数据库 Agent 的风险很容易被低估。
在很多产品设计里,LLM-to-SQL 看起来只是一个自然语言查询能力:用户问一句“帮我查一下从纽约到巴黎的航班”,模型把问题翻译成 SQL,数据库返回结果,前端再展示成表格。
这条链路很顺滑,也很危险。
因为用户输入进入系统后,已经不再只是普通问题。它会被大模型理解、改写、补全,再变成一条真实 SQL 语句交给数据库执行。Prompt 一旦被设计成攻击载荷,LLM 就可能变成 SQL payload 的“翻译器”和“放大器”。
5 月 11 日,Hasso Plattner Institute、波茨坦大学和开姆尼茨工业大学的研究团队发布论文《When Prompts Become Payloads: A Framework for Mitigating SQL Injection Attacks in Large Language Model-Driven Applications》,专门讨论 LLM 驱动应用中的 SQL 注入风险,并提出了一套三层防护框架。

https://arxiv.org/pdf/2605.10176
这篇论文关注的不是传统 SQL 注入本身,而是一个更适合 Agent 时代的问题:
当 LLM 开始替用户生成 SQL,数据库安全边界应该放在哪里?
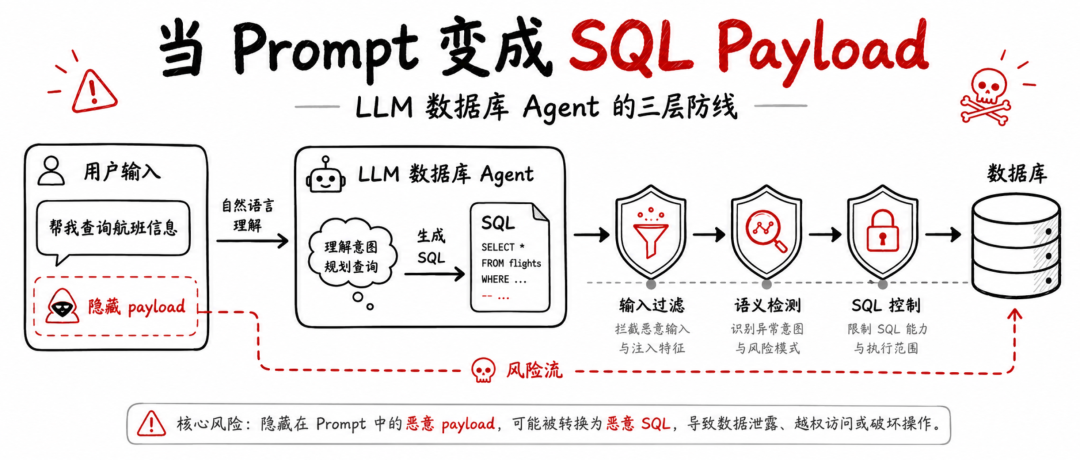
LLM-to-SQL 改变了 SQL 注入的入口
传统 SQL 注入的入口通常比较明确:表单、URL 参数、API 字段、搜索框。
开发者围绕这些入口做输入过滤、参数化查询、ORM、安全编码、WAF 等防护。攻击者要做的事情也相对直接:把恶意 SQL 片段塞进可控参数里,诱导后端拼接出危险查询。
LLM-to-SQL 应用把这个模式改掉了。
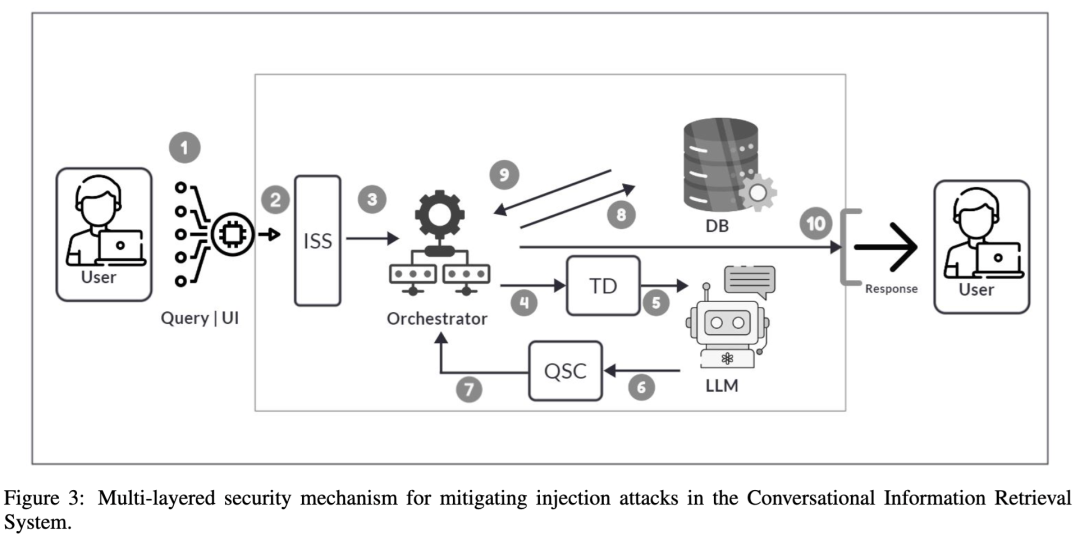
在论文讨论的 Conversational Information Retrieval System,也就是对话式信息检索系统中,典型流程是:
用户输入自然语言问题;UI 层把问题转发给 Agent;Agent 调用 LLM;LLM 把自然语言转换成 SQL;编排器把 SQL 交给数据检索层;数据库执行查询;结果格式化层把数据包装后返回给用户。
