前言
近年来,随着数据挖掘、机器学习、深度学习等技术的兴起于发展,企业从普通用户处收集到了大量的数据,并对这些数据进行分析处理来了解用户的习惯和喜好,从而向用户提供更加个性化的服务。但是用户在日常生活中产生的数据包含了大量的个人敏感信息,直接发布或者进行分析会使得不法分子收集到用户的隐私。
2006年,Netflix举办了一个预测算法比赛,比赛要求利用公开数据推测用户对电影的评分。Netflix把数据中唯一识别用户的信息抹去,但是两位研究人员通过关联Netflix公开的数据和IMDb网站上公开的记录成功识别出匿名后用户的身份。
我们在讨论隐私保护的时候通常包括两种情况:
第一种是公司为了学术研究和数据交流开放用户数据,学术机构或者个人可以向数据库发起查询请求,公司返回对应的数据时需要保证用户的隐私。
第二种是公司作为服务提供商,为了提高服务质量,主动收集用户的数据,这些在客户端上收集的数据也需要保证隐私性。
匿名保护技术
1、k-匿名
K-匿名是一种数据匿名化方法,首先让我们看下面表格:
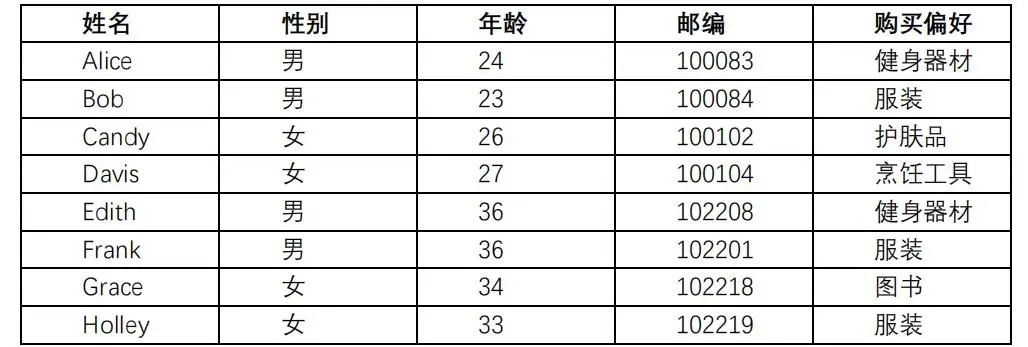
表格中的公开属性可以分为三类:
标识符: 一般是个体的唯一标识,比如说姓名、地址、电话等,这些内容需要在公开数据的时候删掉;
准标识符:类似邮编、年龄、生日等不是唯一的,但是能帮助研究人员管理相关数据的标识;
敏感数据:比如说购买偏好、薪水等等,这些数据是研究人员最关心的。
