文/柯善学
上一篇提到了Illumio实施零信任微分段的“三步走”方法论:1)获得应用程序实时地图;2)为工作负载打标签;3)实施安全策略。
作为本系列第3篇,本文延续上一篇,重点介绍第3步(安全策略设置)。如果说应用程序实时地图是技术根基,则可以认为自然语言安全策略是上层建筑,容易体现“三步走”方法论的价值。
设置安全策略通常是相当困难的。由于应用程序是高度互联的,即使只有几百个应用程序(可能由几千个工作负载组成),也可能有数百万个需要分析的连接。所以,设置安全策略的最佳方法是自动化生成允许这些连接的策略。
本文将结合一个演示(Demo),来更清楚地解释自动化的自然语言策略方法。通过手把手的配置过程,令人不禁感叹:原来零信任的实施也可以如此简单!当然,其背后隐藏了很多复杂性。
所以,Illumio其实是在尽其所能提升客户体验,把简单留给客户,把复杂留给自己。
目录
1.总体架构:安全大脑+神经元
1)神经元:虚拟执行节点(VEN)
2)安全大脑:策略计算引擎(PCE)
2.工作负载微分段之“三步走”方法论
3.四维标签模型及其数据治理
1)Illumio的四维标签模型
2)标签数据的来源
3)标签数据的质量
4)标签数据的治理
5)从网络语言转向自然语言
4.应用程序的五级可见性
1)第1级可见性:全局视图
2)第2级可见性:单个数据中心
3)第3级可见性:单个应用程序
4)第4级可见性:单个主机(工作负载)
5)第5级可见性:跨多个数据中心的单个应用程序
5.自然语言安全策略设置
1)通过策略生成器编写安全策略
2)第1级安全策略:应用程序组级别
3)第2级安全策略:应用程序角色级别
4)第3级安全策略:应用程序服务级别
6.安全策略的测试验证
1)构建(build)模式
2)测试(test)模式
3)强制(enforce)模式
01
总体架构:安全大脑+神经元
Illumio总体架构是安全大脑+神经元的结构。安全大脑是策略计算引擎(PCE),神经元是虚拟执行节点(VEN)。如下图所示。使用零信任架构的语言讲,策略计算引擎(PCE)是策略决策点(PDP),虚拟执行节点(VEN)是策略执行点(PEP)。

图1-总体架构:安全大脑+神经元
1)神经元:虚拟执行节点(VEN)
如图,您可能会在数据中心或云中,运行裸机、虚拟机、容器。我们可以先在这些机器上安装一个VEN代理。它很像天线(或神经元/传感器/探针),其作用就是发送和接收信息。它会收集IP地址、机器主机名等信息,甚至收集打开的进程、端口和与之通信的东西,并将其发送到安全大脑即策略计算引擎(PCE)中。