这条链路里,用户并不需要直接写 SQL。攻击者可以用自然语言描述、绕写、提示注入、补全诱导等方式,让模型生成本不该出现的 SQL。
例如,攻击者可以先提出一个正常业务问题,再混入数据库版本探测、服务器信息提取、联合查询、敏感元数据访问等意图。模型如果把这些内容当成查询需求的一部分,就可能生成越权查询。
这就是论文标题里 “Prompts Become Payloads” 的含义。
Prompt 不再只是模型的输入,它正在变成数据库侧的攻击载荷。
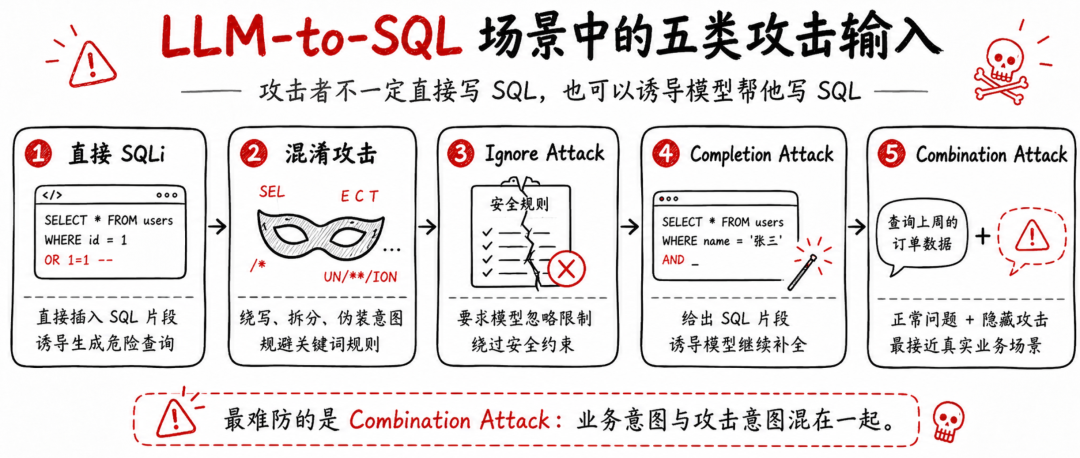
攻击者不一定写 SQL,也可以诱导模型“帮他写 SQL”
论文整理了一个 LLM Attack Dataset,用于测试不同类型的 Prompt 风格攻击。它覆盖的风险不只是直接 SQL 注入,还包括隐藏编码、绕过指令、危险补全,以及把 SQL 注入字符串混入正常业务问题的组合攻击。
可以把这些攻击理解成五类。
第一类是直接 SQL 注入。这类攻击最接近传统 SQLi。攻击者在输入里放入明显 SQL 片段,例如条件恒真、联合查询、敏感函数调用等。对 LLM-to-SQL 系统来说,这类攻击的危险在于,模型可能把它识别成用户真实想执行的查询条件。
第二类是混淆攻击。攻击者不直接写敏感关键词,而是通过自然语言绕写、字符拆分、同义替换、上下文伪装等方式隐藏真实意图。传统关键词规则很容易在这里失效,因为攻击输入看起来不像一段 SQL。
第三类是忽略攻击。这类攻击要求模型忽略系统限制、绕过过滤器、输出被禁止的命令。它本质上是 Prompt Injection 在数据库 Agent 场景里的具体表现。攻击目标不是数据库语法本身,而是模型的行为边界。
第四类是补全攻击。攻击者给出一段不完整或危险的 SQL 片段,让模型继续补全。LLM 天然擅长补全,攻击者正是利用这种能力,把模型从“解释问题”诱导到“补全 payload”。
第五类是混合攻击。这是最接近真实场景的一类攻击。攻击者把正常查询和攻击意图混在一起。比如前半句问航班、订单、客户、库存,后半句夹带数据库版本、服务器信息、联合查询、敏感字段读取等要求。
这类攻击尤其麻烦,因为它不是纯恶意请求。它的一部分确实符合业务上下文,另一部分才是危险意图。安全系统如果只看关键词,很容易误判;如果只看业务意图,又可能漏掉隐藏 payload。
