
作者:刘艾杉,编辑:金磊
一张简单的涂鸦贴画就能让AI自动驾驶系统产生致命错误乃至车毁人亡!
来自北京航空航天大学(Beihang University)、悉尼大学(University of Sydney)和剑桥大学(University of Cambridge)的一项最新研究成果显示,将一张用打印机简单打印出来的涂鸦贴画贴在路牌上就可以让AI自动驾驶系统完全误分类。
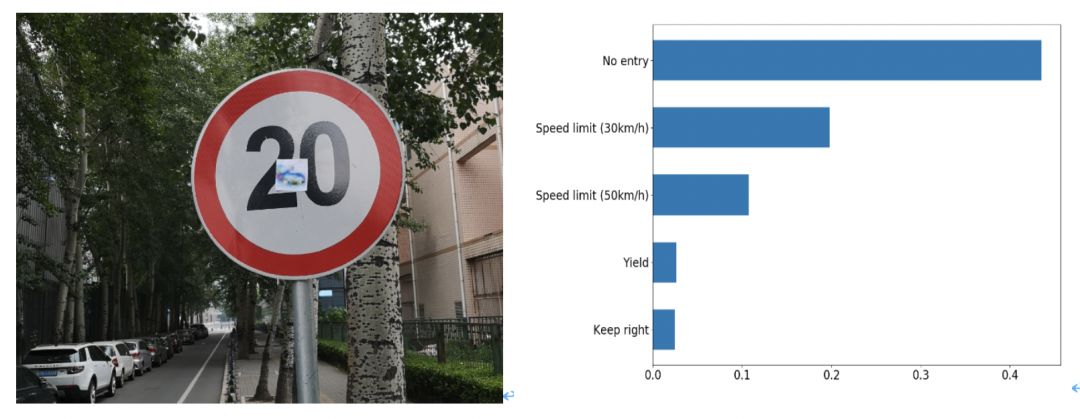
图1 利用对抗补丁在真实世界中攻击自动驾驶系统
如上图所示,将生成的涂鸦贴画贴在北航校园中标为“限速20km/h”的真实路牌上后,AI自动驾驶系统完全被误分类,将其识别为“No Entry”(禁行)。该涂鸦贴画在论文中被称为 “对抗补丁”(adversarial patch),正是这块补丁 “欺骗” 了 AI 自动驾驶系统,让系统将该路牌误分类,在top-5分类中都没有正确标签“限速20km/h”。
该团队发表了题为Perceptual-Sensitive GAN for Generating Adversarial Patches的论文。该论文使用对抗生成网络(GAN)来生成视觉保真度较好且与场景语义相关度较高的对抗补丁(如:路牌和贴画,路牌和涂鸦等),可以在数字世界(digital-world)和物理世界(physical-world)完成对深度学习模型的攻击,目前该论文已在全球人工智能顶级会议AAAI-2019上发表。

论文地址:https://www.aaai.org/Papers/AAAI/2019/AAAI-LiuA.723.pdf
经实验证实,用该方法生成的对抗补丁 (adversarial patch)具有稳定的攻击效果,将其贴在路牌上后,不会影响人类对于路牌语义信息的认知,且由于场景语义相关性人类也不会感觉到“违和”;但是,该对抗补丁对于AI自动驾驶系统则是毁灭性的。例如,这种攻击可能被恶意地用来攻击自动驾驶系统,入侵者只要将一小片贴画贴在路牌上,当自动驾驶汽车驶过时就可能会造成系统的致命错误,导致车祸产生。
使用对抗生成网络(GAN)生成对抗补丁
该论文提出了一种使用对抗生成网络来生成视觉保真度较好且与场景语义相关度较高的对抗补丁的方法(PS-GAN),并且结合系统分类器注意力信息使得补丁的攻击具备稳定性。算法模型提出了一种Patch-to-patch translation的过程,将输入的普通涂鸦图片转换生成为具有攻击性的涂鸦图片。算法的整体架构如下:
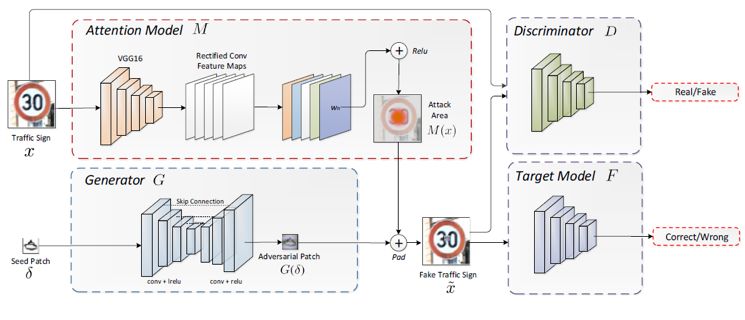
图 2 算法PSGAN架构图
为了达成效果,PSGAN的优化目标包含以下几个部分:
提升视觉保真度和感知相关性
为了提升生成的对抗补丁的视觉保真度,他们引入了GAN损失函数:
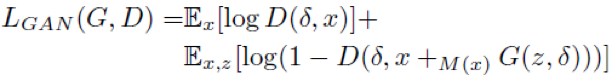
同时,为了保持感知相关性并控制扰动在合适的范围内,他们引入了patch损失函数:
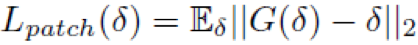
对抗补丁的攻击性
为了使产生的对抗补丁具有攻击性,我们引入了attack损失函数的损失函数:
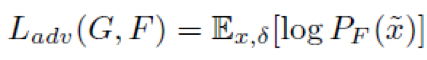
该损失函数的目标是让生成的对抗补丁贴在图片上后,深度学习模型分类器对于该图片的正确类别的预测降低。
整体的优化函数
将整个优化过程转化为对抗生成的极大极小优化过程:

模型的注意力敏感度
为了进一步提升对抗补丁的攻击效果和稳定性,该论文选择让对抗补丁放置在深度学习模型分类敏感的位置。最直观的思路是利用注意力机制(attention & saliency),选择图片中对于模型分类最敏感最重要的区域去放置对抗补丁实施攻击。
实验结果:自动驾驶真的安全吗?
通过实验结果评估 生成的对抗补丁的有效性。主要针对GTSRB和ImageNet数据集进行测试。
视觉效果
图 3 不同算法生成的对抗补丁的视觉效果
通过上图展示可以看出,作者提出的算法(第三行PSGAN)与其他对比算法相比,生成的对抗补丁具有非常好的视觉效果和语义相关性。对比算法生成对抗补丁一般都是比较杂乱的噪音,放置在图片中显得非常突兀;PSGAN生成的对抗补丁视觉效果较好,而且具备较高的语义相关性(如:猩猩与苹果,路牌与涂鸦贴画等)。
攻击效果
为了验证模型生成的对抗补丁的攻击性,论文分别从白盒攻击(white-box)和黑盒攻击(black-box)的角度进行了测试。
在黑盒攻击场景下,算法通过在一种模型上生成对抗补丁并迁移攻击其它模型,可以从下表中看到,由PSGAN产生的对抗补丁具有很好的迁移攻击性。这说明,入侵者可以不用了解目标AI自动驾驶系统所使用的算法模型,只需要使用该算法生成对抗补丁,就可以利用其迁移性实施攻击。
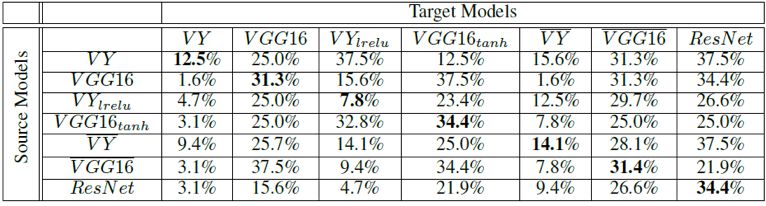
图 4 GTSRB数据集下模型在对抗补丁黑盒攻击场景下的分类准确率
在白盒攻击场景下,算法基于给定的模型生成对抗样本并对该模型实施攻击。生成的对抗补丁在保持较高语义相关性的同时,仍能具备较强的攻击性。
与此同时,研究团队为了验证生成对抗补丁的攻击性不是由于遮盖了目标的关键信息,还使用了普通的 patch 进行了实验。比如他们会使用普通的涂鸦贴画贴在同样的位置,通过结果看到,深度学习模型的分类准确率基本上没有明显的变化,这更证明了生成的对抗补丁的攻击性。

图 5 模型在对抗补丁白盒攻击场景下的分类准确率(ImageNet只选择了部分类别)
最后,为了验证算法生成的对抗补丁的攻击稳定性,论文还对算法训练不同周期时生成的对抗补丁的攻击性的效果进行了测试。如图所示,可以看到PSGAN的攻击性较为稳定,攻击能力持续上升并最终保持稳定;而对比算法产生的对抗补丁的攻击性则不稳定,训练了几百个epoch之后仍会产生较大的波动。
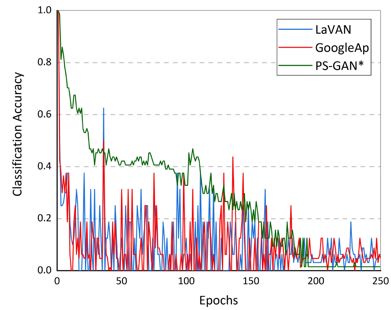
图 6 算法攻击稳定性
真实世界(physical-world)中的攻击性

图 7 真实世界中的攻击
为了验证算法生成的对抗补丁再真实世界中也具有攻击性,论文选择在北京航空航天大学校园中的真实路牌上(限速20km/h)进行验证。作者使用普通的打印机将生成的对抗补丁打印出来,并贴在路牌的合适位置,选择不同距离(1米,3米,5米)和角度(0°,15°,30°,-15°,-30°)拍照并测试深度学习模型的分类结果,其平均分类准确率从86.7%降低至17.2%。人类对于路牌语义信息没有任何误解,也不会对于贴画感到“违和”,但是深度学习模型则产生了致命分类错误。
未来展望
虽然人工智能技术在各个领域都取得了巨大的成功过,但是人工智能安全问题仍不容忽视。近日,清华大学的朱军教授所带领的团队提出了一种基于决策的黑盒攻击方法——演化攻击(Evolutionary Attack)来攻击人脸识别系统[可加链接];比利时鲁汶大学 (KU Leuven) 几位研究人员最近的研究发现,借助一张简单打印出来的对抗补丁,就可以大大降低监控系统对人类的识别率,可以将人隐藏起来。
与此同时,即使AI自动驾驶已经取得了成功并在现实世界中应用,但由北京航空航天大学(Beihang University)、悉尼大学(University of Sydney)和剑桥大学(University of Cambridge)的研究人员提出的算法PSGAN仍可以在黑盒场景下对其系统进行攻击。可以说,这个方法将真实世界自动驾驶存在的安全漏洞极大地暴露了出来。
当然,对抗攻击技术的进步也将催生更多对于模型鲁棒性、稳定性和安全性的研究和发展。未来,如何打造安全、可靠的人工智能系统则显得至关重要。
论文地址:
https://www.aaai.org/Papers/AAAI/2019/AAAI-LiuA.723.pdf
声明:本文来自新智元,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
