原文作者:JoséCabrero-Holgueras, Sergio Pastrana
原文标题:A Methodology for Large-Scale Identification of Related Accounts in Underground Forums原文链接:https://www.sciencedirect.com/science/article/pii/S0167404821003138原文来源:Computers & Security笔记作者:2rrrr@SecQuan文章小编:cherry@SecQuan
介绍
地下论坛由于其提供的伪匿名性,如今已经成为交易非法产品和服务的主要市场,其中也包括用于进行网络攻击的产品。因此,这些论坛是威胁情报分析人员和执法部门的一个重要数据来源。大多数的地下论坛禁止同一个用户创建多个账户来使用,因为通常这些账户都是出于恶意目的而创建。但若能识别出多个帐户背后的行为人或团伙,则有助于对非法活动的监管,甚至可以直接采取措施干预非法活动。目前现有的方法需要较多的人工操作,根据真实的论坛数据进行有监督分类。文章中作者提出基于分析帐户发布内容的大规模识别相关帐户的方法,并在具有15个地下论坛超过100万帐户的数据集中进行了实验验证。
方法
作者提出的方法主要关注帐户发布内容中具有的相同特征,该方法的框架图如下图所示。
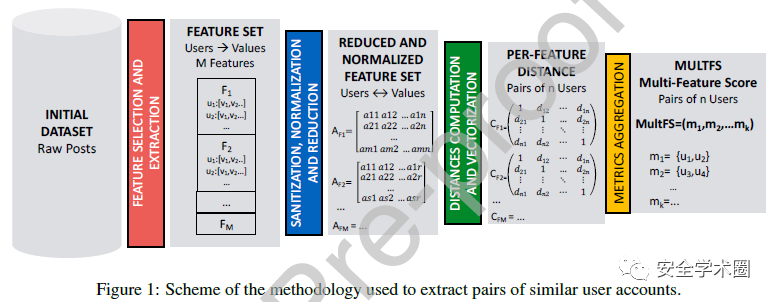
特征选择和提取:由于从地下论坛获得的原始数据是异构且非结构化的,因此第一步需要选择能够唯一描述发布该信息的账户的特征,包括网页URL、Skype帐号、Email、IP地址、BTC钱包地址以及三元词汇特征(n-grams, n=3)。其中,BTC地址代表了金融信息,Email和Skype则是卖家的个人联系信息,三元词汇特征则能够描述个人在语言语法表达习惯中的特征。
数据规范化和清理:提取的特征值中存在一定的冗余,如不区分大小写的Email和域名,需要统一将其转换为小写,去除重复的特征。数据清理首先删除只出现一次的值,并针对URL、IP地址和三元词汇特征做以下处理:
URL:主要删除同一个论坛的内部链接,以及没有提供路径的仅主机URL(如www.mainsite.com)
IP:使用本地地址的环境搭建教程和分享某些代理服务器节点的帖子中出现的IP地址对于识别用户没有太大意义。前者使用白名单过滤局域网地址(如192.168.0.0/16)、本地地址(如127.0.0.1)和子网掩码(如255.255.0.0);后者情况下对同时出现超过30个不同IP地址进行自动过滤
三元词汇特征:删除含有非ASCII字符的trigrams,如特殊字符表情和emoji,因为不同的用户很可能使用相同的这类符号而不存在任何联系
单一特征相似性度量:对于某一特征相似性分数,定义以下3条规则:
没有任何联系的一对用户,如 和 没有发布任何相似信息,则得分为0
某个特定的特征重合次数越多,分数越高,如 和 在不同帖子中使用相同的Email和BTC地址,则应该得到高分
重复的特征越少见,得分应该进一步提高,反过来说,如8.8.8.8是很常见的DNS地址,当 和 都发布了该值时,增加的得分应该忽略不计
多特征相似性度量:为了将上一步中的不同分数合成为一个指标,作者提出一种聚合方法,考虑各个特征的不同权重。首先将单一特征相似性分数标准化到[0, 1]区间,再根据以下两式计算,得到两账户相关性的最终得分MultFS:
实验
实验数据集为CrimeBB数据集,由Cambridge Cybercrime Center提供,包含了15个论坛110万个账户发布的5600万个帖子,涵盖计算机黑客、游戏作弊、社会工程学技术等主题。
图分析
首先作者构建一个无向图 和有向图 。 中的节点为账户,边的权重为相连的一对账户的MultFS分数; 中,节点为论坛F中的账户,边的权重为一个账户对所指向的账户所发布的帖子的回复次数。之后通过 的节点度数统计出含有多个账户的组有5372个,再通过 中统计每个组内的账户之间交互次数。因为通常来说,同一用户创建的多个账户之间一般不会有频繁的互动行为。
用户名分析
用户名分析考虑了不同论坛的账户使用的昵称上的相似性,使用Jaro-Winkler距离度量,并设置85%的阈值,可以将形似字符的替换(如leet与l33t)视为有关联。
结果
将图分析和用户名分析的结果结合,只要满足同一个论坛的一对账户互动少于5次,或不同论坛的一对帐户同户名Jaro-Winkler距离超过0.85,就认为是相关账户。通过这一方法,共得到3716对账户,再选取MultFS分数最高的前200对进行人工验证,结果发现有60%的账户对来自同一个用户,有25%的账户对没有足够的证据能够证明是来自同一用户,剩余的15%则能够确定来自不同用户,错误分类的原因可能是一个账户逐字逐句地引用另一个账户内容,或者账户被盗等。
与Doppelganger-finder的对比
Doppelganger-finder(DGG)是一个用来分析多账户的工具,但在大型数据集上效率较低。两种方法的对比结果如下图所示:
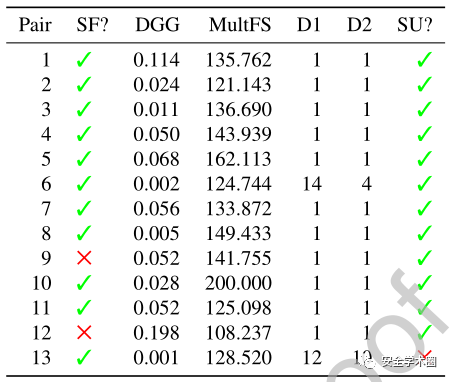 SF?表示账户对是否来自同一论坛;SU?表示账户对是否为同一用户;D1(D2)表示账户2(1)在DGG中与账户1(2)的相似度排名;DGG和MultFS分别是两种方法得到的相似度分数,值越高则表示两账户是同一用户的可能性越高
SF?表示账户对是否来自同一论坛;SU?表示账户对是否为同一用户;D1(D2)表示账户2(1)在DGG中与账户1(2)的相似度排名;DGG和MultFS分别是两种方法得到的相似度分数,值越高则表示两账户是同一用户的可能性越高
在13个样本中,作者的方法有一个误报,原因是由于这对账户中有内容完全相同的引用帖子。但总体来说,作者的方法相比DGG准确度有所提升,且能够高效地在大规模数据集上运行。

声明:本文来自安全学术圈,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