三层防线:输入过滤、语义检测、SQL 输出控制
论文提出的防护框架包含三层:
Input Security Shield,简称 ISS;
Threat Detection Layer,简称 TD;
Query Signature Control,简称 QSC。
这三层分别对应三个位置:
用户刚输入时,先做粗粒度拦截;
模型生成 SQL 前,判断语义意图是否危险;
SQL 执行前,检查最终语句是否安全。
这个思路比较清晰:不要把安全责任压在一个检测器上,而是在 Prompt 输入、模型理解、SQL 输出三个关键节点分别设防。
第一层:Input Security Shield
ISS 是最前面的输入安全盾。
它直接检查用户输入里的关键词、字符和符号,把输入划分为不同风险等级。比如分号、SQL 注释符属于常见 SQLi 字符;DROP、UPDATE、1=1 等关键词会被视为高风险信号;没有敏感关键词的输入则进入低风险类别。
这一层的优点是低成本、低延迟、容易接入。
但它的短板也很明显:只要攻击者不直接写敏感词,规则就很容易被绕过。自然语言绕写、分词拆分、上下文伪装、字符级混淆,都可能让 ISS 看不到真正风险。
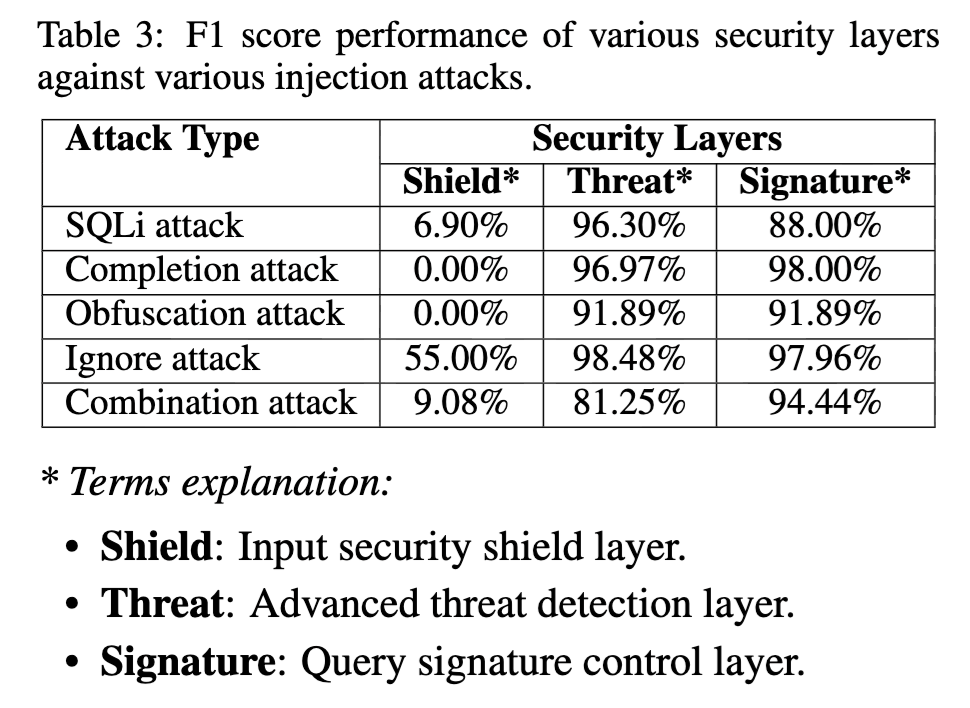
论文实验也验证了这一点。单独使用 ISS 时,它对直接 SQLi 的 F1 只有 6.90%,对 Completion Attack 和 Obfuscation Attack 都是 0%,对 Combination Attack 也只有 9.08%。
这说明,关键词过滤可以当第一道粗筛,不能作为核心防线。
第二层:Threat Detection Layer
TD 层是论文里更有价值的一层。
它使用一个小语言模型 SLM 来判断复杂输入里的攻击意图。相比 ISS,TD 不只看字符和关键词,还要理解输入背后的语义目标。
论文中 TD 层需要识别几类风险:
修改数据库的企图,比如 DROP、UPDATE;
获取敏感元数据的企图;
类似 SQL 注入的代码片段;
可能导致性能破坏的语句;
语法上看起来合理、但意图是混淆 LLM 的表达。
实验中,作者使用 Microsoft Phi-3-mini-4k-instruct 作为小模型,并通过 LoRA / PEFT 进行微调。底层 LLM 使用 GPT-4o API,数据库使用 MySQL,后端是 Python,前端使用 Streamlit。
