摘要:针对Android 恶意应用泄露用户隐私以及造成财产损失等问题,提出了一种基于随机森林的恶意应用检测模型。通过批量反向Android 应用,依据函数调用图获取其实际使用权限组合,建立应用特征向量库,结合常用的朴素贝叶斯、K- 近邻以及随机森林等不同学习方法,建立不同方法的Android 恶意应用检测模型。实验结果表明,基于随机森林的检测模型对应用的识别准确性更高,准确率达90% 以上。同已有研究相比,具有代价低、准确性高、普适性好等特点。

0 引言
近年来,智能手机迎来爆发式的增长,极大方便了人们的生活,成为不可或缺的生活必需品。当前市场主流的智能手机操作系统为iOS 以及Android 系统。据2017 年年末统计,Android系统的市场占有率为86.1%,而iOS 的市场占有率约13.2%。由于Android 手机操作系统的开放开源特性,吸引了越来越多的应用程序开发人员,其应用程序种类以及数量都呈现出爆发式的增长,但是同时也成为恶意应用的聚集区。恶意应用程序通过盗取用户隐私信息或者植入恶意代码等方式攻击用户,造成用户隐私泄露与财产损失。因此,控制检测恶意应用的影响意义十分巨大,对Android 恶意应用的检测方法研究成为当前研究热点之一。
针对上述问题,本文提出了一种基于随机森林方法的Android 恶意应用检测方法模型,通过反向等手段获取应用程序的实际调用权限,并利用上述获取到的系统权限及其组合权限等作为待检测应用特征,通过使用朴素贝叶斯方法、K- 近邻方法以及随机森林方法等算法学习恶意应用的特性,构建针对恶意应用的分类器,对比分析不同的方法分类器的优劣。
本文剩余部分将按照如下形式组织。第一部分充分调研当前针对恶意应用检测的国内外研究现状,第二部分介绍本文采用的关键算法与技术,第三部分进行分类器构建过程的详细设计与实验,第四部分对分类器检测效果分析对比,并对实验分类结果进行系统分析。最后总结本文并对未来研究方向进行展望。
1 国内外研究现状
当前对Android 恶意代码的检测方式主要包括基于特征码匹配的方式以及基于行为的方式。其中,基于特征码的检测方式需要将待测应用的特征码去匹配恶意应用特征码库,根据匹配的情况来判断是否是恶意应用。该种方式需要维护一个巨大的特征库,维护成本高,因此,通常只有360 等安全企业通过恶意特征库来鉴别一个应用是否为恶意应用。基于行为的检测方式又分为静态检测方式与动态检测方式,依靠学习恶意应用的静态特性与动态行为来判断待检应用是否为恶意应用。这种方式可以检测未知恶意应用,并且不需要维护特征库。静态检测方式可以通过解析源码获取特征来检测应用,无需运行应用,效率极高。而动态检测则通过检测应用运行时的行为特征来判断应用类别,该种方式检测效率较低且行为特征获取的难度较大。
虽然该研究领域研究时间不长,但国内外已经存在众多针对恶意应用检测的研究成果。针对恶意代码的不同特性,Schultz 等人提出使用多种分类算法识别恶意应用的基础理论,开创了数据挖掘技术用于恶意应用检测的先河。在此基础上,Liu 等人提出了一种基于SVM 的Android 恶意应用检测方法,将应用的Manifest文件分析作为特征,使用SVM 算法对应用进行分类识别,取得了较高的识别准确率,但是对具有组合恶意特征的应用识别率较低;Akanksha Sharma 等人通过分析应用程序的非正常API 调用,提出了一种基于敏感API 的检测模型,该方法从敏感API 的角度判断恶意应用,准确率不高。
