笔记作者:CDra90n@SecQuan
原文作者:Michael Meli,Matthew R. McNiece,Bradley Reaves
原文标题:How Bad Can It Git? Characterizing Secret Leakage in Public GitHub Repositories
原文来源:NDSS 2019
原文链接:https://www.ndss-symposium.org/wp-content/uploads/2019/02/ndss2019_04B-3_Meli_paper.pdf
GitHub和类似平台已使软件的公开协作开发变得司空见惯。然而当此公共代码必须管理身份验证秘密(如API密钥或加密秘密)时会出现问题。这些秘密必须保护为私密,但是诸如将这些秘密添加到代码中的常见开发操作经常使意外泄露频繁发生。本文首次对GitHub上的秘密泄露进行了大规模和纵向的分析。使用两种互补的方法检查收集到的数十亿个文件:近六个月的实时公共GitHub提交的扫描和一个涵盖13%开放源码存储库的公共快照。
一、简介
自2007年创建以来,GitHub已经建立了一个由近3000万用户和2400万公共存储库组成的庞大社区。除了仅存储代码之外,GitHub旨在鼓励软件的公开、协作开发。随着公众受欢迎程度的提高,“社会化”编码的普及也使得软件比以往任何时候都更依赖外部在线服务来获得基本功能。例子包括用于地图、信用卡支付和云存储的API,更不用说与社交媒体平台的集成了。作为此集成的一部分,开发人员通常必须对服务进行身份验证,通常使用静态随机API密钥[35],这些密钥必须被安全的管理。开发人员还可能需要管理用于访问控制(例如SSH)或TLS的加密公钥和私钥。
不幸的是,GitHub的公共性质常常与将身份验证凭证保持为私有的需要相冲突。因此,这些秘密常常是-无意或有意的-作为公开存储库的一部分。这类秘密泄露以前就被利用过。虽然这个问题是已知的,但目前还不清楚秘密泄露的程度,以及攻击者如何高效和有效地提取这些秘密。
本文首次对GitHub的秘密泄露进行了全面的纵向分析。构建和评估两种不同的挖掘秘密的方法:一种能够实时发现99%新提交的包含秘密的文件,而另一种则利用大型快照覆盖13%的公共存储库,一些可以追溯到GitHub的创建。我们检查数百万的存储库和数十亿个文件,以恢复数百万个针对11个不同平台的秘密,其中5个在Alexa前50网站中。从收集到的数据中提取了证实gitHub上令人担心的秘密泄露普遍存在的结果,并评估了开发人员缓解这一问题的能力。
二、秘密检测
在本节中将描述检测和验证秘密的方法。将“秘密”定义为密码密钥或API凭据,为了安全起见必须维护其隐私。
发现秘密的一个主要问题是避免来自非秘密随机字符串的误报。天真地使用以前工作中的工具,如扫描高熵字符串或编写与已知秘密格式匹配的正则表达式,可能会导致大量的误报字符串。这些方法检测到的字符串不能保证是秘密。为了避免这一问题,本文开发了一个严格的多阶段过程,将多个方法结合起来检测候选秘密,然后对它们进行验证,以获得对其敏感性的高度置信度。
