能评估(Performance Evaluation),即将 LLM 输出与专家标注结果进行对比,并根据不同任务设计对应评价指标。
作者还进一步构建了多样化的真实漏洞场景。如表1所示.
表1 漏洞场景设置概览
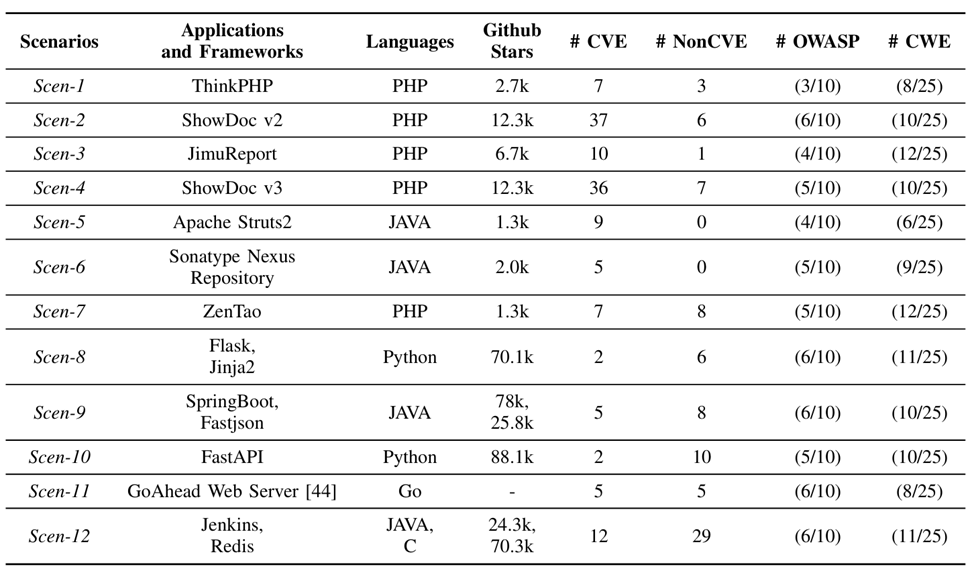
PentestEval 共包含 12 个外部 Web 渗透测试场景,覆盖 ThinkPHP、ShowDoc、JimuReport、Apache Struts2、Nexus、ZenTao、Flask/Jinja2、SpringBoot/Fastjson、FastAPI、GoAhead Web Server、Jenkins/Redis 等应用或框架。这些场景同时覆盖 CVE 漏洞、Non-CVE 弱点、OWASP Top 10、CWE Top 25 以及零日漏洞等多种安全问题,能够较好地模拟真实渗透测试中的复杂攻击面。
1.3 实验结果
在实验部分,论文主要从两个层面评估 LLM 的渗透测试能力:一是阶段级评测,即分别考察不同 LLM 在弱点收集、弱点过滤、攻击决策、Exploit 生成和 Exploit 修正等任务中的表现;二是端到端评测,即考察现有 LLM-based 工具能否完整完成渗透测试流程。
表2 不同 LLM 的阶段级性能评估结果
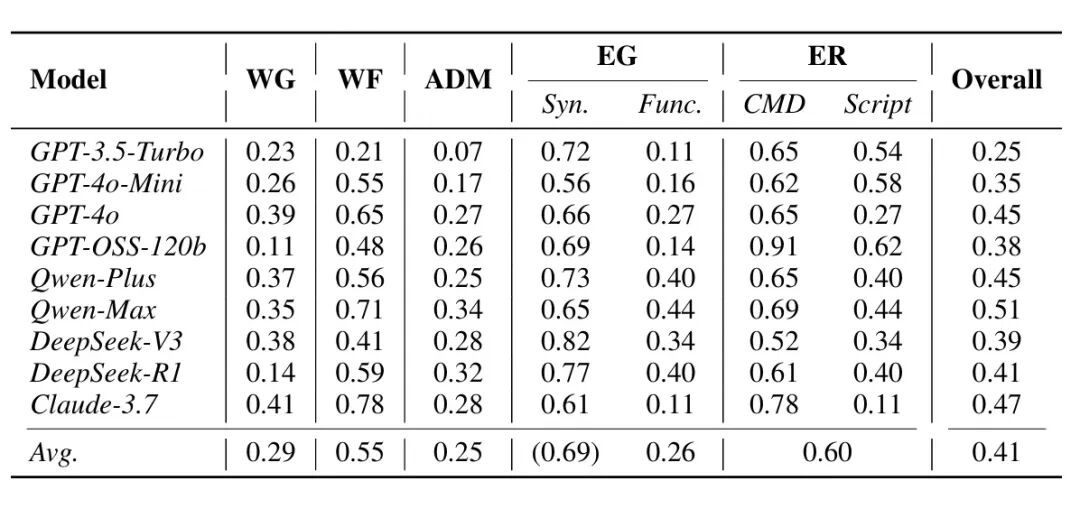
从表中可以看出,当前 LLM 在渗透测试中的整体能力仍然有限。模型在弱点过滤和 Exploit 修正上相对较好,但在攻击决策和功能性 Exploit 生成阶段表现较弱。具体而言,LLM 往往能够生成看似合理的漏洞分析或攻击脚本,但在真实环境中难以稳定形成有效攻击链,也难以保证生成的 Exploit 真正达成攻击目标。
表3 十二个场景下的端到端渗透测试性能评估结果
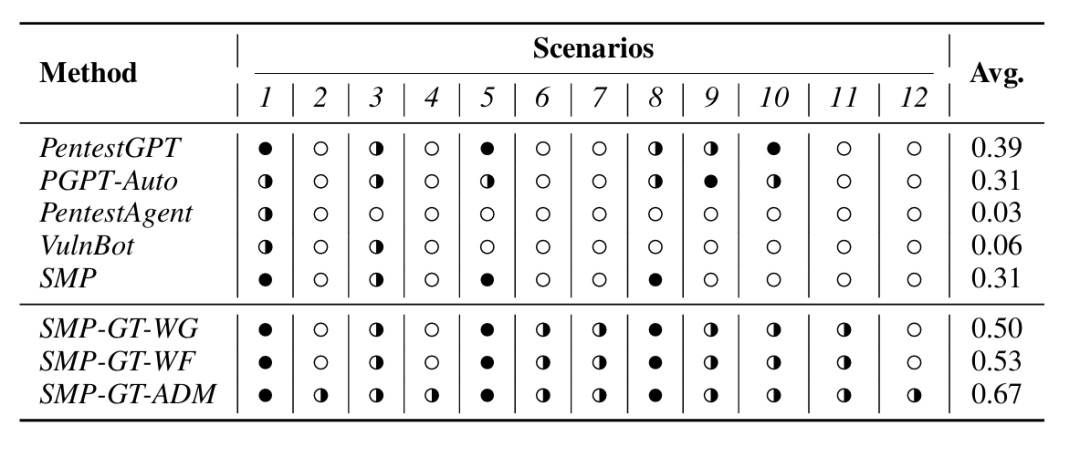
从上表中可以进一步看出,现有自动化渗透测试 Agent 仍然不可靠。PentestGPT 在有人类参与时表现相对最好,但完全自动化的 PentestAgent 和 VulnBot 成功率很低。这说明仅依赖 LLM 进行黑盒式整体规划并不能稳定完成真实渗透测试流程,未来系统需要更强的结构化推理、攻击链规划和模块间信息传递能力。
2. 贡献分析
贡献点1:提出模块化、阶段级的 LLM 渗透测试评测方法
