导语:一个帖子在用户点进去观看之前,能被用户捕捉到的信息只有封面缩略图、标题、作者等少量信息,这些因素直接决定了用户是否愿意点击该帖。一个好的封面能明显提高用户的点击欲,而对于不少UGC内容的帖子,用户也不会去指定封面,这时智能提取封面就显得尤为重要。
对于资讯类App,从文章的配图中选择1-3张图片并裁剪出适合区域作为封面,是一种很常见的场景。这里会涉及到两个问题:如何从多张图片中选择质量较高的前几张图作为封面?挑选出来的图片宽高比可能与封面要求的比例不符,如何从图中裁剪出适合的区域呈现给用户?
本文主要跟大家分享一下我们团队最新开发的智能封面提取方案。
封面提取流程
针对以上需求,我们提出了一种多图文帖的封面提取方案,其主要流程如下:
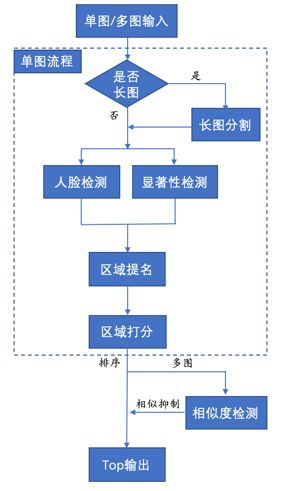
可以看到单张图片处理的流程主要包括人脸检测、显著性检测、区域提名和区域打分(其中长图分割属于异常流程,非必经主流程)。通过人脸检测和显著性检测技术来提名候选区域是比较有效的聚集方法,可以让我们快速地找到图片中的“重点”,过滤掉一些无用信息。
在前两步检测的基础上,通过提名算法,我们会选取出多个候选区域作为备选封面,最后再用打分模型对候选区域进行美学打分,输出高分区域作为这张图的最适区域。
在我们的应用场景波洞星球App中有许多长图,每张长图是由多张小图片组合而成,例如一张长漫画可能包含多画图片。因此在单张图片提取之前,我们会先检测图片是否为长图,如果是长图,则先对其进行分割操作,分割后的结果再走后续流程。
对于多张图片的最终封面选取,我们首先会依次对每张图片进行封面提取,同时得到该封面对应的得分。然后对得到的所有封面按分值进行排序,再通过相似度检测算法对相似封面进行抑制。最后,选取Top-N作为最终的帖子封面。
下面我们分模块说一下各自的实现原理。
人脸检测
在人脸检测中,我们用的是经典的yolov3模型。由于模型适用的场景不只需要检测真人人脸,还有很大一部分是动漫人物的人脸。动漫人物与真人存在许多差异,例如人物可能是简笔画风格、人物的身材比例失真、五官缺失等等(见下图)。因此我们对重新训练了模型对得到新的权重。我们收集了约3万张图片作为训练集,其中包含了来自WiderFace数据集的1万多张图片,Danbooru2018数据集的1万多张动漫人物图片以及从波洞星球上收集的6千多张动漫和Cosplay图片。验证集4500多张,测试集2800多张(动漫人物与真人各一半)。
最终模型在测试集上的召回率为97.88%,精准率为99.08%。
动漫人物上的检测效果:

显著性检测
在观看一张图片时,人眼自动地对聚集到感兴趣区域上而选择性地忽略不感兴趣区域,这些人们感兴趣区域被称之为显著性区域。目前显著性检测算法主要分成两大类:传统算法和基于深度学习的算法。深度学习算法由于复杂的网络结构和计算量,一般会比传统算法耗时更长一些,但是效果也会好一些。由于显著性检测只是作为提名的一个参考依据,不需要十分准确,所以封面提取模型使用了性能更好的传统算法。我们在传统的FT算法上做了改进,检测的过程主要有以下几个步骤:
1、对图像做高斯平滑,去掉高频信息。对显著性检测来说,细节信息显得没那么重要,相反低频信息更有价值。
2、在Lab色彩模式下,计算每个像素点与均值的欧氏距离,该距离与该点的显著性直接正相关。因为与均值距离更远,说明该点更加“与众不同”,更容易被人眼捕获。
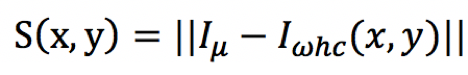
3、对2中得到的结果作归一化,将取值限定在0~255之间,然后用三个不同阈值分别对其进行二值化处理,这样一共可以得到三张二值图片。之所以要用三个阈值是因为很难找到一个通用的经验阈值可以适合不同图片。
4、用漫水填充算法将这三张二值图的边缘附近的噪点去掉。
5、将三张二值图上的同一个像素点求和并作归一化处理,得到的即为最终的显著图。
下面对比了改进FT算法和几种常见显著性检测算法的效果以及耗时:

不同算法得到的显著图
在CPU环境下的各算法耗时:
算法 | 耗时(ms) |
Improved Frequency-Tuned(IFT) | 150 |
Frequency-Tuned(FT) | 120 |
Minimum Barrier detection(MBD) | 1880 |
Robust Background Detection(RBD) | 3660 |
Deeply Supervised Salient Object Detection (DSS) | 1510 |
区域提名
在获取到图片的人脸信息以及显著性信息后,下一步要做的就是根据这两个基准信息做区域提名。通过区域提名模块,我们可以挑选出多个候选区域,再由后续打分模块选出最佳区域。区域提名主要解决了两个问题:
1、在同一张图内可能会有多个人脸以及多个显著区域,当这些区域比较分散时,一个裁剪框可能无法包含所有的内容,这时如果随机选择其中一个可能会错失最佳区域。
2、即使这些区域较为集中,也会存在不同布局带来美观程度上的变化。区域提名的方式避免了“一刀切”可能带来的badcase,进一步提高了截图的准确性。
区域提名采用的是一种基于权重的提名机制。
首先,生成mask矩阵(M)。我们会用人脸信息和显著性信息分别生成两个mask矩阵(Mf和Ms),矩阵大小与原图保持相同(实际为了节省运行开销,可以作等比例resize),将有信息区域的值设为m(m为常数,人脸信息权重较高m=10,显著性区域信息权重较低m=1),并将mask四条边框置0(为避免惩罚因子影响,下文讲到)。这时可以得到两张掩码图(无人脸时只有显著性mask):

然后,生成权重矩阵(W)。权重矩阵表征的是裁剪框中每个位置所占的比重,它的大小与最终裁剪区域的大小相同(用WxH表示)。假设要从一张1280x720的图片中裁剪出一个800x800大小的区域,那么W即为800x800的矩阵。权重矩阵有几个参数:边框惩罚因子k,边缘衰减因子alpha,以及半衰长度L。为简化说明,下面以一个8x8的权重矩阵为例。
在下图的权重矩阵中,外围点的取值由边框惩罚因子k乘以-1后得到,它的作用是在图像区域提名过程中对裁剪到人脸框或是显著区域的情况进行抑制。由于Mf的m值更大,所以抑制会更加明显,几乎不会出现把人脸切开的情况。
矩阵中心的Wi取值由边缘衰减因子alpha和半衰长度L共同决定。对人眼而言,中心区域往往会比边缘区域更容易被注视到,因此我们把矩阵按“井”字型划为9个子区域,每个子区域共享一个权重。在实际操作中,中心区域共享同一个权重W1,左上、右上、左下、右下的4个区域共享一个权重W3,其余区域共享权重W2。半衰长度L表示中心区域的长度,在下图中L=2。在超出半衰长度后,权重从W1衰减到W2,衰减大小等于衰减因子的一半,即
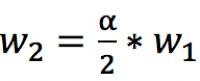
W3是全衰减的结果
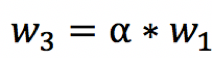
一般地,将W1设为1作为基准;alpha取值在(0.8,1]之间,为1时表示不启用衰减;k取值在[2W1, 4W1]之间。
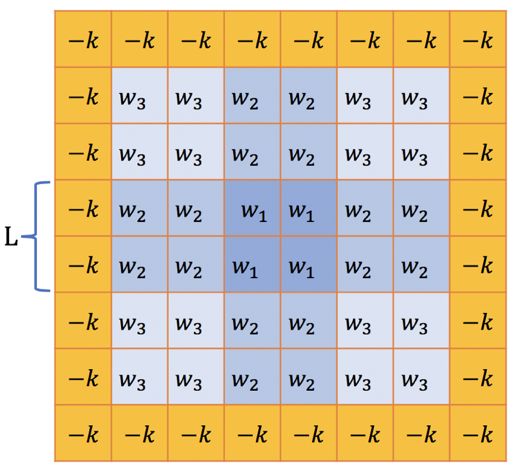
权重矩阵
得到权重矩阵W以后,可以用W根据一定步长对叠加后的掩码矩阵M(Mf+Ms)做2D卷积,得到提名矩阵:
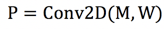
过程类似卷积神经网络中的卷积层,此处不再赘述。
最终的提名矩阵是一个二维矩阵,每一点的值代表其所表示起始点所获得的提名权重,数值越大,说明位于该点的裁剪越好,我们从中挑选出Top-N个候选区域输入到区域打分模块。
注:从提名矩阵中选值会可能会碰到多个连续的极大值点,这时我们会选择中心点,并对附近点作近邻抑制,保证提名区域不会太过相似。由于篇幅关系,这里不展开细说。

