2021年6月10日,《数据安全法》正式颁布,于2021年9月1日正式施行,作为我国数据安全领域的首部基础法律,也是国家安全领域的一部重要法律,标志着我国以数据安全保障数据开发利用和产业发展全面进入法治化轨道。
1 背景由来

随着大数据时代的发展,数据信息已经成为了企业运行的重要资产。不同企业之间相互共享数据、分析数据,进而开展相关业务。然而,一些企业在对数据进行分析处理时,并没有对数据进行安全保护,导致数据存在泄露等风险。安全研究中心Ponemon Institute和IBM Security联合发布的《2019年数据泄露成本报告》中指出,超过100万条记录的泄露预计会给企业带来4200万美元的损失。在这样的背景下,数据泄露可能造成的潜在危害,驱使国家、行业、企业等各层面愈发重视数据安全问题。2021年6月10日,十三届全国人大常委会第二十九次会议通过并正式发布的《数据安全法》,明确指出数据安全需要通过必要措施,确保数据处于有效保护和合法利用的状态,以及具备保障持续安全状态的能力。
作为数据安全中重要的一环,数据脱敏也逐渐被人们所关注。数据脱敏技术是一种可以通过数据变形方式对于敏感数据进行处理,从而降低数据敏感程度的一种数据处理技术。使用数据脱敏技术,可以有效地减少敏感数据在采集、传输、使用等环节中的暴露,降低敏感数据泄露的风险,尽可能降低数据泄露造成的危害。
2 脱敏技术
2.1隐私数据脱敏技术
通常在大数据平台中,数据以结构化的格式存储,每个表有诸多行组成,每行数据有诸多列组成。根据列的数据属性,数据列通常可以分为以下几种类型:
序号 | 类型 | 性质 | 例子 |
1 | 可识别列 | 可确切定位某个人的列 | 身份证号,地址以及姓名等 |
2 | 半识别列 | 单列并不能定位个人,但是多列信息可用来潜在的识别某个人 | 邮编号,生日及性别等 |
3 | 用户敏感信息列 | 包含用户敏感信息 | 交易数额,疾病以及收入等 |
4 | 其他不包含用户敏感信息的列 | _ |
2.2 隐私数据风险泄漏模型
目前在隐私数据脱敏领域,有几个不同的模型可以用来从不同角度衡量数据可能存在的隐私数据泄漏风险。
2.2.1 K-Anonymity
隐私数据脱敏的第一步是对所有可标识列进行移除或是脱敏,使得攻击者无法直接标识用户。但是攻击者还是有可能通过多个半标识列的属性值识别个人。攻击者可能通过其他方式获得特定个人的半标识列属性值,并与大数据平台数据进行匹配,从而得到特定个人的敏感信息。
如表1所示,如果攻击者知道某用户的邮编和年龄,就可以得到该用户的疾病敏感信息。

表1 原始信息
为避免这种情况的发生,通常需要对半标识列进行脱敏处理,如数据泛化等。数据泛化是指将半标识列的数据替换为语义一致但更通用的数据,以上述数据为例, 对邮编和年龄泛化后的数据如表2所示。
