作者:wstart@先知社区
0x00 前言
基于设备指纹的风控策略以及应用已经十分的广泛。
但是似乎大部分的文章都是为了产品做了PR又或者简单的介绍了场景
并未提及太多研究的过程,于是在重新造轮子的过程中,
顺便把过程记录一下就有了本文
0x01 设备指纹
设备指纹的采集有很多方式,但是我们主要关注以下几个方向
硬件环境 (cpu型号,主板型号,制造商等...)
硬件运行的环境(充电,电量,罗盘等...)
软件环境(系统版本,组件版本等...)
软件运行的环境(内存,写入速度,运行速度等...)
从4个方向共39个维度进行采集。因为需要兼容GDPR的要求,我们采集信息只有
设备的特征以及运行的状态,通过这两大组的数据组合去判断这个设备是否是
改机或者是场机,以此来对抗黑灰产,所以我们需要申请的权限有且仅一个
READ_PHONE_STATE
0x02 特征工程和建模
虽然只有39维,但是每一个维度都需要进行分析,过程十分的繁杂
但是分析和处理的方法比较传统,基本上最终还是是围绕分桶和独热进行
通过结合数据的特征,把低维的向量展成高维的向量构造出一个巨大的稀疏矩阵供给机器学习
篇幅有限,我们这里只把品牌这个维度单独拎出来做个展开过程的例子
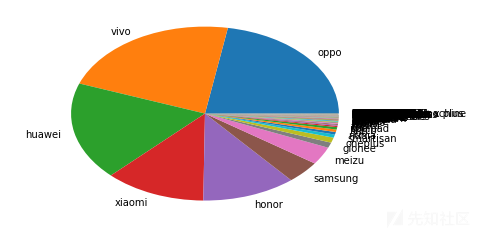
可以看到 ,各大品牌分布的情况
TOP 10的占比情况
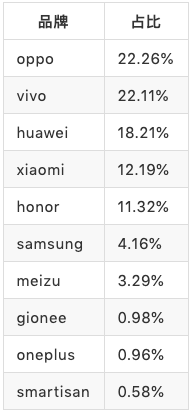
共采集到的品牌数目有1052个品牌,基本上,前10占据了总量的95%左右,
我们以此作做一个置信区间为95%的正态分布来设计一个维度 brand_pop ,
如果落于此区间的,我们把这个值置为1,否的话置为0
我们把不是前10的牌子的数据都看了一遍,这里摘抄一些实例数据
Text(1.1,-0.000515123,"ztev987"),Text(1.1,-0.000513474,"f8"),Text(1.1,-0.000511826,"zte-e3"),Text(1.1,-0.000510177,"f8909"),Text(1.1,-0.000508529,"f8919"),Text(1.1,-0.000506881,"定制版"),Text(1.1,-0.000505232,"小米mix"),Text(1.1,-0.000503584,"desay"),Text(1.1,-0.000501935,"翼触"),Text(1.1,-0.000500287,"鱿鱼客"),Text(1.1,-0.000498639,"dostyle"),Text(1.1,-0.00049699,"韩众"),Text(1.1,-0.000495342,"青葱metal"),Text(1.1,-0.000493694,"长虹"),Text(1.1,-0.000492045,"迪美"),Text(1.1,-0.000490397,"谷歌"),Text(1.1,-0.000488748,"dow"),Text(1.1,-0.0004871,"e6"),Text(1.1,-0.000485452,"苹果"),Text(1.1,-0.000483803,"e889"),Text(1.1,-0.000482155,"美沃"),Text(1.1,-0.000480507,"建议该项值修改为 oppo"),Text(1.1,-0.000478858,"纽麦"),Text(1.1,-0.00047721,"e9003"),Text(1.1,-0.000475561,"diskon"),Text(1.1,-0.000473913,"王者"),Text(1.1,-0.000472265,"eamey"),Text(1.1,-0.000470616,"火米"),Text(1.1,-0.000468968,"detel"),Text(1.1,-0.00046732,"智先锋"),Text(1.1,-0.000465671,"edward"),Text(1.1,-0.000464023,"惠普"),Text(1.1,-0.000462374,"恒语"),
这里看到一个有意思的,"建议该项值修改为 oppo"
不知道是灰黑产喜欢伪装成vivo,oppo,还是说伪装成 oppo和vivo更容易过关,
于是翻回了原始记录进行查看,发现该设备的型号是 OPPO R11s 可农药多线程
查看其他信息后,发现是一台真实的机器,不过为了更流畅的玩王者荣耀,改成了 OPPO R11s
不过可以看到,大部分的中文的机器基本都是改过的机器,
依据此,我们再造一个特征 brand_zh,包含中文的,这个值是1,不包含的是0,
另外在品牌这个字段,大部分的牌子都是没有空格或者是特殊字符的
所以根据这个我们再造一个特征 brand_symble ,计算空格或者特殊字符的个数,
