AI 写代码已经从一个新鲜功能,变成了很多开发者日常工作流的一部分。
从代码补全、函数生成,到测试编写、Bug 修复,LLM 正在越来越深地进入软件开发流程。
但随之而来的问题也变得更尖锐:这些由模型生成的代码,真的安全吗?它和人类写出的代码相比,到底应该怎么比较?
这听上去像是一个可以直接评测的问题。找一批人类代码,再找一批模型生成的代码,用静态分析工具扫一遍,统计漏洞数量,然后得出结论。
但苏黎世应用科学大学的 Rebecca Balebako 和 Jasmine Egli 在论文《How to Compare the Security of Code Written by Humans to LLM-generated Code》中提醒我们:事情没有这么简单。

https://arxiv.org/pdf/2606.00186
真正困难的地方,不在于跑一次安全扫描,而在于如何设计一个公平、可复现、可审计的比较方法。
论文明确指出,现有研究对 LLM 代码安全性的结论并不一致,一个重要原因是评测方法、任务条件和实验上下文并不统一。
问题不只是“谁更安全”,而是“怎么比较才公平”
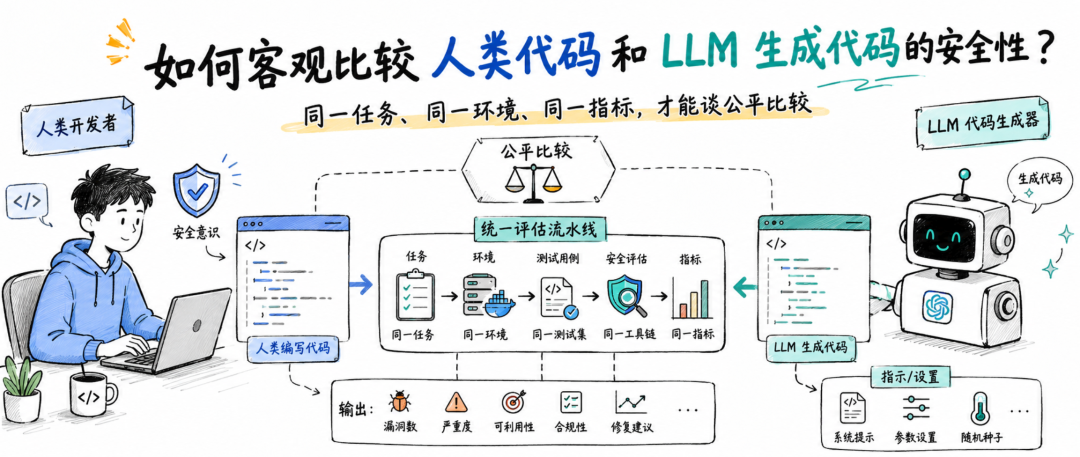
很多人讨论 AI 写代码安全性时,默认把人类代码和 LLM 代码放在一个简单对立面里。
比如,人类代码代表经验、审查和工程习惯;LLM 代码代表速度、自动化和不确定性。然后大家很容易得出一个直觉判断:模型可能会生成不安全代码,所以要谨慎使用。
这个判断当然有现实基础。LLM 生成代码确实可能出现硬编码密钥、不安全随机数、错误的密码学 API、缺少超时设置、输入校验不足等问题。但这篇论文最有价值的地方,是没有急着回答“LLM 到底更安全还是更危险”,而是先追问:我们真的知道自己在比较什么吗?