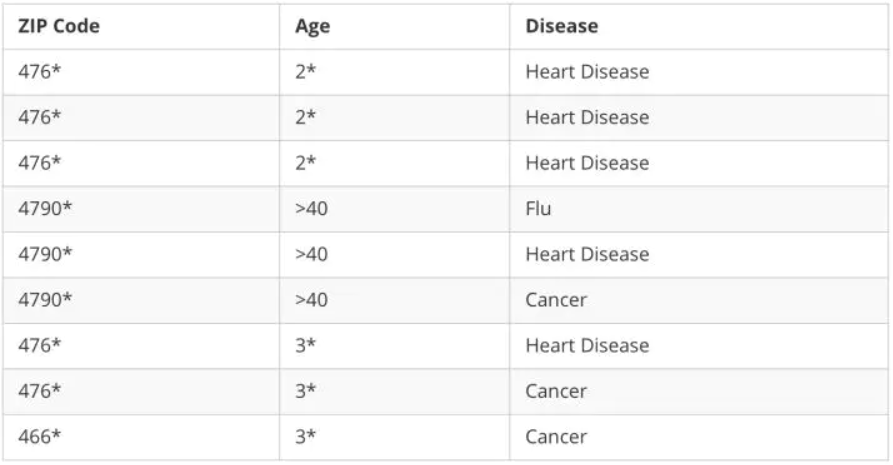
表2 3-Anonymity病人信息
经过泛化后,有多条记录的半标识列属性值相同,所有半标识列属性值相同的行的集合被称为相等集。如表2中1,2,3行是一个相等集,4,5,6行也是一个相等集。
K-Anonymity定义如下:
K-Anonymity要求对于任意一行纪录,其所属的相等集内纪录数量不小于k,即至少有k-1条纪录半标识列属性值与该条纪录相同。
表2中的数据是一个3-Anonymity的数据集。
作为一个衡量隐私数据泄露风险的指标,K-Anonymity可用于衡量个人标识泄露的风险,理论上来说,对于K-Anonymity数据集,对于任意纪录,攻击者只有1/k的概率将该纪录与具体用户关联。
2.2.2 L-Diversity
L-Diversity可用于保护个人标识泄漏的风险,但是无法保护属性泄漏的风险。对于K-Anonymity的数据集,攻击者可能通过同质属性攻击与背景知识攻击两种方式攻击用户的属性信息。
1. 同质属性攻击。对于表2半标识列泛化后的数据集,假如攻击者知道Bob邮编为47677,年龄为29,则Bob一定对应于前面三条记录,从而可以确定Bob有心脏病。
2. 背景知识攻击。对于表2半标识列泛化后的数据集,假如攻击者知道Alice邮编为47673,年龄为36,则Alice一定对应于后面三条记录,如果攻击者知道Alice患有心脏病的几率很小,则能判断Alice很有可能患有癌症。
L-Diversity定义如下:
如果对于任意相等集内所有记录对应的敏感数据的集合,包含L个“合适”值,则称该相等集是满足L-Diversity。
基于表2的数据通过插入干扰记录,一个3-anonymity 2-Diversity的数据集如表3表示:
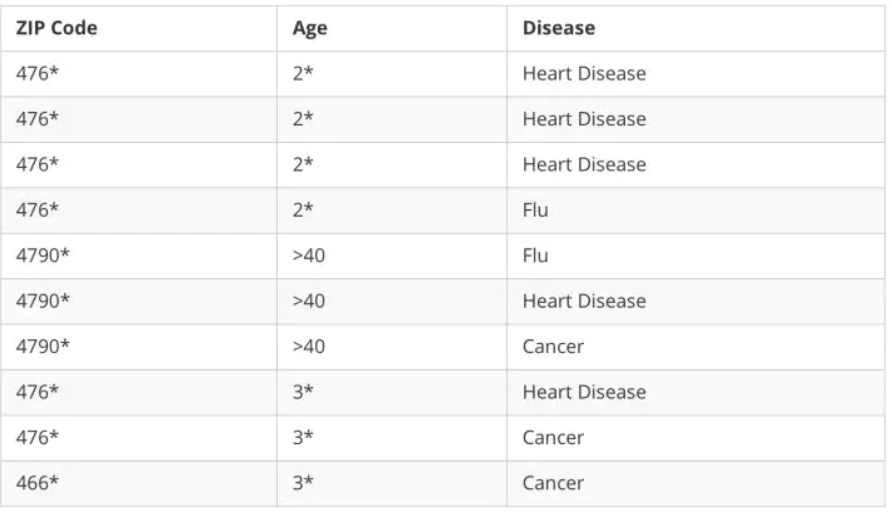
表3 3-Anonymity 2-Diversity 病人信息
相对于K-Anonymity标准,符合L-Deversity标准的数据集显著降低了属性数据泄露的风险。对于满足L-Diversity的数据集,理论上,攻击者最多只有1/L的概率能够属性泄露攻击,将特定用户与其敏感信息关联起来。
2.2.3 T-Closeness
直观来说,隐私信息泄露的程度可以根据攻击者增量获得的个人信息衡量。
假设攻击者在访问数据集之前已知的个人信息为B0,然后假设攻击者访问所有半标识列都已移除的数据集,Q为数据集敏感数据的分布信息,根据Q,攻击者更新后的个人信息为B1。最后攻击者访问脱敏后的数据集,由于知道用户的半标识列的信息,攻击者可以将某用户与某相等集联系在一起,通过该相等集的敏感数据分布信息P,攻击者更新后的个人信息为B2。