另外品牌的长度 brand_len 也是一个比较重要的特征,直接计算牌子的长度
所以,最终brand这个字段,我们造出了4个特征
brand_pop
brand_zh
brand_symble
brand_len
通过对39个维度的由低维展开到200多个维的一个过程,最终把所有的维度全部数值化,方便机器学习建模和训练的多维向量
0x03 建模
一开始想用有监督的学习进行训练,即先人工进行打标后再进行训练和学习
但是由于数据量太大,标注和训练太耗费时间,于是想先尝试直接使用无监督的学习聚类算法。
常见的聚类算法有三种
分散性聚类(kmeans)
结构性聚类(层次聚类AGNES)
密度聚类(DBSCAN)
通过这三种的聚类算法加权求平均来推算最终的分类情况,我们发现也可以获得比较好的效果
由于算法都比较简单,这里只摘取我们使用kmeans的算法过程来进行介绍
使用kmeans非常简单,借助sklearn后两步即可训练完成
estimator = KMeans(n_clusters=2,) #设定分类数量estimator.fit(X) #训练
但是这样子的效果非常不好,我们需要调参数才可以更加方便的进行处理
具体的参数说明
http://scikit-learn.org/stable/modules/generated/sklearn.cluster.KMeans.html#sklearn.cluster.KMeans
比较重要的参数有
random_state 这个是控制随机种子的参数,为了让实验的变量是可控的,我们这边随机设置了一个整数
n_init:这个是计算初始化质心的计算次数,默认是10,但是我们可以稍微调大一点,来获取更好的质心来进行分类
max_iter:默认是300,
tol: 与inertia结合来确定收敛条件,默认值= 1e-4
比较重要的属性有:
labels_ : 各个标签的预估值
inertia_ : 每个点到其簇的质心的距离之和 越小越好
建模代码
from sklearn.cluster import KMeansX = trandata.values #聚类数据estimator = KMeans(n_clusters=2,n_init=100,random_state=1,n_jobs=-1,max_iter=300,tol=0.0001) #构造聚类器estimator.fit(X) #聚类label_pred = estimator.labels_ #获取聚类标签#获取k-means结果x0 = X[label_pred == 0]x1 = X[label_pred == 1]
0x04 评估
评估的分类的方式有很多, 这里我们采用 F1-Score 去评判
F1 同时评估了 召回率和精准率 ,代码如下
from sklearn.metrics import classification_report,precision_score,f1_score##表示真实的情况act_y = all_data["act_y"].values##表示预测后的值pred_y = all_data["pred_y"].valuesf1_score(act_y, pred_y, average="macro")
在未进行任何优化之前 F1的得分 0.509422680896571
通过调整参数和优化特征后 ,最后的F1得分 0.768547163906923
虽然还是差强人意的分数,离我们预期的0.95以上的分数还是差一大截
不过没关系,这是我们第一个模型,我们还有其他两个模型一起协同计算分数
最终我们的计算公式是
Score = (y1*f1_1 + y2*f1_2+y3*f1_3)/3这里的y1,y2,y3 分别是各自聚类算法中算当前预估的点到核心的距离的一个scale后的值
通过三个聚类的模型进行融合后,我们从数据里筛选出近 0.0265 左右的异常手机,但是
这里的数值依旧感觉是偏高,模型无法投入实际生产环境,不过依据这 0.0265 的异常手机的量,
我们拿到了非常多异常特征的值,启发了设备指纹的采集方向和思路,重新设计了设备指纹
把39维的采集维度扩增到80维,待重新采集一段时间后,再使用算法进行对设备指纹的数据重新建模
0x05 总结
尽管在有数据的情况下,想着可以一步到位通过机器学习来建立一个比较好的模型,但实际上可能还是经验和特征不够的问题,导致建模的结果并不是特别的好,不过好在模型筛选出来的数据都比较有代表性,提供了设备指纹一些设计思路和方向,对于后续重新建模提供了基础的模板和方向。
这里提出一个我们在建模中遇到一个问题:
如果你用机器算法学习去识别异常机器,假设黑产也用GAN去模拟真实机器,那么,如何识别这些通过GAN生成出来的真实机器呢?
声明:本文来自阿里安全响应中心,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
