近年来,生物识别技术的应用越来越广泛,我们已渐渐习惯使用指纹识别来代替密码,方便快捷地解锁手机,进行支付等。但其安全性仍然堪忧。
犯罪分子能通过屏幕图像采集技术、指纹雕刻技术或者简单的恶意软件等手段轻松捕获、复制我们的指纹,用于犯罪。
不过,“魔高一尺,道高一丈”。当下前沿的“生物探针技术”就是反欺诈和防盗刷的利刃,能通过用户的行为特征对屏幕面前的人进行身份判定,更精准地识别出“你是不是本人”,有效地检测识别自动化工具撞库攻击、授权爬取账单、网银盗号、电诈盗刷等交易风险。
下面就让我们来回顾看雪2020第四届安全开发者峰会上《生物探针技术研究与应用》的精彩内容。
演讲嘉宾

王巍,东南大学计算机博士,哈工大博士后,曾就职于微众银行等知名机构,主持反欺诈算法框架的建设;拥有10年反欺诈算法经验;发表论文10余篇,拥于10+相关专利。现就职于同盾科技,任小盾安全算法总监。
演讲内容
以下为速记全文:
大家下午好,我是王巍,来自于同盾科技。现在就由我来给大家分享一下生物探针的研究与应用这个课题。
今天下午的分享有四个部分的内容,第一个部分是生物探针的概念及应用背景的介绍,第二个是业界研究现状的总结以及我们对现有的研究现状做一个问题的梳理,第三个部分我们将介绍我们自然基于神经网络算法来解决业界存在的一些问题,第四个部分的内容是对我们的工作做一个总结以及对下一步工作做一个展望。
一.生物探针及应用场景
我们先来看一下第一部分的内容——用户认证方式的发展过程。2010年前是PC时代,主要就是通过输入密码等来进行认证。稍微加强一点的认证方式就是在电脑中再插一个U盾来加强认证。
2010年之后随着智能手机的普及,一些强身份认证信息,像指纹、人脸、声纹等等都被应用到认证当中,极大方便了我们的认证工作。
到了2020年,随着AI技术被讨论得越来越多,越来越多的AI技术也被应用到身份认证当中,我们也更加关注个人隐私保护,关注一些用户体验等等。因此生物探针这个技术也得到了广泛的关注,生物探针主要是收集用户在使用手机过程中的一些行为习惯,比如说持机方式是单手还是双手,平时是双手操作还是单手操作,以及你的按压力度以及输入密码的时长、间隔等等。它会通过这些生物特征来构建唯一的一个用户ID,来对用户进行身份认证。
生物探针一般有如下几个应用场景,一个是无感认证,主要是强调用户体验,用户在输入用户名、密码的时候同时就可以在后台完成两步认证,对于用户来说是无感知的。
第二个应用场景是可以强化身份验证。输入用户名密码之后,如果系统检测你的网络环境有异常,会弹出一个验证码或者人脸识别等等。但如果用生物探针这项技术,只要在输入用户名和密码的时候,就可以同时完成对用户行为习惯的认证。