简单来说,K-匿名模型就是要求发布的数据中,指定标识符(标识符或准标识符)属性值相同的每一等价类至少包含K个记录。
举个例子,假设一个公开的数据进行了2-anonymity保护,如果攻击者想确认Frank的敏感信息,通过查询他的年龄、邮编和性别,攻击者会发现数据里至少有两个人是有相同的年龄、邮编和性别。这样攻击者就没办法区分这两条数据哪个是Frank了,从而也就保证了Frank的隐私不会被泄露。
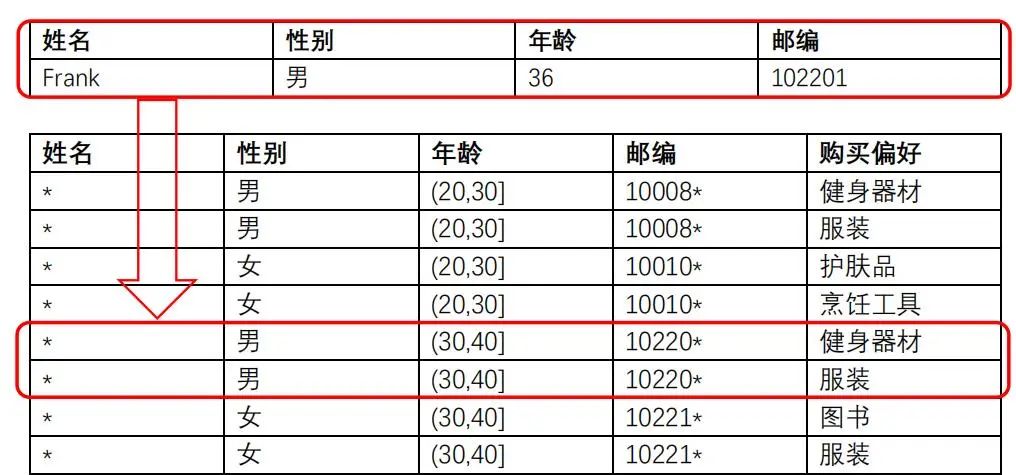
K-匿名方法主要有两种:
(1)一种是删除对应的数据列,用*号代替;
(2)另外一种方法就是用概括的方法使之无法区分,比如说把年龄这个数字概括成一个年龄段。
对于邮编这样的数据,数字若全用*号代替,数据会失去很多有意义的信息,可以选择删除其中一位数字。
攻击方法1:未排序匹配攻击
当公开的数据记录和原始记录的顺序一样时,攻击者可以猜出匿名化的记录属于谁。
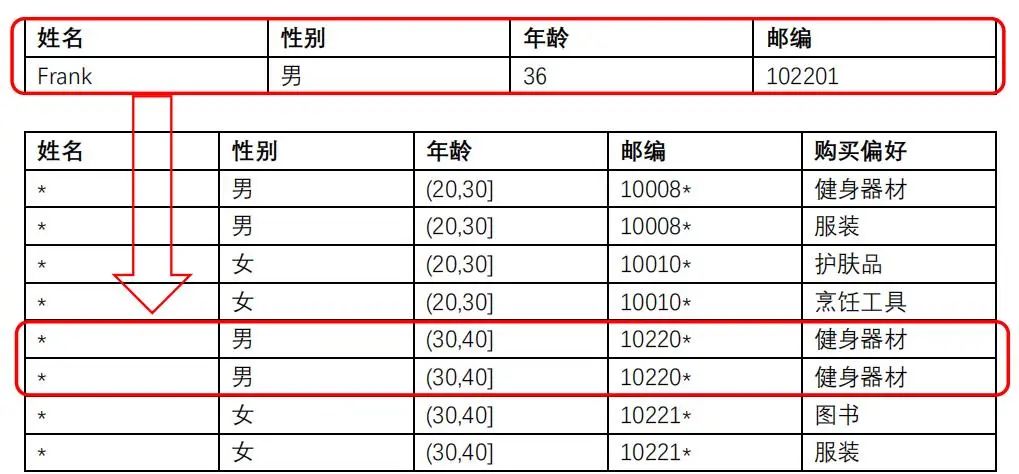
例如:如果攻击者知道在数据中Edith排在Frank前面,那么就可以确认,Frank购买偏好是服装。
防御方式:在公开数据前打乱原始数据的顺序。
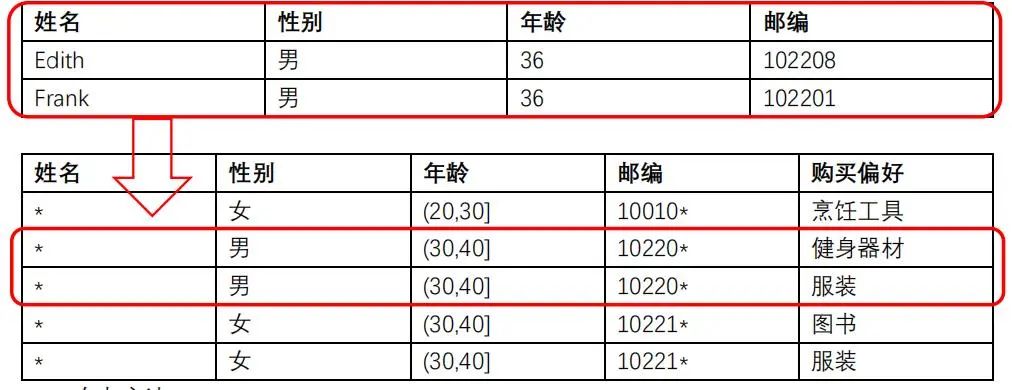
攻击方法2:同质化攻击
某个K-匿名组内对应的敏感属性的值也完全相同,这使得攻击者可以轻易获取想要的信息。
例如:Frank信息对应表中的两条记录购买偏好都是健身器材,那么就可以确认,Frank购买偏好是健身器材。
