由《农业图书情报》编辑部主办的2019全国图书情报青年学术论坛于1月7号在冰城哈尔滨胜利落下帷幕。此次论坛云集了来自北京大学、清华大学、中国科学院、南京大学、武汉大学、复旦大学,北京理工大学、黑龙江大学、中国农业科学院、中国科学技术信息研究所、中国医学科学院等50余家科研院所图书情报领域的专家学者。
2019年论坛主题“新兴技术、前沿追踪与最佳实践”,共22场学术报告。(专家报告请关注公众号的后续报道)。
专家简介

刘敏娟,农业信息管理学博士,中国农业科学院农业信息研究所文献资源发展部副主任,副研究员,美国伊利诺伊大学香槟分校访问学者。主要从事信息资源建设、知识组织方面的研究与工作。发表学术论文20余篇,出版著作3部,申请软件著作权3项,主持各类科研项目10余项。
面向学科领域分析的数据集构建方法研究
在学科服务的过程当中,数据集构建是我们必须要面临的一个重点问题。报告会介绍一些针对文献、数据集和子集构建的方法,并且会分享这个方法作用在数据集构建上的效果。
01 研究切入点
进行学科领域分析时,数据集的构建是位于整个分析链条工作上游的基础性环节,它的质量好坏直接决定了分析结果的准确性,是重点也是难点。在数据集构建时,我们经常需要去构建文献数据集或者是词集。
1.1 文献集合现有研究及问题
目前,文献数据集的构建方法主要是借助数据库提供分类、关键词、机构(作者)、期刊作为检索入口来构建文献数据集。但这些方法都具有一定的局限性。我们在实际工作中经常遇到的情况是,目标学科领域在数据库中无法找到既定的主题分类,也没有工具提供相应的参考,或者学科范围较广并与其它领域有交叉现象,因此没有专家能通晓整个跨学科、综合性领域,使得罗列完整关键词和选择有代表性机构不可能实现,而且没有现成的核心期刊范围可以参考。因此,如何进行文献数据集的构建是一个亟待探寻的问题。
1.2 词语集合现有研究及问题
共词分析法是学科领域分析中应用广泛的一种方法,共词分析中词集范围的选择决定了用哪些词来进行共词分析,直接决定着分析结果的准确性,如果在一开始就没有选择合适的分析对象,无论后期采用如何精良的分析技术都无法纠正其由于词量过少带来的结构性缺失问题,或者由于词量过大造成不必要的干扰。目前,依据齐普夫第二定律或者经验判定等方法确定高频词范围,用高频词进行共词分析是最为常用的方法。但是,高频词阈值的确定比较主观、标准不一,也不够规范,这方面专门的研究并不多见,是有很大值得研究和推进的空间。
