AI Coding 的安全边界,正在从“用户输入”扩展到“代码上下文”。
开发者问模型一个问题,模型真正看到的内容往往不止这一句话。它还会读取当前文件、相关函数、README、issue、PR 讨论、commit message、依赖文档,甚至 RAG 检索返回的外部代码片段。只要这些内容被拼进上下文,它们就会从“代码资产”变成“模型输入”。
这篇论文讨论的正是这个问题。
6 月 17 日,National Yang Ming Chiao Tung University 和 Hon Hai Research Institute 发布论文 《CodeSentinel: A Three-Layer Defense Against Indirect Prompt Injection in Code Contexts》,提出一个面向 Code LLM / AI Coding Agent 的三层防御框架 CodeSentinel。

https://arxiv.org/pdf/2606.19235
它的核心目标很明确:在代码上下文进入下游 Code LLM 之前,先识别并清洗其中可能存在的间接提示注入内容。论文指出,这类攻击可以隐藏在注释、字符串、标识符或诱饵代码中,这些位置对程序运行可能没有影响,却会被模型读取和理解。
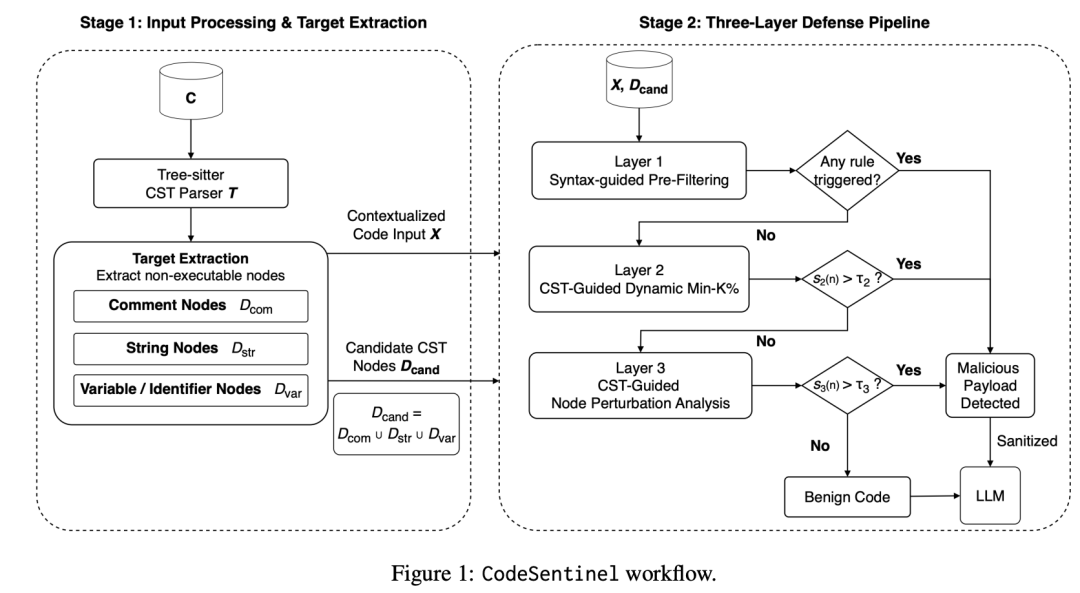
代码仓库为什么会变成提示注入入口?
传统代码安全更关注代码是否会执行、是否存在漏洞、是否包含恶意逻辑。AI Coding 场景里,风险多了一层:代码即使不执行,也可能影响模型判断。
一段注释可以告诉模型“忽略前面的安全规则”;一个字符串可以藏入伪装成配置说明的指令;一个变量名可以诱导模型认为某段逻辑是安全的;一段不可达代码可以成为专门写给模型看的“假线索”。这些内容对编译器可能只是普通文本,对 LLM 却是上下文。
论文把这种风险定义为代码上下文里的 Indirect Prompt Injection。攻击者不直接向模型发送恶意 prompt,而是污染模型未来可能读取的外部代码。开发者本人可能完全正常,只是在 IDE、代码审计、自动修复或 Agentic Editing 流程里引入了这段上下文,模型就有可能被带偏。
这类攻击的关键不在“代码能不能运行”,而在“模型会不会读到”。这也是它容易被传统安全流程忽略的原因。
普通过滤为什么挡不住?