敏感属性缺乏多样性
攻击方法3:背景知识攻击
即使K-匿名组内的敏感属性并不相同,攻击者也有可能依据其已有的背景知识以高概率获取到其隐私信息。
例如:攻击者知道Davis的信息,并且知道她不喜欢购买护肤品,那么从表中,攻击者可以确认Davis的购买偏好是烹饪工具。
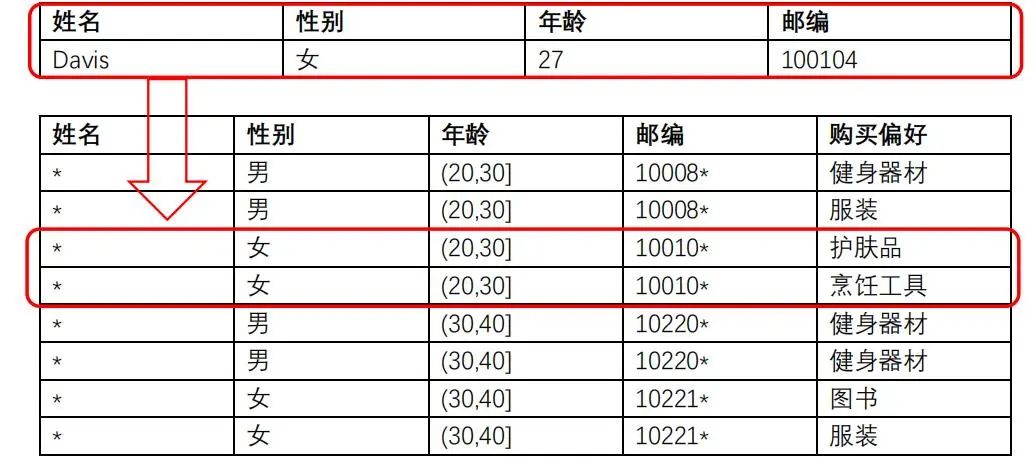 背景知识:Davis不喜欢化妆品
背景知识:Davis不喜欢化妆品
攻击方法4:补充数据攻击
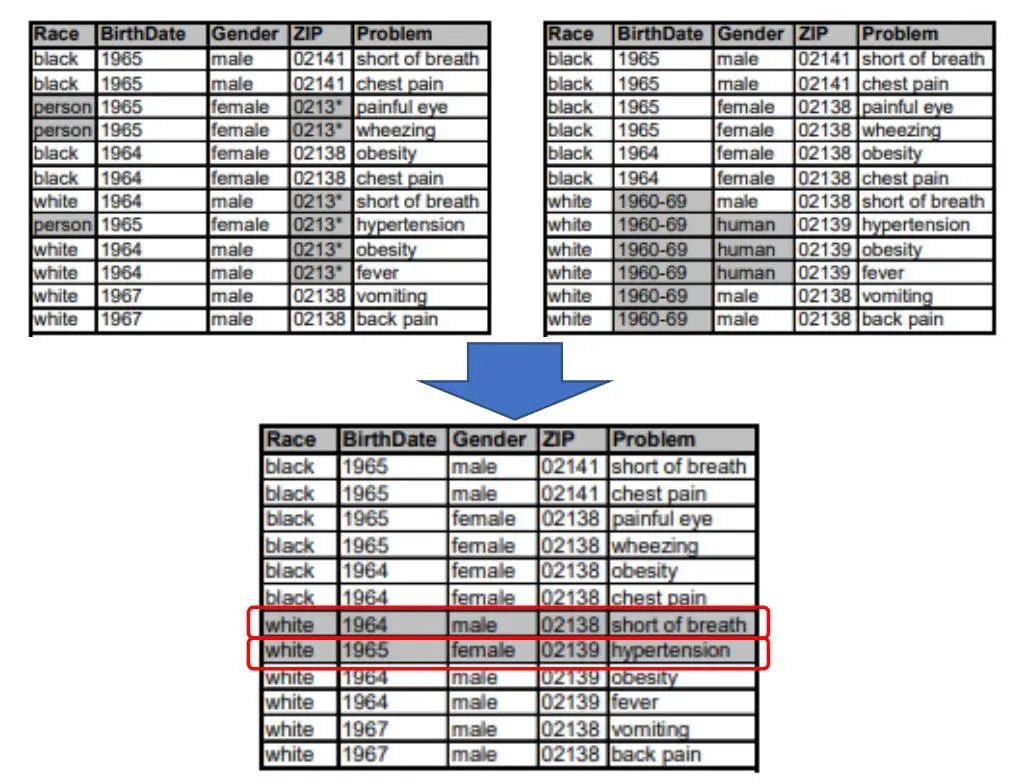
假如一份数据被公开多次,且它们的k-匿名方式并不一样,那么攻击者可以通过关联多种数据推测用户信息。
例如:从一个表中无法直接获取用户数据,这时引入多个表推测用户信息。下面的两个表都是满足2-匿名的,但是攻击者若将两个表格的数据进行拼接,形成一个新的表,可以发现新表中存在唯一的数据。
2、L-多样性
同质化攻击,引出了敏感属性多样性的概念。即在公开的数据中,对于那些准标识符相同的数据中,敏感数据必须具有多样性,这样才能保证用户的隐私不能通过背景知识等方法推测出来。
L-多样性保证了相同类型数据中至少有L种内容不同的敏感属性。
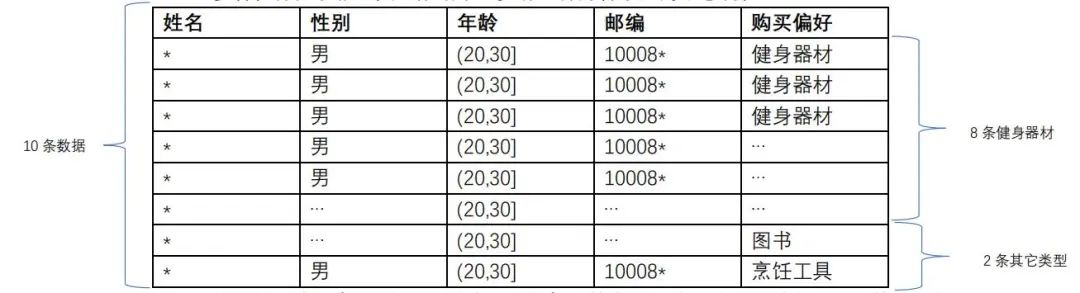
在这个例子中,有10条相同的类型的数据,其中8条购买偏好是健身器材,其它两条分别是图书和烹饪工具,那么在这个例子中,公开的数据就满足З-多样性。