整体上,关于数据集构建主要还是集中于实际操作,并未形成一定的理论与方法体系。现有的研究比较分散,理论根基并不深厚和扎实。分析人员大多依靠自身的经验摸索着进行。因此,我针对数据构建的方法做了些研究,提出了一个基于期刊主题相似性的文献数据集构建方法和一种基于词频、词量、累积词频占比的词集构建方法,接下来主要介绍一下这两种方法。
02 文献数据集构建方法
2.1 分析思路
期刊是文献发表的重要途径,因此,选用期刊作为遴选数据的途径。主要的思路是由特定学科领域的单本期刊,去发现更多的学科领域内的相关刊物,进而寻找到一系列属于该学科领域内或与其紧密相关的期刊群,再通过期刊间关系的建立使得之前相对游离的期刊群成为关联期刊群组。而同一群组中的期刊正是由于其主题的相近关系被聚合在一起,通过对期刊群组的分析,可以识别出哪些为拟分析学科领域的核心期刊群组,在此基础上可以构建满足不同的分析任务的需求与目标的文献数据集。
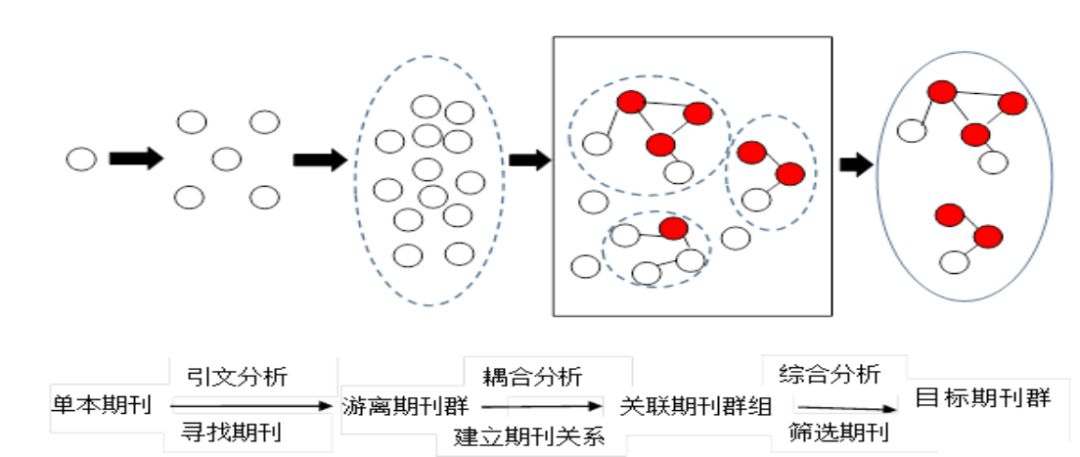
2.2 分析流程
接下来看一下具体的分析流程。首先,选择一本学科领域中的权威的刊物,且内容尽量综合,能够涵盖该学科领域内的分支领域,作为母本期刊,进行引文分析,去发现更多的学科领域内有代表性的刊物。为了避免单一期刊对分支领域覆盖的局限性,对单一期刊进行引文分析后,确定了被单一母本期刊引用最多的一组期刊,作为母本期刊进行再次引文分析,找到该学科领域内重要的期刊群。
然后,进行期刊—引文耦合分析以及期刊关系图谱的绘制,其中期刊文献耦合分析:是指以期刊为基本单元而建立的期刊—文献(引文)耦合关系。具体地说,n种(n≥2)学术期刊共享相同的参考文献时,称这n种期刊具有“期刊耦合”关系。其耦合程度以共享参考文献的多少来衡量,这个测度称为期刊耦合强度,这一环节的目的是为了挖掘出期刊间潜在的关系,也是最为核心的部分。最后,根据期刊学科属性的划分,并结合期刊被引频次的高低,辨识出该学科领域的代表性期刊群组,再结合特定的分析需求和目标,选定目标期刊组(即限定了分析数据集的边界)。之后,采集目标期刊组的期刊中一定时间范围内的发文,并对其进行清洗就构建了文献数据集。

