基本信息
原文标题:OpenAnt: LLM-Powered Vulnerability Discovery Through Code Decomposition, Adversarial Verification, and Dynamic Testing
原文作者:Nahum Korda, Gadi Evron
作者单位:Knostic
关键词:漏洞挖掘、大语言模型、静态分析、对抗性验证、动态验证、自动化渗透、可达性过滤、Claude Sonnet/Opus
原文链接:https://arxiv.org/pdf/2606.19149
开源代码:https://github.com/knostic/OpenAnt
论文要点
论文简介:在动辄数百万行的真实代码仓库里挖漏洞,一直是安全行业的"老大难"问题。传统的静态应用安全测试(SAST)误报率动不动就突破 40%,开发者深陷"告警疲劳";而模糊测试(Fuzzing)虽然精确,却需要为每一个目标准备繁复的编译、插桩和执行环境,很难规模化推广。大语言模型的出现给这件事打开了一道新缝隙——它能像人一样阅读源码、理解语义、推理控制流和数据流。然而把 LLM 直接丢进百万行的仓库里也并不现实:上下文窗口塞不下、"中间信息丢失"会让推理失真、调用成本一路飙升、推理结果还经常是无法落地的"理论漏洞"。本文介绍的 OpenAnt 就是为了解决这一连串棘手问题而生。它把静态程序分析与 LLM 语义推理串成一条六阶段流水线:先用 AST 解析与可达性过滤把分析面砍掉 97%,再让 Claude Sonnet/Opus 做暴露分类、漏洞检测和对抗性攻击者模拟,最后用 Claude Sonnet 自动生成 Dockerfile、PoC 脚本,跑在沙箱容器里"亲手"验证漏洞可达性。作者在 OpenSSL、WordPress、Flowise、n8n、Rails 等八个真实开源项目上做了完整评估,挖出 190 个候选漏洞、其中 144 个能被自动复现,全程总成本仅 1461.25 美元。
研究目的:作者想要回答一个非常工程化的问题:能不能用 LLM 在真实世界的大型代码仓库里挖到真正可被利用的安全漏洞,而不是停留在"看起来像漏洞"的层面?为此他们要同时解决三件事——其一,是把仓库规模的分析成本控制在可接受的预算内;其二,是要让漏洞结论的可信度高于传统 SAST,能区分出"理论漏洞"和"实际可利用漏洞";其三,是要让发现具有可复现性,让开发者拿到结果就能直接打补丁,而不是再花几天逆向去判断告警是否真实。研究的预期成果是构建一套闭环式(closed-loop)的漏洞挖掘流水线,并通过开源方式让安全行业可以复用与验证。
研究贡献:本文的核心贡献围绕一条思路展开——把漏洞挖掘从"模式匹配"变成"语义推理 + 真实验证"的闭环。第一项贡献是代码分解:作者提出了一套自动化的代码解构方法,把仓库切成函数级的"分析单元",并把跨文件依赖在三层深度内全部内联进单元中,让每个单元都能独立分析;同时只保留那些能从外部入口(HTTP 路由、CLI 参数、WebSocket 等)可达的函数,从而把分析面平均压缩 97%。第二项贡献是对抗性验证:他们没有让模型只回答"这段代码有没有漏洞",而是要求模型扮演一个"只有浏览器访问权限、没有服务器权限、没有管理员凭证"的远程攻击者,去推理具体的利用路径,逐步走完认证、输入校验、平台边界等真实障碍,从而把"看似可疑"的代码进一步过滤。第三项贡献是动态验证:对仍然可信的候选漏洞,OpenAnt 让模型从零生成 Dockerfile、攻击脚本、依赖配置乃至 Docker Compose 多服务环境,在受限沙箱里跑一遍真实利用流程,并要求容器以 JSON 输出 CONFIRMED/NOT_REPRODUCED/BLOCKED 等结论;所有产物用完即丢,确保每次实验都是"从第一性原理出发"而非套用预置模板。这种"语义推理 + 攻击者模拟 + 自动 PoC"的三段式架构,是 OpenAnt 与既往工作最关键的差异。
引言与背景