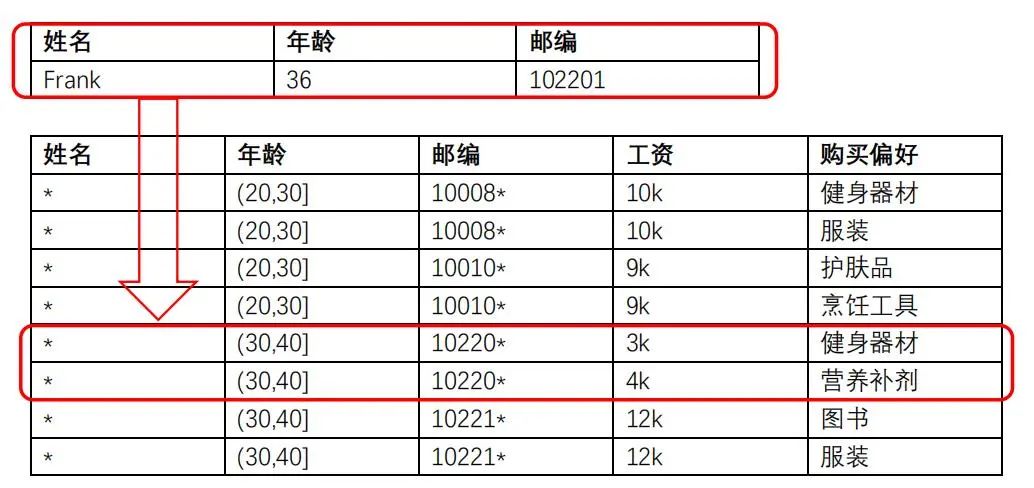
L-多样性没有考虑敏感属性的语义,比如说通过下面的例子,我们用Frank的信息从公开数据中关联到了两条信息,通过这两条信息我们能得出两个结论。第一,Frank的工资相对较低;第二,Frank是个锻炼爱好者。
3、T-接近
L-多样性引出了T-接近的概念,T-接近是为了保证在相同的准标识符类型组中,敏感信息的分布情况与整个数据的敏感信息分布情况接近,不超过阈值T。
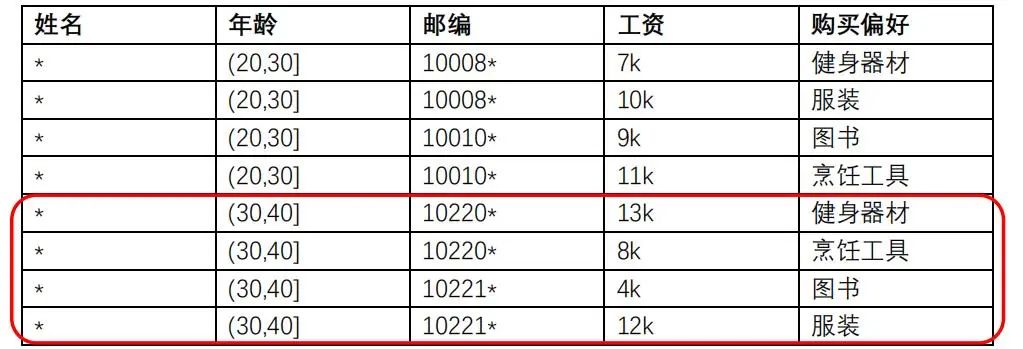
即使同时保证了K-匿名,L-多样性,T-接近,信息依然会因为攻击者的背景知识而遭到泄露。
攻击者通过Frank的个人信息找到了四条数据,同时知道Frank有很多书,这样就很容易在四条数据中找到Frank的那一条。
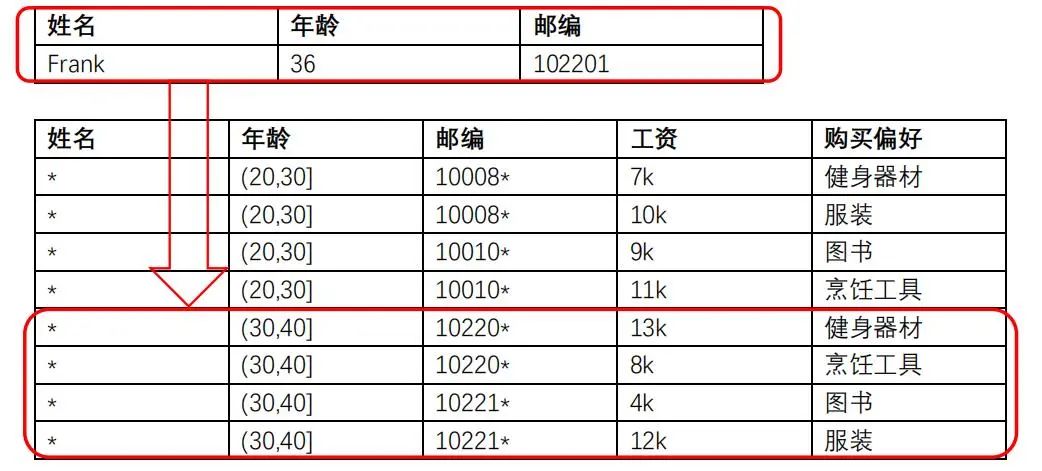
4、差分隐私
差分攻击:医院发布了一系列信息,说医院这个月有100个病人,其中有10个感染HIV。假如攻击者知道另外99个人是否有HIV的信息,那么他只需要把他知道的99个人的信息和医院发布的信息比对,就可以知道第100个人是否感染HIV。