2.3 目标期刊群组的选择
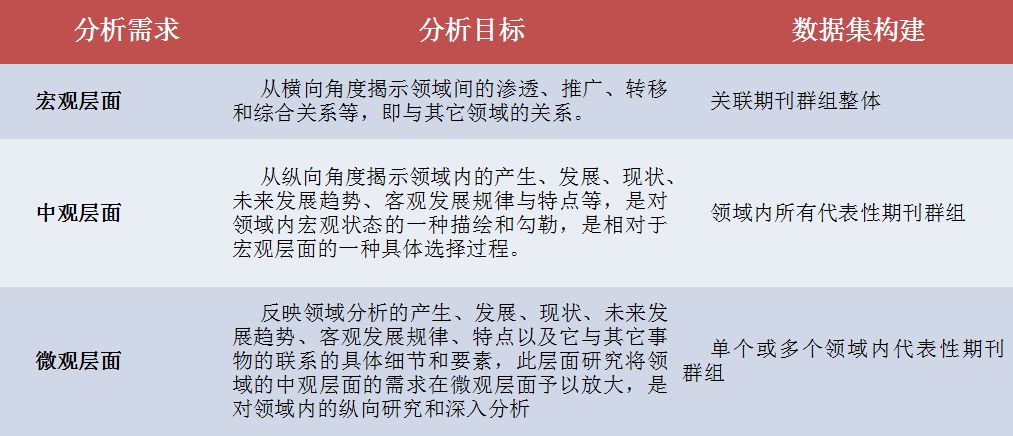
根据不同分析任务的需求与目标,进行期刊群组的组配是关键的环节,直接决定了不同的数据集边界。学科领域分析的需求大致可以分为3类:
(1)宏观层面
重点关注拟分析学科领域与其它领域的关系,可选择全部关联期刊群组构建分析数据集,期刊的主题结构即可反映学科宏观的知识结构,关注不同时期期刊结构的变化即可以发现拟分析学科领域与其它领域交叉渗透、推广和转移的情况。
(2)中观层面
需要立足于某一领域内部关系,从上到下解析领域结构,可选择领域内所有代表性期刊群组构建分析数据集,可进一步通过构建其发文或引文文献数据集开展相关分析。
(3)微观层面
如果关注具体某一分支领域的情况,可选择单个或多个领域内代表性期刊群组构建分析数据集。
以上就是关于基于期刊主题相似性的文献数据集构建的方法。
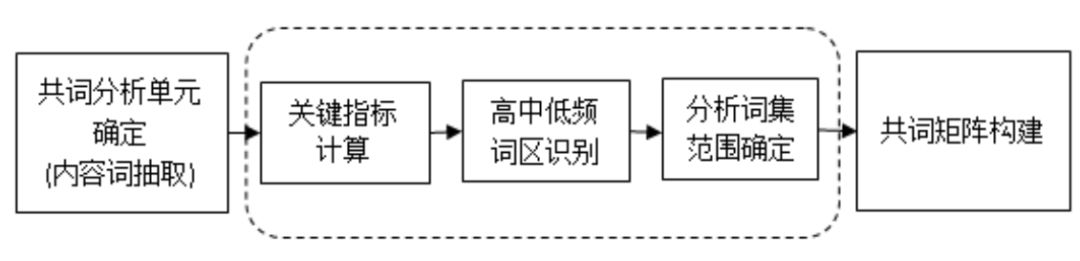
03 分析词集构建方法
3.1 分析流程
这个方法是基于关键词词频、词量和累积词频占比的关系,依据不同学科领域词集实际分布规律和特点,动态确定高、中、低频词区阈值,并将中、高频词共同作为共词分析词集的方法,是对共词分析过程中涉及的关键环节进行的改进,也是一种新的词频阈值确定及共词分析词集范围选择的方法。
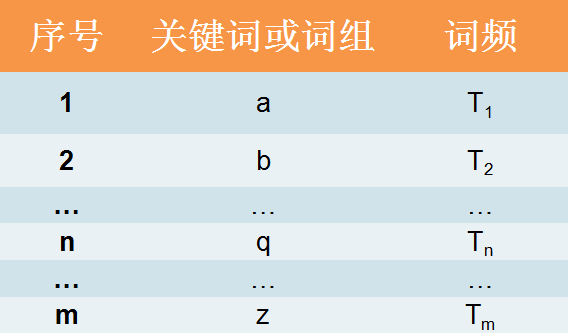
3.2 关键指标计算
方法中涉及的3个关键指标分别是关键词的词频、词量和累积词频占比。举个例子说明一下这3个指标:比如这张是某一关键词词集,包含词或词组a、b…z,词或词组按照词频降序排列,即关键词a在词集中词频最高。那么,关键词q的词频为Tn ,词量为n,累积词频占比就是用T1到Tn的累积求和除以T1到Tm的累积求和。
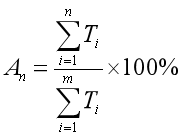
3.3 词集范围确定(选多少来分析?)