第三个是持续认证。我们输入密码,接下来在浏览网页、购物的时候就不需要再认证了,但是生物探针是在后台持续运行,持续对用户进行认证的,中间发现任何异常,可以立刻终止。
第四个是隐私保护。生物探针记录的是人的一些行为习惯,不像人脸一样涉及到一些用户的隐私,因此对隐私保护是有非常大的帮助的。
二.业界研究现状
下面,我们对业界的研究现状进行了梳理。我这边列出来的主要是一些学术界的paper,之所以列出来,是因为工业界目前生物探针落地的场景和案例比较少,而且能够找到的一些公开资料也都是在学术界的。主要可以分两大类,一类是使用传感器,一类是不使用传感器。如果是使用传感器的话,一般就是对移动端的认证,如果不使用传感器的话,一般就是对PC端的认证,就是击键形式的一个生物认证。
同时我们可以看到,在学术圈内的一些文章中,它的人数和样本量都是比较少的,主要是因为生物特征本身很难用代码生成的方式来大量生成样本,只能靠人工点按收集,这也是制约我们做一个好的模型或者算法的难点所在。
最后,我们可以看到它当中的一些分类器和模型的选择基于两大类。一类是基于距离类的模型,还有一类是基于一些传统的机器学习算法,比如说基于一些统计学、基于一些传统的神经网络的机器学习算法。
而最新的算法模型,比如说像深度学习很难用起来有几个原因,一个是生物探针的发展是由对键盘、击键认识发展过来的,那个时候深度学习讨论得比较少。还有一个原因是受限于样本量,很难以现有的人工采集方式构建出大量的样本来供深度学习,学习出一个好的模型。
对此呢,我们对现有的研究现状进行了一个总结,梳理了其中的三个问题。
第一个是数据限制的问题。数据限制是指,我们在手机上网的过程中,或者在用一个APP的过程中,一般有三个方面的数据被我们采集,一个是滑动数据,就是滑动的起始位置、长度和面积、压力等等,这个数据是可以拿到的。第二个是传感器数据,传感器数据有三大类,磁力器、加速器、陀螺仪,还有就是按压的力度。还有一类就是按压的力度,比如说你输密码的时候按压的力度、大小面积等等是可以拿到的。但是因为历史沿承的原因,击键的数据被研究得比较多,点按的数据很多的算法会用到,但是滑动和传感器的数据只有很少的文章在进行专门的研究,而且很少有研究是把所有收集的数据都用起来的。
第二个问题是跨期不稳定的问题。虽然说一个人的行为习惯相对是固定的,比如说有长期养成的行为习惯,但是我们训练模型的时候,因为采集环境会受到一些影响,噪音数据以及传感器的不稳定等等原因,都可能会导致我们先前采集来的数据建立的模型在后期验证的时候失效。
第三个问题是不支持小样本的训练。如果说我们只有简单的几次输入,生物探针模型就很难对它做一个准确的判断。如果说我们需要大量的样本来学习到一个足够好的生物探针模型的话,在长期的学习过程中,我们又很难保证会不会发生攻击,因此需要构建一个在冷启动阶段就能快速用起来的生物探针模型。