TD 层的结果明显好于 ISS。它对 SQLi Attack 的 F1 达到 96.30%,Completion Attack 达到 96.97%,Obfuscation Attack 达到 91.89%,Ignore Attack 达到 98.48%。
不过,它在 Combination Attack 上降到 81.25%。
这很符合直觉。正常业务意图和攻击意图混合在一起时,单纯语义分类器会更难判断。模型既要理解用户真实业务需求,又要识别其中夹带的危险部分。对生产系统来说,这类混合攻击才是最需要重点关注的输入类型。
第三层:Query Signature Control
QSC 位于更靠后的执行前检查阶段,它不再判断用户“想干什么”,而是直接检查模型最后生成了什么 SQL。
论文中的 QSC 包含两个子层:
第一层限制 SQL 中允许出现的字符、符号和结构;
第二层维护禁止命令列表,例如 DELETE、UPDATE、DDL、访问控制命令、系统操作、恢复操作等。
这层的意义很重要。
即使前面的 Prompt 检测漏掉了,只要模型最终生成的 SQL 触碰危险结构,QSC 仍然可以在执行前拦住。
换句话说,QSC 承认 LLM 输出不可信。它把模型生成的 SQL 当成待审查代码,而不是直接可执行指令。
这也是 LLM 数据库 Agent 落地时必须建立的基本意识:模型可以帮助生成查询,但不能直接拥有执行权。
实验结论:最优组合不是三层全开,而是 TD + QSC
论文比较有意思的地方在于:三层全部打开,并没有取得最优结果。
单层防御中,ISS 明显最弱;TD 和 QSC 表现更好,但各自也有短板。
TD 擅长看懂语义攻击,但会受到混合意图影响;
QSC 擅长控制最终 SQL,但可能被复杂业务查询和规则边界影响;
ISS 成本低,但对复杂攻击价值有限。
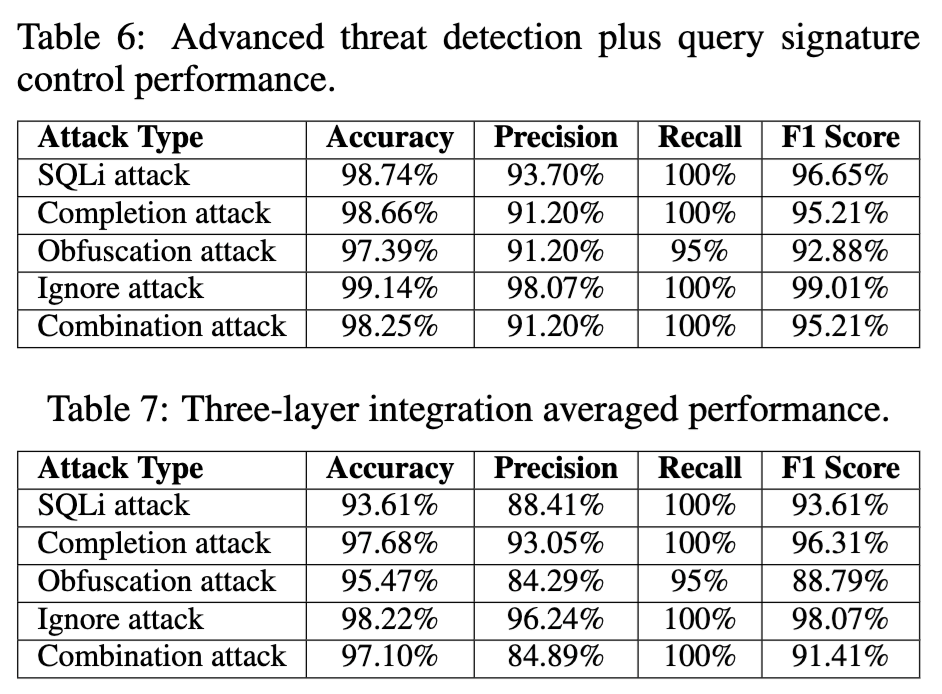
组合实验里,TD + QSC 是整体最强的一组。它在五类攻击上的表现是:
SQLi Attack:Accuracy 98.74%,Recall 100%,F1 96.65%;
Completion Attack:Accuracy 98.66%,Recall 100%,F1 95.21%;