明确了3个关键的指标,接下来就要回答到底选多少词来分析的问题了。也就是词集范围的确定。这个方法是从词频、词量与累积词频占比三者的变化关系入手的,通过考察三者的变化关系,来识别出高、中、低频词区。这里面有两个关键性问题:
(1)如何识别出高、中、低频区域;
(2)选哪个区域进入词集。
3.3.1 如何识别出高、中、低频区域
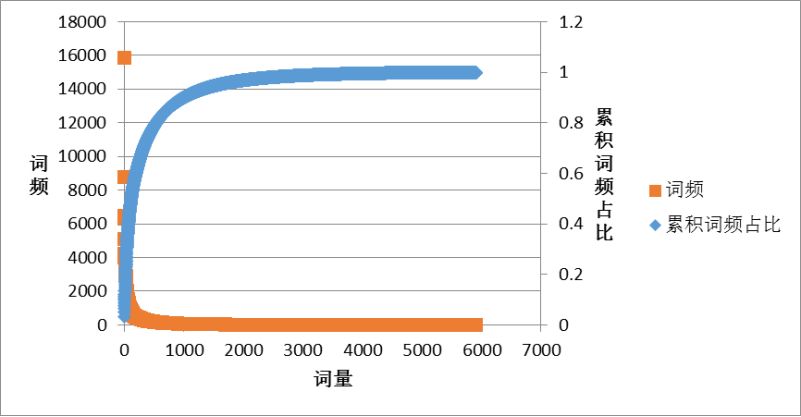
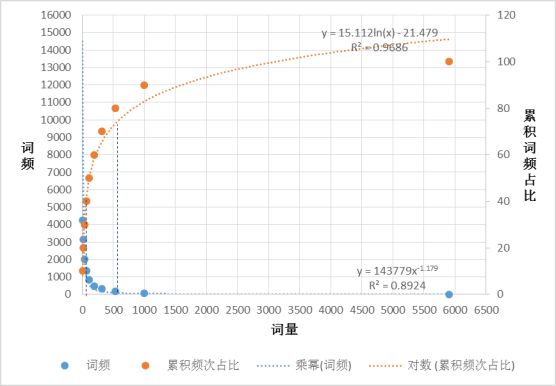
首先来看如何识别高、中、低频区域。图1是词频、累积词频占比随词量变化情况。区间0到 x1,就是高频词区,特征是词量增加不多,但是词频迅速下降,累积词频占比迅速增加。该区域词频波动较大,且对整体词频贡献很大。区间x1到x2是中频区,特征是随着词量的增加,词频下降和累积词频占比增加的趋势都明显放缓,也意味着若想获得相同的累积词频占比,需要增加的词量变大,且词频在中间区域变化。大于x2的区间是低频区,特征是,即使词量大量增加,词频下降和累积词频占比增加的趋势都非常缓慢,也意味着若想获得相同的累积词频占比,需要增加大量词汇的个数,且词频在低频区域变化。而为了进一步识别3个不同区间的曲线变化特征,将累积词频占比作为自变量,词频、词量分别作为因变量,就如图2所示,再去进一步识别高、中、低频区域。
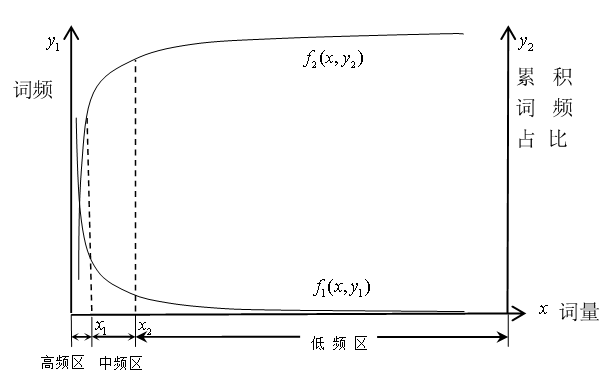
图1 词频、累积词频占比随词量变化情况
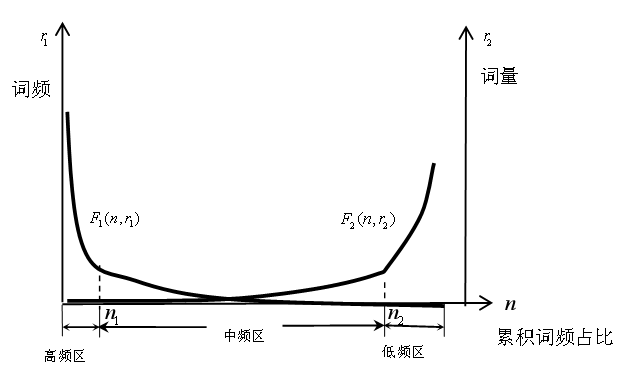
图2 累积词频占比作为自变量情况
3.3.2 选哪个区域进入词集
识别出3个区域后,就要确定选择哪个区域纳入分析词集了。通过研究,最终选择了高频区和中频区共同作为分析词集,这样既能保证包含了重要的骨干关键词,又不会增加过多的干扰和词量负担。但需要注意的是,由于不同学科不同词集其分布函数具有差异,因此应当根据其实际变化的特点确定阈值和词集的范围,这也是本方法区别于以往传统高频词阈值确定方法的特点之一。
04 实证分析—作物学科分析数据集构建