多阶段过程如下图所示。从第0阶段开始,对大量的api凭据和加密密钥进行了调查,以识别任何具有不太可能发生的不同结构的证书和密钥,从而对检测到的有效性有很高的信心。然后编写正则表达式来识别这些秘密。请注意本文没有试图检查密码,因为密码可以是任何给定文件类型中的几乎任何字符串,这意味着它们不符合不同的结构,使它们很难以高精度检测。
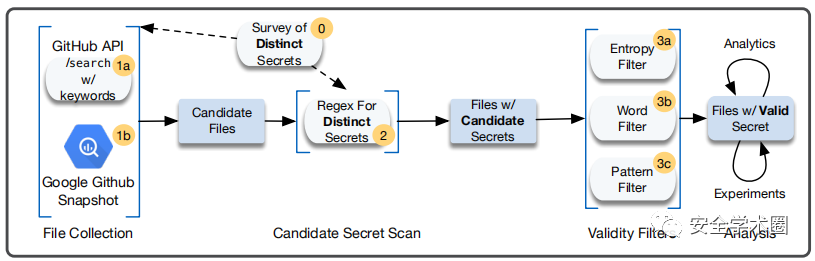
然后,在第1a和第1b阶段,采用了两种互补的方法来查找可能包含秘密的文件。在第1a阶段为GitHub的搜索API开发了有针对性的查询,以收集“候选文件”,这些文件可能包含秘密。可以不断地搜索这个api以识别新的秘密,因为它们是实时提交的。在阶段1b中在GitHub的快照中搜索了秘密,该快照在Google BigQuery中作为公共数据集维护。选择BigQuery快照而不是GitHub数据的替代集合(例如GHTorrent)是因为BigQuery包含可搜索的文件内容。由于计算限制和GitHub速率限制,通过克隆和检查每个存储库来自己创建这个数据集是不可行的。
在第2阶段,使用在第0阶段开发的正则表达式来扫描第一阶段的候选文件并识别“候选秘密”。然后第3阶段3a、3b和3c的过滤器扫描候选秘密,以标记和删除不太可能有效的候选秘密。在第3阶段过滤后,我们认为其余的候选是“有效的秘密”,然后在以后的分析中使用。注意第3阶段分类为“有效”的秘密并不总是“敏感”。例如,在OpenSSL单元测试中使用的RSA密钥可能是有效的,因为它实际上是一个密钥,但它是不敏感的,因为它的保密性不是必需的。
A.第0阶段:流行API调查
识别代码或数据文件中的秘密可能是一项困难的任务,因为秘密根据其类型、应用程序和平台而采取多种形式。如第0阶段所示去识别一组符合高度清晰结构的密钥。由于它们清晰的结构,这些密钥不可能随机出现,因此它们的检测具有很高的有效性,称这些类型的钥为“明显秘密”。对于这些明显的秘密,手动构造了“明显秘密正则表达式”,可以在以后的阶段中使用这些表达式从给定的输入文件中提取具有高度可信度的候选秘密。总共确定了15种API密钥类型和4种具有不同签名的非对称私钥类型。虽然这些类型并不是详尽无遗的,但它们代表了软件开发人员使用的许多最流行的秘密,它们的高度清晰的结构允许对GitHub上的泄泄露进行高置信度下界评估。
1)API密钥:一些流行的API服务在创建API秘密时向它们随机生成的值添加了一个独特的签名。例如,所有AmazonAWS访问密钥ID值都以字符串Akia开头,而GoogleAPI密钥以Aiza开头。这种方法不会降低API秘密的随机性安全性,但它确实使搜索泄露的密钥变得非常容易。
