过去谈 Agent 安全,我们很容易把问题理解成一组技术攻击:提示注入、工具滥用、数据泄露、越权调用、恶意网页诱导、MCP 工具投毒、长期记忆污染。
这些问题当然都存在,但如果把视角再往上提一层,会发现它们其实都指向同一个问题:
Agent 到底是在执行用户真正想做的事,还是已经被外部内容、模型幻觉、权限漂移和错误配置带偏了?
最近一篇论文《Reframing LLM Agent Security as an Agent–Human Interaction Problem》给出了一个很有意思的判断:LLM Agent 安全,不能再被简单看成纯算法问题,而应该被重新理解为一个 Agent–Human Interaction Security 问题,也就是“Agent 与人交互过程中的安全问题”。

https://arxiv.org/pdf/2605.24309
论文分析了截至 2026 年 4 月的 59 篇学术论文、21 个生产级 Agent 系统和 26 个安全插件,最后发现一个非常明显的错位:工业界已经大量依赖人参与的安全机制,但学术界仍然更偏好研究自动化的安全判断方法。
这篇文章的价值,不在于提出了一个新的攻击样本,也不在于发布了一个新的 benchmark,而在于它把 Agent 安全的核心问题重新框定了。
过去我们常说“human in the loop”,但在 Agent 时代,这句话可能需要重新理解。人不是简单站在最后按一下“同意”或“拒绝”的按钮,而是要通过策略、权限、边界、审批、上下文说明,把自己的真实意图持续表达给系统。
Agent 安全的关键,不是把人从回路里拿掉,而是把这个人类回路重新设计好。
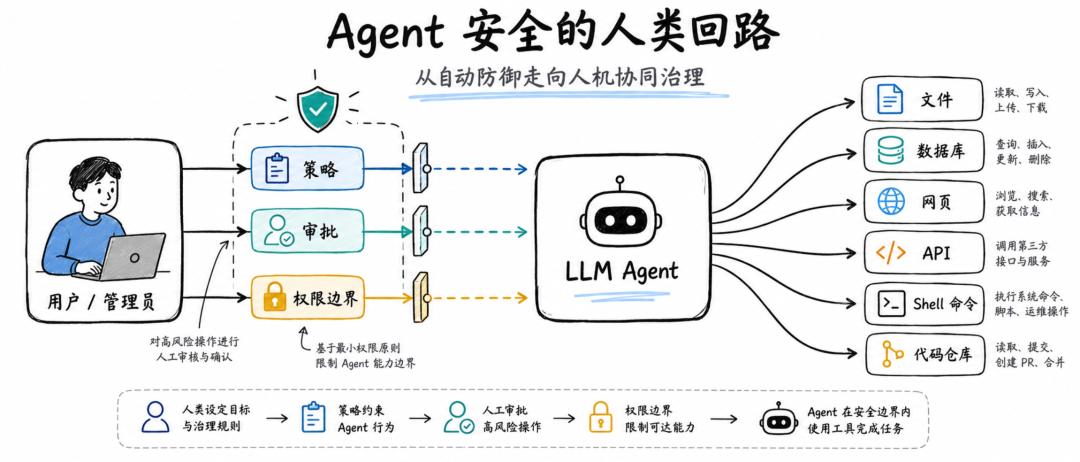
Agent 安全的核心,不是工具调用,而是意图对齐
论文提出的第一个关键概念叫 Intent Alignment,可以翻译成“意图对齐”。
这个概念并不复杂。用户让 Agent 做一件事,比如“帮我修复这个 bug”“帮我整理这批文件”“帮我检查这个系统配置”“帮我生成并提交一份报告”。Agent 在执行过程中可能会读文件、写代码、运行命令、访问网页、调用 API、连接数据库,甚至修改生产环境配置。
问题在于,用户最初的一句话通常很模糊。用户说“修复 bug”,不代表允许 Agent 删除数据库;用户说“整理文件”,不代表允许 Agent 把本地文件上传到外部服务;用户说“分析日志”,不代表允许 Agent 访问所有系统凭证。