要理解 OpenAnt 的设计动机,必须先回到 SAST 工具今天所处的尴尬位置。Semgrep、CodeQL、Fortify、Checkmarx 等老牌工具在工业界推行了二十多年,但大规模实证研究反复显示,它们的误报率在不同基准和配置下可以从个位数飙升到 40% 以上。开发者一边被淹没在"告警海"里,一边又得花大量时间去甄别哪些值得修。一项针对开发者的最新调查甚至显示,只有大约 20% 的开发者会主动使用 SAST 工具。规则驱动的根本困境在于,规则永远落后于真实世界中千变万化的漏洞模式:写得太严就误报,写得太松就漏报。再加上规则编写依赖人工,对新兴语言、新框架的支持滞后明显,这条路径已经显得力不从心。
大语言模型这两年在代码理解上的进步,让安全研究者们看到了另一条路。现代代码型 LLM 可以同时理解语法和语义,可以从上下文中推断开发者意图,可以根据自然语言生成程序逻辑。这些能力直接指向了一个更深层的目标:不再是匹配模式,而是真正去"读懂"代码,从而判断它是否会把外部输入引向危险的操作。然而事情没有这么简单。当我们把 LLM 投入到真实仓库里,会马上撞上几个工程难题。第一个是"中间信息丢失"现象——研究表明,模型在处理超长上下文时,对位于序列中段的信息识别能力会显著下降,这让"把整个仓库塞进上下文"几乎不可能成为可行方案。第二个是成本——按 token 计费的 API 在面对百万行级仓库时会产生天文数字的开销。第三个是验证——LLM 的推理结果如果不能闭环验证,就等于把"误报"问题从规则世界搬到了概率世界,并没有解决根本问题。
OpenAnt 的整体设计正是直击这三大痛点。它的核心思想是:不要试图让模型一次性"吃下"整个仓库,而是把仓库变成一组组小而自洽的分析单元;不要让模型只做静态推理,而要让它扮演攻击者,把"理论可疑"转换成"实际可达";不要相信模型自报的结论,而要用沙箱里跑出来的真实 PoC 来定论。这条思路把 LLM、静态分析、动态验证这三种过去各自为政的技术拼成了一条闭环管线,让漏洞挖掘从"识别可疑模式"升级为"生成可执行证据"。
系统架构
OpenAnt 的整体架构是一条由六个阶段串联而成的流水线,前两个阶段完全依靠传统静态分析,不调用 LLM;中间三个阶段交给 LLM 完成语义推理与对抗模拟;最后一个阶段则把推理结论拉到沙箱容器里做真实运行验证。这种"先廉价过滤、再昂贵推理、最后真实验证"的顺序,本质上是一种成本与精度的渐进权衡。
第一阶段是代码解析。OpenAnt 用语言特定的 AST 解析器把仓库里所有函数都抽出来,并记录函数签名、函数体、文件位置和调用关系,从而构造出一张双向调用图。它目前支持 Python、JavaScript/TypeScript、Go、C/C++、Ruby 和 PHP 六种语言:Python 与 Go 直接用原生 AST 库,JS/TS 用 ts-morph,其它语言则交由 tree-sitter 处理。所有解析结果会被归一化为统一的中间表示,方便后续阶段统一处理。
第二阶段是分析单元生成与可达性过滤,这是整条流水线第一次"大砍"。每个分析单元包含三类信息:目标函数本体(Primary code)、最多三层深度的依赖函数(Resolved dependencies,跨文件内联进来)、以及入口元数据(是否来自 HTTP handler、CLI 参数、WebSocket、文件读取等外部输入)。然后系统从入口点出发,对调用图做广度优先遍历,只保留可被外部输入触达的函数,剩下的内部工具函数、测试辅助、管理脚本统统过滤掉。这一刀下去效果惊人:OpenSSL 仓库的 15232 个函数被压缩成 390 个分析单元(约 97% 缩减),Grafana 的 18500 个函数被压缩成 994 个(约 94.6% 缩减)。这一阶段不消耗任何 token,却为后续 LLM 推理节省了海量成本。
第三阶段是暴露分类,OpenAnt 在这里第一次召唤 LLM。对每个可达单元,Claude Sonnet 会在工具辅助下迭代地探索代码库,搜索调用方、读取被调函数实现、追踪调用路径,最终把单元归入四类之一:可被利用(Exploitable)、内部潜在不安全(Vulnerable-internal)、安全控制(Security control)、与安全无关(Neutral)。只有第一类会继续进入下游分析。以 OpenSSL 为例,390 个可达单元在这一阶段又被压缩到 49 个对外暴露单元,进一步缩减 87%。这一阶段是整条流水线中最贵的部分,占据了总成本的近七成,因为它需要"智能体式"地在仓库里反复探索,但作者认为这种昂贵换来了显著的精度提升。