为了验证上述方法,此处选择了作物学科进行了实证分析。不仅因为该学科在农业领域的重要性,也因为进行作物学科分析,数据集构建是个难点。我们没有办法通过数据库提供的分类或者现成的核心期刊清单检索数据,而且罗列整个学科的关键词或者定位只研究作物科学的机构和作者更是不可能。因此,通过对作物学科领域分析数据集的构建,验证前面提出的数据集构建方法的可行性及效果,目标是构建作物学科分析数据集,实现作物学科热点主题和领域结构的探测。接下来就是按照上述的方法进行实践。
4.1 母本期刊的选择及引文分析
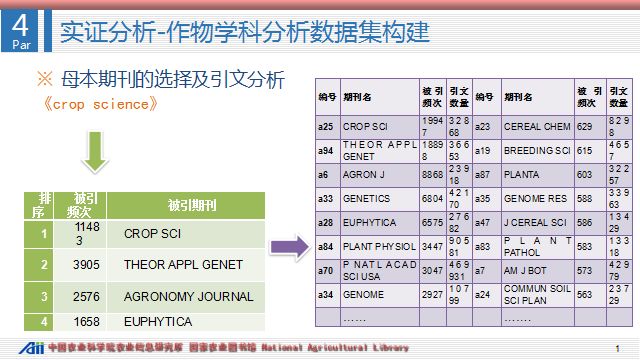
首先选择在作物学领域中的重要期刊《crop science》作为母本,是作物科学领域覆盖学科范围较为广泛,且受关注程度较高的期刊,因此将其作为母本期刊有很好的代表性。通过引文分析,我们发现《crop science》在时间段内共引证了2,736种期刊,总的引证频次为62,950次。其中被引频次最高的前4种期刊,再进行进一步的引文分析,借此确定作物学科领域的86种重要期刊。
4.2 期刊—引文耦合分析
针对上一步骤中确定的86种期刊,计算其期刊文献耦合强度,构建了86x86的矩阵。
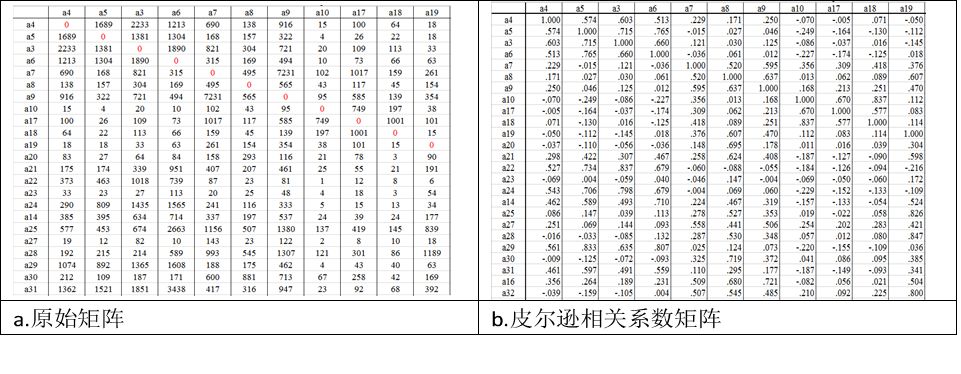
4.3 期刊关系图谱
绘制86种期刊的关系图谱,通过分析大致可将86种期刊分为ABCD,4个区域,8个期刊群,每个期刊群代表一定的主题。区域B中的4号期刊群组代表领域为作物遗传育种,是作物科学领域最为重要的期刊群组,分布着最多的被母本期刊高引用的期刊,即属于作物学科代表性期刊群组之一;区域B中3号期刊群组代表领域为分子生物学、植物生理生化、植物细胞学等,与4号期刊群组关系最为紧密,也属于作物科学领域的代表性期刊群组;区域A中的1号期刊群组关系分布着一些农艺学类的综合刊物,从图中可知,有几种期刊与4号期刊群组关系较为密切,反映了其发文更侧重遗传育种的情况,另外几种期刊与2号期刊群组距离更近,则说明其更侧重生产与栽培的内容,与水土和环境领域的关系较为密切,但作物生产与栽培也属于作物学科的主要分支领域,因此该群组也应属于作物科学领域的代表性期刊群组;其它2、5、6、7、8号期刊群组,被认为是作物学科领域的相关期刊群组。事实上,通过期刊分布结构图已经可知,作物科学包含了遗传育种、分子生物学、植物生理生化、作物生产等主要研究领域,而且图中清晰反映了作物科学与资源环境、植保、园艺、食品、畜牧等学科的交叉融合以及生物技术与信息技术在作物学科中的渗透应用现象。