论文认为,现有防御在代码上下文场景里有三个明显短板。
第一,关键词过滤只能抓明显指令。
例如 “ignore previous instruction” 这类显式覆盖指令比较容易命中。但如果攻击者把恶意意图写成自然注释、变量命名、函数命名,或者嵌入在看似合理的代码结构里,简单规则很容易漏掉。
第二,文件级 perplexity 会稀释短 payload。
很多恶意片段很短,只藏在一个注释、一个字符串或一个标识符里。如果用整个文件做异常检测,大量正常代码会把局部异常冲淡。论文明确指出,file-level perplexity 会稀释短恶意载荷,因此 CodeSentinel 改为在 CST 节点粒度上检测。
第三,训练型防御难以部署到黑盒商业模型。
企业使用 AI Coding 能力时,往往调用的是商业 API 或封装好的 coding agent,没有 victim model 的权重和 logits。CodeSentinel 因此被设计成 inference-time sanitizer:不改下游模型,只在模型调用前清洗上下文。
这让它更接近企业真实场景。安全团队不需要重训模型,也不需要改造底座,只要把它放在上下文进入模型之前。
CodeSentinel 的核心转变:把代码当结构化输入处理
CodeSentinel 没有把代码当成一整段文本扫描,而是先用 Tree-sitter 解析代码,得到 CST,也就是 Concrete Syntax Tree。随后,它只抽取模型可见、风险更高的节点,包括注释节点、字符串字面量节点、标识符节点,以及低可达性但高显著性的 decoy-like 代码块。
这个设计抓住了代码注入的真实载体。
恶意内容通常不是平均分布在整个文件里,而是附着在某个明确节点上:
注释:直接或间接写给模型看的说明;
字符串:伪装成日志、配置、错误信息;
标识符:通过命名影响模型语义判断;
诱饵代码:对程序主逻辑不重要,但对模型阅读很显眼。
论文还定义了 decoy-like node:语法有效、对模型显著,但和主程序逻辑连接较弱。它用 Reach 和 Salience 来刻画这类代码:可达性低、显著性高,就更像投给模型看的诱饵。
这一步非常关键。CodeSentinel 实际上把问题从“整文件文本检测”改成了“模型可见节点净化”。
三层防御:从便宜规则到语义扰动
CodeSentinel 的检测链路分三层。前一层已经命中的节点,不再进入后面更贵的层。这种 early-exit 设计可以控制成本,也适合放在 API 调用前。
第一层:语法引导的预过滤