同样一道编程题,人类可能看到的是完整需求文档,模型看到的却是简化后的函数签名和 docstring;人类可以调试、搜索、查文档,模型可能被要求一次性输出完整代码;模型可能获得了精心设计的 prompt,而人类只拿到了普通自然语言描述。这样的比较看似在比较代码安全性,实际比较的可能是提示词设计、任务约束、工具使用权限和实验流程。
论文借用了一个概念,叫 species-fair comparison。直译是“物种公平比较”,放在这里可以理解为“跨主体公平比较”。也就是说,既然比较对象一边是人类,一边是模型,就必须尽量保证双方面对的是相同任务、相同约束、相同运行环境和相同评价指标。否则,实验结果很可能反映的是评测设计偏差,而不是代码安全能力差异。
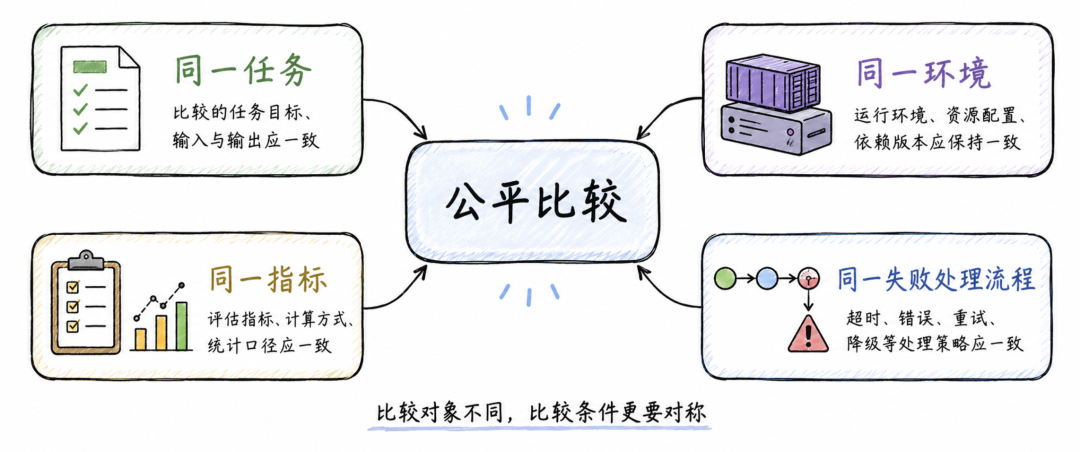
自动化评测流水线
为了把这个问题做得更可操作,论文提出了一套自动化框架,用来比较 human-only、LLM-only 和 human-LLM hybrid 三种代码生成方式。
这套框架的基本逻辑很清楚:
先定义编程任务,然后把同一个任务同时给人类和 LLM;双方输出代码后,形成统一代码数据集;接着在隔离容器中运行代码,判断功能是否正确;只有通过功能测试的代码,才继续进入静态分析阶段;最后从正确性、复杂度、函数长度、安全规则命中等维度生成指标。
论文 Figure 1 展示的就是这条流水线,从 exercise definition 到 prompt LLMs 和 humans,再到 code execution、static code analysis 和最终 metrics。
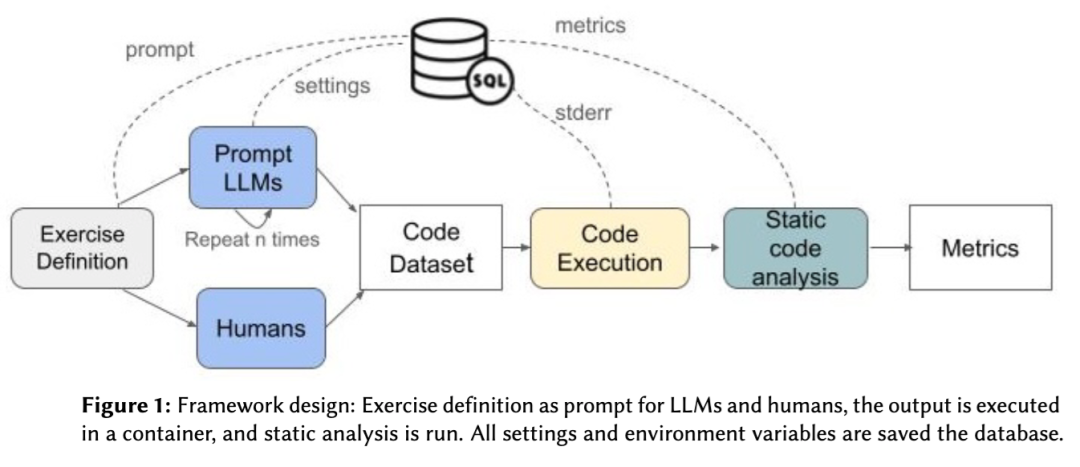
这套流程看起来并不花哨,但它抓住了代码安全评测里最容易被忽视的问题:不能在代码还不能正确运行的时候,就直接评价它安不安全。
一段代码如果语法错误、输入输出格式不对、逻辑结果不对,那么后续安全扫描出来的结论就会很混乱。它可能没有安全问题,只是因为根本没有跑到关键路径;它也可能有安全问题,但功能错误已经让它失去了可比较性。所以论文采用了顺序质量门禁:先看代码是否可执行,再看输出是否正确,最后才看安全和质量指标。