三.基于神经网络的生物探针模型
基于上面介绍的几个问题,我们的目标就是要构建一个数据全面、跨期稳定、能够支持小样本的模型。

首先介绍一下我们所采用的一些特征,主要是三大类,刚才已经介绍过了,滑动类、传感器还有击键的。
滑动类的特征,有一个时间特征,就是你滑动的时长,还有空间特征,滑动的长度、宽度,以及滑动的力度、强度等等,这几个方面的特征要在特征空间用起来。
第二个是传感器的特征,主要是有加速器、陀螺仪和磁力器,这三个特征采集到的一般是XYZ三个轴上的数据。我们做特征的时候还会做合力方向,四个特征,四个维度,每个维度都可以提取一些特征出来。
第三个特征是击键类的特征,包括击键的时间、击键的间隔、长度,还有差分。差分是指你第一次输入和第二次输入的时间差,以及第一次输入和第三次输入的时间差。我们发现这个特征在我们的模型构建的时候是比较有效的。
这是我们采用的一个生物特征表。

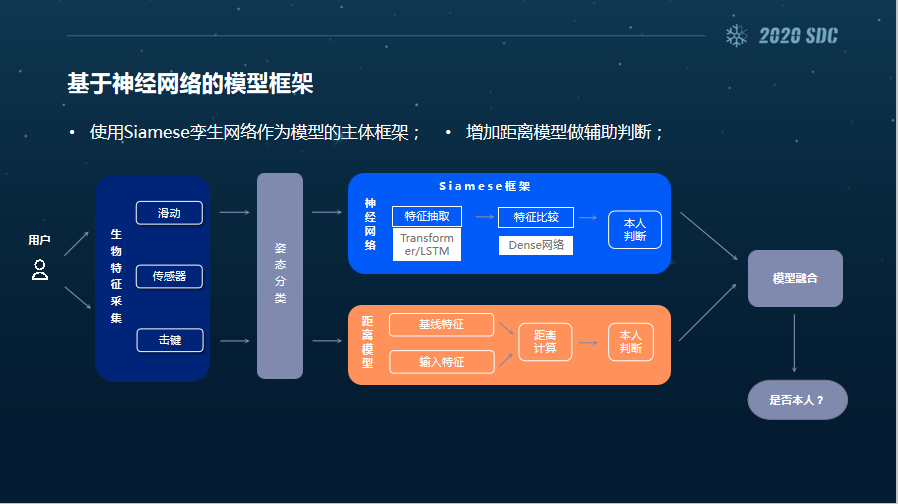
下面是我们一个基于神经网络的模型框架。这是我们的一个主体的判断模型,主要由三个小模型组成。
第一个是姿态分类模型,就是指我们在实验的过程当中,发现用户他握手机的手势对模型或者数字采集的抖动性影响很大,或者对于样本采集的质量影响很大,比如说有的人是单手持机单手操作,而有的人是双手。这个我下一页会做详细的介绍。
第二个模型是一个孪生网络模型,这是基于深度学习的一个网络模型,也是我们的一个主体模型。
第三个是基于距离的模型,是一个辅助判断的模型。我们最终的结果,就是采集到用户的输入数据之后,经过姿态分类模型、孪生网络模型和距离模型的融合结果,来判断是否是本人输入。
这三个模型我接下来分别都会做一个详细的介绍。
我们简单地做了一个姿态分类模型,主要有六类,单手持机单手操作、单手持机另一个手操作等,就不详细介绍了。
接下来,说一下孪生网络模型。这里,我们用的一个模型就是简单的决策树,这个模型是我们在构建生物探针时的一个主体模型。大家如果对其有所了解的话会知道,一个感知机的输入向量是固定的一串特征,输入到模型中可以进行判断,通过判断结果看是否是本人。
但是这个孪生网络模型和传统的模型有一个很大的不同,就是输入向量是由两个特征组成的。也就是说,它会每次将两个特征,即用户行为1和用户行为2同时输入到孪生网络当中,再根据比较网络去判断结果。这就是我们的模型和一般的模型最大的不同所在。