Agent 的行动空间太大,用户不可能在任务开始前完整列出所有允许动作和禁止动作。更麻烦的是,Agent 执行任务时还会不断遇到新的上下文、新的子目标和新的工具调用。很多安全判断并不是简单的语法判断,而是语义判断。比如“删除所有临时文件”到底安全不安全,要看项目结构、文件含义、当前任务目标和用户真实意图。论文正是把这种问题称为 Agent 安全中的“意图对齐挑战”。
这也是 Agent 安全和传统应用安全不太一样的地方。
传统应用系统通常有相对固定的业务流程。一个按钮触发一个接口,一个角色拥有一组权限,一个 API 对应一组明确资源。Agent 不一样,它的行为是动态生成的。它不是在一条固定流程里移动,而是在开放环境里不断规划、调用工具、读取反馈、再次规划。
所以,Agent 安全不能只问“这个工具能不能调用”,还要问“在当前任务、当前上下文、当前用户意图下,这个工具调用是否合理”。
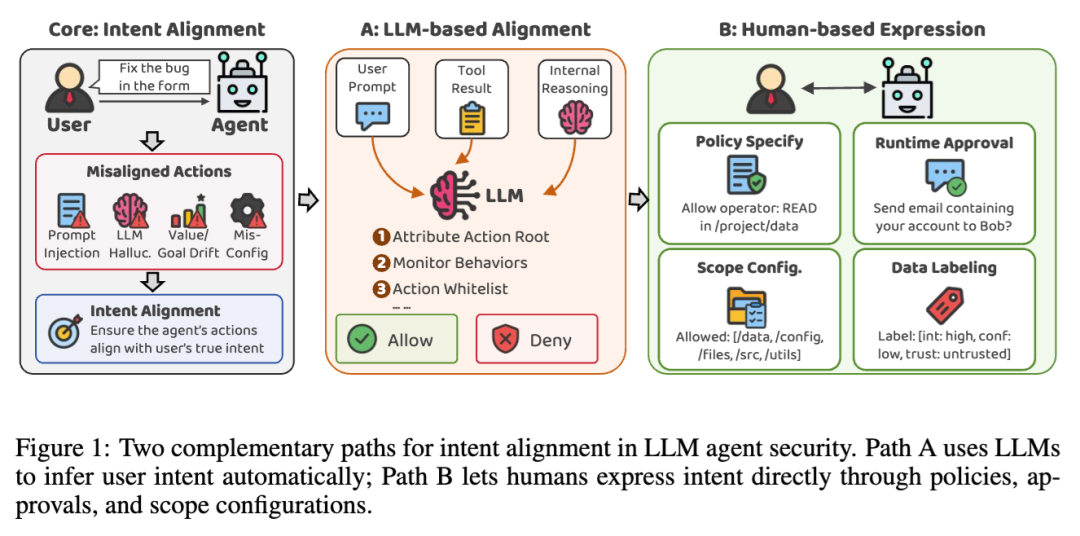
两条路线:让模型替人判断,还是让人表达边界
围绕“意图对齐”,论文把现有 Agent 安全方案分成两条路线。
第一条路线,是让模型来判断模型。系统可以引入另一个 LLM、安全模型或 Judge 模型,观察用户原始任务、Agent 当前计划、工具调用参数和上下文信息,然后判断这个动作是否符合用户意图。学术界很喜欢这条路线,因为它看起来足够自动化,也足够“AI native”。如果这条路线成立,用户只需要发出任务,后续所有安全判断都可以由模型自动完成。
第二条路线,是让人类更明确地表达自己的意图和边界。人可以提前写策略,说明哪些工具允许调用、哪些目录允许访问、哪些网络请求必须禁止;也可以在运行时审批高风险动作;还可以配置 Agent 的工作范围,比如只能访问某个项目目录、某个代码仓库、某组 API、某个云资源空间。
论文的核心判断是:这两条路线并不是完全对立,但它们的地位并不对称。LLM 可以帮助降低人的负担,但不能完全替代人。因为“用户到底想要什么”,最终只能来自用户自己。
这个判断看起来朴素,但非常重要。
如果 Agent 只是一个聊天机器人,模型自动判断安全边界还有一定空间。因为它最多只是生成一段文本,风险主要集中在内容层面。但当 Agent 可以执行命令、修改文件、访问凭证、调用外部 API、操作业务系统时,安全问题就不再只是“回答得对不对”,而是“行为是否越界”。
在这种情况下,让另一个 LLM 做最终裁判,会遇到一个很难绕开的循环依赖:如果主 Agent 会被提示注入影响,那么负责判断安全的 LLM 同样可能被上下文误导;如果用户意图本身没有被清楚表达出来,那么安全模型也只能在不完整信息上做猜测。
换句话说,自动判断不是不重要,但它不能成为唯一防线。
最关键的数据:工业界和学术界已经走向两边
这篇论文最值得拿出来讲的,是它统计出来的产业实践和学术研究之间的错位。