在实现上,论文框架用 Python 编写,运行过程中的 prompt、模型参数、时间戳、输出、错误日志、执行结果和安全分析结果都会写入 SQLite 数据库。LLM 调用时固定 temperature、top_p、max_tokens、frequency penalty、presence penalty 等参数。代码执行则放在 rootless Podman 容器中,用于保证环境一致,并降低执行潜在恶意或畸形代码时对研究环境的影响。
安全不能只看“漏洞数量”
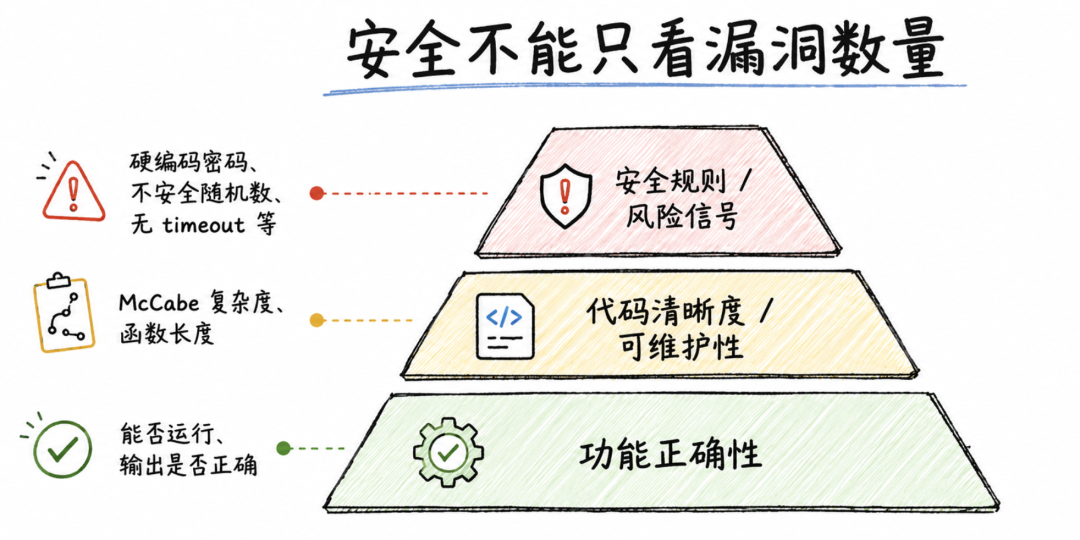
这篇论文还有一个重要判断:代码安全不能被压缩成一个简单分数。
在工程里,很多人喜欢问“这个模型生成的代码安全得几分”。但代码安全是一个多维问题。一个代码片段可能功能正确,但复杂度很高,后期难维护;也可能写得很短,但缺少边界检查;还可能静态扫描没报问题,但业务逻辑上存在权限绕过。
因此,论文把评测指标拆成几类。
首先是正确性,也就是代码能不能运行,能不能得到预定义的正确输出。
其次是清晰度,包括 McCabe 圈复杂度和函数长度。复杂度高不等于一定有漏洞,但复杂度过高往往意味着更多执行路径、更多状态组合和更高维护成本。函数过长也不是漏洞本身,却可能带来状态泄漏、变量复用、逻辑耦合等问题。
论文还使用 Ruff linter 和安全规则来检查代码里的安全气味,例如使用 assert、硬编码密码、requests 调用不设置 timeout、使用非密码学安全随机数、使用 MD5/SHA1 等不安全哈希函数。
这是一种比较克制的安全评测方法。它没有假装能发现所有安全问题,也没有把静态规则命中等同于真实漏洞。它真正做的是建立一条可重复执行的基础流水线,让不同来源的代码至少能在相同规则下被比较。
这对产业评测很有启发。很多企业在评估代码助手时,只看“生成是否成功”或者“开发者是否觉得好用”。但从安全角度看,还应该记录更多过程性指标,比如生成代码的运行失败率、修复轮次、静态扫描结果、复杂度变化、依赖风险、敏感 API 使用情况,以及人类审查后的修改成本。