第四阶段是漏洞检测,由 Claude Opus 接手。它使用一份语言无关的提示词,要求模型回答三个问题:这段代码在做什么?输入从哪里来?由此可能产生什么安全风险?模型会输出 vulnerable、bypassable、inconclusive、protected、safe 五种结构化判断之一。设计上最巧妙的地方在于"语言无关"——同一个提示词在 Python、JS、Go、C/C++、Ruby、PHP 仓库间通用,而无需为每种语言专门微调。这一现象本身也佐证了一个观点:安全推理在语义层面具有跨语言的普遍性,本质上都是"追踪外部输入到敏感操作的路径"。
第五阶段是对抗性验证。所有在第四阶段拿到任何判定的单元,无论是 vulnerable 还是 safe,都会被送进来重新审视。模型被要求扮演一个能力受限的远程攻击者:只能通过浏览器交互、没有服务器访问权、没有管理员凭证、不能修改服务器文件。在这种约束下,模型必须为每个候选漏洞构造完整的利用路径,逐步说明每一步是否可行、哪一步会被认证或输入校验拦下。作者特别强调了两项设计要点:一是"多路径探索"——模型必须尝试多条攻击思路才能下"无法利用"的结论,因为单路径推理常常错过可利用条件;二是"受害者要求"——必须有第三方受到影响,不能是"攻击者影响自己的数据"这种无意义场景。每一次尝试都会被记录成结构化文档,最终给出该单元能否实际被利用的结论。
第六阶段是动态验证,整条流水线的"压轴节目"。对仍然可信的候选漏洞,Claude Sonnet 会自动生成 Dockerfile(指定执行环境)、测试脚本(尝试重现利用)、依赖清单,以及在 SSRF 等多服务场景下生成 docker-compose 配置。生成的环境会被放进受限沙箱执行:只读文件系统、512MB 内存上限、单 CPU、禁用提权、120 秒超时。容器必须输出一个 JSON 对象,把结果归入 CONFIRMED、NOT_REPRODUCED、BLOCKED、INCONCLUSIVE、ERROR 五种之一。如果首次执行出现 ERROR,错误信息会反馈给 LLM,让它修正测试代码,最多重试三轮。最关键的一点是"瞬时执行"——所有 PoC 脚本、Docker 镜像、中间文件都在执行后立即销毁,系统从不维护任何漏洞模板库,每一份证据都是为当前漏洞从零生成的。
评估方法
在评估章节,作者花了不少篇幅讨论一个看似老生常谈、实则被很多 LLM 安全研究忽视的问题:基准数据集污染。Juliet 测试集、OWASP Benchmark、各类 CVE 复现样本,这些数据集已经在公开网络上流传了十年甚至更久。它们大概率早已是大模型训练语料的一部分。在这种情况下,一份模型在基准上"考了 95 分"的成绩,到底反映的是真实的漏洞推理能力,还是仅仅在背诵训练集?已有实证研究发现,LLM 在"泄漏样本"上的通过率可以比"未泄漏样本"高出 4.9 倍。更糟糕的是,常用漏洞数据集本身的质量也不高:有研究指出 20% 到 71% 的漏洞标签是错的,17% 到 99% 的样本是重复的;而当研究者用更接近真实分布的 PrimeVul 数据集来评估时,模型在"真实漏洞"上的检测准确率比合成数据集低 10.5 个百分点。Juliet 还有一个老问题,它的文件命名直接暴露漏洞类型(例如 CWE89_SQL_Injection__*),模型完全可以不读代码就猜出答案,这就是所谓的"快捷学习"漏洞。
基于这些考量,作者选择了一种更激进、也更接地气的评估方式:直接在活跃维护的真实开源项目上挖洞。这意味着 OpenAnt 必须在"代码不是为基准而生、漏洞结论需要被独立验证"的条件下证明自己。一旦能在 OpenSSL、WordPress、Rails 这类老牌项目中挖出此前未知的安全问题,就说明系统具备真正的语义推理能力,而非记忆复现。更重要的是,真实仓库会同时考验系统的代码理解、漏洞推理以及区分"理论可疑"与"实际可利用"的能力。作者也老实承认,OpenAnt 主要瞄准的是"外部输入流向危险操作"这类结构性漏洞——注入、路径穿越、SSRF、权限绕过、XSS——对于 CVE 中大量存在的"功能缺失"、"协议解析不一致"或者"跨子系统逻辑错误",它并不擅长,所以基于传统漏洞数据集的召回率指标对它并不公平。