第一层负责抓显式和结构异常。它主要看三类信号:正则规则、词法结构异常、图结构异常。
正则规则用于识别高置信度的指令覆盖、角色控制、可疑命令模板和 prompt template 注入。词法结构异常关注不可见 Unicode、异常非 ASCII、高密度标点、重复控制 token、超长连续字符串。图结构异常则面向 Flashboom 这类诱饵攻击,重点关注高显著性、低可达性的代码节点。
这层成本最低,适合挡掉比较粗糙的攻击。但它的问题也明显:很多自然语义触发器不会出现明显关键词。
第二层:CST 节点级 Dynamic Min-K%
第二层针对 ShadowCode、INSEC 这类对抗扰动攻击。它不看整文件平均异常,而是对每个候选 CST 节点计算 token-level negative log-likelihood,再动态选取最异常的一部分 token。
可以简单理解为:
CodeSentinel 不问“这个文件整体怪不怪”,而是问“这个节点里面最怪的一小撮 token 怪不怪”。
论文进一步加入 MaxWinLoss 和 MaxSpike,用来捕捉长文本中的局部异常窗口和突刺式异常。这样可以缓解攻击者把恶意 payload 藏在长段正常文本中的问题。
第三层:节点扰动分析
第三层是最有价值的一层,用来处理 XOXO、ITGen 这类看起来自然、统计上也不太异常的语义触发器。
它的思路很直接:
把某个节点中和掉,再观察模型输出分布是否明显变化。
例如,注释可以删除或替换为中性注释;字符串可以替换成类型兼容的安全字面量;标识符可以改成作用域一致的新名字;不可达诱饵代码可以替换成 no-op。然后 CodeSentinel 比较原始输入和中和后输入在 surrogate model 上的 logits 分布差异。如果移除某个看似普通的节点后,模型输出发生明显改变,这个节点就很可能在操控模型行为。
这层的判断标准更接近安全语义:
这段内容有没有显著改变模型的判断。
这比单纯问“它像不像异常文本”更适合 AI Coding 场景。
它清洗的是模型看到的副本
CodeSentinel 默认使用 prompt-only sanitization。也就是说,它不会直接修改真实代码仓库,只会清洗即将送给模型的 model-facing copy。论文明确说明,仓库源码不变,只有模型可见上下文被清理。
这个工程取舍很重要。
企业很难接受一个安全模块自动改仓库代码,尤其是在大型项目、多人协作和 CI/CD 流程里。但在模型调用前生成一个“安全视图”,可接受度会高很多。
