论文作者:郭夏玮、姚权铭、James T.Kwok、涂威威、陈雨强、戴文渊、杨强
论文:Privacy-preserving Stacking with Application to Cross-organizational Diabetes Prediction
论文地址:https://arxiv.org/pdf/1811.09491.pdf
人工智能顶会 IJCAI 2019将于8月份在澳门举行,此前其就已经公布了接收论文列表。今年IJCAI接收了850篇论文,接受率只有17.9%。在被IJCAI 2019接收的这篇论文中,来自香港科技大学、第四范式的研究者提出了一种隐私学习算法。在严格遵守数据隐私保护条例下,该模型能在跨机构的数据上高效学习。
该论文的作者之一,国际人工智能学会理事长、香港科技大学杨强教授将出席市北·GMIS 2019并做出主旨演讲,他将介绍更多关于联邦学习与数据隐私方面的前沿研究。
关注跨机构数据的隐私保护
随着越来越多的用户数据被收集,数据隐私(Data Privacy)问题获得越来越多的关注,特别是在近年来一系列相关事件发生后 Facebook 隐私泄露、GDPR 隐私保护法律等。
第四范式的研究者提出一种新的隐私学习的方法,该方法的思想是基于集成学习(ensemble learning)减轻噪声对于学习效果的影响,它的有效性同时在跨机构的糖尿病预测问题上得到了验证。如下第四范式的研究者将向大家介绍这篇 IJCAI 2019 论文。
典型应用场景
带隐私保护的机器应用场景很多,例如推荐系统和人脸识别,在本文中我们着重关注跨机构的糖尿病预测问题。
糖尿病已经成为现代人类的最大潜在杀手,主要在于糖尿病等慢性病早期知晓率与控制率处于较低的水平。因此我们选择该场景切入,使系统从大医院中迁移出有用的知识(同时带隐私保护),去帮助小医院更好的做医疗诊断(例如糖尿病预测)。如 Figure 1 中所示。
已有隐私保护方法在以上应用中包含三个方面的问题
隐私保护的机器学习方法,预测性能较差
暂时没有迁移学习方法带隐私保护
糖尿病预测的特征有不同的重要性,例如饭后一小时血糖的重要性高于身高
我们提出的方法能用在以上糖尿病预测的问题中,并且同时解决以上三个方向的局限性。
差分隐私 - 机器学习中的隐私保护
机器模型的训练涉及到大量用户数据的使用,这些数据都可能包含敏感信息。传统的做法是对数据的敏感列作匿名化 (anonymization)。但是这样并不能完全保护数据隐私,攻击者可以通过查表等方法反推原数据。对于隐私的保护,差分隐私 (Differential privacy) 定义 [Dwork et al., 2006] 被提出,其定义如下:

