实践DevSecOps的第一个误区,就是错把“DevSec”当成“DevSecOps”,忽视“OpsSec”;
系统不安全是常态,应急响应流程存在不足是常态,防微杜渐、严防死守的观念已经不适应现在行业发展,动态的安全就需要关注Ops领域。
作者:安全乐观主义
将安全性和可靠性结合
业界不少关于DevSecOps实践的文章,大都是一些静态代码检查、被动扫描器、安全框架和SDK、域名上线卡点之类的介绍,文章不约而同地避开了软件的维护、运维阶段。实践DevSecOps的第一个误区,就是错把“DevSec”当成“DevSecOps”,忽视Ops阶段仅将安全左移是一件简单的事,但不是正确的事。
笔者认为是时候谈谈安全和可靠的融合了,该领域是未来5到10年DevSecOps行业的主战场,而国内阿里、腾讯早已经在布局这方面的人员和技术积累。
错把“DevSec”当成“DevSecOps”
折腾开发人员是安全团队的一项传统技能,安全的偏见认为运维就是做申请机器,打补丁的事情,其实现在SRE的角色已经完全不同,虽然折腾SRE总是没人愿意去做,但是我们不能妥协,工作哪能不严格呢?和和气气怎么能把工作搞好,变革是需要付出代价的。
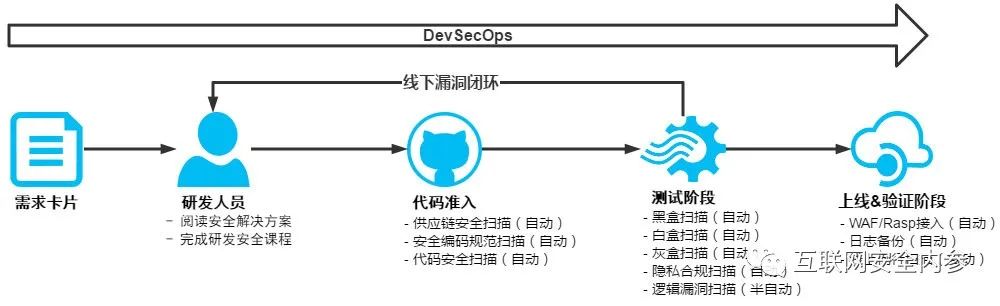
只关注dev的sec,不关注ops阶段的sec,主要体现在四个方面:
建设的思路受限于过去的经验。对于云原生项目、微服务、大数据、SaaS的项目,仅通过安全团队的web、移动应用安全审查,并说“安全审核通过,可以上线发布了”是不够的,谈到应用安全其实是指狭义的研发安全,好像以为主机系统安全、部署安全、运维安全、基础设施安全领域和自己没有什么关系,安全的手不能伸得太长,可是现在未来是“基础设施即服务”(IaaS)、”配置即服务“的趋势,不能仅仅关注代码维度了,要关注产品的全部生命周期。
选择做当前的事,不着眼于长远。当前的问题是仅在需求、设计和开发实施的阶段考虑安全性,对于业务视角来说,安全本身就是一个正在进行的项目,而这项工作随着企业软硬件的发展永远不会完成。我们总是可以做些事情来减少未来漏洞带来的风险和影响。
ROI不高。关注成熟度从80%到90%演变,而不是0到80%。我们总是以为公司的安全隐患是研发人员写的代码引入的,实际对于一次全链路攻击,利用代码安全漏洞仅仅是入口边界,提权、抓hash、未授权等横向渗透后果其实和开发人员没什么关系。现在能力大都集中在主要是防入侵而已,防范删库跑路不少公司是做不到的。花了很大精力去做长尾工作的扫描、修漏洞、告警能力,安全投资的回报已经不足,为什么不真实关注建设的短板呢?