通过列举Alexa全球和美国前50的列表以及流行公共API的开源列表中的所有网站和服务来寻找具有不同密钥的服务。接下来搜索这些列表,以确定大约50个提供公共API且其密钥泄露会带来安全风险的知名和常用服务。通过分析API的功能范围来评估安全风险,以确定如何滥用不同的服务;例如可以使用AWS密钥授权昂贵的计算(货币风险)或访问和修改云存储中的数据(数据完整性和隐私)。最后,对于每个高风险API,注册并创建了10组惟一的开发人员凭据,以确认所提供的秘密是否显示了一个独特的签名,如果是,则手动开发一个与这些秘密紧密匹配的正则表达式。总的来说,能够为11个独特的平台(如Google)和15个不同的API服务(如Google Drive)编译签名,其中5个平台和9个API用于撰写时Alexa排名前50的美国网站。这些API、它们的密钥以及它们各自的风险(如果受到影响)如下表所示。我们为每个键使用的正则表达式可在附录的表三中找到。
所列出的API密钥具有不同的保密性和复杂度,因此可能需要充分利用其他信息。例如,敏感的Amazon AWS请求需要具有独特结构的访问密钥ID和不需要的访问密钥秘密。同样注意到谷歌的OAuth ID通常不被认为是秘密的,但是它的存在可以找到相邻的OAuth秘密。在下表中将需要额外信息的密钥区分为“多因素秘密”,而单独使用的密钥则被分类为“单因素秘密”。
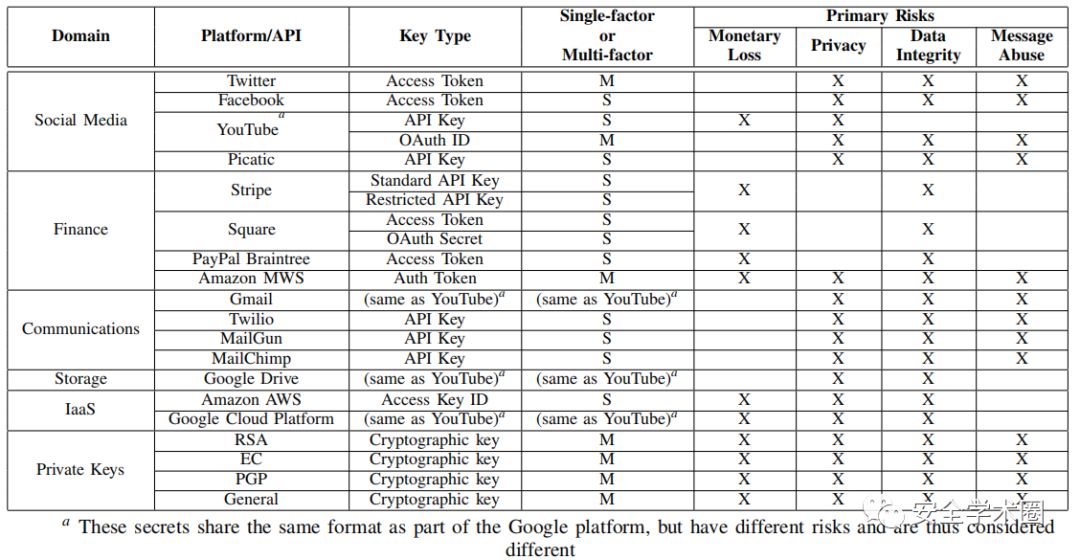
2)非对称私钥:非对称密码在许多应用中经常使用。例如,通过ssh进行的身份验证通常使用位于个人˜/.ssh/id_rsa文件中的私钥,或者OpenVPN的基于证书的身份验证可能包括*.ovpn配置文件中的私钥。在许多情况下,私钥将以增强隐私的电子邮件(PEM)格式存储,由于其头部包含文本-----BEGIN [label]-----可以识别,其中label可能是许多字符串之一,如RSA私钥。本文确定了4种常见的泄露类型的私钥,包括使用流行工具(如ssh-keygen、openssl和gpg)生成的私钥,如上表所示。
B.第1a阶段:Github搜索API文件收集
在这一部分中描述了用独特的秘密正则表达式收集要扫描的候选文件的方法,如阶段1a所示。GitHub提供了一个搜索引擎API,允许用户查询存储库中的代码内容、元数据和活动。从2017年10月31日到2018年4月20日对Github进行了近6个月的持续查询,对其进行了纵向分析。由于此API[22]在将文件推送到Github时提供近乎实时的结果,因此所有搜索结果都来自主动开发的仓库(repo)。
搜索API是一个灵活、功能强大的工具,但它确实有两个限制必须解决:不支持正则表达式并对调用率和结果计数设置限制。查询搜索API需要两个参数:查询字符串和排序类型。不幸的是查询字符串中不支持诸如正则表达式之类的高级搜索技术。为了解决这个限制首先创建了一组查询,用于标识可能包含秘密的文件。这些查询本身不足以找到秘密,但是可以下载结果文件,然后在第2阶段使用正则表达式离线扫描它们。执行了两组独立的查询:
(1)针对任何潜在秘密的常规查询,而不针对特定平台(例如,api_key);
(2)针对第III-A节中从正则表达式派生的不同秘密创建的特定查询(例如,亚马逊AWS密钥的AKIA)。