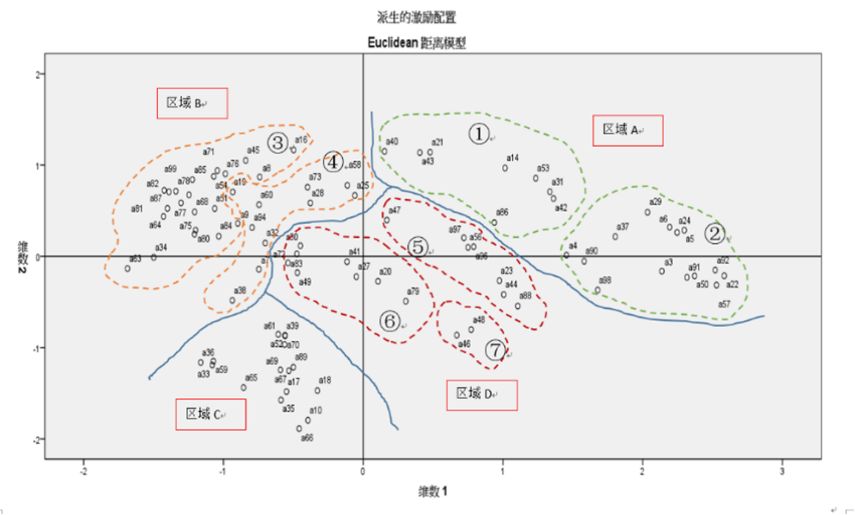
4.4 文献数据集构建
构建文献数据集,需要结合不同的领域分析任务的需求,来组配不同的期刊群组:如果侧重分析作物学科与其它领域关系的宏观分析,可选择全部关联期刊群组。如果进行作物学科发文趋势、研究力量分布、主流研究领域等的中观分析,可以选择1、3、4号期刊群组。如果想深入一个领域分析具体细节,如某一领域的热点主题等,也可以选择任一1、3、4代表性期刊群构建数据集开展进一步分析。
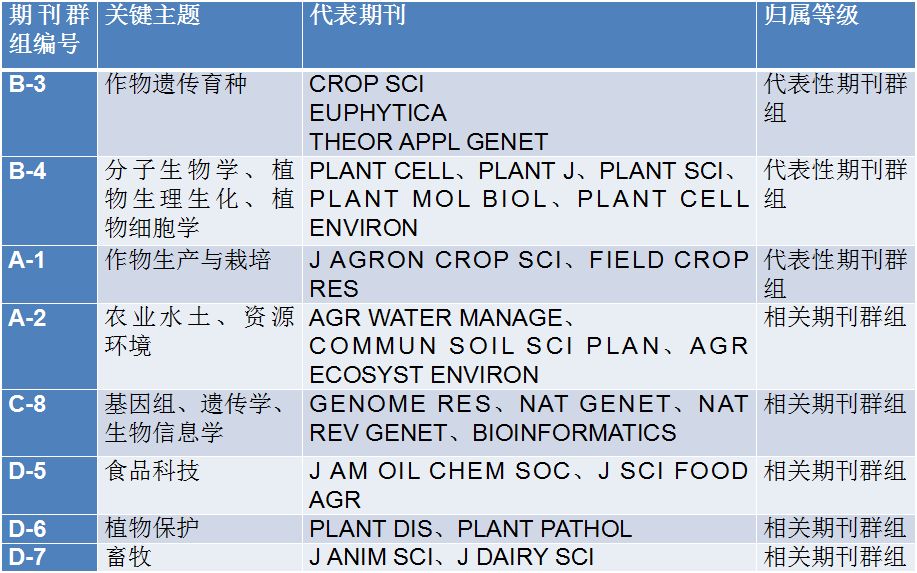
4.5 词集范围选定
这里选择了B区的期刊群组。也就是包括作物遗传育种、分子生物学、植物生理生化、植物细胞学领域的代表性期刊群组作为目标期刊群组,利用期刊中的发文构建了作物学科主流领域文献数据集,通过抽取内容词,并计算词频,继续构建共词分析的词集。
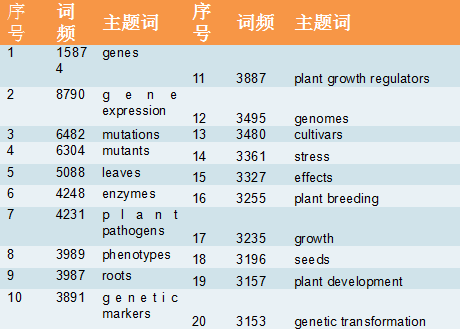
根据之前所述方法,做出词量—词频以及词量—累积词频占比关系函数图。但由于散点过密不利于关系函数变化的判断和阈值的确定。
所以我们按照累积频次占比每10%作为切片,取其对应的词量以及每段区域最后一个词的词频,再根据三者的关系,做出两幅关系函数图,辅助高、中、低频区域范围和阈值的确定。通过前面方法中提到的高、中、低频区域的特征,识别出词量为0-70区间为高频区,词量为71-536区间为中频区,词量为537-5,906区间为低频区,因此选择536个词纳入分析词集,累积词频占比覆盖到了80%。

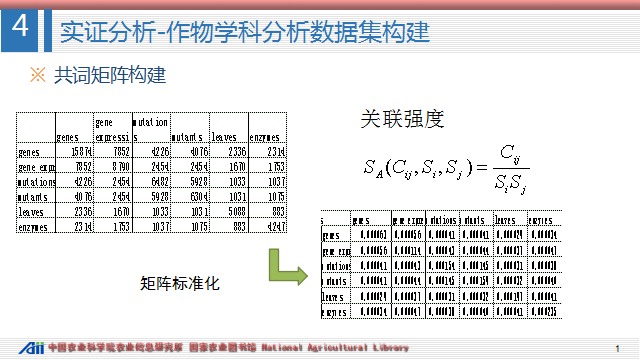
4.6 共词矩阵构建
随后构建了536×536的共词矩阵,并将原始矩阵采用关联强度算法转化为相关矩阵,即标准化。
4.7 共词聚类图谱绘制
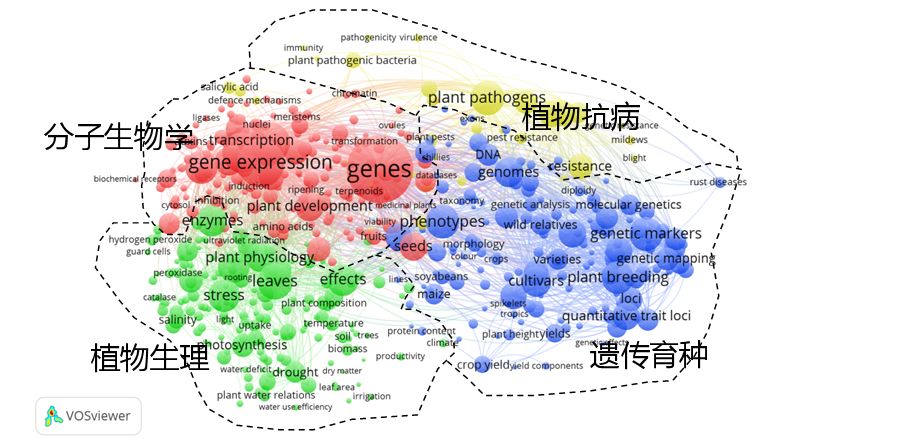
基于这样一个矩阵,可以绘制作物科学主流领域知识图谱,并进行热点主题和领域结构的探测。