L-Diversity约束是通过约束P的diversity属性,尽量减少B0和B2之间的信息量差距,差距越小,说明隐私信息泄露越少。T-Closeness约束则期望减少B1和B2之间的信息量差距,减少攻击者从敏感数据的全局分布信息和相等集分布信息之间得到更多的个人隐私信息。
T-Closeness的定义:如果一个相等类的敏感数据的分布与敏感数据的全局分布之间的距离小于T,则称该相等类满足T-Closeness约束。如果数据集中的所有相等类都满足T-Closeness,则称该数据集满足T-Closeness。
T-Closeness约束限定了半标识列属性与敏感信息的全局分布之间的联系,减弱了半标识列属性与特定敏感信息的联系,减少攻击者通过敏感信息的分布信息进行属性泄露攻击的可能性。不过同时也肯定导致了一定程度的信息丢失,所以管理者通过T值的大小平衡数据可用性与用户隐私保护。
2.3 常见数据脱敏算法
K-Anonymity, L-Diversity和T-Closeness均依赖对半标识列进行数据变形处理,使得攻击者无法直接进行属性泄露攻击,常见的数据变形处理方式如表4:
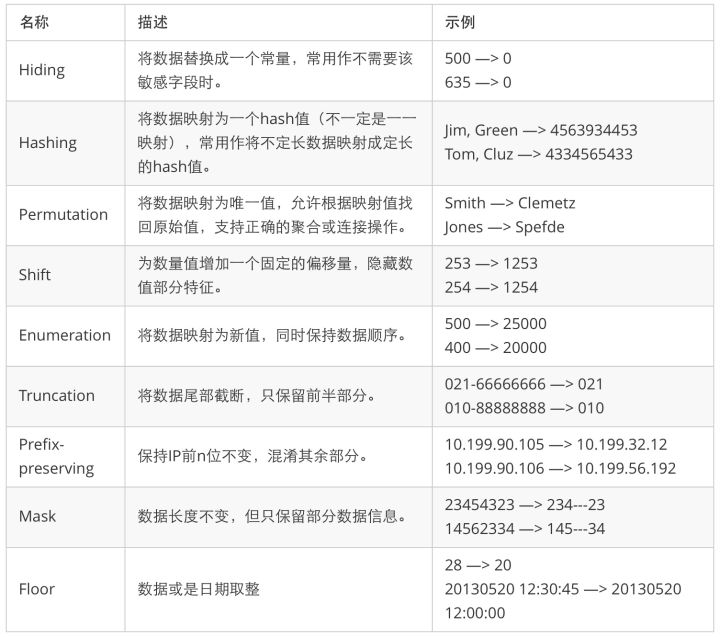
表4 常用数据变形操作
此外,K-Anonymity,L-Diversity和T-Closeness约束可能还需要生成干扰数据,敏感数据干扰项的生成策略与方法也是保证K-Anonymity,L-Diversity和T-Closeness的重要条件,在这里篇幅有限,就不过多介绍。
3 主要应用

随着互联网、云计算等信息技术与通信技术的迅猛发展,社会逐步进入了数据时代。海量数据在各种信息系统上被存储和处理,其中包含大量有价值的敏感数据。目前,大量敏感数据都存储在政府、企业或机构的数据平台中,基于当前的法律法规,数据在进行采集、传输、交换和共享的过程中要采用必要的手段防止数据泄露,保证数据安全。数据脱敏技术的应用目的主要包括两方面:一是以保护敏感数据安全、实现合法合规为主要目的;二是在达到第一目标的前提下,尽可能地保证数据可用性以及可挖掘价值。
数据脱敏技术通常应用在涉及到个人隐私数据存储和应用的部分行业领域,因此广泛应用于政务、金融、电信、医疗、能源、互联网等行业领域。在政务行业中,工商、公安、税务、社保等政府部门及公共事业部门,采集的公民个人信息及企业敏感信息,需要针对数据采集、传输、应用、归档等全生命周期进行数据脱敏并同步实施其他数据安全防护手段。在金融和电信行业中,由于金融客户的个人账户信息、交易记录等信息以及运营商内部存储大量的客户信息均属于敏感信息,对数据库查询返回的结果进行敏感数据遮盖,防止数据泄露。在医疗和能源行业,医院系统中存储大量患者隐私信息以及电力行业内部不同部门甚至是跨组织、跨区域间的电力数据共享场景越来越普遍,对敏感数据进行脱敏,既能满足国家对数据隐私保护的基准要求,又能对用户隐私数据的有效保护,维护和提升医疗和能源行业领域的形象和公信力。在互联网行业,用户行为数据更是成为企业指导业务增收的重要资源,用户行为分析、个性化推荐、精准营销等应用方向成为多数互联网企业的通用服务手段,相应地分析挖掘应用不可避免。
