最近看了不少 AI 安全的文章,听了一些相关播客,也和朋友聊了几轮。我越来越觉得,很多时候大家在 AI 安全上的很多分歧,底层其实是对 AI 本身的认知差异。但讨论开始时大家又很少先交代这部分前提,每个人都带着自己默认的 AI 观进入对话,聊到后面就容易发现,大家说的好像是同一个问题,心里想的却不是同一种 AI。
最明显的是对 AI 发展速度的判断。我们可以把这个问题想成一条光谱,一个极端是,如果你认为 AGI 甚至 ASI 今年底就能实现,那你现在应该什么都别做了,去休假,去歇着,工作上的困扰、公司的难题、产品的瓶颈,等到年底直接抛给 ASI 就好了。当然,到了那个时候,人未来生活的意义可能也只能向内求了。另一个极端是,如果你认为 AI 今天就撞墙了,能力被三体文明锁死在当前水平,那你现在应该抓紧去创业。因为今天水平的 AI 已经足够颠覆很多行业,而且能力停滞以后,也不用担心自己投入三个月做出来的东西,转头就被一个新模型重置。
现实里,大家的看法肯定都在这两个极端之间。有人认为快一些,有人认为慢一些;有人认为现有路线还能继续推进很远,有人认为很快要换技术范式。这里没有必要也很难争出输赢,但知道自己站在光谱的哪里,也知道对面的人站在哪里,非常重要。否则讨论很容易跑偏。比如最近 Anthropic 围绕 Claude Mythos Preview 模型做了很多安全能力展示,我们当然可以讨论 Mythos 有没有 Anthropic 宣传的那么厉害,但这并不是关键问题。关键的是,你认为这种能力会不会出现?如果会出现,它是已经出现、几个月后出现,还是几年后出现?
所以我想聊聊自己对 AI 的一些基本看法。这不是完整的技术判断,也不是对未来的预测清单,更像是我现在进入 AI 安全讨论时带着的几个底层前提。未来回过头看,它可能对,但更可能不对,无论如何讨论总得有个基础。
LLM 走不到 AGI
我不认为基于 Transformer 架构的大语言模型会直接走到 AGI。
LLM 已经是非常重要的技术突破,而且它的影响还远没有结束。但从原理上看,LLM 是在多维向量空间里学习和操作表示。它可以把文字、代码、图像、语音,以及越来越多形式的信息统一到某种表示系统里,再在这个系统内部完成理解、推理、生成和规划。这个能力很强,但纯粹表示出来的理性世界,能不能充分代表真实世界,我觉得要打一个大问号。
真实世界里有大量能力,未必是从语言和概念里长出来的。鹰对重力、风向、角度和速度的处理远超人类,但它不懂数学,也不懂文字。刚出生的小马几个小时后就能站起来,这里面包含了漫长进化写进 DNA “权重”里的能力。人类后来学会数学、语文、哲学和各种抽象概念,这些东西很适合被语言和符号表达,也就很适合被 LLM 学习。但身体和物理世界里的很多能力,并不是靠读完互联网就能自然长出来的。
当然,未来也许语言和表示可以更完整地表达物理世界。模型可以通过视频、传感器、机器人反馈和仿真环境,逐步形成更丰富的世界模型。很多新公司和研究者也正在往 world model、空间智能、具身智能这些方向探索,包括李飞飞的 World Labs 和杨立昆的 AMI Labs 等一众 Neolabs。我不知道哪条路线可以达到 AGI,但我很怀疑 LLM 可以做到。
但比特世界会被 LLM 处理得很好
技术范式突破无法预测,它可能十年都不来,也可能下个月就出现。那在现有的 LLM 架构下,智能可以被推进到什么程度,天花板又在哪里?