另外一个不同点是我们在孪生网络中加了一个transformer网络。意思就是说,我们对持续的特征进行了一个处理。这么处理是因为我们在实验中发现,用户在浏览一个网页或者在转账的过程中,他按键的顺序、浏览的顺序对我们模型的效果影响很大,所以我们加了一个transformer网络来学习持续的变化,从而来构建一个更精确的模型。这个我们后面也会有数据来支撑这个论点。

而在比较网络中,我们还用了一个Triplet损失。这个比较专业,我就不详细介绍了。主要就是说,我们加这个损失函数的原因是希望在一个小样本空间中把好坏样本区分开,把正确的本人用户和非本人用户区分开,实验的时候我们发现这个对模型精准度是有很大帮助的。
这么做的主要思想在于,能使具有相同标签的样本在embedding空间中尽量接近,第二是使具有不同标签的样本在embedding空间尽量远离,同时它对小样本的训练也非常有利,可以帮助我们得模型在冷启动阶段快速学习到用户的一些基本的行为。
接下来我们介绍辅助的判断模型,就是距离匹配模型。它非常好理解,假定每个用户输入了3-5条数据,我们标记他为本人,我们就会把这3-5条数据在每个特征维度上做一个平均,构成他的击键特征。
此时再来一个新的用户,不管他是不是本人,我们会把这个数据和我们训练的击键特征进行比对。比如说是一个相减的操作,如果距离大的话,我们就认为他不是本人;距离小的话,就是跟本人很相似,那我们就认为他是本人。其实采用距离模型的一个很重要的原因是,它可以很方便我们定位到具体是哪个特征出了问题,然后相应去调试我们的模型。
另外,这个地方我重点介绍一下我们距离选型的一个计算公式。其实维度很多,有成千上万维,我们采集的也是很多维度的特征。在这里我们只放了十维的数据,图上的亮橙色就是我们的击键特征,暗的就是我们采集的特征数据。
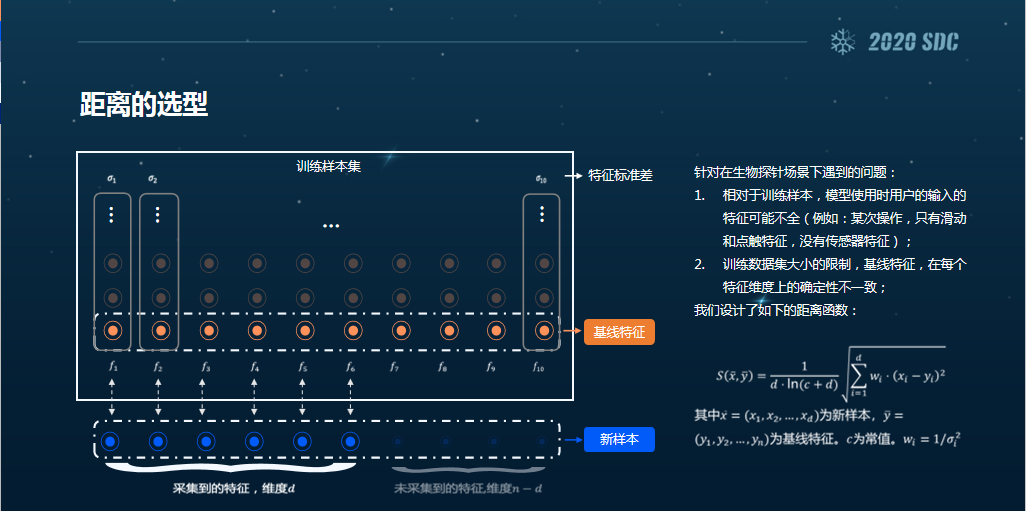
击键特征是由暗的以及亮橙色的各条样本的各个数据加权形成的,这就是我们判断的依据。然后当一个新的用户需要验证的时候,采集到的用户输入特征数据可能会不全。
假定采集到了一个维度d的数据,剩下的v-d维度的数据是我们没有采集到的,这个距离公式就是我们计算新的样本特征和击键特征有多大差距的一个计算公式。大家学过高数都应该知道,这个公式是一个欧式距离的变形,其中我们重点考虑了两个参数。
一个是每个维度上的特征标准差,特征标准差越大,就意味着这个维度上的信息的抖动越大,这个信息就会越不足,因为它不稳定。另外一个就是我们在考虑距离的时候,考虑到了采集到的一些特征可能会不全。这在现实当中是经常发生的,越是采集不到足够全的数据,对模型精准度的影响也会越大。
我们主要就是考虑以上两个参数,把它加入到欧式距离中,对它进行变形,形成了我们的距离函数S,也就是我们最终用来判断的距离公式。