未来,越来越多的行业将采集数据,利用大数据技术提高产业效率,从而推动产业升级。数据量将进一步汇聚,规模将以指数级增长,数据脱敏技术的应用场景将扩展到国民经济的各个领域,随着需求的增长和多样化,数据脱敏技术也将得到长足的发展。
4 发展趋势

数据脱敏技术已成熟应用于部分领域,但伴随着脱敏需求的不断发展变化,仍存在继续优化演变的方向。后续数据脱敏技术的发展主要呈现出4个趋势。
4.1 提升数据脱敏性能
随着信息技术在各方面的一步步深入应用,各企业组织存储和使用的数据量的增长将十分迅速,相应地,需要进行脱敏处理的数据量也会同步提升;另一方面,依赖于数据分析进行即时反馈调整的数据应用,对于数据的实时性需求愈加强烈,在涉及到敏感数据的实时应用中,即时或短时间内完成大量数据的脱敏处理需求将会逐渐增多。数据量及响应时间两方面的需求变化要求研究如何提升数据脱敏技术的性能。
4.2 对非结构化数据的脱敏
相对于传统通过关系型数据库存储的结构化数据,在当前被存储和应用的数据中,图片、音频、视频等非结构化数据占比不断提升。众多智能化数据应用中对于涉及个人隐私的非结构化数据的使用挖掘愈加常态化,原本主要针对于结构化数据的脱敏处理技术不能满足需求,针对于各类非结构化数据的脱敏处理技术后续将成为重点发展方向。
4.3 智能化数据脱敏
当数据的维度和种类逐渐增加时,通过用户指定数据脱敏策略,手动绑定待脱敏数据及脱敏规则和算法的方式将显得效率比较低下。需要进一步减少使用者的人工工作量,因此已有部分企业在脱敏工具产品中实现了敏感数据自动识别发现等便利化功能。后续通过应用机器学习等技术,结合各类数据分类分级规则及已实际使用的数据脱敏策略及规则,实现自动化实时敏感数据发现、自动化脱敏规则匹配等智能化数据脱敏技术,将成为受人期待的发展方向。
4.4 数据脱敏技术的合规应用
随着今年《个人信息保护法》和《数据安全法》的颁布、近年来频发的数据泄露事件、以及针对违规使用用户隐私数据企业的处罚时有发生,共同敦促着企业将数据合规视为当下的首要任务。通过将数据脱敏技术同各类相关法律规范、企业相关业务相结合,实现企业业务流程中对于敏感数据的使用处处合规,形成直接实现业务合规化的数据脱敏产品,将有效改善这一合规问题。
参考文献:
王卓,刘国伟,王岩,李媛.数据脱敏技术发展现状及趋势研究[J].信息通信技术与政策,2020(04):18-22.
本期作者:工业和信息化电子第五研究所:刘佳宝、乐琦雯、曹敬宇、刘帅(以上排名不分先后)
图片转自网络,侵删
声明:本文来自赛宝商密通,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