2006年,微软的Dwork提出了差分隐私的概念,简单说来,就是用一种方法使得查询100个信息和查询其中99个信息得到的结果是相对一致的,那么攻击者就无法通过比较数据的不同找出第100个人的信息。这种方法就是加入随机性,如果查询100个记录和99个记录,输出同样的值的概率是一样的,攻击者就无法进行差分攻击。进一步说,对于差别只有一条记录的两个数据集 ,查询它们获得结果相同的概率非常接近。
,查询它们获得结果相同的概率非常接近。
差分隐私分为中心化差分隐私和本地化差分隐私。

中心化差分隐私处理框架
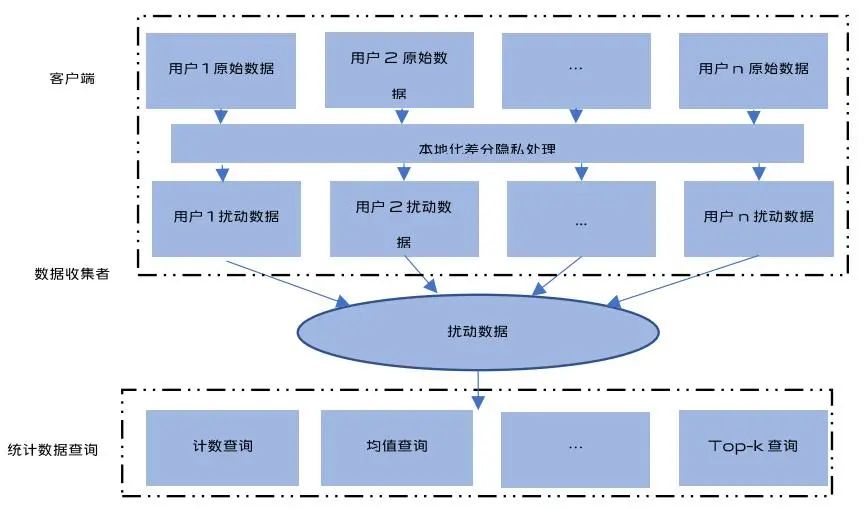
本地化差分隐私处理框架
定义:邻近数据集
若两个数据集可以通过对任一数据集添加或删除一条记录来得到另一个数据集,则称这两个数据集是邻近数据集。
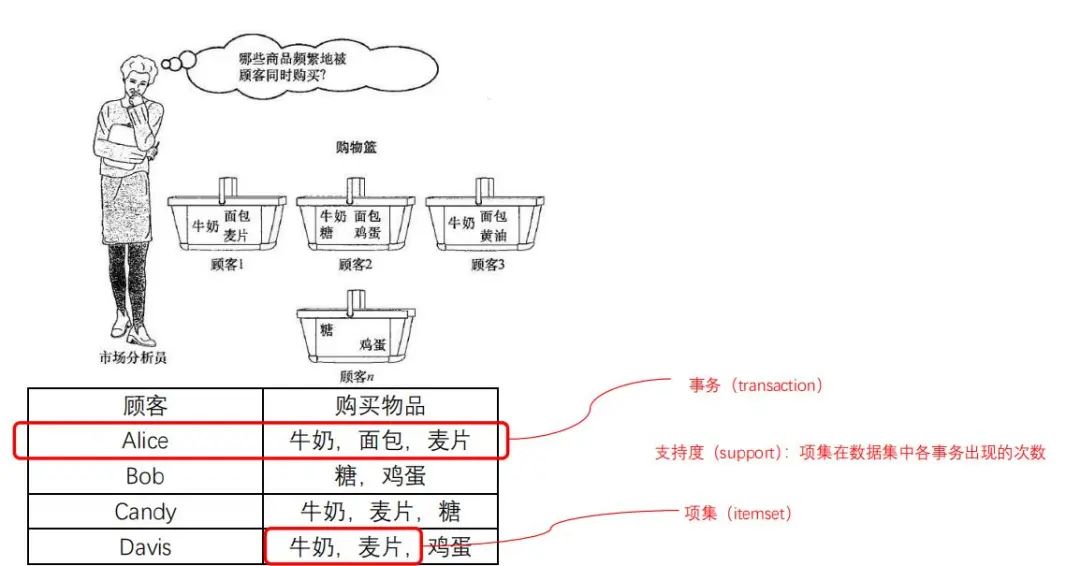
顾客 | 购买物品 |
Alice | 牛奶,面包,麦片 |
Bob | 糖,鸡蛋 |
Candy | 牛奶,麦片,糖 |
Davis | 牛奶,麦片,鸡蛋 |
顾客 | 购买物品 |
Alice | 牛奶,面包,麦片 |
Bob | 糖,鸡蛋 |
Candy | 牛奶,麦片,糖 |
Davis | 牛奶,麦片,鸡蛋 |
Edith | 牛奶,麦片 |
定义:ε-差分隐私
给定两个邻近数据集,若算法K,值域为Range(m),在
上任意输出的结果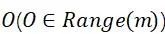 满足下面的不等式,则称算法K满足ε-差分隐私。
满足下面的不等式,则称算法K满足ε-差分隐私。