真正暴露的是评测漏斗
论文做了一个 feasibility study,也就是可行性实验。这个实验不是为了给出最终排名,而是为了验证框架能否支撑这种跨主体公平比较。
实验选择了 13 个 Python 编程任务,来源包括 w3resource 的 Python cybersecurity exercises 和 Advent of Code 2024。这些任务覆盖安全相关练习、算法题、解析任务和数据结构任务。人类代码部分,w3resource 任务使用在线参考解,Advent of Code 任务则从 GitHub 上选取大约 5 个高排名 Python 解。LLM 侧比较了 5 个模型变体:gpt-4.1、gpt-4o-mini、gpt-5.1、gpt-5-mini 和 gpt-5-nano;每个任务和模型组合重复生成 60 次,理论上共有 3900 个 LLM 样本。最终 3832 个样本可以执行,2615 个样本产生了正确输出。论文也明确指出,人类参考代码来自较优公开解,并不代表随机开发者水平。
这个实验最有意思的地方,不是哪个模型赢了,而是它展示了代码评测中的“漏斗效应”。
从模型输出到最终进入安全分析,中间会经历多层筛选。有些输出不是完整代码,只是自然语言解释;有些代码可以执行,但没有标准输出;有些代码能输出结果,但逻辑不正确;还有些代码在运行时触发语法错误、索引错误、递归错误或变量未定义错误。论文把这种层层损耗称为 leaky pipeline,也就是“漏水的评测流水线”。
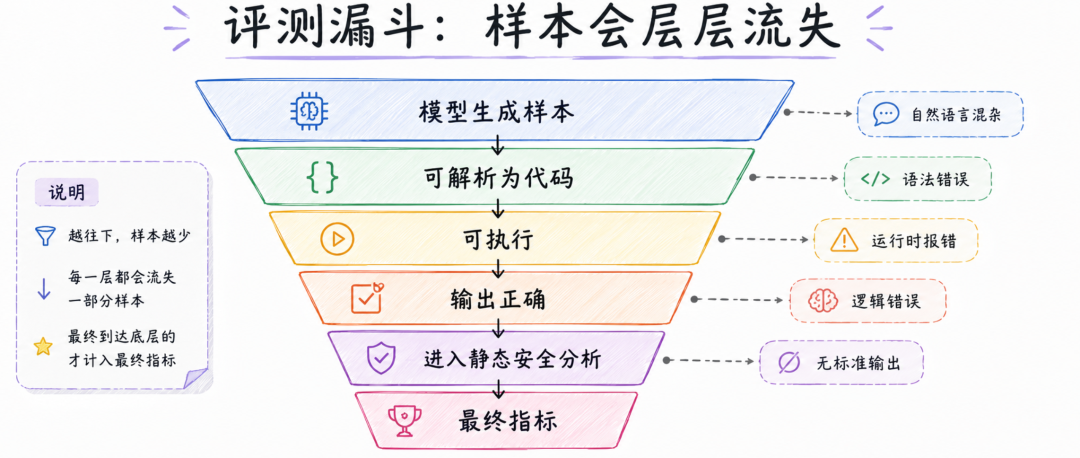
这对代码安全评测非常关键。很多评测报告只呈现最后通过测试的样本,然后在这些样本上统计漏洞。但如果不报告中间损耗,读者就不知道样本池经历了什么。一个模型可能看起来安全问题少,只是因为大量代码在功能阶段已经失败,根本没有进入安全分析。
任务比模型更影响正确性
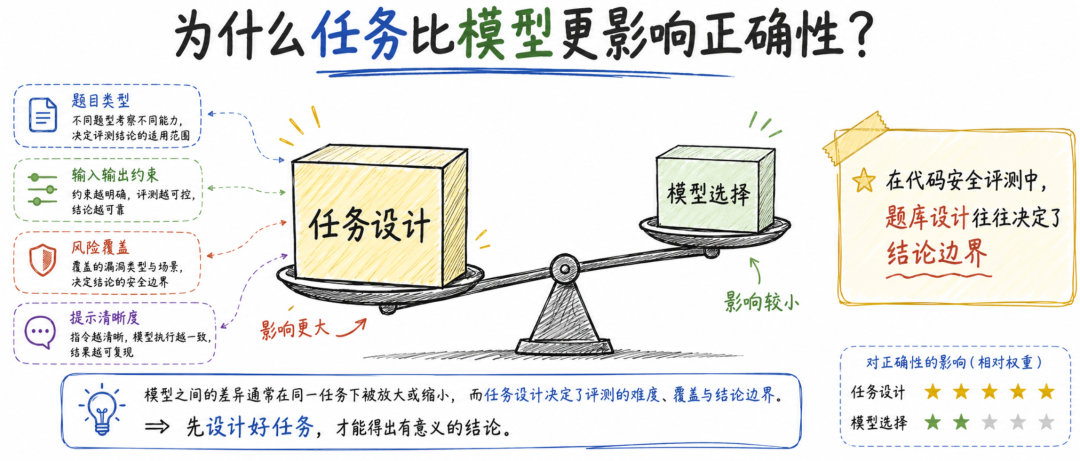
论文中有一个很关键的统计结果:在正确性上,任务本身的影响明显大于模型选择。