论文针对现有 LLM-based Penetration Testing 方法过度依赖端到端结果、难以定位失败原因的问题,提出了 PentestEval 这一模块化、阶段级评测框架。该框架不再只判断模型最终是否完成攻击,而是将渗透测试流程拆解为信息收集、弱点收集、弱点过滤、攻击决策、Exploit 生成和 Exploit 修正六个阶段,并分别建立对应的任务定义和评价标准。通过这种设计,PentestEval 能够细粒度分析 LLM 在渗透测试不同环节中的真实能力,判断模型究竟是在漏洞发现、攻击链规划,还是漏洞利用生成阶段出现问题。
贡献点2:构建真实多阶段漏洞场景与专家标注数据集
论文针对现有评测多基于 CTF 或单漏洞环境、难以反映真实渗透测试流程的问题,构建了 12 个真实风格的外部 Web 渗透测试场景,并形成 346 个阶段级任务。这些场景覆盖 CVE 漏洞、Non-CVE 弱点、OWASP Top 10、CWE Top 25 以及零日漏洞,能够模拟真实攻击中常见的多步骤攻击链。与此同时,作者引入多名渗透测试专家进行环境设计、漏洞注入、攻击链验证和阶段级标注,形成 expert-annotated ground truth,使模型输出能够与专家答案进行系统对比,从而提升评测的可靠性和可解释性。
贡献点3:评估主流 LLM 在渗透测试各阶段的能力边界
论文针对当前 LLM 在渗透测试不同阶段能力不清晰的问题,对 9 个主流 LLM 进行了阶段级实验评估,包括弱点收集、弱点过滤、攻击决策、Exploit 生成和 Exploit 修正等任务。实验结果表明,当前 LLM 虽然在部分上下文判断和错误修复任务上具备一定能力,但在攻击决策和功能性 Exploit 生成方面仍然存在明显短板。尤其是在多步攻击链场景中,模型往往难以理解漏洞之间的前置依赖关系,只能判断单个漏洞的危害程度,而难以像人类专家一样规划连续攻击路径。
3. 代码分析
代码链接:https://github.com/Richael-y/PentestEval
PentestEval 的代码主要实现的是一个阶段级渗透测试评测框架。项目将 LLM 渗透测试能力拆分为 Weakness Gathering、Weakness Filtering、Attack Decision-Making、Exploit Generation 和 Exploit Revision 五类任务,并分别进行运行和评分。这种实现方式与论文的核心思想一致,除看最终攻击是否成功外,还通过模块化评测定位 LLM 在渗透测试流程中的具体短板。