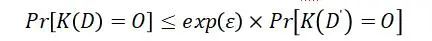
其中,Pr[.]表示算法K输出结果为Ο的概率,隐私预算ε控制隐私保护程度。ε值与隐私保护程度成反比,ε越小,需要添加的噪声越大,隐私保护程度也就越高。
定义:全局敏感度
对于某查询函数f的全局敏感度为:
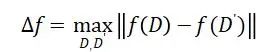
以求中位数函数为例,设函数为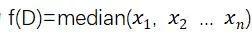 ,其中
,其中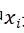 是区间[a,b]中的一个实数
是区间[a,b]中的一个实数
设数据集D为(a,a,a,b,b),那么函数的返回值即为a。
从中删除一个数,数据集变为(a,a,b,b)就使函数的返回值由a变为 ,因此函数的全局敏感度为
,因此函数的全局敏感度为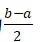 。
。
目前常用的有两种机制,一个是Laplace机制,在查询结果里加入满足Laplace分布的噪音,适用于数值型输出。
Laplace机制:对于任意一个函数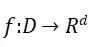 ,若算法K的输出结果满足下式,则算法K满足ε-差分隐私。
,若算法K的输出结果满足下式,则算法K满足ε-差分隐私。

其中,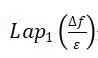 是相互独立的拉普拉斯变量,
是相互独立的拉普拉斯变量,  。
。

例如:知乎里有多少人是985大学毕业的?假如真实结果是2000人,那么每一次查询得到的结果都会稍稍有些区别,比如有很高的概率输出2001,也较高概率输出2010,很低概率输出1000,等等。
另一种是指数机制,在查询结果里用指数分布来调整概率,适用于非数值型输出。
指数机制:设有随机算法M,输入为数据集D,值域为Range,输出值为实体对象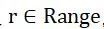 ,q(D,r)为打分函数,
,q(D,r)为打分函数, 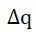 为打分函数q的敏感度,如果算法以正比于
为打分函数q的敏感度,如果算法以正比于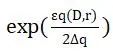 的概率从Range中选择并输出r,那么算法M满足ε-差分隐私。
的概率从Range中选择并输出r,那么算法M满足ε-差分隐私。
例如:
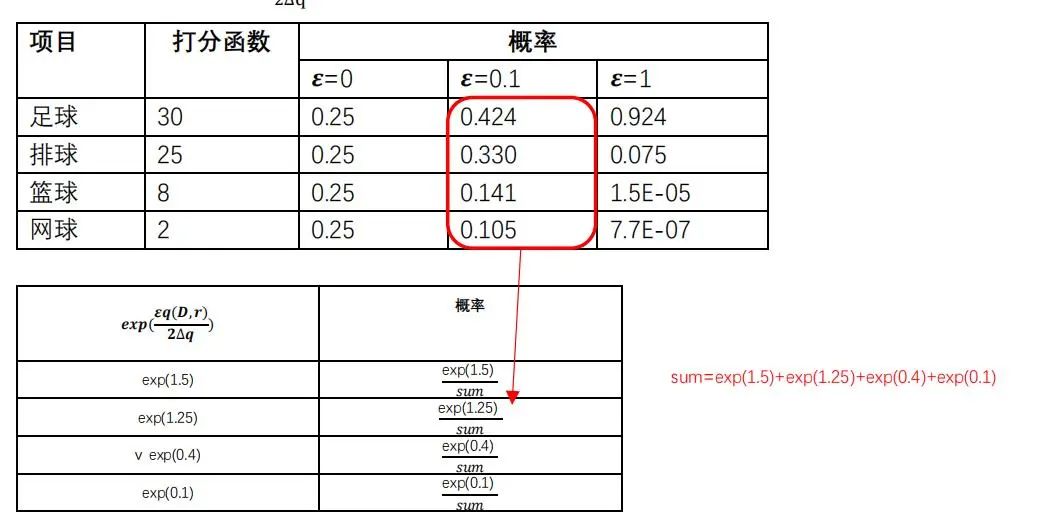
现在要举办一场体育比赛,可选的体育项目有{足球、排球、篮球、网球},观众对选择举办哪个体育项目进行了投票,我们要保证用户投票的隐私性,此时我们可以使用指数机制来满足ε-差分隐私。