作者使用 Binomial GLM 分析正确性,结果显示 Prompt ID 的 Δ Deviance 为 1693.59,而 Model 的 Δ Deviance 为 397.81。简单理解就是,在这个实验设置里,决定代码能不能正确完成任务的首要因素,不是“用哪个模型”,而是“给它什么任务”。
这个结论对 AI 安全评测很重要。
现在很多评测都喜欢做模型排行榜,把模型 A、模型 B、模型 C 放在同一张表里,给出分数高低。但如果题库设计不合理,排名就可能主要反映题库偏差。一个任务如果天然诱导模型使用不安全随机数,那么很多模型都会踩坑;一个任务如果没有明确输入输出格式,模型就可能输出说明文字,而不是可执行程序;一个任务如果依赖隐藏文件或复杂上下文,模型就可能因为环境假设错误而失败。
这意味着,AI 代码安全评测的核心资产不是模型调用接口,而是任务集本身。题目如何设计、是否覆盖不同风险类型、是否区分功能错误和安全错误、是否能复现真实工程场景,都会深刻影响最终结论。
从这个角度看,论文其实是在提醒我们:评测不是把题丢给模型,然后收集答案。评测本身就是一种安全工程。
LLM 的失败,很多时候不是漏洞,而是结构性错误
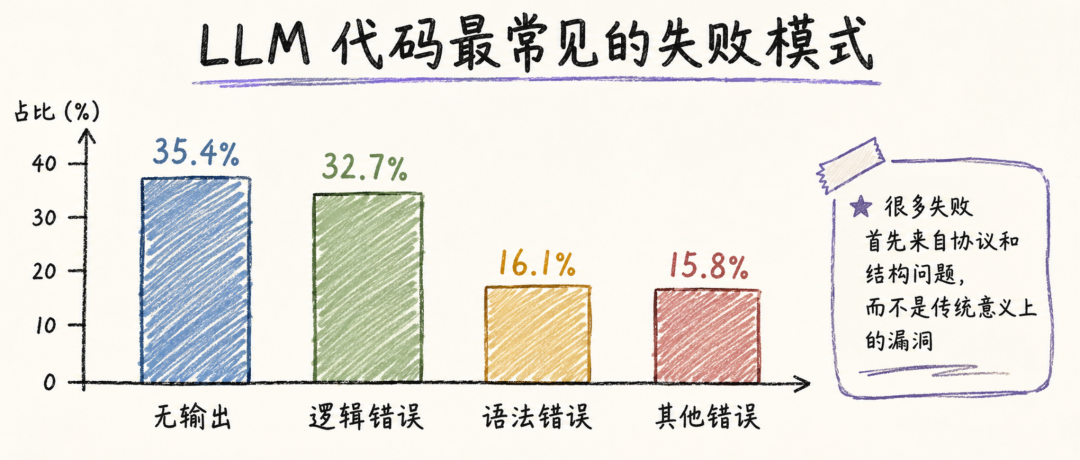
论文对失败类型也做了统计。最常见的问题是 No output,占 35.4%;其次是 WrongLogic,占 32.7%;SyntaxError 占 16.1%。No output 通常不是模型完全不会写代码,而是输入输出处理不符合评测协议,比如假设存在外部文件、等待手动输入、漏掉输入赋值,或者输出自然语言答案而非标准输出。
这个发现很值得注意。
在讨论 LLM 代码安全时,我们往往会直接想到“漏洞”。但从评测流水线看,LLM 生成代码的第一类风险可能更基础:它没有稳定遵守任务协议。对于真实工程来说,这意味着模型生成代码可能在接口约定、输入来源、输出格式、错误处理、环境依赖上出现偏差。