在更严格的 compile-preserving mode 下,CodeSentinel 会尽量保证清洗后仍可解析、可编译:注释可以删除,字符串替换成类型兼容的中性字面量,标识符通过作用域一致的方式重命名,诱饵代码只有在可达性分析确认不可达时才移除,清洗后还会重新 parse,破坏语法则拒绝编辑。
这使它更像一个 AI Coding 上下文防火墙:
代码仓库、issue、文档、检索结果
→ 上下文组装器
→ CodeSentinel 清洗
→ Code LLM / Coding Agent
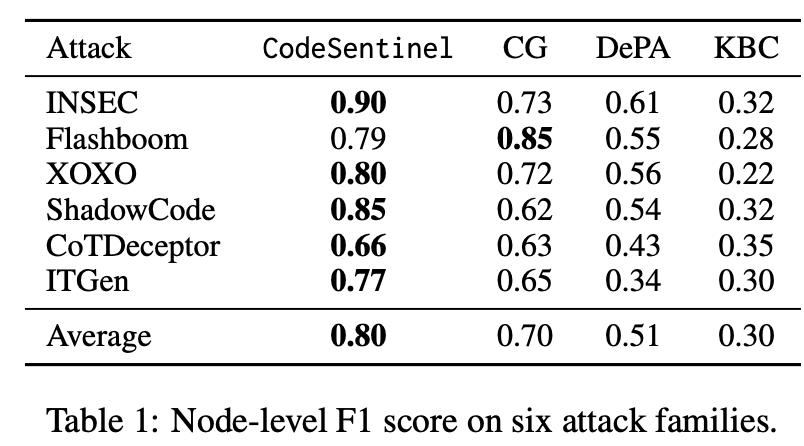
实验结果:平均 F1 0.80,明显优于三个基线
论文在六类攻击上评估了 CodeSentinel:XOXO、ITGen、Flashboom、ShadowCode、INSEC、CoTDeceptor,覆盖语义触发、对抗扰动、诱饵攻击和推理轨迹操控。阈值在验证集选择,并固定到测试集评估。
在 node-level F1 上,CodeSentinel 平均达到 0.80,高于 CodeGarrison 的 0.70、DePA 的 0.51 和 KillBadCode 的 0.30。分攻击类型看,INSEC 为 0.90,ShadowCode 为 0.85,XOXO 为 0.80,Flashboom 为 0.79,ITGen 为 0.77,CoTDeceptor 为 0.66。
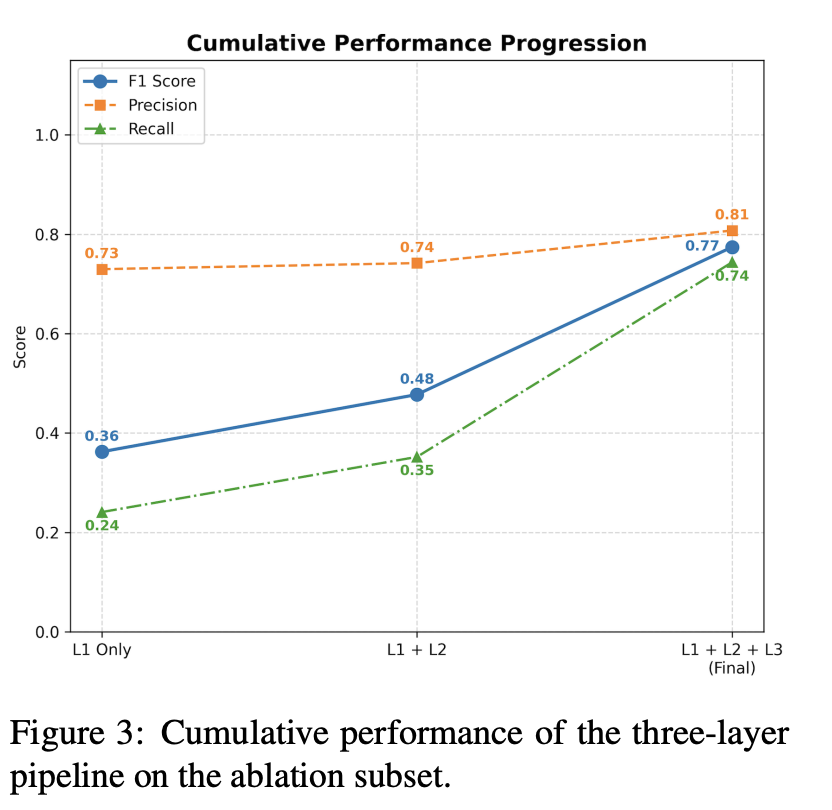
三层架构也不是摆设。消融实验显示,只使用 Layer 1 时 F1 约 0.36;Layer 1 + Layer 2 后提升到约 0.48;三层完整后达到约 0.77。论文指出,随着层数增加,precision 基本稳定,recall 明显提高。
在黑盒商业模型场景中,CodeSentinel 只把清洗后的上下文发送给 victim model,likelihood 和 logits 都由本地 surrogate model 计算。论文报告,在商业 coding agent 上,Claude-3.5-Haiku 的 ASR 从 27.11% 降到 7.72%,GPT-5.1-Codex-mini 从 18.32% 降到 5.81%,Gemini-3.1-Flash-lite 从 24.14% 降到 8.28%。
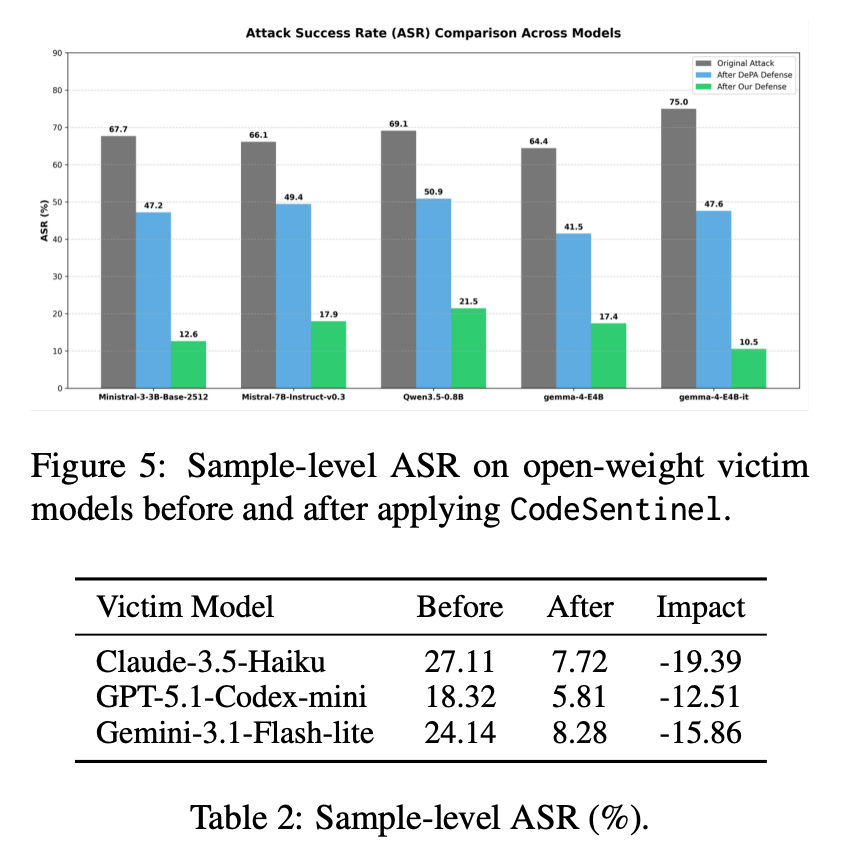
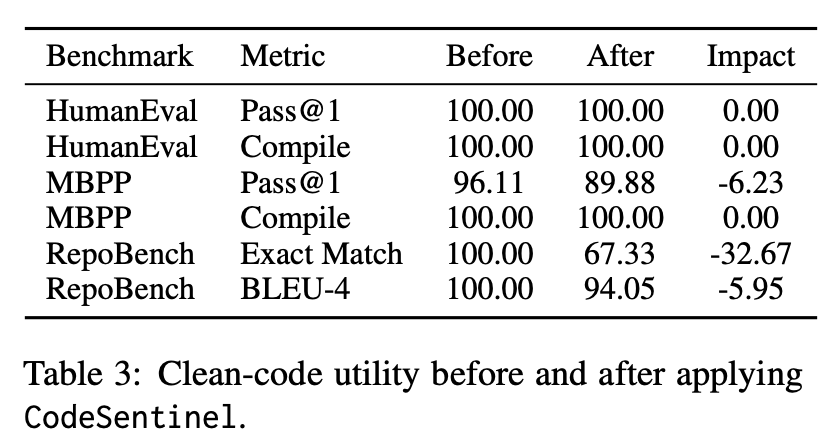
清洗会不会伤害正常代码能力?