论文把 Agent–Human Interaction 安全机制分成五类:范围与边界配置、运行时审批、策略定义、信任与数据标注、意图锚定。结果显示,在 21 个生产级 Agent 系统中,范围与边界配置被 16 个系统采用,运行时审批被 15 个系统采用,策略定义被 14 个系统采用;而学术界较多研究的意图锚定和信任标注,在生产系统中的采用数量都是 0。
这组数据很有冲击力。
工业界真正大规模使用的,是听起来并不“性感”的安全机制:配置范围、写策略、做审批。学术界更感兴趣的,是让模型自动识别用户意图、自动判断行为是否安全、自动标注数据可信度。
这背后其实反映了两种安全哲学。
学术界关心的是:模型是否可以越来越聪明,最终自动判断什么是安全的。
工业界关心的是:系统一旦真的能删库、改代码、发邮件、调 API、操作云资源,就不能把最终判断完全交给另一个模型。
所以工业界选择了一条更保守也更现实的路线:先把人留在回路中,再想办法降低人的操作负担。
这不是因为工业界不懂自动化,而是因为在真实生产环境里,Agent 的错误动作不是实验分数下降,而可能是数据丢失、服务故障、凭证泄露、合规事故和供应链风险。
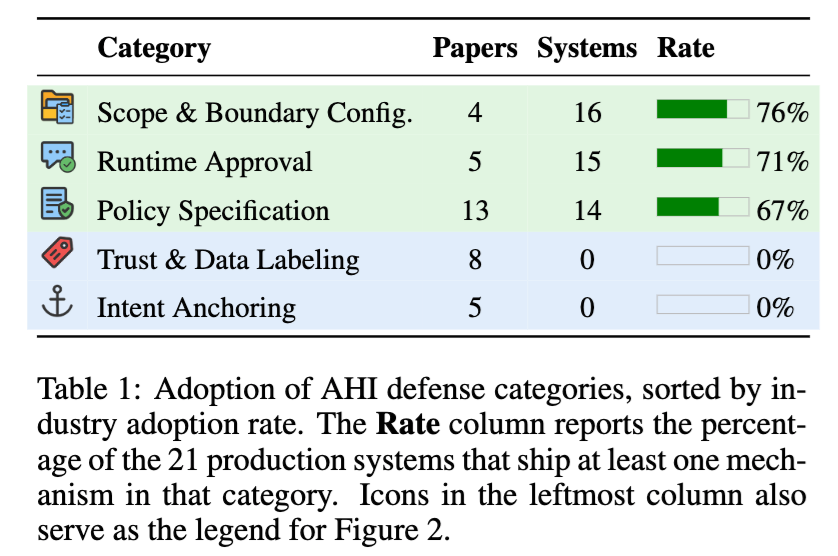
为什么人不能被完全拿掉
论文认为,在当前阶段,人类参与 Agent 安全决策仍然不可替代。
第一个原因,是用户 prompt 本身就不精确。用户的一句话往往只是任务目标,不是完整授权书。比如“帮我修复项目里的问题”,里面并没有说是否允许访问隐藏文件,是否允许安装依赖,是否允许修改测试脚本,是否允许连接外部服务,是否允许提交代码。把这样一句模糊指令当成安全判断的唯一锚点,本身就不稳。
第二个原因,是很多安全判断依赖用户背景和业务语境。某个文件对一个用户来说只是临时缓存,对另一个用户来说可能是关键配置;某个 API 对一个测试环境来说可以随便调,对生产环境来说就必须严格审批。这些信息不一定在 prompt 里,也不一定能从上下文中可靠推断。
第三个原因,是 LLM 做安全裁判会遇到自我引用问题。Agent 可能被提示注入误导,安全 Judge 也可能被提示注入误导;Agent 可能误解任务上下文,安全 Judge 也可能误解任务上下文。把安全完全交给模型,本质上是在用一个不完全可靠的系统审查另一个不完全可靠的系统。
第四个原因,是人类可以直接表达意图,而模型只能推测意图。比如用户明确配置“只允许读取 /project/data 目录,不允许访问 ~/.ssh,不允许联网”,这就是一个可执行、可审计、可验证的边界。相比之下,让 LLM 判断“访问 ~/.ssh 是否有助于完成任务”,就会引入更多不确定性。