我现在更愿意把 atom 和 bit 分开看。物理世界,也就是 atom 的部分,确实不好说。机器要进入真实环境,就会遇到视觉、触觉、力反馈、空间关系和不可控扰动。它要和物体、身体、材料、环境打交道,很多能力并不只是读更多文本就能长出来。机器人能不能像人一样可靠地在真实世界里行动,什么时候可以大规模进入家庭、工厂和城市空间,我现在没有很强判断。
但 bit 的部分,我的判断要明确得多。互联网世界本来就是由表示构成的。网页、文档、代码和日志,配置、工单、API 和数据库字段,本质上都是可以被读取、转换、生成和调用的对象。只要一个任务主要发生在这些对象之间,AI 就会不断进入它的核心流程。它未必一次性把所有工作都做完,但它会先接管一部分,再通过工具调用、工作流和 Agent 把更多环节连起来。
这里有一个很有意思的错位:很多人觉得难的东西,AI 觉得相对容易;很多人觉得容易的东西,AI 反而很难。理解复杂概念、写代码、做逻辑推理和总结资料,这些在人的教育体系里属于高阶能力,但它们很大程度上发生在表示世界里。只要输入、过程和输出可以被足够好地表达,模型就有机会不断逼近,甚至超过大部分人类水平。
相反,人觉得很自然的事情,模型和机器人并不一定做得好。随便放一罐易拉罐可乐在桌子上,让机器人自己识别、拿起、打开、避免弄洒,这个问题在真实物理环境里仍然很难。它涉及一堆人在生活里根本不会意识到的隐性知识。人类觉得简单,是因为这些能力背后有身体和进化的长期积累。
这个错位对产业判断很重要。AI 不会平均地替代所有人类能力,它会先冲进那些已经高度表示化的领域。代码、文档、合同、客服、财务分析、知识管理、搜索和数据处理,这些都在它的主战场里。网络安全也在其中。漏洞描述、PoC、流量、日志、配置和告警,大量安全工作本来就发生在数字系统和文本化对象中。只要这些对象能被模型读懂、关联和操作,AI 就会持续推进。
所以我对 bit 世界的判断比较激进:互联网上绝大多数可被表达、可被调用、可被验证的任务,基本都会被 AI 处理掉。它不一定意味着每个岗位都会消失,也不意味着每家公司都会被淘汰,但这些工作的成本结构、交付方式和竞争边界都会变。物理世界还要等机器人、传感器、执行器和世界模型继续进步;数字世界已经在 AI 的射程里了。
更重要的商业问题是扩散速度
讨论最先进模型的能力,更多是技术问题。到了商业和社会层面,更重要的是扩散速度。
做科学研究、做前沿漏洞挖掘、做复杂攻击链分析,永远都需要人类手头最先进的模型。但总结会议纪要,DeepSeek R1 级别的模型可能就够了,V4 都不需要,十年后可能也还是不需要,到那个时候,能完成这件事的小模型也许已经可以跑在手表里。模型能力继续上升,并不意味着所有任务都永远需要领先模型。恰恰相反,对大量具体任务来说,一旦模型能力跨过可用阈值,竞争重点就会转到成本、速度、稳定性、集成和体验。
所有任务都会经历同一条曲线:AI 干不了这个;AI 还是干不了这个;AI 好像可以做了,但有时候还不行;大部分时候 AI 都可以做了;AI 做得很好了;最新模型做这个有点大材小用;领先模型太贵了,这个任务我们用旧模型吧。
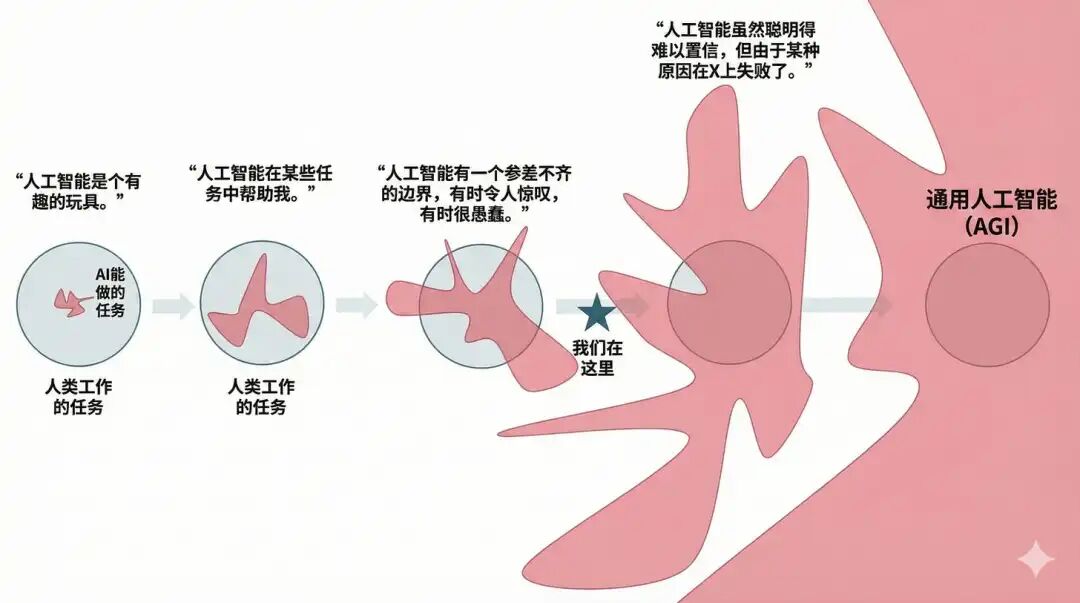
Source: 博客文章——Google Gemini 转绘,Tomas Pueyo
这条曲线会反复出现。每一个任务都有自己的临界点。有的任务很早跨过去,比如会议纪要、翻译、基础代码生成。有的任务会慢一些,比如复杂项目管理、专业研究、跨系统 Agent 执行。还有一些任务会很晚,尤其是涉及真实世界、强责任边界和不可逆动作的任务。产业变化的速度,不取决于“AI 总体有多强”这个抽象问题,而取决于一个个具体任务什么时候跨过够用线。
够用线一旦被跨过,市场结构就会变。领先模型还在继续变强,但客户不会为每个任务都付领先模型的钱。一个模型能不能在企业里真正用起来,往往还取决于它是否便宜,能不能私有化或本地化,延迟是否可接受,权限和日志能不能接入,输出是否稳定,出了问题能不能追溯。模型能力越往上走,这些部署和运营问题反而越重要。