实验评估
OpenAnt 的评估目标涵盖了八个真实开源项目:OpenSSL(C)、Flowise(JavaScript)、eShopOnWeb(PHP)、n8n(TypeScript)、WordPress(PHP)、object-browser(Go)、paperless-ngx(Python)、Rails(Ruby)。这些项目都拥有超过一万颗 GitHub 星,覆盖六门主流语言,并且都具备明显的外部攻击面,例如 HTTP 接口、API 路由、公开服务等。在评估配置上,第三阶段和第六阶段使用 Claude Sonnet 4,第四阶段和第五阶段使用 Claude Opus 4,所有阶段的 temperature 都设为 0 以保证可重复性,并且没有启用系统级缓存。
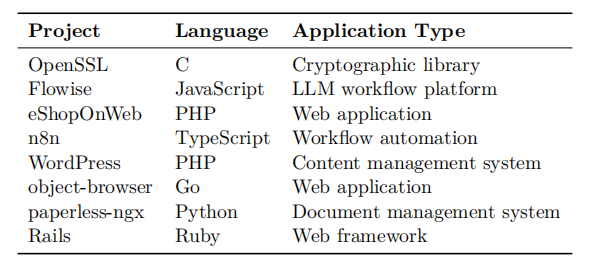
最终的实验结果非常具有说服力。八个仓库总计 64132 个函数,经过可达性过滤后只剩 2281 个单元(96.4% 缩减),暴露分类阶段进一步压缩到 586 个外部可达单元(不到原始仓库的 1%),第四阶段标记出 376 个潜在漏洞,第五阶段的对抗验证确认了 190 个,第六阶段成功复现了其中 144 个,占已确认漏洞的 75.8%。从漏洞类型看,发现覆盖了 30 多种类别,其中数量最多的是 IDOR / 缺失授权(29 个)、Mass Assignment / 权限提升(26 个)、SSRF(25 个)、路径穿越 / Zip Slip(18 个)、XSS / 内容注入(17 个)、SQL/NoSQL 注入(11 个)。从语言/项目看,工作流自动化平台(Flowise、n8n)漏洞密度最高,反映了"允许用户执行任意工作流并对接外部服务"这一架构本身就攻击面庞大;相比之下,成熟框架 Rails 和密码学库 OpenSSL 的确认漏洞数量较少,这也符合人们对成熟项目"已经被反复审计"的认知。
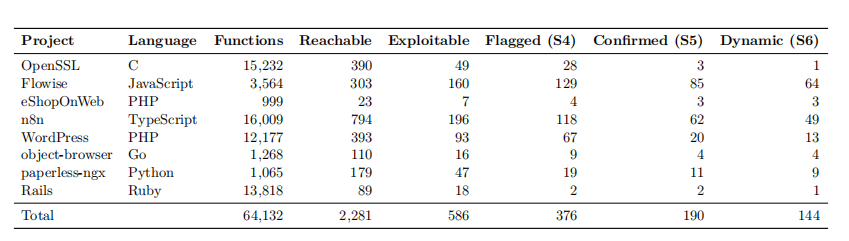
在动态验证维度,作者特别给出了不同漏洞类型的复现率:命令注入 100%、路径穿越 88.9%、认证绕过 83.3%、Mass Assignment 76.9%,这些"输入直接驱动结果"的漏洞天然适合自动 PoC 复现;而竞态条件、跨服务时序依赖类问题则因为环境复杂度高而难以自动复现。在误报率方面,第四阶段标记的 376 个候选中,有 49.5% 在对抗验证阶段被排除,主要原因包括:输入清洗阻断了攻击者控制的数据流、认证屏障无法绕过、漏洞只影响攻击者自己(违反"受害者要求")、平台保护机制(如同源策略、云存储访问控制)。这一过滤机制是 OpenAnt 区别于传统 SAST 的核心利器。在成本层面,全套评估总花费 1461.25 美元,其中暴露分类阶段占 72.9%;作者算了一笔账:如果不做可达性过滤,按第三阶段中位成本计算,把所有函数都跑一遍将花费约 23700 美元。换言之,静态过滤把成本压缩了超过 96%,让"在真实仓库中跑大模型挖洞"在经济上变得可行。
相关工作与讨论
把 OpenAnt 放到学术坐标系里看,它综合了四条研究路径的精华。第一条是基于模式的 SAST:Semgrep、CodeQL 这类工具用人工编写的规则进行语法匹配和数据流分析,胜在快、能集成进 CI,但被规则集的覆盖度严格限制;NIST 的 SATE 系列评测也反复印证了这种范式在不同工具间精度差异巨大。OpenAnt 对它们的差异化在于:检测不再依赖规则,而是基于语义推理;候选结果会被"是否能被利用"反复拷问,把误报压到最低。第二条是 LLM 辅助的代码安全分析:Google 的 Big Sleep 项目证明了 LLM 可以挖出传统测试漏掉的内存安全 bug;Anthropic 的 Claude Code Security、OpenAI 的 Aardvark 也在朝同一方向努力。但这些系统大多停留在"静态推理"层面,OpenAnt 在它们之上加了对抗验证与自动 PoC 的闭环,让分析目标从"识别可疑模式"变成"产出真实证据"。