从整个图谱来看,“基因”居于最核心的位置,与各聚类群的关系都十分密切,536个主题词共识别出4个主题群,分别为分子生物学领域、植物生理学领域、作物遗传育种领域、植物抗病性研究领域。其中分子生物学领域作为连接植物生理生化领域与作物遗传育种领域的纽带,与二者交叉交融关系都非常密切,足见其作为基础学科在作物学研究中的广泛应用。
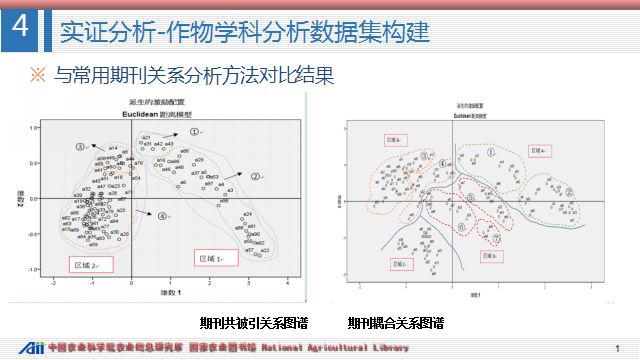
4.8 与常用期刊关系分析方法对比结果
为了进一步验证研究中涉及到重要环节方法的科学性,分别将前面提到的文献数据集合词集构建方法中的关键环节与常用方法的分析结果进行对比。首先,在文献数据集构建中期刊关系的确定是最核心的环节,因此期刊关系挖掘技术的选择至关重要。共被引分析以及耦合分析是两个常用的探测分析对象关联关系的方法。因此此处将这两种方法进行了对比。
首先,从分析原理来看,期刊共被引分析是依赖共同引用两种期刊的文献建立的关联关系,随着时间的推移其引用的模式会发生变化形成一种动态结构模型,这种关系是一种变化的、短暂的关系,且存在一定的滞后性。
期刊文献耦合则是通过期刊发文的参考文献建立的关联关系,随着时间的推移其引用模式不会发生变化,从而形成的是一种静态结构的模型,是一种固定的、长久的关系,可以更好地分析出期刊间当前关系的现实情况。
其次,从构建关系矩阵来看,共被引次数普遍低于引文耦合频次,更易出现“0”值,使得在衡量期刊关系时受到干扰,出现不稳定因素。
再次,可以从这两幅期刊关系结构图谱来看,右图的期刊文献耦合方法对期刊的分类更加细致和准确,在探测期刊主题相似性方面更具优势。
4.9 与常用词集范围确定方法对比结果
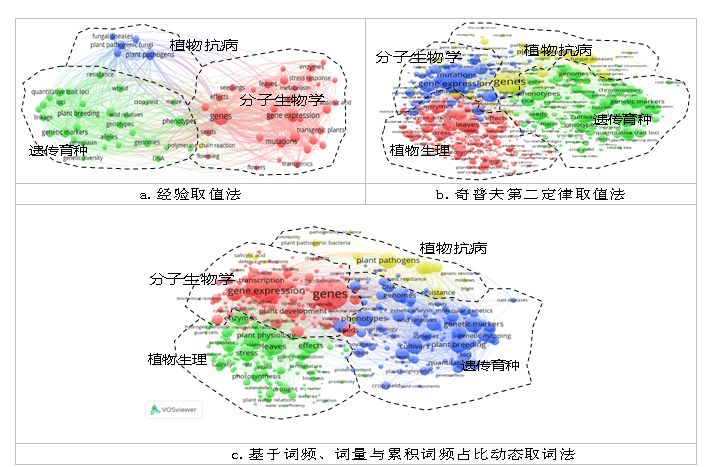
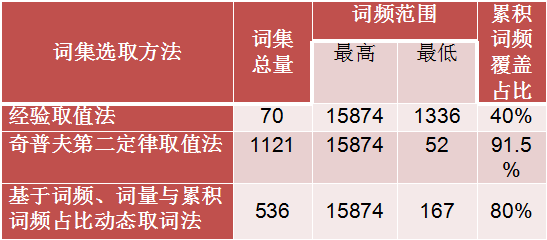
另外,还将词集范围确定的方法与常用方法做了比较。下图可以看到,左上角这幅图是采用经验取值法确定的词集范围,研究人员主要是在选词个数和词频高度上进行平衡,选取数量一般保持在40-70之间,这是选了70个高频词做出的图谱。那么,右上方的图谱是利用奇普夫第二定律计算的阈值,词量为1,121,而下面这幅图是本研究中提出的基于词频、词量、累计词频占比三者变化规律,动态取值的方法,词量为536。