国内对该领域的研究起步较晚,但是也取得了很多研究成果。杨欢等人提出了一种结合静态分析与动态特征的多特征的恶意代码检测方法,设计了一个三层混合综合算法分类器来评判Android 应用恶意行为,该方法检测精度较高,但是由于提取动态特征时的代价高,且不能识别新恶意特征组合;王菲飞使用恶意代码特征值匹配的方式实现了Android 恶意应用的检测,其识别的准确性依赖于特征码库的丰富性与多样性;邵舒迪提出了基于权限和API 特征结合的Android 恶意软件检测方法,将APK 文件的权限作为特征,通过决策树分类法实现了恶意软件的甄别检测,针对具有单一恶意特征及敏感API 的应用,检测准确率达90%;刘智伟等人通过对应用执行过程中统计调用的API 资源进行相应的权限检查,通过监控应用是否连续调用敏感API 来判断应用是否为恶意应用,该方式检测速度慢且容易出现误判的情况。
已有的检测研究方法大都基于敏感权限、API 调用、特征码等应用特性,通过分类来实现恶意应用检测研究。但是这些研究具有检测速度慢、代价高,针对具有单一明显敏感权限、API 的恶意应用识别准确率高但对常规权限组合产生危险权限的恶意应用检测准率不高等问题。因此,本文在上述研究的基础上,采用易于采集应用权限及其组合作为特性,通过多种机器学习方法进行学习分类,选择检测兼具高精度与快速的机器学习方法,以充分利用应用的静态特性来提升检测判别准确率与速度。
2 恶意应用检测关键算法技术
获取恶意应用程序的关键特性是判断程序是否为恶意应用的基础,而其中对权限的滥用最能直观地反应程序是否为恶意应用。本节将说明如何获取应用的上述特性以及检测判别方法。
2.1 基于权限检测原理及权限获取技术
通常,Android 系统权限安全级别分为四级:正常、危险、签名以及系统。Android 操作系统对上述四种权限分别采用了不同的认证方式,在应用的Manifest.xml 文件中进行配置声明。“正常”权限只需要在声明即可使用,“危险”权限则需要用户人工确认,“签名”以及“系统”权限则需要系统的ROOT 管理员权限。为了有效保护系统安全以及用户隐私等,良性应用不会主动申请“危险”“系统”权限,而恶意应用为达到入侵用户隐私等目的,则需要上述权限。因此,可以依据应用程序所申请的权限的种类来评估其恶意性。
单个危险权限:直接申请此类权限代表应用程序具有非常高的危险性,因此,应用程序基本都不会单独申请该类权限。表1 总结了Android 系统中的单一危险权限,这类权限均属于“危险”“签名”以及“系统”级别的权限。
表1 Android 系统的危险权限表

恶意应用使用此类权限则极容易被发现,因此,恶意应用为了规避系统自身检测很少去直接申请这类敏感危险权限。因此,恶意应用通过申请大量的常规权限,那么通过组合这些常规权限,实现恶意操作的可能性就更高,形成对用户Android 系统的攻击。通过来自某移动应用安全平台的数据,分析了几组多个权限危险组合,如下表2 所示。
表2 Android 系统多个权限的危险组合示例表

表2 中的权限组合可以实现对Android 系统的攻击,同系统核心权限相比,每组危险组合权限具有常规的权限组成,例如接收/ 发送短信等,具有隐蔽性的特征;但是相比良性应用,恶意应用通常申请更多的敏感权限。由于Android系统开放开源特性,为了方便程序的开发与维护,经常会出现过度声明大量权限的情况,这对于基于权限的恶意程序检测造成了一定的难度。因此,在已有的基于权限的恶意应用判别研究基础之上,通过对APK 文件进行逆向,以Manifest.xml 文件中声明的组件为起始搜索点,建立对应的函数调用图,并依据构建的Psout 提供的API- 权限映射库,找出应用程序实际使用的权限组合,有效避免了过度声明权限对恶意应用判定产生的影响。
2.2 分类器学习方法