由权重矩阵提名的Top-2区域
区域打分
区域打分的作用是从候选区域中选择最佳的区域作为最终裁剪区域,打分综合考虑截图区域的美观程度、清晰度和内容完整程度(后统称为美学得分)。这里用到的是深度学习的方法,我们选用了模型相对较小的SqueezeNet网络。
SqueezeNet用FireModule的网络架构来进行模型压缩,FireModule先用1x1卷积对上一expand层的输出进行降维操作,降低参数数量,然后再分别用1x1卷积和3x3卷积结合提取特征,padding使得输出维度相同后concat拼合。这样可以使模型参数有效地减少,整个模型大小仅有1.5M左右,运行速度较快。
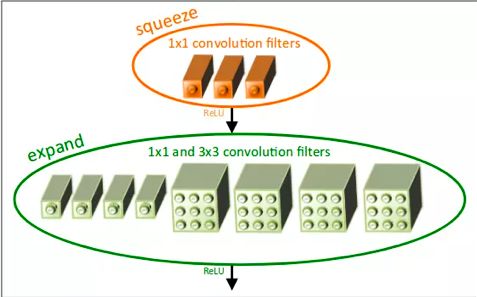
FireModule结构,图片来自网络
我们从动漫、真人以及风景场景中共搜集了5万张左右的训练样本,按产品需求将其按分为5类,对应1~5分的美学得分。模型最后取输出向量的加权平均分作为图片的美学得分。在第一版本的模型中,我们只区分了内容完整度,对内容布局上的美观程度区分不明显,在第二版本优化模型中,我们加入了对图片子等的预测,效果得到明显提升。目前,CPU环境下单帧打分耗时约为40ms。
上一轮提名的两张图片的打分结果分别为4.73分(头部略有些不完整)和5.0分(完美),因此最终会选择右图作为最终的裁剪方案。
训练过程中的其他设置:使用EMD推土距离作为损失函数,采用阶梯衰减的学习率(初始为3e-4)来加快训练过程,梯度下降优化算法使用Adam。
长图分割
在波洞星球App中有大量的长图,如果不加以分割可能会造成几个问题:首先,人脸检测的输入尺寸是416x416,长图下采样到这个尺寸后已经无法检出人脸;其次,在显著性检测中多耗费大量计算资源;再次,区域提名可能越过长图边界截到下一张图的区域。
长图分割主要有以下几个步骤,核心思想是在二值图像上寻找相邻的凸包并进行合并。
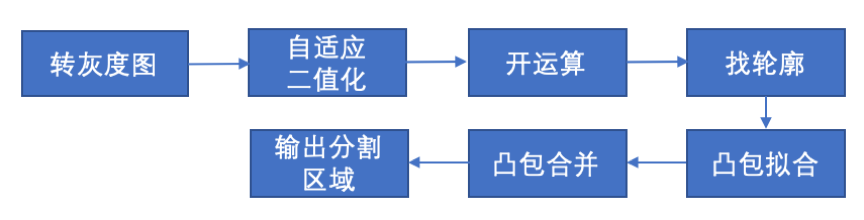
图片分割效果如下:

最终提取效果
我们选取了波洞星球上的1945组真实帖子图片作为测试集,采用按Group的形式提取图片,若帖子图片多于3张则从中提取3张子图片作为封面,若帖子图片少于3张,则提取相应张数的图片作为封面,同一Group有一张封面不好时即视为badcase。经统计,新算法提取封面的准确率为81%,旧算法准确率73%,提升了8%。长图场景下,新算法的表现得更加突出,在160张长图中,新算法准确率88%,相比旧算法57%的准确率提高了31%。
可以看两组新旧算法提取的封面效果感受一下:
第一组:
旧算法

新算法

第二组:
旧算法

新算法

总结与感谢
封面提取方案在动漫、Cosplay、风景等多种场景下都有较好的表现,目前波洞星球App已经在接入,后续我们会持续优化模型,也欢迎大家留言讨论。
声明:本文来自腾讯技术工程,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