忽略人的因素。是人就会犯错误,我们只能缩减问题发生的影响,永远不能完全解决问题。除了关注技术和流程,人的Operation因素是影响DevOps效果的最大变量。
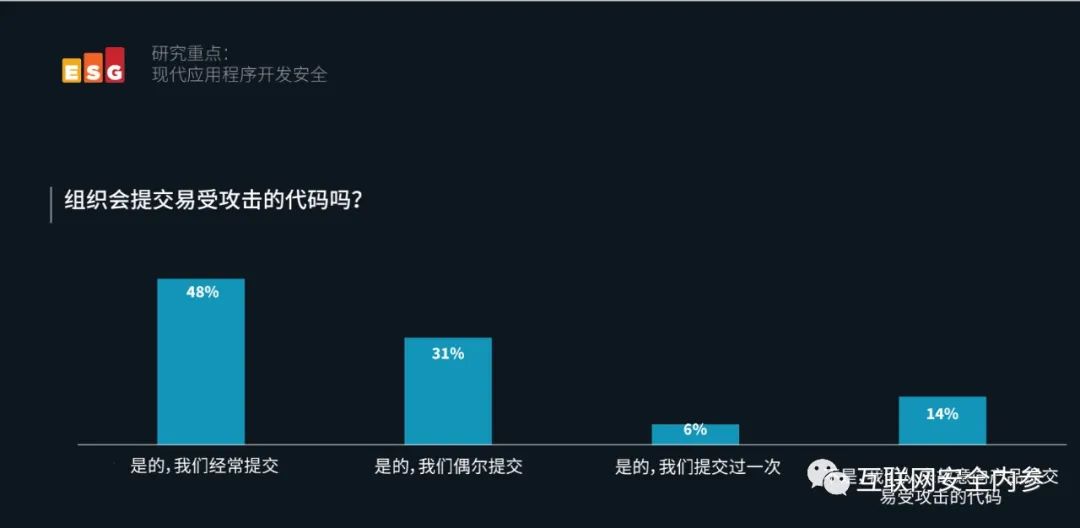
ESG对北美对私营和公共部门的IT和网络安全专业人员进行的调研显示,48%的组织故意将易受攻击的代码推送到产品中,说明工具流程虽然能检出,但是人却主动忽略放行。
还有个最近的例子,我们能否真正解决”删库跑路“问题?字节最近通过”传字节跳动实习生删库,公司通报为重要事故“事件回答:不能。
Secure Your Ops
DataOps、MLOps 和AIOps,可以统称为Operations(Ops\\运维)阶段。站点可靠性工程的概念由 Google 工程团队的 Ben Treynor Sloss 第一个提出。SRE 可以帮助团队在发布新功能和确保用户可靠性之间找到平衡。可靠性和安全性不可分割,没有安全性何谈可靠性,没有可靠性就没有可用性。SRE(或者是DevOps工程师)关注的稳定性和安全所关注的安全性问题,在解决思路策略、技术实现、对人的要求都是一致的,但现状是安全和SRE的沟通协作还远远不够。
我们永远无法理解我们自己的系统,安全还没理解这个道理,总是喜欢规范统一,现在我们构建的分布式关键系统变得如此复杂,以至于没有谁能够说明其整个运行本质。系统不安全是常态,应急响应流程存在不足是常态,防微杜渐、严防死守的观念已经不适应现在行业发展,动态的安全就需要关注Ops领域。业界已经有一些实践作用于安全和可靠性领域。
安全混沌工程-Security Chaos Engineering
红蓝对抗方式是一种偏向传统的思维,显而易见其不足之处在于:一、攻击者总是能发现缺陷,蓝队总是能收到告警,说不清到底有多少工作要做;二、虽然少数优秀的执行团队可以做到以周、月度为周期演练,频度仍然严重不足;三、不透明、不可重复实验、过程不可控,缺少持续的反馈。如果说红蓝对抗的定位是“发现建设存在哪些问题”,安全混沌工程则关注“建设这些问题的优先级”。
当我们面临一个复杂规模的业务系统时,出现安全漏洞几乎是必然事件,没有安全问题是偶然现象。不管你花多少精力进行漏洞修复,出现0day几乎是必然事件;不管你组织多少安全培训,员工点击钓鱼系统几乎是必然事件;不管你做多少风险感知能力,入侵行为发生快于阻断是必然事件。
根据《IBM Security 2020 Cost of a Data Breach Report 》52%的数据泄露是因为恶意代码攻击,23%的原因是人的犯错,25%的原因是系统故障。安全混沌工程通过观测应急响应、安全控制措施验、基线监控、风险发现等技术手段解决后两类问题,占比共达到48%!
将安全视为故障需要运维和安全共同进行改善,安全混沌工程通过快速检测服务是否健壮、安全、有足够的韧性、能否容忍意外的安全事件来提高企业安全架构的实用性。
韧性-Resilience
发生安全事件的第一步应该做什么?恢复业务正常运行进行止损。组织需要建立面对性能和安全威胁时,有效保持系统弹性和恢复的能力。今年RSAC大会探讨的韧性其实已经超越了安全的范畴,是踏踏实实的软件工程。韧性要求安全工作不仅仅重视拿结果,也重视过程阶段的成熟,引入了控制降级、冗余、弹性设计、隔离、自动缓解和恢复的概念。
Zero Touch
恶意用户(或者攻击者)尝试破坏系统、中断系统来影响服务可用性,我们必须将”人的因素“装在”笼子“里。想象一下,一位研发人员通过配置管理下发了一个错误的配置引起了软件变更,但是这个时候是不是绕过了code review和代码扫描?
Zero Touch通过审核每一次变更必须通过自动化、软件校验风险因子、可审计的备用措施来实现”提高生产安全性、避免中断“,被背后代表着需要落地大量安全原则,比如最小权限、前置安全检查策略、安全代理、审核、关注人和机器之间、机器和机器之间的交互。这方面需要建设工具链很多,安全的前景很大。
对待安全的观念需要立刻改变
笔者从不相信DevSecOps,指导所在领域建设的思路只有基础设施强制安全和极致自动化两个概念,DevSecOps这个名词的作用仅仅是说服合作伙伴达成协作而已:)
不要去保证100% 安全性,而是针对安全故障做好计划并妥善应对,现在开始关注Ops安全,立即行动起来吧!
参考资料
https://www.researchgate.net/publication/335922038_Security_Chaos_Engineering_for_Cloud_Services
https://www.freebuf.com/articles/security-management/275605.html
https://security.tencent.com/index.php/blog/msg/150
声明:本文来自互联网安全内参,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