这类问题未必会被安全扫描工具标记为漏洞,却会带来工程风险。比如模型默认读取本地文件,真实部署环境却没有这个文件;模型默认从命令行输入,业务系统实际从 API 参数传入;模型输出解释性文本,调用方却期待 JSON;模型使用外部网络请求,但运行环境不允许访问互联网。这些都不一定是传统意义上的 CWE 漏洞,却足以破坏系统可靠性和安全边界。
所以,LLM 代码安全治理不能只做 SAST 扫描。它还需要检查生成代码是否遵守接口契约、是否符合运行环境、是否引入隐式依赖、是否按预期处理输入输出。
人类代码和模型代码的差异,不能简单归结为高低优劣
在代码清晰度上,论文发现人类参考代码的 McCabe 圈复杂度平均为 2.9,低于所有模型;但人类函数长度平均为 10.7 行,高于部分模型。模型之间也有差异,例如 gpt-5-mini 的 McCabe 平均值为 5.2,gpt-4o-mini 为 3.3;函数长度方面,gpt-5.1 平均为 6.4 行,gpt-5-nano 平均为 13.5 行。
这个结果说明,人类代码和模型代码并不是简单的“谁更好”。它们可能呈现不同风格。
人类高排名参考解往往更有经验感,路径可能更少,逻辑更直接,但函数可能更长。模型代码有时更模块化、更短,有时又会为了处理各种假想边界而引入额外分支,导致复杂度上升。不同模型的代码风格也不一样,有的倾向生成更简洁的解法,有的倾向生成更防御式、更啰嗦的解法。
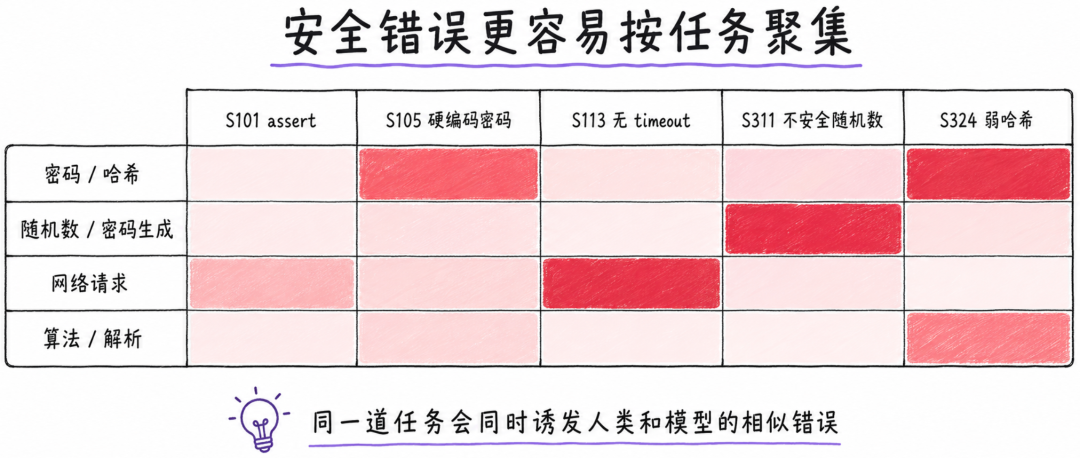
在安全问题上,论文更加谨慎。由于安全规则命中的总体数量较少,作者没有给出强统计结论。但已有数据暗示,安全错误类型更像是按任务聚集,而不是按模型家族聚集。也就是说,同一道任务容易诱发某类安全错误时,人类代码和模型代码都可能出现类似问题。
这点非常重要。很多安全风险并不是“模型独有”的。比如在要求生成密码、哈希、随机数、网络请求的任务中,如果题目没有明确强调安全约束,人类和模型都可能使用默认但不够安全的 API。真正的问题可能不只是模型能力,而是需求描述、开发习惯和默认工程范式本身不够安全。
启发
这篇论文表面上讨论的是人类代码和 LLM 代码的安全比较,实际对企业使用 AI 编程工具有更直接的启发。