回到网络安全,进攻会一直追前沿,防守要逐渐去分层
网络安全是一个很适合观察 AI 扩散的行业,因为它本来就是对抗性的。
不同安全问题对应不同扩散阶段。前沿模型刚出现某种能力时,最重要的风险可能集中在少数实验室、少数合作伙伴和少数高能力攻击者手里。等能力下沉到开源模型、旧模型、小模型、本地模型,风险就会变成广泛扩散的问题。前者更像前沿能力治理,后者更像基础设施治理。两个问题都重要,但应对方式完全不同。
在攻击侧,最先进模型始终能带来对抗优势,攻击者有动力一直追前沿。复杂漏洞利用、多漏洞链式组合、系统特殊状态的把握、长程攻击路径规划,这些任务都会受益于前沿模型的代码、推理和工具使用能力。Anthropic 对 Mythos Preview 的叙述之所以引起关注,也正因为它把“模型能发现漏洞”和“模型能把漏洞变成可用 exploit”之间的距离大幅缩短了。如果这类能力继续扩散,安全行业面对的会是攻击者研究、试错和武器化速度的整体上升。
但在防守侧,很多任务并不需要追逐最前沿模型。很多场景一旦被良好定义,够用模型就能产生价值。告警初步分级、资产和数据分类、配置检查、规则推荐、报告生成、低复杂度日志关联,这些任务的重点未必是模型有多聪明,重点在于能不能嵌进流程,能不能稳定运行,能不能降低人力成本,能不能被审计和复核。
这会带来一个分层结构。最前沿的安全能力,会集中在漏洞研究、攻防推演、复杂代码理解和自动化利用这些地方;大量日常安全运营,会逐步被已经成熟、成本更低的模型覆盖。攻击侧为了优势追前沿,防守侧则要同时管理前沿能力和普及能力。前沿模型可以帮助发现最难的问题,旧模型和小模型会进入更多现场,把安全工作中的重复劳动吃掉。
所以讨论 AI 安全时,我不太愿意只问“AI 会不会带来安全风险”。这个问题太大了。更好的问法可能是:我们讨论的是哪一种 AI?是实验室里尚未公开的前沿模型,还是企业已经部署的通用模型?是能自主调用工具的 Agent,还是只负责分类和总结的小模型?是攻击者用于漏洞利用的模型,还是防守方用于告警分级的模型?这些对象不一样,安全问题就不一样。
如果一个人认为 AGI 很快就会出现,他最关心的可能是模型失控、对齐失败、战略稳定和人类整体控制权。如果一个人认为 LLM 很快到顶,他可能更关心眼前的内容安全、数据泄露、自动化攻击和产业落地风险。如果一个人像我这样,怀疑 LLM 能直接走到 AGI,但又相信它会吃掉大量 bit 世界的任务,那么我会特别关注数字世界里的能力扩散:代码、安全、知识工作、企业流程和 Agent 权限。
写在最后
我现在对 AI 的基本判断,大概可以概括成三句话。
第一,现有 LLM 路线非常强,但我不认为它会自然走到 AGI。它在表示世界里的能力会继续提高,但真实世界、身体、物理反馈和长期自主行动,可能需要新的技术范式。第二,即使没有 AGI,LLM 也已经足够改变大量数字行业。第三,商业和社会影响不只取决于最强模型能做什么,更取决于能力什么时候扩散到具体任务里,什么时候变得够用、便宜、稳定、可集成。
带着这三个判断再看 AI 安全,我会更关注一个问题:AI 能力会在哪些数字任务上快速跨过够用线,随后以什么速度扩散到更多人手里。网络安全是最典型的场景之一。因为安全工作本来就大量依赖代码、文本、日志和系统知识,也因为攻防双方都会主动寻找能力差。只要模型在这些表示型任务上继续进步,安全行业就不可能只是把 AI 当成一个新功能模块。
这也是为什么我觉得,聊 AI 安全之前,先要说清楚自己相信什么样的 AI。你相信 AGI 很快到来,和你相信 LLM 已经撞墙,会得到完全不同的风险地图。你相信前沿模型最重要,和你相信旧模型的扩散更重要,也会得到完全不同的产品和治理重点。很多讨论聊不明白,不一定是某一方逻辑差,而是大家没有先把这些前提摊开和对称清楚。
声明:本文来自表图,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