2)安全大脑:策略计算引擎(PCE)
策略计算引擎(PCE)是整个解决方案的大脑。PCE可以部署在客户数据中心的物理或虚拟服务器上运行,也可以直接在Illumio云服务中使用。不论哪种方式,都可以扩展到支持数十万个工作负载。
PCE这个大脑会做两件神奇的事情:
一是制作应用程序通信的地图。而这些都是神经元VEN报告的。值得提醒的是,这是一个应用程序拓扑图,而非一个网络拓扑图。

图2-应用程序实时地图
二是根据应用程序实时地图,编写安全策略。这里的特别之处在于,你可以使用非常母语化的语言(即自然语言而非网络语言),编写安全策略。安全策略的样子就像“我想让web层与数据库对话”,或者“我想分段我的生产环境”这种自然语言,而非难以理解的IP地址等网络语言。
一旦你让这种语言或者策略就位,策略计算引擎(PCE)将把它翻译成本机第三层/第四层状态防火墙的规则,并将其发送回VEN。
虚拟执行节点(VEN)所做的并不只是强制执行任何操作,相反,它还会对Linux的iptable进行编程,也对Windows的Windows过滤平台(Windows Filtering Platform)进行编程。而且,还可以跨Solaris或AIX这样的遗留系统,来实现这一点。
故事并没有结束,因为您的应用程序总是在变化。当您从一个数据中心故障切换到另一个数据中心时,会发生什么呢?或者说当你迁移到云端时?VEN都会向PCE更新这些变化信息。而PCE则会不断地重新计算策略,以确保VEN上的策略是最新的。
02
工作负载微分段之“三步走”方法论
何谓工作负载?在Illumio的话语体系中,工作负载指的是网络上的端点,可以是物理或虚拟服务器、公有云实例、容器、存储设备、负载平衡器或代理设备上的VIP,或者任何具有IP地址的东西。
如上篇所述,Illumio高度概括了实施零信任微分段的“三步走”方法:

图3-工作负载微分段的“三步走”方法
第一步是获取地图:Illumio使用“应用程序依赖关系图”(Application Dependency Map),来实现应用程序实时地图(Application Real-time Map)。从而获得了应用程序级(而非网络级)的上下文,包括应用程序组件以及这些组件之间关系的可见性。这是上一篇介绍的重点。