今天很多企业正在引入 Copilot、Cursor、代码 Agent 或内部研发助手。但评估这些工具时,常见指标仍然偏向效率,比如补全率、采纳率、节省时间、生成速度。安全指标经常被放在后面,甚至只在代码入库前通过传统 SAST 工具补一遍。
这远远不够。
更合理的做法,是把 AI 编程纳入完整的软件安全治理流程。企业可以构建一套内部评测任务集,覆盖认证鉴权、文件上传、网络请求、数据库查询、密码学使用、敏感信息处理、日志脱敏、异常处理、并发资源管理等典型场景。每个任务都要同时验证功能正确性、接口契约、运行稳定性和安全规则。生成代码不能只看“能不能跑”,还要看它是否引入隐式依赖、是否违反安全基线、是否增加审查负担。
更进一步,评测对象也不应只有 LLM-only。真实开发中,很少有人直接把模型一次性生成的代码原封不动上线。更常见的是人类和模型共同完成代码:模型生成初稿,人类修改;模型解释报错,人类决策;模型补测试,人类 review;模型根据静态扫描结果修复代码。论文提出的 human-only、LLM-only、human-LLM hybrid 三类条件,正好适合企业评估不同开发模式下的安全边界。
对安全团队来说,这意味着代码安全评测要从“扫描代码”升级为“审计生成过程”。不仅要看最后的代码,还要记录任务说明、prompt、模型版本、生成参数、修复轮次、执行日志、扫描结果和人工修改轨迹。这样才能回答更关键的问题:AI 到底在哪些任务上提升效率,在哪些任务上引入风险,在哪些环节必须保留人类审查。
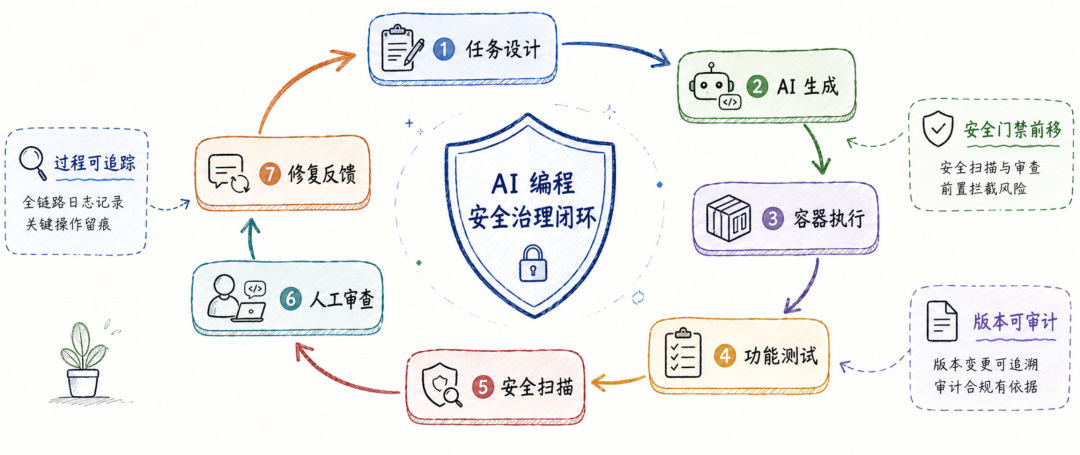
局限性
这篇论文更像是一篇评测方法论论文,而不是最终安全结论论文。
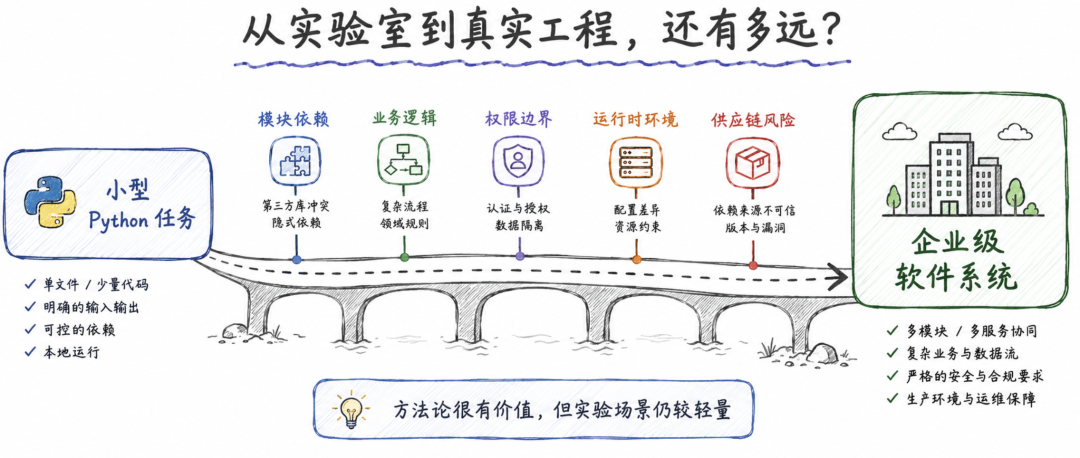
首先,它的实验主要集中在 Python 小型任务上,大多是独立脚本或练习题。真实软件系统里的安全问题,往往发生在跨模块调用、框架配置、权限边界、依赖版本、业务逻辑、数据流转和部署环境中。单文件 Python 任务很适合做可控实验,但距离企业工程代码还有距离。