那么有了这个距离之后,我们还要做的是距离阈值的选定,就是说有了距离之后,那么多大为大,多小为小呢?我们要有一个判断的标准。
一般来说学术界有一个EER的指标,它是由两个指标构成的,一个是FRR,它的意思是样本为本人,但是未能通过验证;另一个是FAR,叫误识率,意思就是样本为非本人,但是通过了验证。
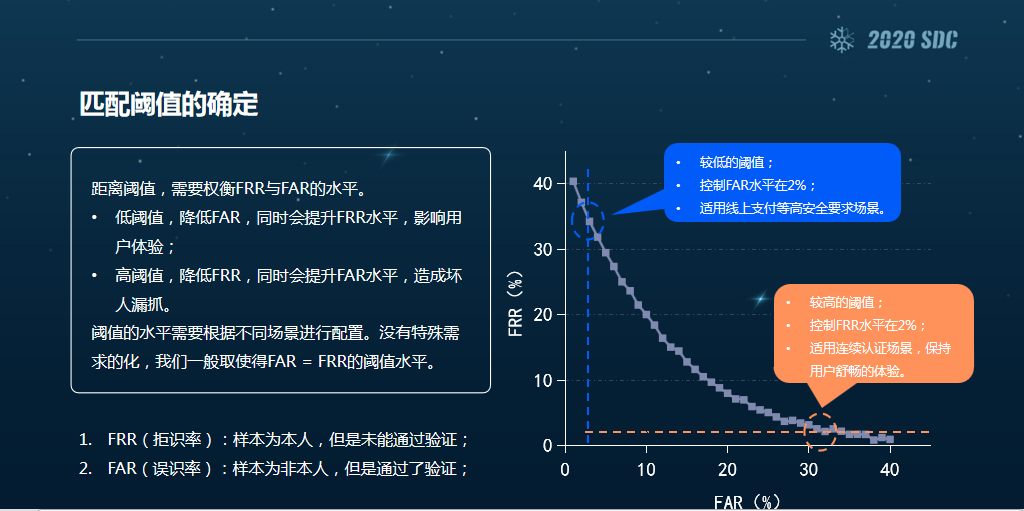
这个图是我们选取距离函数阈值的标准。假定我们要求用户在体验良好的环境当中,比如说客户要求我们必须把打扰率控制在千分之几的水平,这个时候我们就会把FRR控制得比较低,而FAR控制得比较高。这么做的目的就是尽量不要打扰客户,换句话说就是尽量让更多的人去通过模型的验证,尽量少拒绝一些人,即便可能会造成漏抓坏人,但也会有一些其他的验证手段来弥补的。
另一种情况可能就是在高安全的支付场景。这个时候我们希望能尽量地保障安全性,即便打扰客户也没关系,但不能出错。在这个场景下,我们就会把FAR控制得比较低,而FRR控制得比较高,虽然对用户的干扰会高一些,影响用户体验,但安全性能得到更高的保障。
以上就是我们在阈值选择上的一个衡量标准。一般来说,你不知道怎么选或者没有一个业务要求的话,就会选择FRR等于FAR这样一个阈值水平,来衡量模型的好坏。
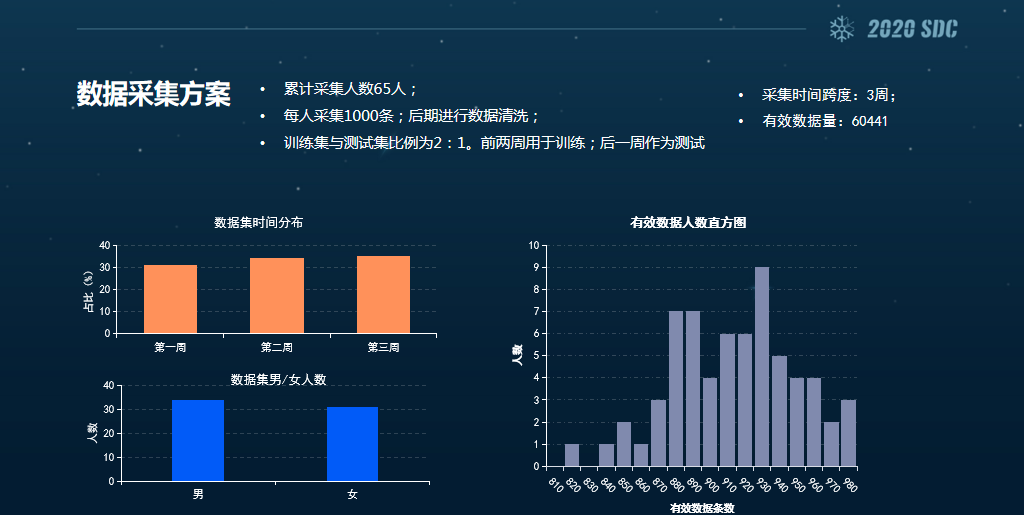
下面再来介绍一下我们的数据采集方案。我们采集了公司内部65个参与者的数据,每个人采集了大概1000条左右的数据,后期进行数据清洗。训练集和测试集的比例大概是2:1,时间跨度为三周,前两周用于训练,后一周用于测试。
这个地方讲一下,很多的公开资料上,它们数据的训练级和测试级的选取都是随机选取的,但我们这个地方为了验证跨区不稳定的问题,是用一个时间周期来作为选取标准的。
从时间分布上来看,采集的时间跨度是3周左右,男女比例也差不多,清洗得到的有效且可用的数据建模条数是90%左右。
这是我们在实验室内部做的一个测试结果。这个图比较专业,我简单告诉大家三个结论。
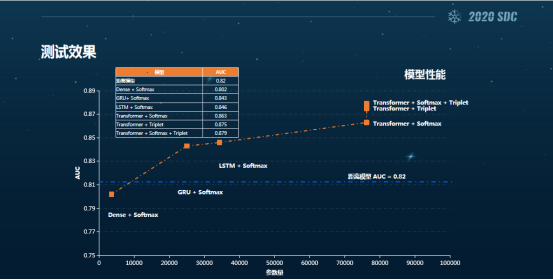
第一,通过我们的数据测算,发现距离模型虽然比较简单,但是它的性能并不差,比一些复杂的模型甚至还要好一些,这也是为什么很多人选择距离模型的原因。
第二,我们加入了transformer这个持续模型之后,效果明显有所提升。因此我们得出用户输入的顺序是非常重要的,比如说先滑动还是后点按这都要在模型中准确识别出来。
第三就是我们加了一个Triplet损失函数,发现它的效能是最好的,也就是说损失函数在小样本的空间中能显著提高模型的性能。