这些查询在附录的表V中显示。对于sort类型参数,总是使用sort=indexed返回最近索引的结果,以确保收到实时结果。从这些结果中排除了.gitignore文件,因为它们很少包含秘密,但占搜索结果的很大比例。对于每个查询,API都返回一组文件及其元数据。然后对API的内容端点执行另一个请求,以获取文件的内容。
GitHub在他们的搜索平台上规定只返回最多1,000个结果,只有少于384KB的文件被索引用于搜索。此外GitHub还规定了频率限制;经过身份验证的用户每小时只能执行30次搜索查询,每小时单独执行5,000次非搜索查询。在实验中每个单独的查询最多需要10个搜索请求和1,000个非搜索查询内容。以这种方式每小时只能进行5次查询。但是由于许多搜索查询每小时不会生成1,000个新结果,因此只能收集数据集中新增的文件以减少API调用。这样可以使用单个API密钥在速率限制内每隔30分钟运行所有查询。
C.第1B阶段:BigQuery GitHub快照文件集
除了使用Github的搜索API,还在第1b阶段查询了Github的BigQuery数据集。Github通过Google BigQuery提供了所有开放源代码许可存储库的每周可查询快照。此数据集中的所有存储库都显式地具有与它们相关联的许可证,这直观地表明该项目更加成熟并可以共享。此快照包含完整的存储库内容,而BigQuery允许正则表达式查询以获取包含匹配字符串的文件。不幸的是BigQuery的正则表达式支持并没有完全的功能,也不支持使用负向先行断言或后行断言(negative lookahead/lookbehind assertions),因此查询结果在第2阶段后期下载以进行更严格的离线扫描,与第1a阶段类似。
虽然两种文件收集方法都查询Github数据,但这两种方法允许分析两个主要不重叠数据集。BigQuery每周仅提供许可仓库的一次快照视图,而搜索API能够提供所有公共GitHub的连续、近实时视图。同时使用这两种方法给出了Github的两个视图。我们收集了2018年4月4日快照中的BigQuery结果。
D.第2阶段:候选秘密扫描
通过第1阶段,我们收集了大量可能包含秘密的数百万个文件的数据集。接下来,我们进一步使用不同的秘密正则表达式离线扫描这些文件,以识别实际包含秘密的文件并提取秘密本身。这个过程产生了一组候选秘密,可以在以后的步骤中进行额外的验证。扫描过程如图1第2阶段所示。
限制意味着从搜索API和第一阶段的BigQuery中检索的文件使用的方法不能保证它们包含匹配的不同秘密。下载这些文件以便根据阶段0的不同秘密正则表达式离线计算。在第2阶段执行了这个离线扫描,并注意到与一个或多个正则表达式匹配的文件和字符串。注意每个正则表达式的前缀都是负向后行(?<![\w]),后缀为负向先行(?![\w])以确保在正则表达式匹配之前或之后不会出现任何单词字符,并提高准确性。此扫描产生的字符串集被分类为“候选秘密”。
E.第3阶段:有效性过滤