这并不是说人永远比模型更懂安全。很多普通用户并不了解工具调用风险、Shell 命令风险、凭证泄露风险和供应链风险。但用户至少是任务意图的来源。安全系统真正要做的,是把用户意图、系统策略和专业安全判断结合起来,而不是简单让模型猜测用户想法。
但现在的人类回路,其实设计得很糟糕
论文没有把“人参与”神化。相反,它明确指出,当前 Agent 系统里的人类参与机制远远不够好。
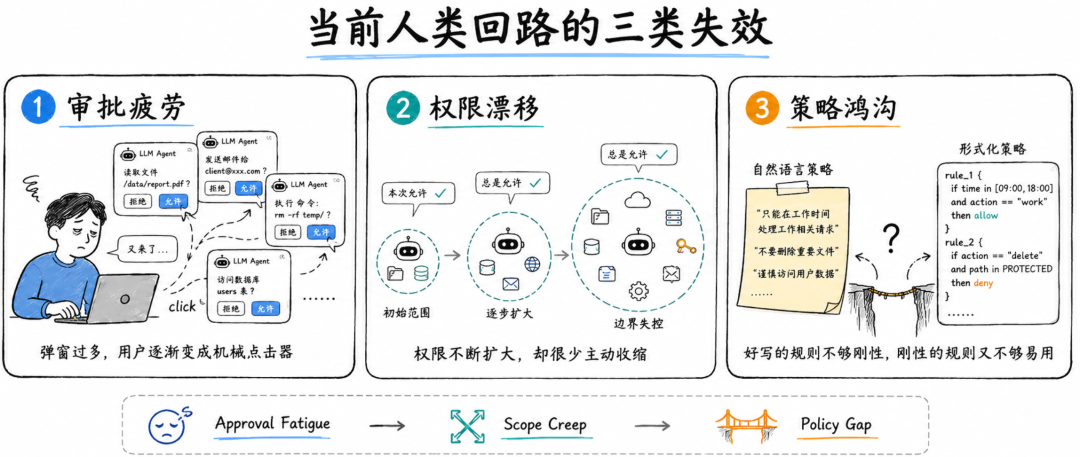
最典型的问题是审批疲劳。
很多 Agent 产品会在执行命令、修改文件、访问网络、安装依赖时弹出确认框。刚开始用户可能还会认真看,但当一个任务连续弹出几十次确认,用户很快就会进入机械点击状态。安全审批从“风险判断”变成了“继续运行任务的障碍”。这时,用户并没有真正理解风险,只是在反复点击“允许”。
另一个问题是权限漂移。很多系统为了降低摩擦,会提供类似“always allow”的选项。用户为了让任务顺利完成,可能不断扩大 Agent 的权限范围。一次任务中放开一个目录,下一次任务中放开一个工具,再下一次任务中允许一类命令。权限边界不断扩大,却很少被主动收缩。论文把这种现象称为 scope creep,也就是范围蔓延或权限漂移。论文还提到,Replit Agent 相关的生产数据库删除事故,就是过宽边界配置可能导致破坏性结果的一个例子。
还有一个问题,是策略表达太难。
自然语言策略很好写,比如“不要修改生产数据库”“不要访问敏感文件”“不要执行危险命令”。但自然语言策略往往依赖 Agent 自己理解和遵守,强约束能力不足。形式化策略更可靠,比如用明确的 allow、deny、resource、operation、condition 来描述权限,但普通用户和普通开发者又很难写好。
于是现在的 Agent 安全产品经常卡在两个极端:要么让用户不停审批,最后变成点击机器;要么给 Agent 很大自由,最后风险不可控。
论文真正想表达的,不是“必须让人审批一切”,而是“必须重新设计人如何参与安全”。
Agent 安全产品真正需要的,是意图捕获系统
如果把论文观点落到产品设计上,我认为它指向一个很清晰的方向:
未来的 Agent 安全产品,不应该只是一个自动风险检测器,而应该是一个人类意图捕获与执行约束系统。
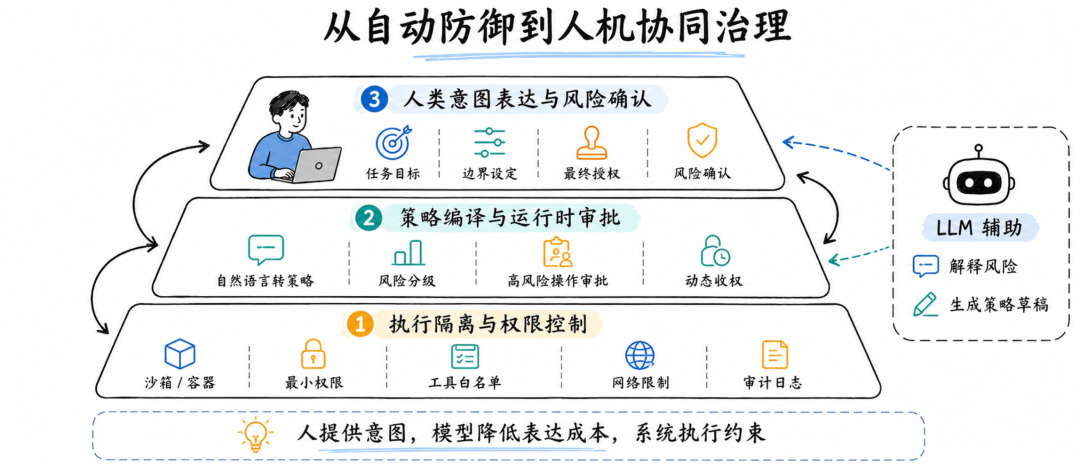
这套系统的第一层,是边界配置。系统要允许用户或管理员定义 Agent 可以访问哪些目录、哪些代码仓库、哪些工具、哪些网络地址、哪些 API、哪些凭证和哪些云资源。论文附录中也提到,生产系统常见的边界对象包括命令、工具、文件目录、网络、执行环境、代码仓库、云资源、API 和凭证等。