第二步是给工作负载打标签:采用四个维度的通用元数据,对工作负载打标签,并且根据标签进行分组。从而获得了带标签的应用程序实时地图。上一篇也做了简单介绍。
第三步是制定和实施安全策略:这是本篇的重点。首先,要轻松的编写安全策略,本就是一件难事。另一个难题是:在真正强制执行安全策略之前,您需要一种方法来测试和建模这些策略。因为我们经常看到客户长期陷入这种状态:他们在提交新的安全策略后,只能祈祷这些策略不会破坏他们的应用程序。这正是因为他们缺少一种方法,在进入强制执行之前测试他们的安全策略。
03
四维标签模型及其数据治理
1)Illumio的四维标签模型
安全策略的前提是标签模型。Illumio的安全策略是根据四个标签维度编写的。如下图所示。

图4-四维标签模型
标签模型的关键之处包括:
务必谨记:标签不是组。每个标签维度都是独立的,标签可以组合起来,为每个工作负载形成一组唯一的安全属性。
Illumio的四维标签模型是构建可扩展和可管理的安全策略的关键。基于上述四个维度交叉点的策略,不仅易于实施,而且易于审查和维护。而常见的标签模型,如扁平组(flat groups)或任意级别“标记(tagging)”,则通常很不灵活。
每一个标签维度都应该被用来引用同一个逻辑概念。比如说,如果角色(Role)标签用于表示应用程序的分层,就不应该再用于表示信息敏感度的分级。
2)标签数据的来源
大多数组织都有一些资源,可以利用它们来获取至少一个标签维度。大型企业通常有CMDB或其他功能齐全的目录,较小的组织可能有一个电子表格,甚至是一个主机名约定。虽然可能不完整或不准确,但都没关系。
在应用Illumio解决方案的早期,客户需要识别哪些资源可以为其工作负载提供部分或全部标签数据。当需要将这些数据提供给PCE(策略计算引擎)时,既可以手工输入,也可以使用Illumio的API一次性或持续地自动同步。
3)标签数据的质量
如果客户担心没有一个完整的目录或可靠的标签数据来源,那就别费心了。通常来说,客户通常能够以50-80%的信心提供环境(Environment)标签(即这是生产工作负载,还是非生产工作负载?),而对其他标签维度的信心则低得多。
Illumio是基于现有目录不完整或不正确的预期而构建的。采用Illumio控制过程,可帮助客户提纯和改进元数据。在客户刚开始的时候,客户并不需要有一个高质量的目录,但是在完成的时候却可能拥有一个高质量的目录。
4)标签数据的治理