可能阶段2提供的候选秘密实际上不是秘密,尽管它们与正则表达式匹配。在第3阶段通过三个独立的过滤器传递候选秘密,这些过滤器用于识别给定的字符串是否应被视为“有效”。将一个有效的秘密定义为一个字符串,它是它匹配的不同秘密的真实实例。例如,考虑Amazon AWS Secret的正则表达式AKIA[0-9A-Z]{16}将与字符串AKIAXXXEXAMPLEKEYXXX匹配,而AKIAIMW6ASF43DFX57X9可能无效。
不幸的是,将字符串识别为具有完全精确性的特定目标的有效秘密是一项非常重要的任务,甚至对于人类观察者来说也是如此。从直觉上看,人类观察者所能做出的最佳近似是候选秘密是否是随机的。过滤器对一个字符串执行三次检查:(1)字符串的熵与相似的秘密没有显著的差异
(2)字符串不包含一定长度的英语单词
(3)字符串不包含一定长度的字符范例。
如果字符串未通过这些检查中的任何一项,则被过滤器拒绝为无效;所有其他字符串都被接受为有效。有效的秘密存储在数据库中,并用于以后的所有分析。
三、秘密泄露分析
在这一章节中使用发现的秘密集合来描述Github上有多少项目由于秘密暴露而面临风险。首先的重点是确定有多少公开的秘密是真正敏感的,我将“敏感”秘密视为无意泄露的秘密,发现会给所有者带来安全风险。首先报告通过两种数据收集方法(三-A节)发现的大量公开秘密的高级统计数据。然后通过严格的手工实验(三-B节)证明大多数被发现的秘密可能是敏感的。接下来比较单个和多个所有者的秘密,以进一步确认上述部分(三-C节)。本文还证明找到一个秘密可以用来发现其他高概率的秘密(三-D节)。展示了许多秘密很少从Github中删除,并且会无限期地持续下去(三-E节)。最后特别关注RSA密钥,以举例说明攻击者如何滥用暴露的密钥(三-F节)
A、秘密收集
在本节中提供关于发现的一组秘密的高级统计信息。在收集方法的每个步骤中详细描述了文件的数量,最终得到发现的唯一秘密的总数。在这里将“唯一”秘密称为在数据集中至少出现一次的秘密;请注意,唯一秘密可能出现多次。
GitHub搜索API。Github搜索API集合开始于2017年10月31日,结束于2018年4月20日。在这近6个月的时间内捕获了4394476个候选文件,代表681784个仓库(第1a阶段),从中我们的独特的秘密正则表达式扫描(第2阶段)识别了109278个仓库中的307461个文件,其中至少包含一个候选字符串,给出了文件命中率约为7%。
总之确定了全部403258个和134887个与正则表达式匹配的独特候选字符串。此外,搜索集合每天收集4258和1793个独特的候选秘密,总范围共计从2516到7159。
如前所述,与正则表达式匹配的某些字符串可能是无效的秘密。因此应用了过滤启发式方法来确定候选字符串中有效秘密的数量(第3阶段)。总的来说,发现133934个不同的候选字符串是有效的,对于在第2阶段中使用的不同的签名正则表达式,总的精确度为99.29%。
GitHub BigQuery。 在2018年4月4日对单个GitHub每周BigQuery快照执行了查询,能够扫描3374973仓库中2312763353个文件的内容(第1B阶段)。在100179个文件中确定了至少一个正则表达式匹配,这些文件代表52117个仓库(第2阶段),在BigQuery的所有开源Github存储库中,文件命中率约为0.005%。在匹配的文件中,确定了总共172295个字符串和73799个不同字符串,其中73079个有效,即98.93%(第3阶段)。