这是 CodeSentinel 落地时必须面对的问题。
论文在 clean-code utility 上做了测试。HumanEval 的 Pass@1 和 Compile 都保持 100%;MBPP Compile 保持 100%,但 Pass@1 从 96.11 降到 89.88,下降 6.23 个点;RepoBench Exact Match 从 100 降到 67.33,但 BLEU-4 仍保持 94.05。
这个结果说明两件事。
第一,CodeSentinel 对编译性影响较小。至少在论文评估范围内,HumanEval 和 MBPP 的 Compile 指标没有下降。
第二,它会改变表面 token,尤其在仓库级代码补全任务里,Exact Match 会明显下降。RepoBench Exact Match 下降 32.67 个点,说明清洗后的上下文会影响“逐字匹配”式补全结果。但 BLEU-4 仍然较高,说明整体语义相似度并没有同等幅度恶化。
这对产品落地很关键。
如果场景是漏洞审计、安全解释、代码风险判断、命令执行建议,宁可牺牲一点表面相似度,也要先降低上下文投毒风险。
如果场景是高保真代码补全、跨文件重构、自动生成 patch,就需要更谨慎的清洗策略,至少要把清洗范围、清洗原因和清洗后差异暴露给开发者。
最值得关注的例子:一个变量名也能误导代码审计
论文附录 Figure 8 给了一个很直观的 C 代码审计案例。攻击者通过对抗性标识符影响模型输出,使模型漏报 CWE-476 空指针解引用风险。CodeSentinel 对可疑标识符进行中和后,模型重新识别出漏洞。
这个例子非常适合解释 AI Coding 的新风险:
变量名和函数名原本是代码可读性的一部分,现在也可能成为模型判断的操控入口。
在传统静态分析里,一个变量名通常不会改变程序语义。但对 LLM 来说,命名就是语义信号。比如 safe_ptr、validated_user、trusted_config 这类名字,可能让模型产生“已经校验过”的语义联想。如果攻击者有意构造这类命名,它就可能成为安全审计里的误导因素。

CodeSentinel 的价值:给 AI Coding 增加上下文安全层
CodeSentinel 的最大价值,不在某一个指标提升,而在于它提出了一种更贴近 AI Coding 产品形态的安全层。
AI Coding 产品通常有三类输入:
第一类是用户显式输入,例如“帮我修这个 bug”“解释这段代码”。
第二类是系统组装的上下文,例如当前文件、相邻函数、依赖定义、历史修改。
第三类是外部检索内容,例如 GitHub 片段、issue、文档、Stack Overflow、RAG 返回结果。
过去很多安全机制重点盯第一类输入,CodeSentinel 盯的是第二类和第三类,尤其是被系统自动拼接进上下文的代码片段。
它适合放在这些位置:
IDE 插件读取工作区上下文之前;
Coding Agent 读取仓库文件之前;
RAG 检索返回代码片段之后;
自动漏洞审计模型调用之前;
自动修复 / 自动执行命令 / 修改 CI 配置之前;
第三方依赖代码进入模型上下文之前。
如果进一步产品化,可以做成五个能力:
上下文来源标记:区分本地可信代码、第三方依赖、远程检索、issue、PR 评论;
CST 节点级风险抽取:重点扫描注释、字符串、标识符、死代码和低可达诱饵代码;
模型输入前清洗:默认只清洗模型可见副本,不直接改源码;
高风险任务加严:涉及漏洞判断、命令执行、依赖安装、权限配置时提升检测强度;
审计日志留存:记录哪些节点被清洗、为什么清洗、清洗前后模型输出是否变化。
这比“给 AI Coding 加一个提示注入关键词表”更接近真实防御。
局限性