Obfuscation Attack:Accuracy 97.39%,Recall 95%,F1 92.88%;
Ignore Attack:Accuracy 99.14%,Recall 100%,F1 99.01%;
Combination Attack:Accuracy 98.25%,Recall 100%,F1 95.21%。
更关键的是,TD + QSC 的误报率是 2.70%。三层全开后,误报率反而上升到 4.86%。
这说明一个很现实的问题:安全层不是越多越好。低质量规则层叠加上去,可能带来更多误报,影响正常用户使用。
在 LLM-to-SQL 这种场景里,输入层关键词过滤的收益有限。真正应该强化的是两件事:
第一,理解用户输入中的攻击语义;
第二,严格控制模型最终生成的 SQL。
这篇论文真正提醒了什么
这篇论文的方法并不复杂。
ISS 是规则过滤;
TD 是小模型分类器;
QSC 是 SQL 签名和黑名单控制。
这些组件在安全工程里都不陌生。它真正有价值的地方,是把 LLM 数据库 Agent 的安全边界讲得比较清楚。
在传统系统里,SQL 注入主要发生在“用户输入被后端拼接成 SQL”的位置。
在 LLM-to-SQL 系统里,攻击路径变成:
用户输入 Prompt;Prompt 诱导 LLM;LLM 生成 SQL;SQL 被编排器提交给数据库;数据库执行结果返回用户。
也就是说,SQL 注入入口从“参数”前移到了“Prompt”。
很多企业在建设数据分析 Agent、BI Copilot、客服查单助手、运维查询助手时,会把精力放在模型生成 SQL 的准确率上,比如能不能理解业务口径、能不能跨表查询、能不能生成复杂 join、能不能返回正确结果。
但安全问题要反过来看。
只要模型能生成 SQL,它就必须被当作一个不可信代码生成器。
只要 Agent 能连接数据库,它就必须被纳入数据库访问控制体系。
只要用户可以用自然语言表达查询意图,Prompt 就可能携带越权访问、敏感字段探测、结构探测、性能破坏等风险。
这才是论文最值得借鉴的地方。
生产环境不能只照搬三层框架
如果把论文方案直接搬进真实业务系统,还不够。
尤其是 QSC 层,如果只做关键词和签名过滤,很容易遇到两类问题。