数据集重叠。一些秘密可能出现在两个数据集中,因为通过搜索API看到的一个文件可能包含在BigQuery快照中,或者一个秘密可能简单地复制到不同的文件中。在加入这两个集合之后,确定在两个数据集中都能看到7044个秘密,占总数的3.49%。
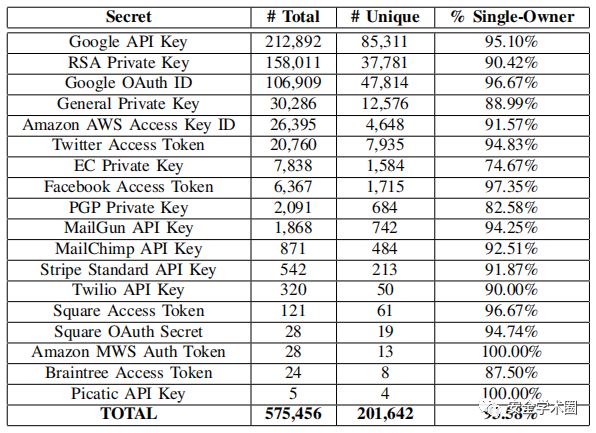
按秘密分类。下表按将全部和不同的秘密按不同的秘密分类。最常见的泄露是谷歌API密钥。RSA私钥泄露也很常见,尽管其他密钥(如PGP和EC)的泄露量要低几个数量级。许多API密钥都有相对较小的泄露事件,可能是因为这些平台在GitHub上的项目类型中的普及率较低。最重要的是能够为每个目标API识别多个秘密。
B、手工审查
在本文中使用统计方法和启发式方法来估计Github上秘密的流行情况。为了验证这些结果,对数据集的样本进行了严格的手工审查。随机抽取了240个候选秘密样本,平均分配在Amazon AWS和RSA密钥之间。三名评估者中的两名(均为论文合著者)在Github的网站上检查了包含秘密的文件和报告。在考虑了秘密的上下文之后,评估者将每个秘密评估为敏感、非敏感、不确定或非秘密。一旦每一个秘密都被标记,就评估这两个评估者之间的可靠性,发现88.8%的判断与Cohen"s kappa值0.753一致,对结果充满信心。所有的分歧都是由第三个评估者来调解的,第三个评估者在不知道之前的标记的情况下,独立地对每一个不一致的案例进行评分,然后通过小组共识来解决。在随后的结果中排除了无法确定或非敏感(共5个)或无效秘密(共4个)的秘密。
C.单一和多所有者秘密
上表中的结果显示,由于唯一秘密的数量小于总秘密的数量,因此收集的秘密存在一定程度的重复。由于以前将秘密定义为必须维护其隐私以确保安全的凭证,因此评估了这种复制,以确定它是否表明结果偏向于非敏感秘密。凭直觉,一个秘密应该对“own”它的个人保密。虽然由于个人在多个文件或仓库中使用相同的敏感秘密而导致复制是有效的用例,但不太可能看到多个用户这样做。
为了验证这种直觉进一步分析了三-B节中的手动审查实验的结果。首先,将一个拥有者的秘密定义为““single-owner secret”,将多个拥有者的秘密定义为“multiple-owner secret”。因为无法确定秘密,而且由于数据源不容易提供贡献者信息,将仓库所有者视为拥有秘密的实体。在所检查的240个秘密中,还平均地在单个和多个所有者秘密之间划分了秘密,这样就可以检查AWS和RSA密钥的单个/多个所有者秘密之间的敏感性是否存在差异。在较高水平上,91.67%的单所有者AWS密钥是敏感的,而66.67%的多所有者AWS密钥是敏感的,RSA密钥分别为75%和38.33%。对于AWS密钥,发现中等的效应大小(χ2=15.2,p<10^-4,r>0.56)有统计学显著差异;对于RSA密钥,发现大的效应大小(χ2=35.7,p<10^-5,r>0.56)有统计学显著差异。这些发现证实了单一所有者的秘密更可能是敏感的。