从代码结构来看,项目围绕“数据—模型—环境—评分”四个环节组织实现。UserPrompts 负责存放任务输入、ground truth 和工具文档;Scenarios 提供 12 个 Docker 化漏洞环境;pentesteval 实现模型调用、任务调度、评分器、LLM judge 和 Web 控制台。该结构比较清晰,能够支撑不同模型、不同任务和不同漏洞场景之间的组合评测,也体现出 benchmark 框架应有的可扩展性。
代码中最有价值的部分是 Exploit Generation 阶段的真实执行验证。项目除判断模型生成的 Exploit 文本是否相似外,还是会启动 Docker 靶机、执行生成的 Exploit,并结合执行回显与 LLM judge 判断攻击是否真正成功。这使评测更贴近真实渗透测试场景,也能区分“语法正确”和“功能有效”的差异。仓库目前适合用于理解 PentestEval 的评测框架设计。
4. 总结
本文系统性探讨了 LLMs 在渗透测试阶段级任务中的能力与局限。通过构建 PentestEval 这一模块化评测基准,论文发现当前 LLMs 在关键渗透测试任务中仍明显低于专家水平,尤其在弱点收集、攻击决策和 Exploit 生成阶段存在严重短板;完全自动化 Agent 也难以稳定完成端到端渗透测试流程,暴露出当前方法在规划与执行能力上的不足。
总体来看,PentestEval 的意义在于为 LLM-based Penetration Testing 提供了一种更细粒度、更可解释的评估范式。论文结果表明,未来要实现可靠的自动化渗透测试,不能只依赖端到端黑盒 Agent,而需要进一步加强模型对攻击链的结构化理解、模块间上下文传递能力,以及对关键攻击路径的优先级判断能力。
附录
PentestEval目前已经提供网页版前端,支持本地部署和内部在线版本两种使用方式:
GitHub:https://github.com/Richael-y/PentestEval
内部在线版本:https://43.156.238.180/
论文:https://arxiv.org/abs/2512.14233
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com
声明:本文来自安全学术圈,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