在上述定义中,t 可以是统计量、模型等。直观上来说,差分隐私的定义要求了输出结果的分布的变化受随着输入数据的变化的影响比较小,受 ϵ 控制。ϵ 越小,则输入变化对输出影响越小。从用户角度考虑,其数据作为样本是否加入训练对结果影响越小,隐私也越不可能泄露。
在机器学习问题上,M 为学习算法,而输出 t 则是输出的模型,输入 D_1、D_2 则是用来训练的数据集。
目前已有差分隐私机器学习算法上的工作,往往是通过往训练过程内注入噪声来实现差分隐私。常见的有三种:目标函数扰动(objective perturbation)、输出扰动 (output perturbation)、梯度扰动 (gradient perturbation)。其中,logistic regression 有成熟的差分隐私算法,以及隐私保护和学习效果上的理论保障。
然而就目前的方法以及对应的理论来看,在保证固定的 ϵ 情况下,数据维度越大,需要注入的噪声强度越大,从而对算法效果造成严重负面影响。
我们的方法
我们的工作主要在于改善上述的问题。基于以往 stacking 集成学习方法 [Wolpert, 1992] 的成效,我们将 stacking 方法与差分隐私 logistic regression 相结合。Stacking 需要将数据按照样本分成数份。我们提出了基于样本和基于特征切分的两种 stacking 带隐私保护的 logistic regression 算法。
在该算法中,数据按样本被分成两份,其中一份按特征或按样本分割后在隐私保护的约束下训练 K 个子模型,并在第二份上通过差分隐私 logistic regression 进行融合。
我们证明了在保障 ϵ- 差分隐私的情况下,按特征切分相比过去的算法和按样本切分算法有更低的泛化误差。同时,按特征切分有另一个优势,如果知道特征重要性,我们的差分隐私算法可以将其编入算法中,从而使得重要的特征被扰动的更少,在保持整体的隐私保护不变的情况下,可以得到更好的效果。
此外,我们的方法可以直接拓展到迁移学习上。即在源数据集上按照特征切分后得到带隐私保护的模型,通过模型迁移,迁移到目标数据集上并通过 stacking 进行融合。在这种情况下,源数据可以在不暴露隐私的情况下输出模型帮助目标数据提升学习效果,而目标数据也可以在保护自身数据隐私的约束下训练模型。
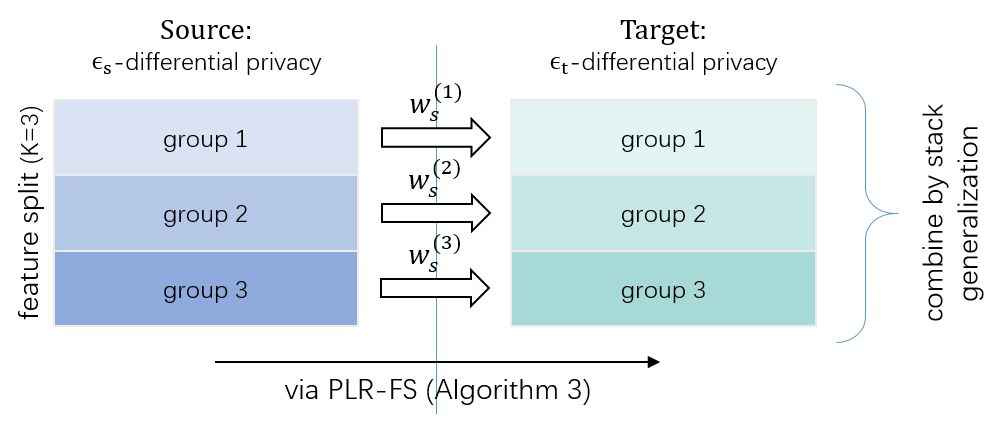
Figure 2 我们的方法在迁移学习中的应用
实验效果
我们比较了几种已有的 logistic regression 差分隐私算法,以及迁移学习相关的差分隐私算法,我们的算法均获得了最好的效果。在下面实验中,PST-F(W) 和 PST-F(U) 分别代表我们的算法使用与未使用特征重要性,PST-S 代表了按样本切分 stacking 的隐私保护算法,PLR 则代表直接在数据集上使用差分隐私 Logistic regression 算法。
1. 标准数据集
我们首先在 MNIST 和 NEWS20 数据上作了对方法的各项研究实验。

图 1 和图 2 分别表示了在不同 ϵ 以及不同 K(切分数量)下,各算法的效果。可以看到 PST-F(W) 效果是要好于其他算法的,而不使用特征重要性的 PST-F(U) 也有不错的效果。另外切分数量对效果也有影响,有一个最佳切分值。

在上图中,C-0~4 表示 5 个切分部分的效果,而 C-mv 和 C-wmv 则代表 stacking 第二层直接求平均和用特征重要性加权求平均的效果,C-hl 则为我们方法。可以看到,C-hl 可以获得最好的效果。
2. 糖尿病预测数据集
之后,我们在一个实际的糖尿病预测医疗数据集上进行了实验。该数据是由分布在不同地区的采集中心采集而成。实验中将其中一部分作为源数据集,其他部分分别作为目标数据集。实验中我们 ϵ 设置为 1,其结果如下表:

其中 PPHTL 为直接带隐私保护的模型迁移算法。可以看到,在同样隐私要求,我们的方法依然有最好的效果。
声明:本文来自机器之心,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