根据直觉将数据集中的每个秘密分类为单个或多个所有者,以评估重复的影响。上表显示了这种分类对组合搜索和BigQuery数据集的结果。显示绝大多数(93.58%)的独特秘密在一个拥有者拥有的repos中发现,这表明这些更可能是敏感的秘密。此外还计算了搜索和BigQuery数据集之间的单个和多个所有者秘密的相对比率之间的皮尔逊相关系数。发现这两个数据集S的相关系数为r=0.944,P值为1.4x10^-9,这表明无论其大小和视角如何,他们对敏感秘密的暴露和传播水平都相似。
D.并行泄露
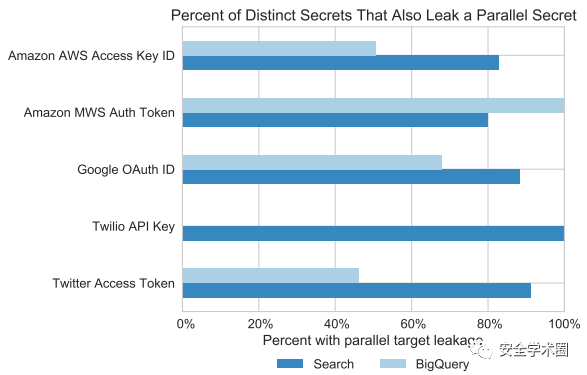
一些秘密需要更多的信息才能被使用,例如需要OAuth Secret才能执行特权操作的Google OAuth ID。之前将这些秘密定义为“多因素”秘密。虽然这些并行的秘密似乎可以通过减少泄露的影响来提高安全性,但在本节中显示缺少的信息是经常与主要秘密并行泄露,使得这种保护大多无关紧要。检测平行秘密的困难在于它们可能没有足够清晰的结构被包括在不同签名中。然而,它们仍然可以通过精心设计的正则表达式进行匹配,并且在事先了解秘密泄露的情况下具有高可信度。检查了每个包含不同多因素秘密的文件,然后在一个秘密前后扫描5行中的并行秘密。此上下文大小是根据先前扫描Google Play应用程序的工作选择的。
下图显示了这个实验的结果,即包含一个具有并行秘密的秘密的文件的百分比。搜索数据集中的每个多因素秘密至少有80%的可能性泄露另一个并行秘密。例如尽管Google Oauth ID需要另一个秘密,但是编写正则表达式以高保真地识别它们的能力允许在近90%的情况下发现其他秘密之一。BigQuery显示并行泄露率较低,可能是因为数据源包含更成熟的文件,但仍然存在令人担忧的泄露量。因此认为这些多因素秘密具有不同程度的妥协性和保密性这一事实并不是一个很大的障碍。
此外,这种并行泄露并不局限于单一类型的秘密;许多包含一个秘密的文件也包含另一个秘密。在同一个文件中发现了729个泄露两个或多个API平台秘密的文件。
E.秘密存活时间
一旦用户公开了某个秘密,用户可以尝试通过随后的提交来追溯地删除该秘密。为了量化这一现象的流行程度,从2018年4月4日开始监测通过搜索API收集的所有秘密。在发现后的前24小时内,我们每小时查询一次Github,以确定包含该文件的仓库、该文件本身以及检测到的秘密是否仍然存在于默认分支上。在最初的24小时后,以较低的每日频率进行相同的检查,如下图所示。
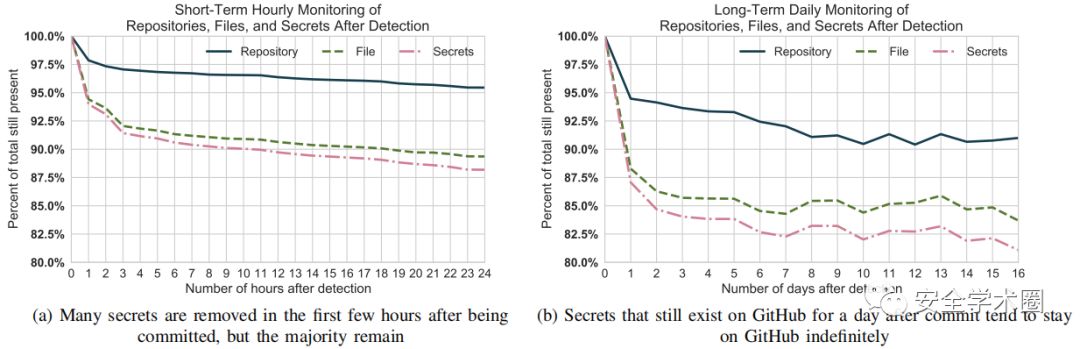
观察到几个趋势。首先,秘密存在最大的下降发生在发现后的第一个小时,在那时大约6%检测到的秘密被删除。第二,存在超过一天的秘密往往长期存在于GitHub上,超过12%的秘密消失了,在第一天结束时,超过12%的秘密消失了,而16天后只有19%的秘密消失了。第三,删除秘密和文件的速度大大超过了删除仓库的速度;这表明用户没有删除他们的仓库,只是创建了删除文件或秘密的新提交。不幸的是,由于Git软件的性质,这些秘密可能仍然可以访问。