进行相同的处理后,得到聚类图谱,可以清晰的看到:
(1)经验取值法由于词量过少导致主题结构缺失了“植物生理”这一重要分支领域;
(2)奇普夫第二定律取值法由于词量过大,出现了大量干扰,也使得网络结构复杂增加了人工判读的难度;
(3)本研究提出的方法,词量规模适中,完整的反映了主要的主题结构,且有效可控制了干扰词的存在还是具有不错的效果。
05 方法总结
5.1 基于期刊主题相似性的文献数据集构建方法
(1)可以满足宏观、中观和微观不同分析层次的需求
可以根据不同的分析需求进行期刊群组的组配,即可以完成从宏观到微观的不同分析任务。
(2)操作过程简单灵活且降低了人工干预的程度
本方法只需选定一本期刊即可开始,整个过程全部采用情报分析的常用方法,没有过多需要人工干预或者领域专家参与的步骤,从而降低了情报分析工作人员进行领域分析的门槛,以及过多人工干预主观局限性对结果带来的干扰。
(3)突破了传统方法在一些领域无法应用的局限
本方法重点针对一些既不能依赖数据库中的主题分类,又根本无法采用罗列关键词的方式进行数据集的构建,也无法定位相关研究机构和现成可用的核心期刊的学科领域,解决其数据集构建的问题。该方法可以运用在一些研究对象复杂,领域边界较宽的学科领域。
5.2 基于词频、词量、累积词频占比的分析词集构建方法
(1)克服了经验阈值选择的主观局限性。
(2)不存在齐普夫第二定律过度依赖词频为“1”的关键词个数的问题。
(3)将中、高频词共同作为分析的对象。在共词分析目标词集范围的确定上,摈弃了只选高频词的传统做法,将中、高频词共同作为分析的对象,在保证了主要信息不致丢失的前提下,避免了词量过高可能导致的数据处理工作量大以及不必要的干扰。
(4)依据不同学科领域词集实际分布规律和特点动态取词。本方法是根据词集高、中、低频词区具体分布特点确定词区范围的,因此不同学科领域不同词集其阈值自不相同,较为合理。为共词分析词集范围的选择提供了一种新的思路,使得共词分析在处理流程上更加精细化和规范化。
本文为录音整理,经本人确认授权后发表
声明:本文来自农业图书情报,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