其次,人类代码来自公开高排名参考解,不代表普通开发者水平。这会让人类样本天然偏强,也无法覆盖真实开发者在时间压力、需求误解、调试过程和工具辅助下的行为差异。论文也明确指出,这些人类代码不是随机开发者分布,主要用于验证框架可行性。
再次,静态安全规则只能捕捉一部分问题。Ruff 和类似工具可以发现一些明确的安全气味,但很难理解业务语义、权限设计、数据敏感性和攻击路径。对于 Agent 代码、云端工具调用代码、插件系统代码来说,更关键的问题可能是工具权限、数据隔离、调用边界和运行时策略,这些超出了普通静态规则的覆盖范围。
最后,“同一个 prompt 给人类和模型”也不必然等于真实公平。人类看到题目时,会自然理解很多隐含语境;模型则可能需要额外提示“只输出代码”“从标准输入读取”“不要解释”“打印标准输出”。如果提示过少,模型吃亏;如果提示过多,模型又可能获得人类没有得到的额外结构化帮助。这种平衡本身就是后续研究需要解决的问题。论文在未来工作中也提到,prompt engineering 必须在“对模型有效”和“对人类可读”之间保持平衡。
写在最后
这篇论文没有给出一个刺激的结论。
它没有说 LLM 代码一定比人类代码危险,也没有说人类代码一定更可靠。它真正想说的是:在我们讨论这些结论之前,先要把比较方法讲清楚。
这是一种更基础、更重要的工作。
当 AI 编程工具进入真实研发流程,代码安全评测不能继续停留在“扫一下有没有漏洞”的层面。我们需要知道代码是怎么生成的,任务是怎么描述的,模型参数是什么,运行环境是否一致,失败样本去了哪里,安全规则是否适配任务,人工审查是否介入,以及不同开发模式下风险如何变化。
换句话说,AI 代码安全不是一个单点问题,而是一套评测和治理体系问题。
未来的软件开发,很可能不再是纯粹的人类写代码,也不会是纯粹的模型写代码,而是人类、模型、工具链、测试系统和安全平台共同组成的新型研发流程。在这个流程里,真正重要的问题不是“AI 会不会写代码”,而是:
它写出的代码,能不能被客观比较、持续审计、稳定治理。
这正是这篇论文的价值所在。
声明:本文来自模安局,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