第二层,是运行时审批。但审批不能粗暴地覆盖所有动作。真正合理的做法,是根据资源敏感度、操作不可逆性、数据外发可能性、权限提升程度和历史行为模式来判断是否打断用户。普通文件读取可以自动放行,高风险命令、生产库写入、密钥访问、外部网络上传、不可逆删除则必须更严格。
第三层,是策略编译。用户可以用自然语言描述偏好,但系统内部要尽量把它转换成结构化策略。比如把“不要访问敏感目录”翻译成具体路径规则,把“不要联网”翻译成网络访问控制,把“不要修改生产配置”翻译成文件和环境标签约束。自然语言可以作为输入界面,但不能只停留在自然语言层面。
第四层,是权限生命周期管理。Agent 的权限不应该只会增加,不会回收。一个任务结束后,临时权限应该自动失效;任务目标变化时,权限应该重新评估;用户进入高风险操作时,系统应该重新确认边界;权限扩大之后,也应该有可视化方式告诉用户当前可信面已经变成多大。
第五层,是解释与审计。审批界面不能只给用户展示一条命令,比如 rm -rf tmp/ 或 curl xxx。它应该解释这个动作要访问什么资源、为什么需要、潜在影响是什么、能否回滚、有没有更安全的替代方案。否则用户看到的是技术细节,不是安全决策。
这才是“人类回路”的真实含义。它不是把人放在流程里挡一下,而是让人能够以低负担、高质量的方式表达意图,并让系统把这些意图变成可执行的安全约束。
LLM 不是最终裁判,但可以成为人类意图的放大器
需要强调的是,这篇论文并不反对使用 LLM 做安全判断。它反对的是把 LLM 当成最终裁判。
更合理的方向,是让 LLM 辅助人表达和管理安全意图。
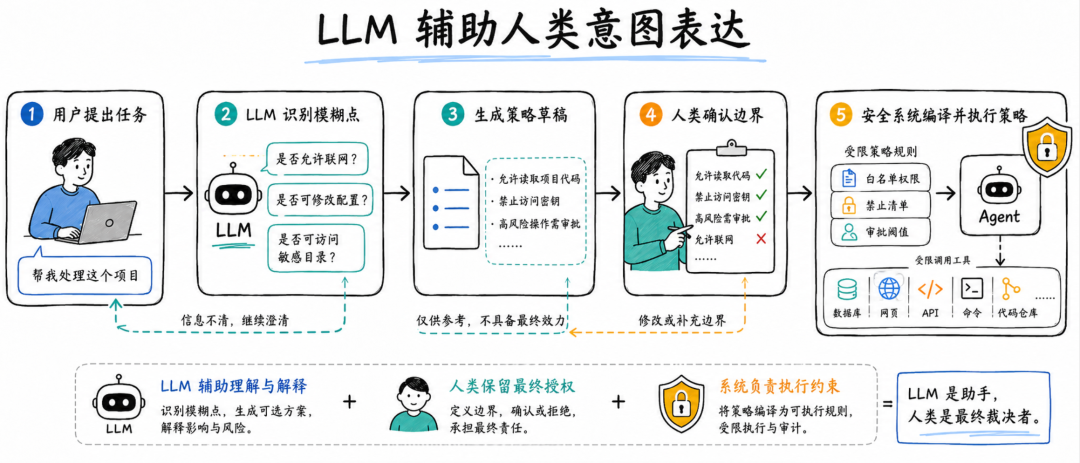
比如,LLM 可以在任务开始前主动发现模糊点。用户说“帮我清理项目目录”,系统可以追问:“是否允许删除未跟踪文件?是否允许修改配置文件?是否允许联网安装依赖?”这比执行到一半再突然弹窗更自然。
LLM 也可以帮助生成策略草稿。用户不需要直接写复杂 DSL,只需要说“这个 Agent 只能读项目代码,不能访问密钥,不能联网,不能修改数据库”,系统可以自动生成初始策略,再让用户确认和修改。
LLM 还可以总结风险。面对一条复杂命令,系统可以用更容易理解的语言告诉用户:这个操作会删除哪些文件、是否可恢复、是否涉及敏感目录、是否和当前任务相关。
论文提到 AutoPermissions 的结果,LLM 可以从上下文中以 85.1% 的准确率预测用户审批决策。这说明 LLM 可以用来降低审批负担,但用户仍然应该保留最终授权权力。