为实现自适应安全,需要了解环境中可能影响安全性的变更。包括供应新的工作负载和停用旧的工作负载,以及标签变化,例如将非生产服务器升级为生产服务器。
如果客户的标签数据是手工维护的,那么客户需要包含一个过程,以便在发生变更时更新PCE。
如果客户使用Illumio的API将标签数据加载到PCE,则更新通常每天进行,也可以根据需要随时进行,包括在变更发生时实时进行。
许多组织选择实施数据治理过程或指定一名数据监护人来管理目录中数据的质量。客户通常会发现,在元数据质量方面的投资,会带来广泛的安全性和运行性好处。
5)从网络语言转向自然语言
标签的概念可能看起来很小,却值得强调。使用标签(即自然语言)来定义安全策略,与数十年来使用网络语言(IP、VLAN、端口等)定义安全策略相比,是一个重大变化。至少表现在两个方面:一是自然语言更加容易理解,便于跨越安全、网络、应用团队之间的交流;二是自然语言更加稳定,与网络基础设施无关,即使工作负载跨越网络结构发生迁移,安全策略也无需改变。
04
应用程序的五级可见性
1)第1级可见性:全局视图
首先,登录到策略计算引擎(PCE)web控制台。在这里,有一个Illumination应用程序,它可以生成实时高保真的应用程序依赖关系图。它可以显示,我的应用系统如何分布在不同的位置。如下图所示:
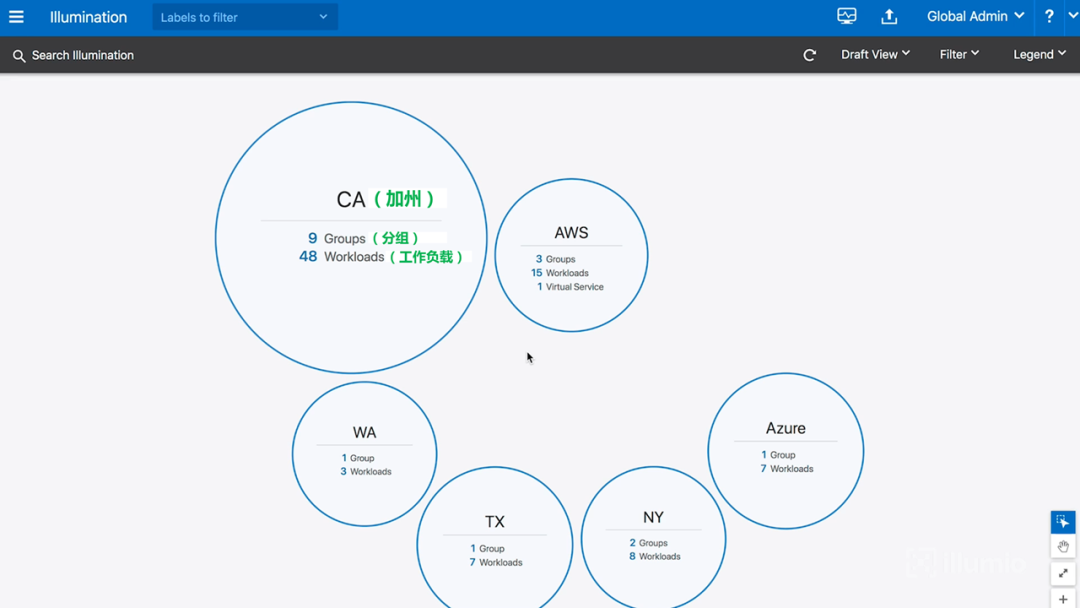
图5-应用程序分组(全局视图)
图中可见,我有一个CA(美国加州,California)数据中心(图中左上角最大的圆圈),其中包含9个分组和48个工作负载。另外,我在云上还有不同的实例,比如AWS和Azure(图中另外两个圆圈)。这是一个高层级的视图。
2)第2级可见性:单个数据中心
当我点击加州(CA)数据中心后,就好像掀开了它的屋顶,看到数据中心里面的各个应用程序。如下图所示:
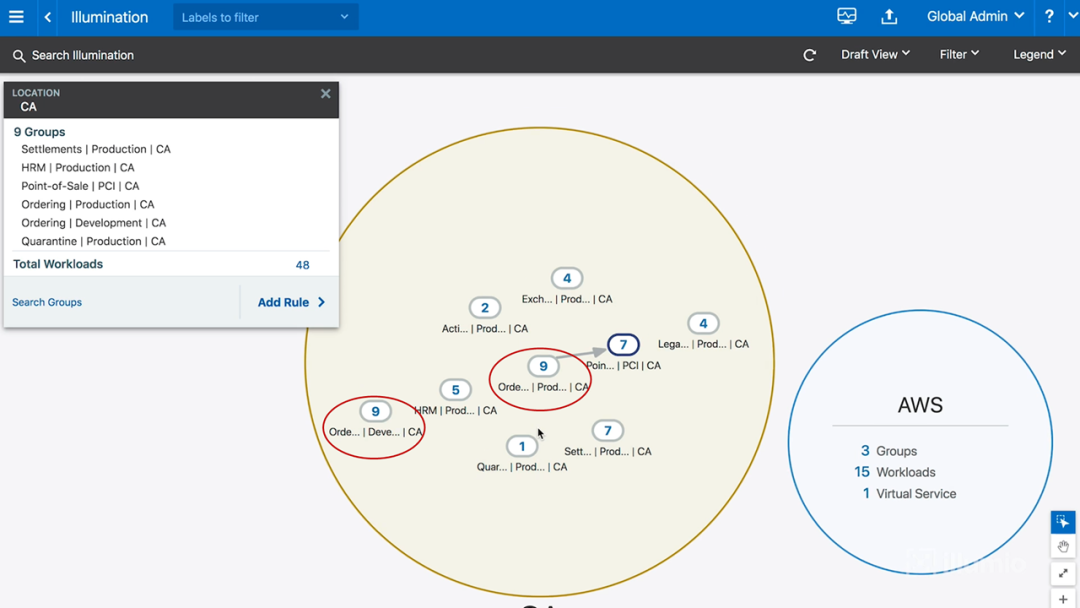
图6-加州(CA)数据中心的内部(含应用程序分组)
可见,加州数据中心有9个不同的应用程序分组在运行。 但注意,大圆圈中9个分组中的数字,并不是分组编号,而是该分组中的工作负载数量。如果把所有数字加在一起,正好是48个工作负载(与图5中的工作负载数量是一致的)。需要注意的是,订单应用程序(Ordering)被分成了两个,即在开发环境中的订单应用程序和在生产环境中的订单应用程序(笔者用两个红圈做了标记)。这正是四维标签发挥的作用。