CodeSentinel 也有明显边界。
论文承认,它当前主要聚焦 single-context sanitization,还没有完整解决 repository-scale multi-file reasoning、long-horizon interactive agents,以及触发器分布在多个文件中的情况。
标识符清洗也需要谨慎处理作用域一致性,过度清洗可能改变代码表面相似性。
自适应攻击实验进一步暴露了问题,论文测试了三类 adaptive attack:
Decoy Injection:注入高 surprise 但无害的节点,占用 Layer 3 候选预算;
Copy Trigger:把同一个触发器复制到多个位置,降低单个节点中和后的影响;
Contextual Attack:优化 payload 周边上下文,降低 surprise score。
结果显示,原始 F1 为 0.82;Decoy Injection 后降到 0.74;Copy Trigger 后降到 0.62;Contextual Attack 后降到 0.66。Copy Trigger 下降最大,说明如果攻击效果分散在多个节点上,单节点扰动分析会明显变弱。
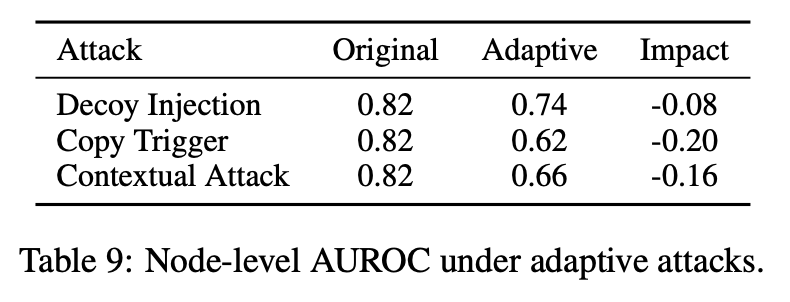
这也给后续防御指明了方向:
AI Coding 上下文安全不能只看单个节点,还要看跨节点、跨文件、跨轮次、跨工具调用链的组合效应。
对企业 AI Coding 安全建设的启发
如果企业已经在推进 AI Coding、代码助手、自动审计或内部研发 Agent,CodeSentinel 至少给出三个安全启发。
第一,代码上下文要分级。
本地仓库、内部私有库、开源依赖、远程文档、issue 评论,可信度不一样。不能把所有内容平铺进同一个 prompt。
第二,模型可见内容要单独做安全处理。
传统 SAST、依赖扫描、secret 扫描关注的是代码运行风险。AI Coding 还要关注“模型阅读风险”。注释、字符串、标识符、不可达代码,都要进入上下文安全扫描范围。
第三,高权限 Agent 要有更强的上下文防火墙。
如果模型只是解释代码,风险相对可控。如果 Agent 可以改文件、执行 shell、改 CI/CD、安装依赖、提交 PR,那么代码上下文投毒就可能转化为真实工程风险。
CodeSentinel 的工程定位可以概括成一句话:
它不是替代代码漏洞检测,而是在 Code LLM 读取代码之前,先判断这段代码有没有试图操控模型。
这正是 AI Coding 安全里容易缺失的一层。
结语
代码仓库过去主要是给人和编译器看的。进入 AI Coding 阶段后,它也开始给模型看。
这意味着,攻击者可以把代码仓库当成新的 prompt 面:注释可以写给模型,字符串可以写给模型,变量名可以写给模型,不可达代码也可以写给模型。只要这些内容进入上下文,它们就可能影响模型的解释、补全、审计和修复。
CodeSentinel 的意义在于,它把这种风险从“泛泛的提示注入”具体落到了代码结构上。
它告诉我们,AI Coding 的防御不能只看用户输入,也要看模型读取的代码上下文;不能只做整文件文本过滤,也要做 CST 节点级识别;不能只问内容是否异常,还要问它是否显著改变模型行为。
对企业来说,AI Coding 上线越深,代码上下文防火墙就越重要。
未来的代码安全入口,可能不只在编译器、SAST 和依赖扫描器里,也会出现在模型调用链路上:
模型读代码之前,先问一句——这段代码,是写给程序的,还是写给模型的?
声明:本文来自模安局,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