恶意程序的检测识别属于数据分类问题。问题的解决需要两步过程:第一步, 建立一个模型,描述预先的数据集或概念集。通过分析由属性描述的样本(或实例、对象等)来构造模型,而模型的构造需要一定算法来进行学习。目前机器学习方法种类较多,不同的机器学习算法具有不同的特点,因此,本文基于已有研究所采用的方法,分别使用朴素贝叶斯算法、KNN算法以及随机森林方法对恶意应用的特征进行学习检测。
2.2.1 朴素贝叶斯算法
朴素贝叶斯方法(Naive Bayesian Model,NBC)是一种构建分类器的简单方法。首先利用训练数据集来构造一棵决策树,一旦树建立起来,它就可为未知样本产生一个分类。在分类问题中使用决策树模型有很多优点,决策树便于使用,而且高效;根据决策树可以很容易地构造出规则,而规则通常易于解释和理解;决策树模型的另外一大优点就是可以对有许多属性的数据集构造决策树。
构建的分类器模型会依据属性值判断测试样本的类别概率,并给出概率最大的类标签。朴素贝叶斯的优势在于只需要少量的训练数据便可以估计出必要的参数。对于一个分类问题,给定样本的特征向量x,那么在样本类别属于y的概率如公式(1) 所示。

2.2.2 KNN 算法
KNN(k-Nearest Neighbor,K 近邻) 算法是通过测量不同特征值之间距离进行分类。其基本思路是:如果一个样本在特征空间中的k 个最相似( 即特征空间中最邻近) 的样本中的大多数属于某一个类别,则该样本也属于这个类别,其中k 通常是不大于20 的整数。KNN 算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。在KNN 中,通过计算对象间距离来作为各个对象之间的非相似性指标,避免了对象之间的匹配问题,在这里距离一般使用欧氏距离或曼哈顿距离,如公式(3)(4) 所示。
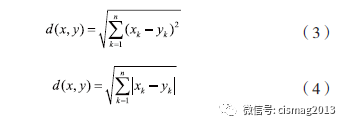
此外,KNN 算法通过依据k 个对象中占优的类别进行决策,而不是单一的对象类别决策。其算法可以描述为:①计算测试数据与各个训练数据之间的距离;②按照距离的递增关系进行排序;③ 选取距离最小的K 个点;④确定前K 个点所在类别的出现频率;⑤返回前K 个点中出现频率最高的类别作为测试数据的预测分类。
2.2.3 随机森林算法
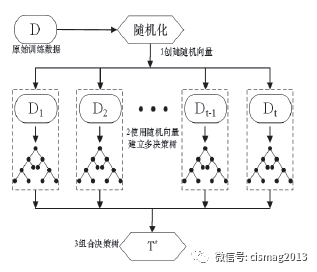
随机森林算法(Random Forest,简称RF) 是一种拥有广泛的应用前景的分类算法,从市场营销到医疗保健保险,既可以用来做市场营销模拟的建模,统计客户来源,保留和流失,也可用来预测疾病的风险和病患者的易感性。随机森林分类器构建依据自助法(bootstrap)重采样技术,通过从原始训练样本集S 中随机有放回的重复选取k 个样本大小为的子样本集合,然后根据上述的自助样本集合来建立k 棵分类树,这些分类树在一起组成具有分类回归能力的随机森林。其中,测试样本的输出结果取决于k 棵分类树每种分类结果比例的大小。随机森林回归本质上是决策树回归算法的改进,每棵决策树由一个独立抽取的样本子集合建立,并且每棵决策树具有相同的分布,误差由所有决策树的分类回归能力与它们之间的相关性决定。在分裂节点时,随机选择特征并比较不同特征下的分裂误差,选择误差最小的特征作为节点分裂特征。一棵决策树的分类回归能力有限,但随机产生大量决策树后,测试样本可以通过每一个树的分类回归结果统计后选择比例最大的结果作为输出值。图1 为一个典型的随机森林原理图。
图1 随机森林原理图
3 检测模型设计与实验
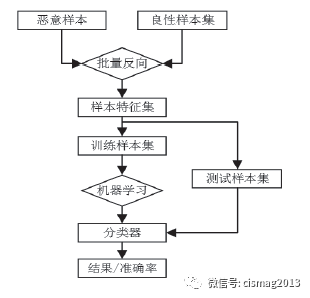