投票观众为数据集D,值域为{足球、排球、篮球、网球},以项目得票数作为打分函数q,敏感度=1,因为少一个或多一个观众,对项目得票数的影响最多为1,在给定隐私预算的情况下计算的值,最后归一化,求出选择各个项目的概率。
 5、频繁项集挖掘
5、频繁项集挖掘
频繁项集挖掘是数据挖掘的核心问题之一,其目标是找出数据集中频繁出现的项集。
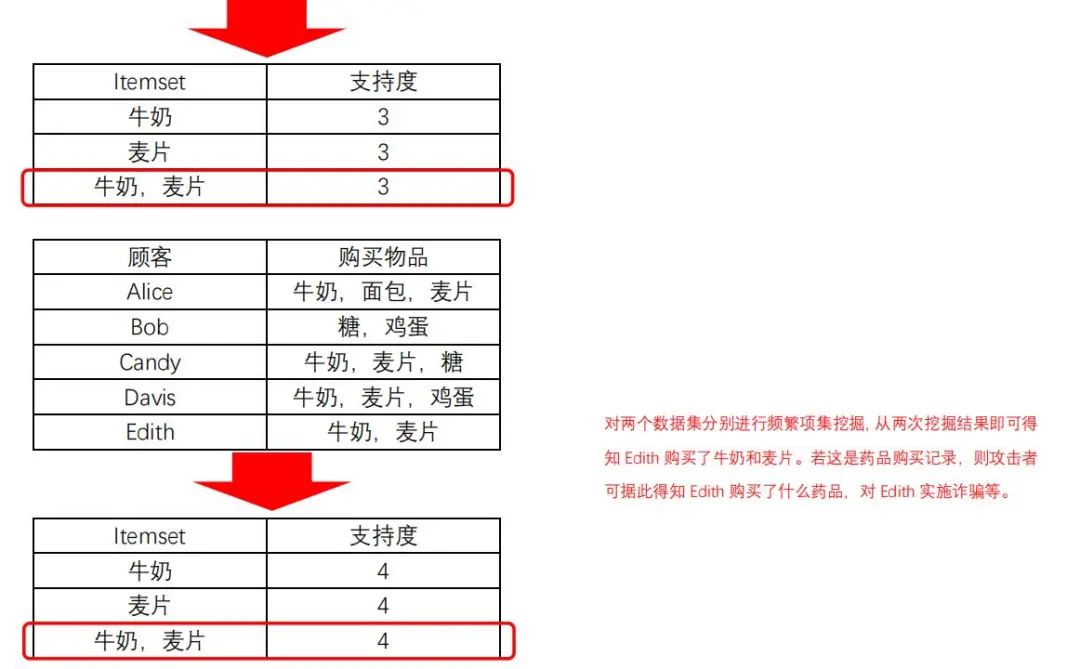
结合差分隐私的频繁项集挖掘算法步骤:
1)使用传统挖掘算法得到所有项集及其支持度;
2) 分配隐私预算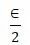 ,使用指数机制,从所有长度不超过阈值的项集中挑选k个项集;
,使用指数机制,从所有长度不超过阈值的项集中挑选k个项集;
3)分配隐私预算,对上一步挑选的k个项集,添加Laplace噪声。
Itemset | 支持度 |
牛奶 | 3.3 |
麦片 | 2.4 |
牛奶,麦片 | 2.7 |
Itemset | 支持度 |
牛奶 | 3.8 |
麦片 | 4.1 |
牛奶,麦片 | 4.3 |
存在问题
1、中心化差分隐私对于敏感信息的保护始终基于一个前提假设:可信的数据收集者。但在实际应用中想要找到一个真正可信的数据收集者十分困难;
2、如何在保护隐私的同时,最大限度地保留原数据中的有用信息。
声明:本文来自vivo千镜安全实验室,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