另外,上图中那条带箭头的直线,表示有流量从生产环境中的订单应用程序,流向PCI环境中的销售点(point of sale)应用程序。
3)第3级可见性:单个应用程序
但我可以更进一步,看看加州数据中心生产环境中的订单应用程序,即Ordering|Production|CA(即上图的中间数字为9的应用程序分组)。点击这个分组后,会看到该分组的内部情况,如下图所示:
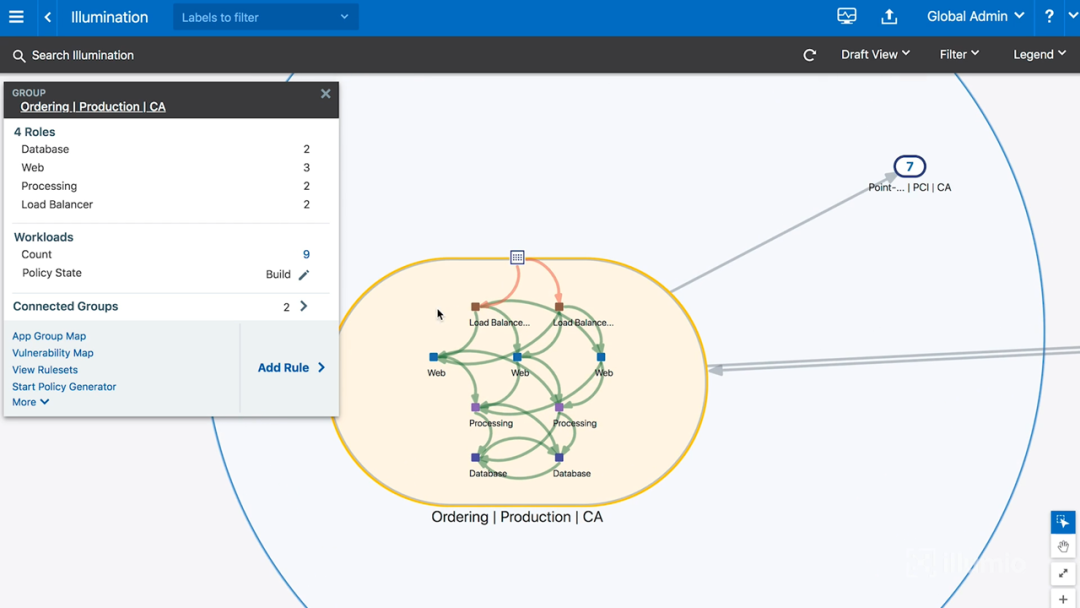
图7-一个应用程序的内部(含工作负载)
可见,它由9个不同系统组成,它们可能是裸金属、VM、容器。 而它们具体是什么形态,却无关紧要。这就是Illumio一直在强调的网络无关性(即可以不考虑网络基础设施的具体形态)。
我们还可以看到主机和主机之间存在依赖关系:红线表示我们检测到了流量,但缺少一个允许这种流量发生的策略;绿线表示我们检测到了流量,并且已经制定了策略来规范这些流量。当我们分别点击红线和绿线时,如下图所示:
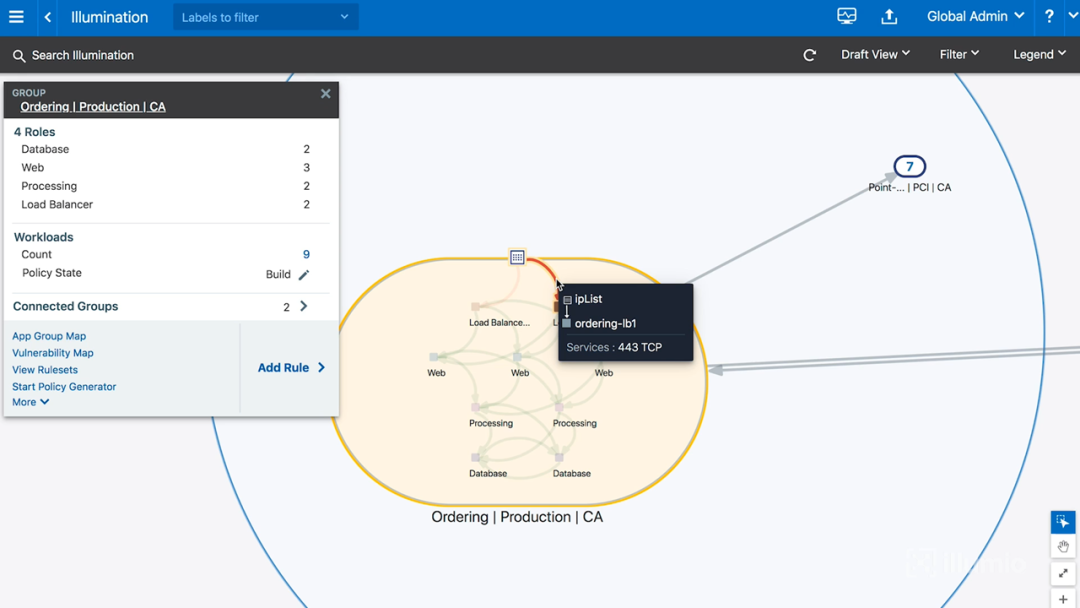
图8-点击红线时显示的信息
上图浮现的信息表明:这条红线流量是从ipList到ordering-lb1(订单程序-负载平衡1号主机),使用了TCP协议443端口。
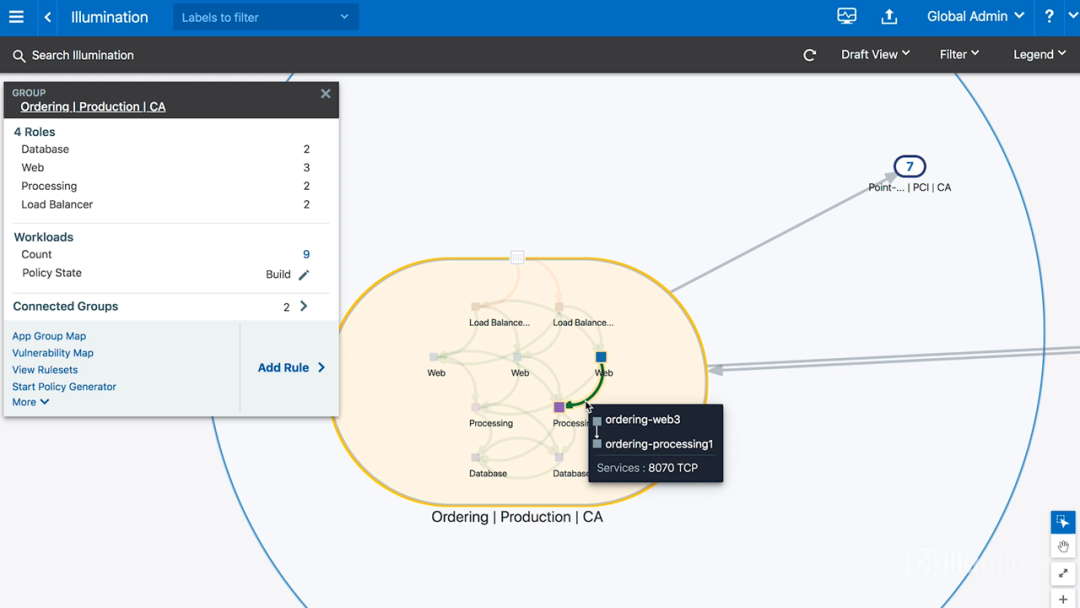
图9-点击绿线时显示的信息
上图浮现的信息表明:这条绿线流量是从ordering-web3(订单程序-web层3号主机)到ordering-processing1(订单程序-处理层1号主机),使用了TCP协议8070端口。
4)第4级可见性:单个主机(工作负载)
更进一步,我们还可以提供主机级的洞察,例如在每台机器上运行或打开的各个端口和进程。
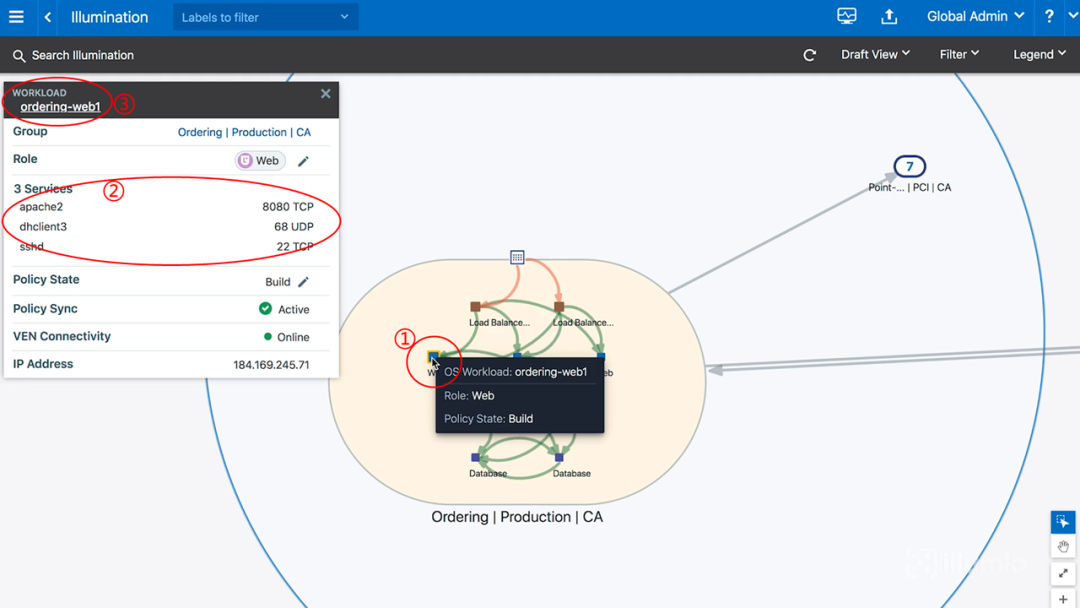
图10-查看单个主机
当点击编号①处的主机时,会浮现出信息:工作负载(OS Workload)的名称是订单程序web层1号(ordering-web1);角色(Role)是Web;策略状态(Policy State)为构建(Build)状态(后面会讲到这个)。
而且,左上角还同步显示了该主机的相关信息。比如在编号②处,显示了该主机上运行的3个服务进程以及相关的协议和端口号。
进一步,我们还可以点击编号③处的ordering-web1,进入到主机内部,查看更多信息。如下图所示:
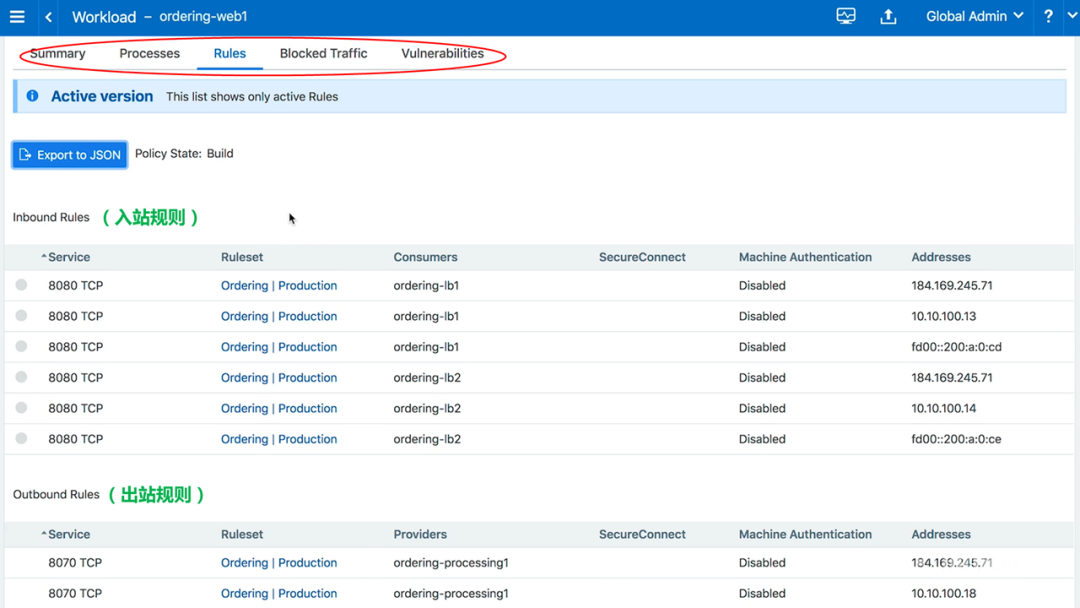
图11-查看主机内部的更多信息
在红圈处可见,包括摘要(Summary)、进程(Processes)、规则(Rules)、阻塞流量(Blocked Traffic)、漏洞(Vulnerabilities)等菜单信息。其中,摘要菜单中显示了主机运行的操作系统等信息。规则菜单中可以看到策略计算引擎(PCE)翻译并发送到VEN以编程到该主机iptable中的各个规则,如入站和出站的3层/4层状态防火墙的规则。这些提供了很好的洞察能力。
5)第5级可见性:跨多个数据中心的单个应用程序
前面的应用程序它只位于一个(地理)位置,即加州数据中心。现在,我们回头看看混合部署的Settlements(结算)应用程序,它不仅位于加州数据中心,而且还运行了Amazon中的一个实例。如下图所示:
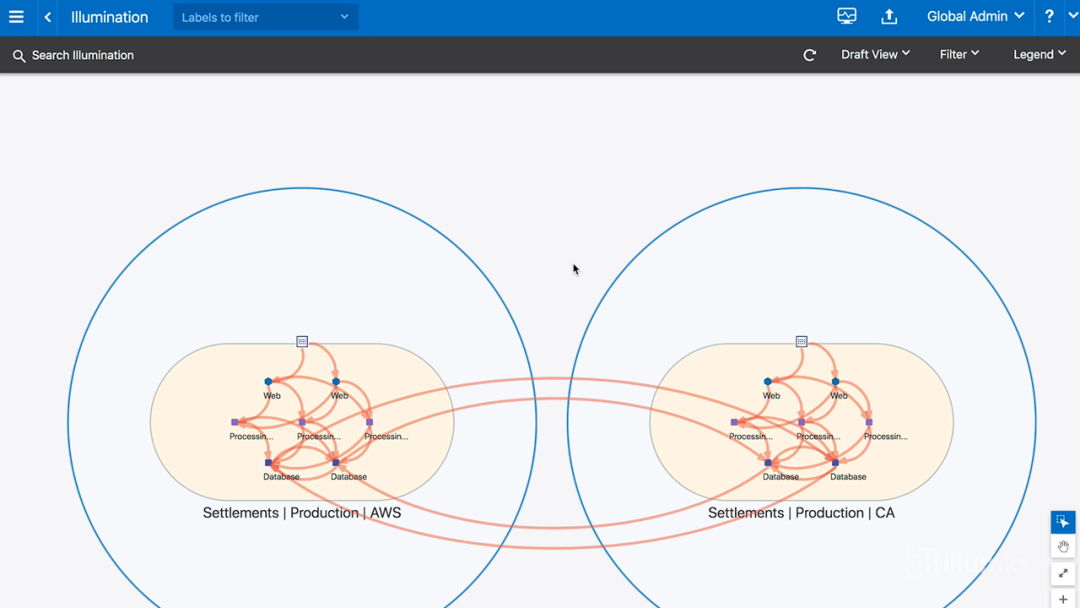
图12-跨数据中心混合部署的应用程序
图中还可以看到,在两个数据中心的数据库层之间存在活跃通信(即图中两个蓝色大圆圈之间的4条红线)。
虽然这看起来不错,但还不够好。我们希望不考虑地理位置,将上图中相同应用程序的14个工作负载,合并到同一个分组中,这就是应用程序分组地图(application group map)视图,可以通过菜单App Group Map打开。如下图所示:
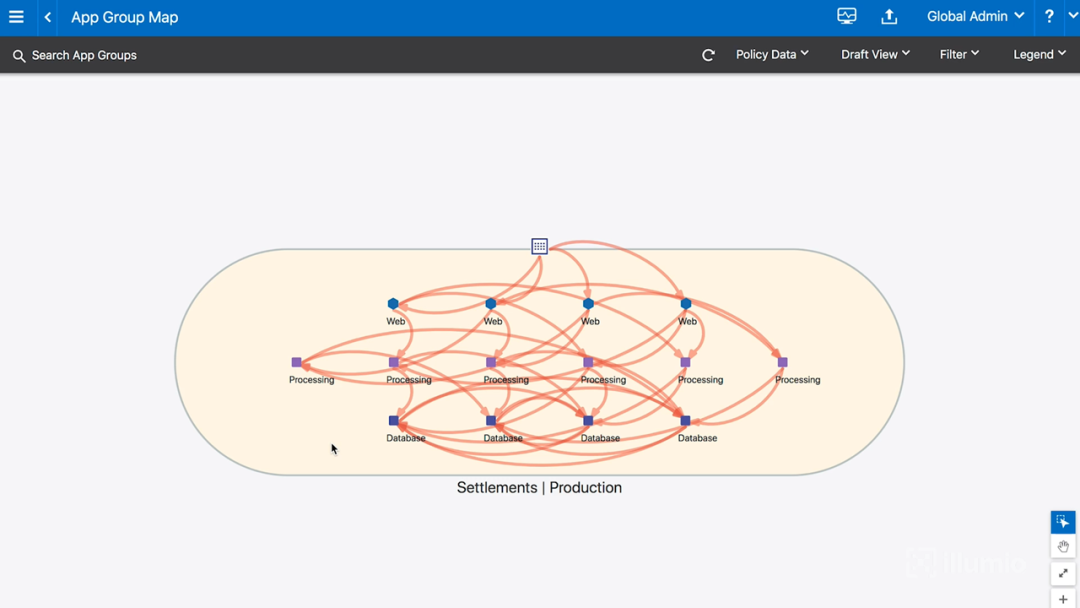
图13-应用程序分组地图
事实上,很多应用程序所有者都是这样看待他们的应用程序的,他们不一定在乎它的具体位置。
05
自然语言安全策略设置
通常,编写安全策略是相当复杂的,或者需要很长时间才能正确处理策略。但是策略计算引擎(PCE)中内置了很多工作流(workflow),使得安全策略的编写工作变得轻松。特别是策略生成器,大大简化了微分段策略的编写过程。
1)通过策略生成器编写安全策略
继续从上面的应用程序开始,如下图所示:
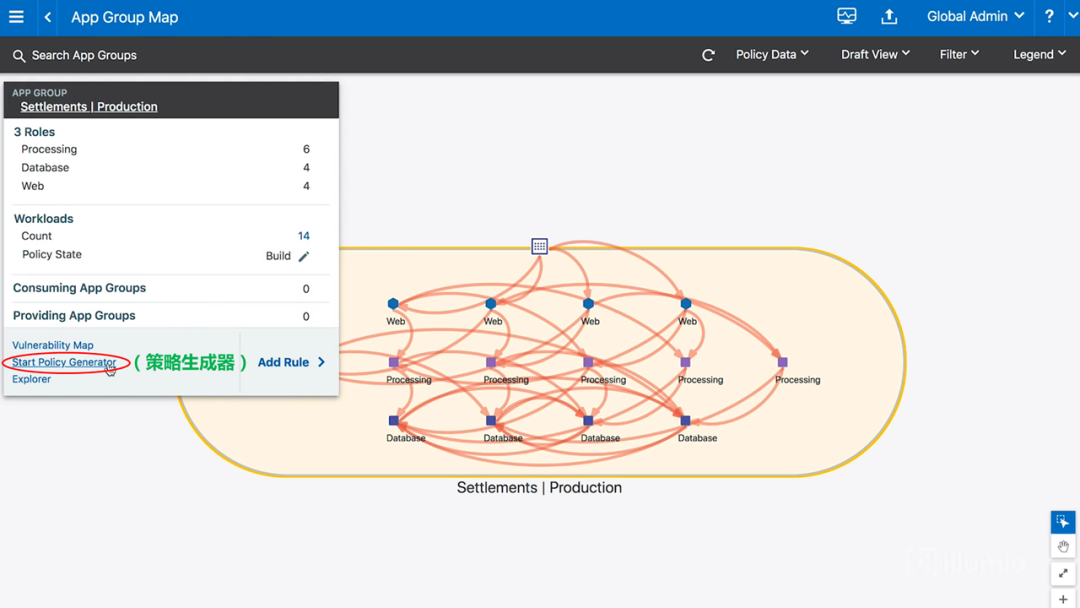
图14-准备设置安全策略
由于图中所有线条都是红色,说明还没有为这个应用程序编写任何策略。我们将使用策略生成器来编写安全策略。策略生成器会观察在应用程序内部或穿越应用程序的所有流量。然后,我就可以获得基于这些流量而自动化生成的策略。我们单击上图中的策略生成器,将出现如下界面:
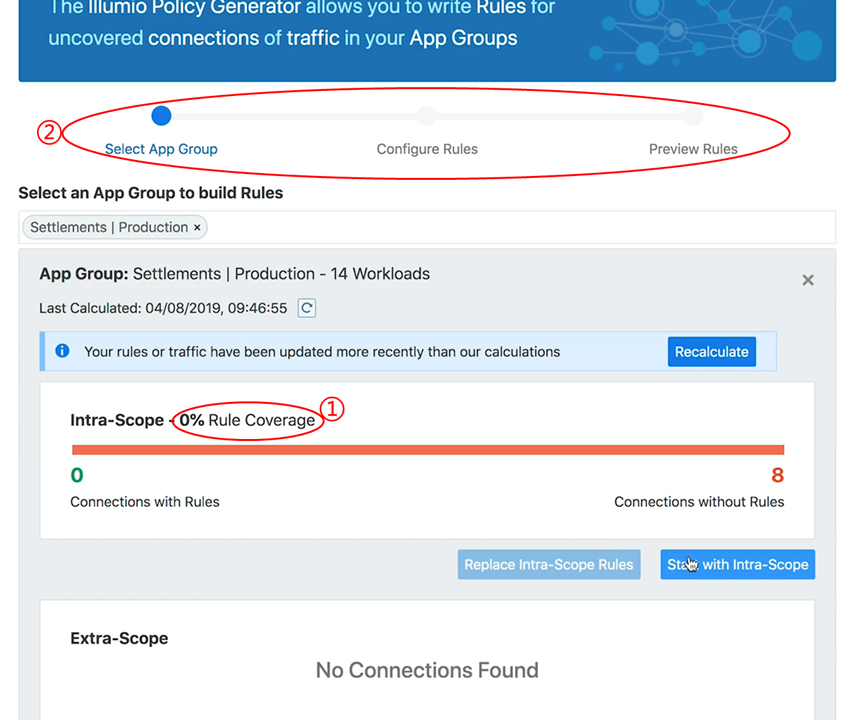
图15-策略生成器的界面
其中,编号①处表明,目前规则覆盖率为0%;编号②处表明,规则编写分为三个步骤:1)选择应用程序分组;2)配置规则;3)预览规则。
2)第1级安全策略:应用程序组级别
策略生成器支持不同粒度的策略层级:1)应用程序组级别(App Group Level);2)应用程序角色级别(Role Level - All Services );3)应用程序服务级别(Role Level - Specified Services );4)自动级别(Auto Level)。如下图所示:
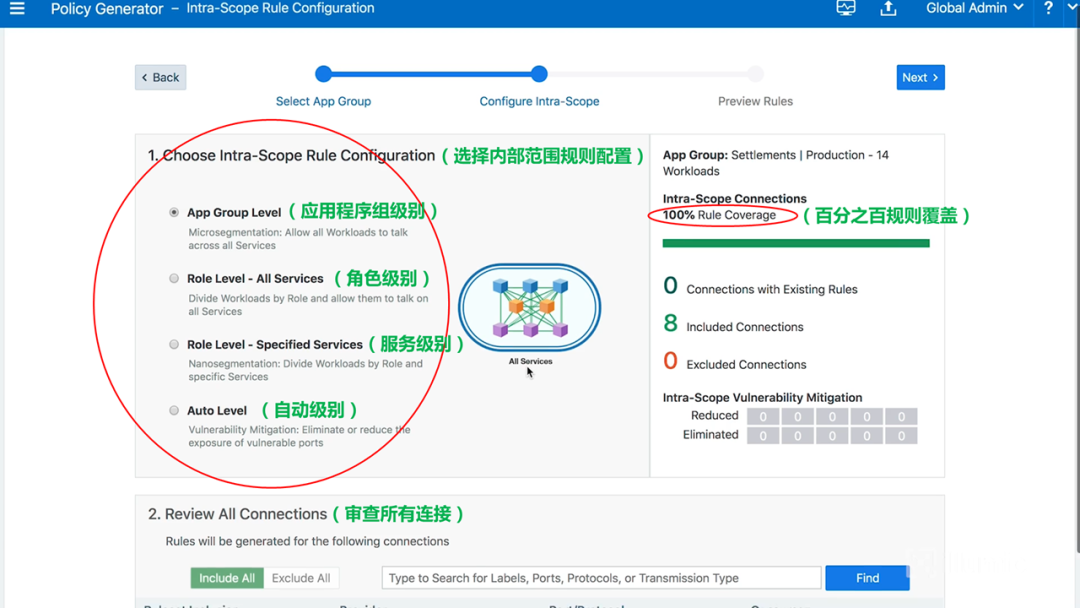
图16-安全策略的不同级别
一般而言,大多数客户会将应用程序组级别(App Group Level)作为起点。也就是在上图中勾选App Group Level选项。这意味着将在Settlements应用程序周围设置一个微边界。勾选好配置后,进入下一页"预览规则",如下图所示:

图17-安全策略的规则预览
可见,勾选App Group Level选项后,会自动化生成一条新的规则/策略,即:在该应用程序内部,允许所有工作负载与所有工作负载进行对话。
我们可以保存这条策略,然后返回到应用程序地图,就可以在地图上得到策略更新的实时确认。如下图所示:

图18-安全策略的实时更新
将该图与图14(准备设置安全策略)对比可知,该图中的内部连线已经全都由红色变成绿色。安全策略的覆盖由0%变成了100%。
3)第2级安全策略:应用程序角色级别
当然,为了设置更加安全的策略,我们可以在图16(安全策略的不同级别)中勾选应用程序角色级别(Role Level - All Services)的自动化安全策略。这会自动设置一个层到层的策略(角色级别也就是层级别),即:Web层可以与处理层对话,而处理层可以与数据库层对话,但是不允许Web层直接与数据库层对话。当这样设置后,我们进一步减少了攻击面。
4)第3级安全策略:应用程序服务级别
我们还能更进一步,在图16(安全策略的不同级别)中选择应用程序服务级别(Role Level - Specified Services )的安全策略。比如将策略设置为:Web层可以与处理层对话,但只能在OpenERP端口上,而我的数据库之间只能通过postgres互相通信。