本文设计的基于应用特征的检测方法流程如图2 所示,分类模型的构建过程主要分为三步:第一步通过批量对应用程序APK 文件进行逆向工程,建立每个程序的函数调用图,并依据所构建的Psout 提供的API- 权限映射库,找出应用程序实际使用的权限组合,作为应用程序的特征数据,形成样本数据集合;第二步对获取的数据进行预处理之后,将数据集分为训练集与测试集,将训练集合使用不同的机器学习方法训练构建分类模型;最后使用测试集合检验分类模型的准确性。
图2 Android 恶意应用检测器构建测试流程图
3.1 样本特征集合的构建
为了保证应用程序样本的随机性与真实性,本文从VirusShare 安全网站恶意应用库以及360 安全应用商店分别下载恶意应用集合( 包含600 个样本) 以及良性应用集合( 包含1400个样本) 作为样本应用程序。分别对两组样本使用反编译工具apktool[15] 的aapt 命令进行批量反编译和自写脚本app_feature_out.py ( 依据Manifest.xml 建立权限调用追踪图,并结合Psout 输出实际调用权限) 输出应用程序样本的权限组合,分别得到恶意样本特征集合与良性样本特征集合。
3.2 样本集合的预处理与分类器学习
在进行分类器的学习之前,需要预先对样本的特征进行数据化形式处理。通常以是否具有某个权限为基本单位,单个应用样本特征向量如下所示。

通过随机工具将良性应用特征集合与恶意应用特征集合随机混洗,得到一组样本特征集合。如图2 所示,在构建不同类型的分类器时,使用交叉验证的方法来验证分类器的准确性,因此需选择大约4/5 样本(1600条) 作为训练样本,剩余1/5 样本(400 条) 作为测试样本。
3.3 不同方法分类器性能的对比与分析
本文使用分类准确率Accuracy, 真正率TPR以及真负率FPR 来作为分类器的评价指标,公式分别如下(5)~(7) 所示。

其中,TP 是测试样本中能够正确分类的良性样本数量;TN 是测试样本中正确分类的恶意样本的数量;FN 是测试样本中误分类为恶意样本的良性样本数量;FP 是测试样本中误被分类为良性样本的恶意样本。
将训练样本集合(1600 条数据) 分别使用朴素贝斯分类算法、KNN 算法以及随机森林方法进行学习。本文使用Python 以及相关工具包实现了三种算法的学习程序,并使用训练集合学习构建了三种不同的分类器,下表3 及图3 是朴素贝叶斯、KNN 以及随机森林训练方法分类器对训练集合的分类效果( 即学习拟合的效果)。
表3 不同机器学习方法训练效果表
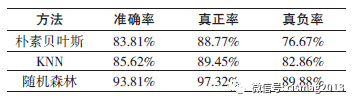
图3 不同学习方法下的训练效果图
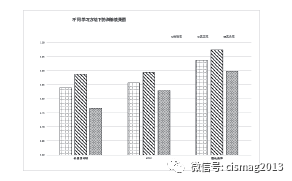
从图3 以及表3 可以看出,已有研究采用的朴素贝叶斯方法、K 近邻算法以及随机森林算法均具有较好的分类准确率,分类准确率可达80% 以上。而三种分类器中,基于随机森林的分类器效果最佳,其整体训练分类准确率、真正率以及真负率指标均高于其他方法构建的分类器效果。从表3 可以看出,良性样本的分类正确率普遍高于恶意样本的分类正确率,其原因可能有两点:一是训练样本中的良性样本的数量远大于恶意样本,因此分类器将“偏好”良性样本;二是某些特殊恶意应用程序样本能够“躲避”静态特征的检测,导致恶意样本的分类正确率偏低。
4 实验结果分析
上文中通过多种不同机器学习方法建立了不同的分类模型,其中随机森林分类器优于其他学习方法的分类器。在训练集合中,其整体分类准确率分别比朴素贝叶斯方法以及KNN 方法高10% 及7%。因此,需要进一步验证并分析上文建立的随机森林分类器的准确性与适用性。
4.1 测试集合上分类准确率验证