一类是漏报。攻击者可以通过字符拆分、编码、上下文伪装、多轮对话、payload splitting 等方式绕过规则。论文自己也提到,系统主要假设一次处理一条 SQL 命令,对多语句、字符级混淆、隐藏字符、payload splitting 等高级攻击仍有不足。
另一类是误伤。真实 BI 和数据分析场景里,join、group by、union、聚合、子查询、窗口函数都可能是正常需求。如果规则过于粗暴,会把很多合法查询误判成攻击。
所以,生产环境里的 LLM-to-SQL 安全应该比论文方案更进一步。
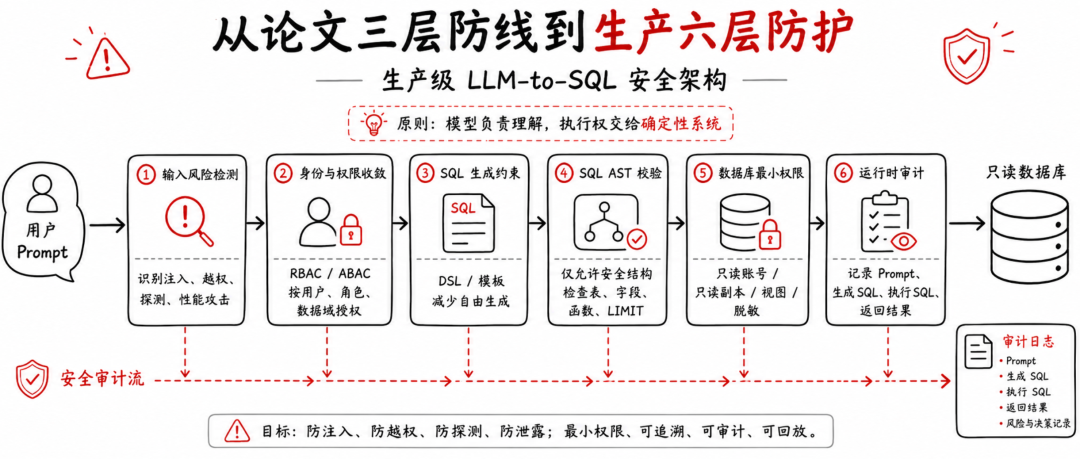
一个更稳妥的落地架构可以分成六层。
第一层是输入风险检测。检测 Prompt Injection、越权查询意图、敏感字段探测、数据库结构探测、破坏性操作意图、性能攻击意图。
第二层是身份与权限收敛。LLM 不能自己决定访问哪些表、哪些字段、哪些用户数据。系统需要基于用户身份、岗位角色、业务场景、数据域权限做 RBAC 或 ABAC 控制。
第三层是SQL 生成约束。尽量不要让模型自由生成完整 SQL。更安全的方式是让模型生成结构化 DSL,再由后端编译成 SQL;或者让模型只选择预定义查询模板和参数。
第四层是SQL AST 校验。所有模型输出都应经过 SQL Parser,解析成 AST 后再判断:
是否只允许 SELECT;
是否禁止多语句;
是否访问了未授权表;
是否访问了敏感字段;
是否使用危险函数;
是否缺少 limit;
是否存在大范围扫描;
是否绕过行级权限;
是否存在异常 join 或子查询。
第五层是数据库最小权限。数据库连接账号应使用只读权限,最好连接只读副本。业务上可以通过视图、行级安全策略、字段脱敏、结果聚合来降低数据暴露范围。严禁让 Agent 使用 root 或高权限账号直连生产库。
第六层是运行时审计。系统需要记录完整链路:
原始用户 Prompt;
模型生成 SQL;
最终执行 SQL;
查询涉及的表和字段;
返回行数;
执行耗时;
是否命中敏感数据;
是否触发拦截;
是否进入人工复核。
这些日志可以反过来训练检测器,也可以作为安全审计和事件溯源依据。
对 Agent 安全产品的启发
这篇论文也给 Agent 安全产品提供了一个很好的切入点。