点评:不论你选择哪种级别的安全策略,基本上只需要在策略生成器上做选择题就可以了。策略生成器将在几分钟内自动生成一致的微分段策略。而且,微分段策略是自然语言,任何应用程序团队都可以阅读和理解。
06
安全策略的测试验证
1)构建(build)模式
经过上面的步骤,我们已经做好了安全策略的配置。为了避免安全策略的变更对应用程序带来未预料的影响,我们需要对安全策略进行测试和验证。这涉及到策略状态(Policy State)的调整,如下图所示:
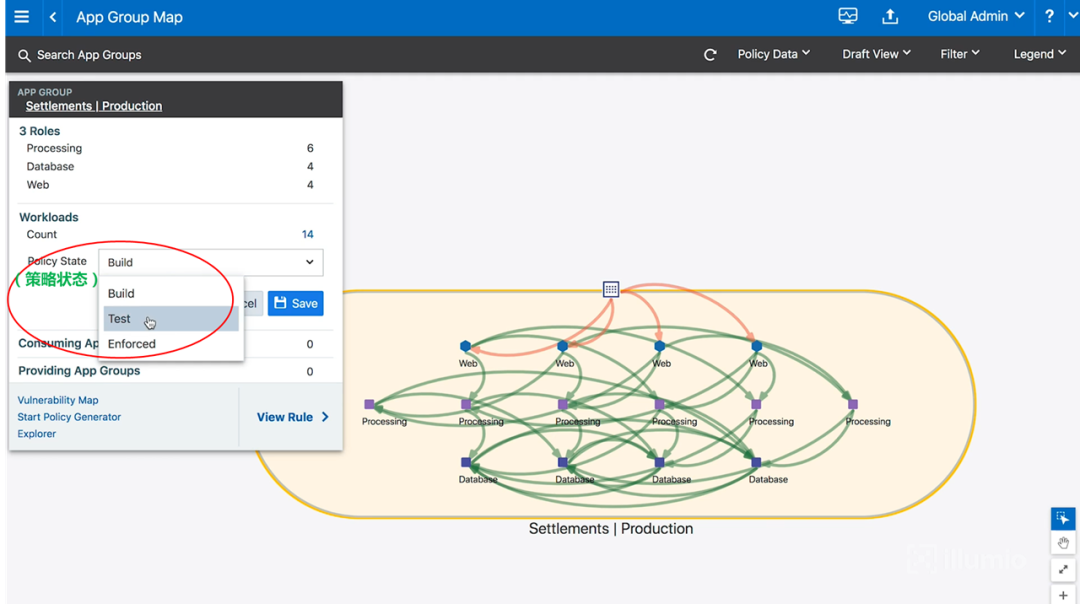
图19-策略状态的调整
图中可见,有三种策略状态:1)构建(build)模式;2)测试(test)模式;3)强制(enforce)模式。下面将分别介绍。
首先,要从构建(build)模式开始。这意味着,虽然我们将配置好的策略覆盖在地图上,但是我们仍然允许所有的流量通信发生,而不管你的策略是否真地允许。 也就是说,在构建(build)模式下,策略并不会真正阻塞流量。
2)测试(test)模式
一旦你觉得你已经有了正确的策略,你就可以更进一步,进入测试(test)模式。测试模式的作用,是将策略向下分配到每个单独的主机,但它会插入一条额外的策略行“允许any到any登录警报(permit any-any log-in alert)”。所以,在测试模式下,还是不会阻塞流量。
但是,如果流量应该被策略阻塞的话,则会记录这个信息并实时发送到策略计算引擎(PCE)。当然也可以把这个信息发送给你的SIEM工具,比如Splunk、QRadar。
比如,我可以点击图中的处理型(processing)工作负载,以查看本应该被阻塞的流量。如下图所示:
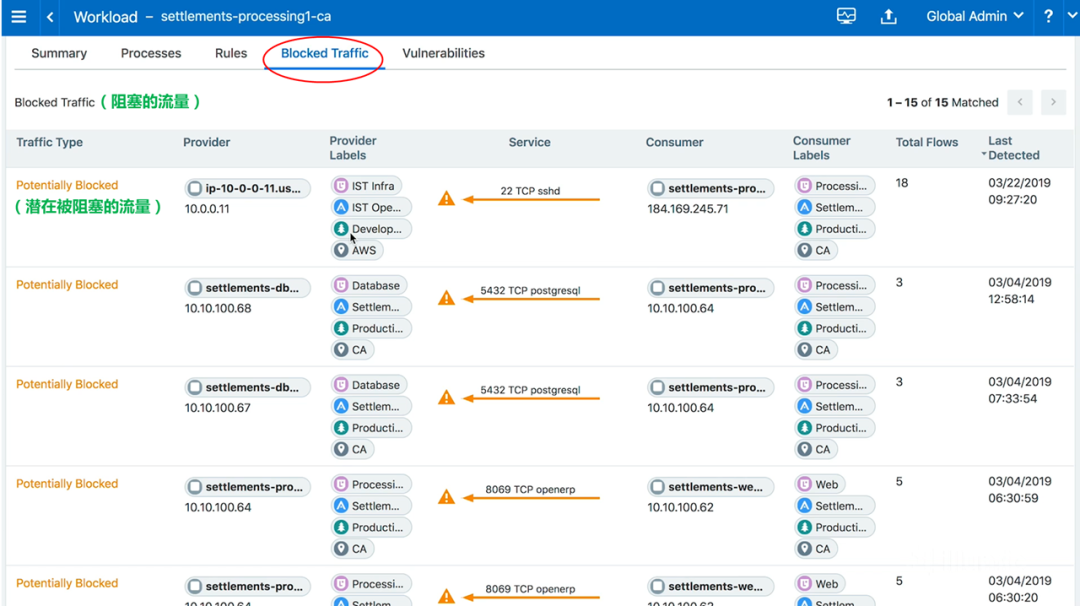
图20-查看本应该被阻塞的流量
实践表明,许多客户都会在这种测试模式下呆上一个月或者一两个季度,这样他们就可以充分地测试和验证安全策略变更的正确性。
3)强制(enforce)模式
一旦客户对上述测试模式感到满意后,他们将进入强制(enforce)模式,这会删除所有any到any规则,并强制执行严格的白名单策略模型。
上面就是进行微分段时你应该遵循的旅程,这样您就可以在不破坏业务运行的情况下安全地保护应用程序。
声明:本文来自网络安全观,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