这些结论表明,发现的许多秘密都是错误提交的,而且它们是敏感的。19%的秘密在大约2周内的某个时间点被删除,其中大部分是在最初的24小时内删除的。这也意味着发现的81%的秘密没有被删除。这81%的开发人员可能不知道秘密被提交,或者低估了妥协的风险。从绝对值来看,研究结果中有19%涉及数千个秘密,并且代表了发现的敏感的秘密数量的下限。
此外还研究了Github建议的在保留其仓库的同时删除其秘密的用户是否执行了重写历史以删除提交的任何过程。对于每一个这样的实例都查询了github Commits API以获取有关发现的提交的信息;如果该提交被重写将不再可访问。本文发现没有一个被监控的仓库被改写了历史,这意味着这些秘密可以通过git的历史来获取。
F.RSA密钥泄露
上表显示了数据集中的很大一部分秘密是RSA密钥,这是预期的因为它们被用于大量不同的应用程序。本文进行了各种实验来研究如果发现这些RSA密钥有多少会带来很大的风险。
有效密钥的数量。RSA密钥包含一个已定义和可解析的结构。因此可以使用Paramiko库确定这些密钥中有多少是有效的。在通过搜索API发现的25437个秘密中发现25370个密钥(99.74%)是有效的。从BigQuery数据集中,在15262个秘钥中,98.31%或15004个秘钥有效。
加密密钥的数量。公钥加密标准(PKCS)允许对私钥进行加密。虽然泄露密钥从来不是一个好主意,但如果密钥是加密的,攻击者将很难危及到泄露密钥。再次使用了Paramiko库以确定密钥何时加密,在密钥上算出有多少是加密的。从这个实验中发现搜索数据集和BigQuery数据集中没有加密泄露的密钥,这意味着攻击者可以轻松地使用每个密钥。
OpenVPN配置分析。RSA密钥的另一个应用是在OpenVPN配置文件中使用,在该文件中可以嵌入密钥,以便对VPN服务器进行客户端身份验证。作为额外的保护层,OpenVPN建议客户机在配置文件中指定auth-user-pass选项。此选项还要求用户输入有效密码以连接到VPN,这使得使用被盗密钥更加困难。为了确定攻击者是否可以获得对VPN服务器的未经授权的访问,我们通过查找扩展名为.ovpn的文件,分析了数据集中存在多少包含RSA密钥的OpenVPN配置,并调查了它们是否可以在无需进一步努力的情况下使用。
在搜索数据集中识别了1890个OpenVPN配置文件。至关重要的是,其中13.18%的用户没有使用auth user pass选项,这意味着用户很容易受到攻击者的攻击。在bigquery数据集中,识别了5390个openvpn配置文件,其中1.08%易受攻击。这两个数据集之间存在差异,可能是因为许可仓库更成熟,包含更多示例文件,但两个数据集仍然显示了绝对数量的大量数据。
声明:本文来自安全学术圈,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