以上就是我们这张图主要想表达的三个意思。
下面我来介绍一下我们的典型用例。这是我们和电商的合作用例,主要是在无感认证上。传统的认证方式有两步,就是在输入用户名密码之后接下来会检测你的网络运行环境,如果有异常会弹出验证码,让你输入验证码,通过之后才能完成最后的认证。
而生物探针技术如果用在无感认证中,可以把两步认证一步完成。在输入用户名密码的时候,后端会有一个生物探针的模型可以完成认证。其优势有两点,一个是耗时明显降低了,一般做两步认证的话至少要十秒以上,但如果只是输入密码的话很快就能完成。第二个好处就是传统的两步认证如果频繁弹出验证码,时间长了会造成一定的客户流失,生物探针这样的问题就比较少。

对于传统的两步认证方式,在第一步输完账号密码之后,我们统计了一下,大概有2.3%的客户。不管是因为什么原因会触发二次验证,当要求用户输入验证码的时候用户就会有22%左右的拒绝率。
同样,我们用生物探针进行认证的时候,可能也会触发输入验证码的操作,但只有大概5‰左右的比例会触发。这个跟业务方是可以商量决定的,要尽量减少对客户的打扰。
输入验证码之后也可能会通过验证,也可能会不通过,大概有77%左右的拒绝率,从这个数据可以看到两个结论。第一个就是对客户的打扰。如果把输入验证码就认定为对客户的打扰的话,2.3%和5‰的差距还是很大的。也就是说,生物探针是可以显著降低这种打扰率的。第二就是在同样筛选客户进入输验证码的环节,拒绝率也发生了很大的变化,这就意味着生物探针对最后准确地识别出好坏客户是有很大帮助的。
四.未来工作
接下来我就介绍一下我们下一步的工作吧,下一步工作主要有四个方面。
第一个,继续基于时序模型的探索。因为我们在研究中发现对于这种用户的输入行为,特征的输入顺序对模型的准确性有很大的影响,这也是有一个业务上的解释的。比如说我们进入一个转账环节的验证,那么用户正常打开APP到进入转账经过了几个浏览的步骤也好、点按操作也好,是相对比较固定的。
第二是要尝试更多的损失函数,这个主要是基于对小样本学习的考虑。我们是希望能够快速地构建出一步到位的简单模型,在冷启动的时候来使用的,而损失函数的变化对于模型的精准度有很大的影响。
第三是提高在线学习的能力,探索一些迁移学习、one-shot learning等技术来进一步提升冷启动的效率。
第四是要扩充当前的数据集规模,因为我们发现目前的数据集还是偏少的,要想构建一个长期、稳定、强大的神经网络模型是需要更大量,甚至更海量的数据采集来帮助我们构建的。
那么今天我的分享就到这里,谢谢大家!
声明:本文来自看雪学院,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