第三条是 LLM 自治渗透测试:Fang 等人的工作展示了 LLM agent 可以自动完成盲注、认证绕过、提权等任务;PentestGPT 进一步证明了结构化提示与工具辅助能显著提升多步攻击能力。OpenAnt 在对抗验证阶段吸收了这一思路,但关键差异在于它的"攻击"发生在源码层而非部署后的真实系统上,因此可以在上线前完成发现。第四条是模糊测试与自动化漏洞挖掘:AFL、libFuzzer、OSS-Fuzz 通过随机变异输入挖出了大量内存安全漏洞,DARPA 网络挑战赛证明了二进制层面的全自动漏洞挖掘是可行的。OpenAnt 的动态验证服务于一个完全不同的目的:它不做大规模输入空间探索,而是基于前序语义分析生成"针对性 PoC",并且天然跨语言、不依赖具体目标的插桩与编译。把这四条路径汇到一起,OpenAnt 构建出一个新形态的"闭环漏洞挖掘系统"——从源码语义出发,经过攻击者视角检验,最终以可执行证据收尾。
作者也直面地讨论了系统的局限。首先是对 LLM 能力的强依赖:检测与验证质量直接取决于底层模型,那些涉及细微语义条件、领域不变量的漏洞依然棘手。未来工作可能借助专门提示词、领域语料训练,或者把符号执行与 LLM 推理混合。其次是成本与扩展性:尽管多阶段过滤大幅降低开销,但大型仓库分析仍可能花费数百美元,而暴露分类的智能体探索是主要开销来源;改进点可能来自模型效率、缓存策略。第三是动态验证覆盖:自动生成 PoC 在容器里跑得通的漏洞才能被"动态确认",竞态、跨服务时序、需要复杂外部基础设施的漏洞则不易复现;这意味着系统结论是"下界"——某个漏洞没被动态复现,并不等于不存在。第四是缺乏形式化保证:OpenAnt 给出的是经验证据而非数学证明,未来可以与形式化验证方法互补。最后是上下文窗口限制:尽管做了代码分解和依赖修剪,超大函数或深嵌套调用仍可能撞上上下文上限,这与"长上下文中信息丢失"的研究结论一致。
论文结论
总结来看,OpenAnt 给出了一个非常具体的答案:用 LLM 在真实大型仓库里挖漏洞,是可行的、可扩展的、并且可以在合理成本内闭环验证的。论文的最大贡献不在于"用 LLM 做安全分析"这件事本身——这早已是热门方向——而在于把"语义推理"、"对抗模拟"、"动态验证"三件事工程化地串成一条流水线,并通过开源把这条流水线交给整个安全社区。代码分解 + 可达性过滤把分析面砍到 1%,对抗性验证把理论漏洞和实际可利用漏洞清晰区分,动态验证用沙箱里跑出的真实 PoC 终结争论,这三步组成的闭环是 OpenAnt 与既往工作的根本不同。
在八个真实开源项目上的评估也证明了这套架构的实际价值:从 64132 个函数到 144 个可被自动复现的漏洞,全程总花费仅 1461.25 美元,平均每个仓库不到 200 美元——这已经远低于多数企业一次专业渗透测试的预算。更重要的是,这项工作给行业留下了几个值得继续探索的方向。其一是基准评估的反思:当模型规模继续扩大、训练语料继续吞噬公开资源时,传统漏洞基准的可信度会持续下滑,"真实世界漏洞挖掘"是否会成为下一代评测的事实标准?其二是闭环验证的泛化:对抗验证 + 动态 PoC 这套思路能否扩展到内存安全漏洞、逻辑漏洞、协议漏洞等更广阔的范畴?其三是与传统工具的协作:OpenAnt 的可达性过滤本质上是一种"轻量 SAST",那么是否可以把更重的符号执行、抽象解释引入到流水线上游,从而进一步压缩 LLM 阶段的成本?OpenAnt 的开源(Apache 2.0 许可,托管在 github.com/knostic/OpenAnt)让所有这些问题都有了真实的试验场。对于安全研究者来说,它既是一个值得复现的研究原型,也是一份可以直接拿来改造的工程脚手架;对于安全工程师与 DevSecOps 团队来说,它则提供了一种新的可能性:把"挖漏洞 + 写 PoC"这件原本依赖资深红队的工作,变成持续集成里跑一遍流水线的事情。
声明:本文来自安全极客,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