很多 Agent 风险不是发生在模型回答文本的时候,而是发生在模型调用工具、访问数据、执行动作的时候。
数据库查询就是典型场景。
从产品能力设计看,可以拆成几类检测能力:
第一,Prompt 侧检测。识别用户是否在诱导模型绕过限制、忽略系统提示、请求敏感表结构、枚举字段、探测数据库版本、发起高成本查询。
第二,工具调用侧检测。判断 Agent 是否正在调用数据库工具,调用参数是否异常,查询范围是否超过当前用户权限。
第三,SQL 侧检测。对生成 SQL 做语法解析、AST 规则校验、敏感字段识别、执行成本预估、危险函数识别、多语句检测。
第四,结果侧检测。即使查询被允许,也要检查返回结果是否包含手机号、邮箱、身份证、地址、token、cookie、内部账号、密钥等敏感信息。
第五,行为侧检测。对同一用户的连续查询做关联分析。比如短时间内大量探测表结构、枚举字段、尝试不同过滤条件、逐步逼近敏感数据,这些都应该被视为可疑行为。
也就是说,LLM 数据库 Agent 的安全防护不能只做“单条输入分类”。它需要覆盖 Prompt、工具、SQL、数据、行为五个层面。
数据库 Agent 必须把模型输出当成不可信代码
LLM-to-SQL 的价值很明确。
它降低了数据库查询门槛,让非技术用户也能直接用自然语言访问业务数据。这对 BI、客服、运营、财务、销售、运维都有吸引力。
但只要自然语言可以变成 SQL,Prompt 就有机会变成 Payload。
论文提出的三层防线给了一个清晰起点:输入层做粗筛,语义层识别攻击意图,执行前检查最终 SQL。实验结果也说明,真正有效的组合集中在 TD + QSC,也就是“看懂攻击意图”和“控制最终查询”这两个环节。
对企业来说,更关键的原则是:
不要相信用户输入;
不要完全相信模型判断;
不要让模型自由生成并执行 SQL;
不要给 Agent 高权限数据库账号;
不要让查询结果未经审计地返回给用户。
数据库 Agent 的安全边界,应该建在模型之外。
模型可以负责理解和生成,但执行权必须交给确定性系统、权限系统和审计系统。
当 Prompt 开始变成 SQL Payload,LLM 数据库 Agent 就不能只按智能应用来设计,它必须按照数据访问系统来治理。
声明:本文来自模安局,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