为充分验随机森林分类模型的准确性,实验采用5 倍交叉验证的方法,使用剩余的400 条特征样本来验证模型的准确性与适用性。表4 是测试集在随机森林分类器下的分类结果统计。
表4 测试样本集在随机森林分类器下分类表
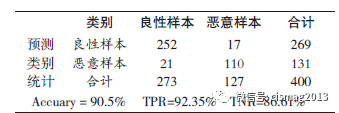
从表4 可以看出,在测试样本集(400 条数据)下,基于随机森林的恶意应用分类器的检测准确率超过90%,略微低于其在训练集合上的分类效果,说明该分类器可以有效地对应用程序类型进行检测,进一步验证了所构建的分类器的有效性。造成在测试集合上分类精准度、TPR以及TNR 精度略低于在训练集分类精度的原因有两点:一是在训练样本集合上会针对训练样本不断反复训练;二是受限于数据规模集合限制,在有限的数据集合下,训练集合与测试集合的分布可能存在一定的差异,在训练集合上分类精度通常均比测试样本分类精度高。
4.2 检测模型中应用特征重要性分析
由于基于随机森林方法的分类器是由大量的分类决策树组合而成,其通过“森林”中的分类树进行投票选择进行分类。在本文中的分类器中,主要由以下两类决策树组成,如下图4所示。
图4 恶意应用检测分类器中的两种分类树:(a) 非系统权限组合下的判别分类树 (b) 危险权限下的判别树
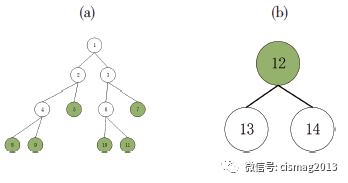
本文的分类器中大部分的决策树属于(a) 类型,即通过对非系统权限组合的决策来判别应用的类型。实验结果表明,表1 中所列举的系统危险权限,在所有样本集合中仅存在8 个应用(0.8%) 拥有直接调用该类系统的权限,且均为恶意应用,进一步表明当前的大部分恶意应用的隐蔽性,通过调用多种非系统权限的常规权限组合来实现恶意攻击的目的,并且同时保持隐蔽性以防止被常规检测方法识别。表5 统计了训练测试集合中最常用的权限组合情况下,判断该应用是否为恶意应用的置信度。
表5 恶意应用常用权限组合置信度统计
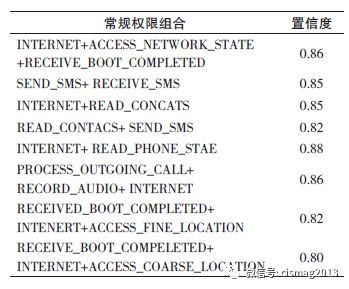
在表5 中的每种非系统权限组合情况下,若某应用具备该权限组合,其属于恶意应用的概率达80% 以上,进一步说明这些权限组合的危险性。从表5 中看出,INTERNET 权限几乎出现在每一项权限组合中,因此,可以在关联分析时将其去除, 突出READ_CONTACTS、SEND_SMS/RECV_SMS 等敏感非系统权限在检测过程中的重要性,以提升随机森林检测模型的检测准确度。
同已有研究相比,该方法在已有研究的基础上,同使用动态执行特征的监测方法相比,对恶意应用的检测准确率没有降低的情况下,降低了恶意应用检测代价;同时,与仅利用权限特征的检测方法相比,该方法提升了检测准确率(90%) 且更具普适性( 可检测常规权限组合形成的恶意权限)。
5 结语
针对Android 恶意应用造成严重隐私泄露与财产损失的普遍问题,在已有研究的基础之上,本文提出并实现了基于随机森林的Android 恶意应用检测模型,可有效地判别应用的类别。该检测模型基于应用的静态特征,以实际使用权限作为特征,采用随机森林学习方法,实现对Android 应用快速低成本判别。但是,由于某些恶意应用可规避静态特征检测,而动态特征检测速度慢代价高,因此,未来将探索如何构建Android 应用的全面有效的特征向量,以进一步提升检测模型的准确率与适用性。
(为便于排版,已省去原文注释)
作者:孙强强,研究生,工程师,主要研究方向为网络安全研究与管理。
(本文选自《信息安全与通信保密》2019年第六期)
声明:本文来自信息安全与通信保密杂志社,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