所以,未来 Agent 安全不是“人 vs 模型”的二选一,而是“模型辅助人,系统约束模型”。
模型负责理解上下文、生成策略草稿、识别模糊点、解释风险;人负责表达真实意图、确认高风险边界、承担最终授权;系统负责把这些意图变成可执行、可审计、可回滚的安全控制。
这篇论文对 OpenClaw 这类系统也有启发
论文附录中多次把 OpenClaw 纳入生产系统对比。比如在策略表达部分,OpenClaw JSON 被列为一种生产系统中的策略表示形式;在运行时审批部分,OpenClaw HITL 被列为高风险操作的人类审批机制;在范围与边界配置部分,OpenClaw 被描述为具备工具、Agent 粒度控制以及 Docker 网络控制等能力。
这说明 OpenClaw 这类系统天然就处在 AHI Security 的实践谱系里。
从这个角度看,Agent 安全框架不只是“拦截危险工具调用”,而是要回答几个更基础的问题:用户如何配置 Agent 的能力边界,系统如何把策略落实到工具和执行环境,运行时如何处理高风险动作,任务结束后权限如何回收,多个 Agent 协同时如何继承或隔离权限。
这也是 Agent 安全从单点检测走向治理体系的关键。
如果说过去的大模型安全护栏主要关注输入和输出,那么 Agent 安全护栏必须进一步关注“行动过程”。输入内容可能安全,输出内容也可能安全,但中间的工具调用链路可能已经越界。Agent 的风险并不只出现在对话框里,而是出现在它对真实系统产生影响的那一刻。
Agent 安全正在从自动防御走向人机协同治理
这篇论文最有价值的地方,是它提醒我们不要过度迷信“全自动安全”。
在内容安全时代,我们已经习惯了让模型自动判断一段文本是否违规。到了 Agent 时代,这个思路还可以继续用,但远远不够。因为 Agent 不只是生成内容,它会行动;不只是回答问题,它会影响文件、代码、系统、数据和业务流程。
行动一旦进入真实世界,安全就不能只靠模型判断。它需要权限边界,需要运行时审批,需要策略系统,需要隔离环境,需要审计和回滚,也需要用户能够清楚表达自己的真实意图。
所以,Agent 安全的下一阶段,很可能不是简单追求“更强的检测模型”,而是构建一套更完整的人机协同治理体系。
在这个体系里,人不是被动审批机器,模型不是万能安全裁判,策略也不是写完就不变的静态文件。三者需要被重新组织起来:人提供意图,模型降低表达成本,系统执行约束。
这才是 Agent 安全的人类回路。
它不是自动防御的倒退,而是 Agent 进入真实生产环境之后,安全治理必须补上的一层基础设施。
声明:本文来自模安局,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
