原文标题:DNS Tunneling Detection by Cache-Property-Aware Features
原文作者:Naotake Ishikura, Daishi Kondo原文地址:http://ijece.iaescore.com/index.php/IJECE/article/view/21870发表会议:IEEE Transactions on Network and Service Management笔记作者:yyp@SecQuan笔记小编:bight@SecQuan
1.简介
作者通过调研分析已有的DNS隧道检测技术,发现现有检测方法依赖于攻击者及其恶意软件通过模仿良性实体而容易混淆的特征。例如,可以通过隐写术绕过对字符频率和熵的分析。因此,有必要提出一种弹性特征,通过关注不易隐藏的DNS隧道“痕迹”来检测DNS隧道。因此,作者提出了一种基于缓存属性感知特征的DNS隧道检测方法。作者实验表明,所提出的特征之一可以有效地描述DNS隧道流量。此外,还介绍了一种基于规则的分类器,以及使用该特征的基于短时记忆(LSTM)的分类器。基于规则的分类器实现了比LSTM分类器更高的DNS隧道攻击检测率,LSTM分类器反而更快地检测到攻击,同时两者都保持较低的误检测率。主要完成了以下几个方面工作:
全面调查研究了DNS隧道攻击和检测技术
引入缓存属性感知特征、访问未命中数,并与缓存命中率和访问命中率进行比较
提出基于规则的分类器和基于访问未命中计数的LSTM分类器
评估了超过350000个DNS查询(包括合法查询和DNS隧道查询)组成的大型合法培训数据集创建的筛选器的性能
2.前期研究
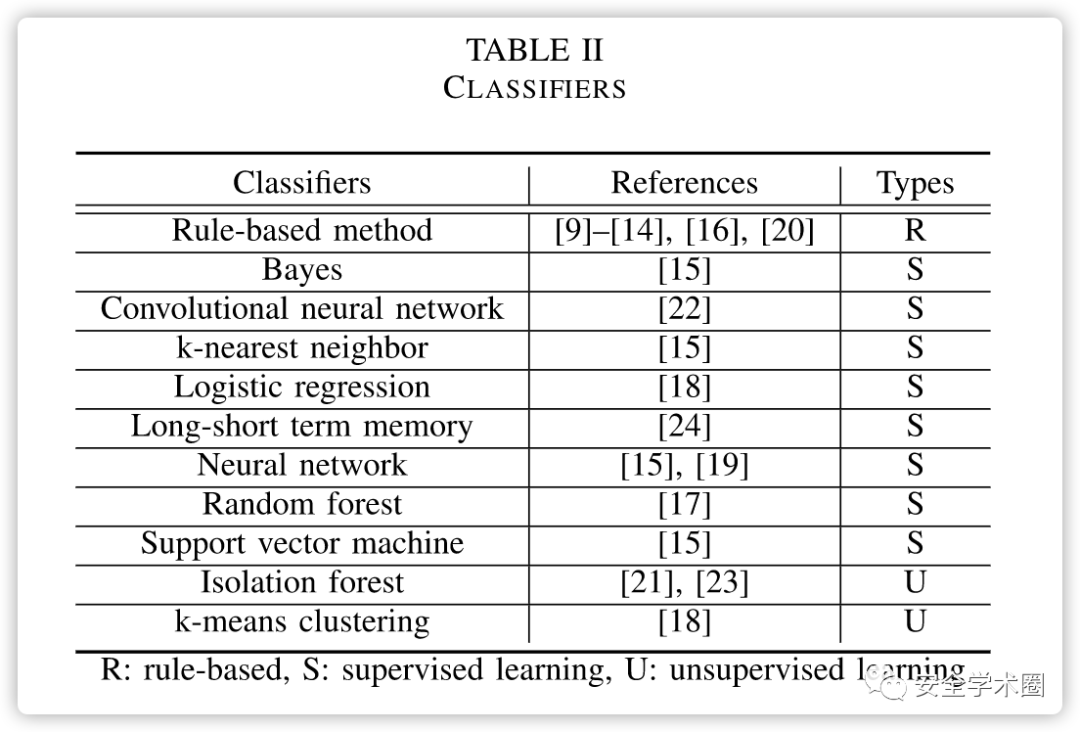
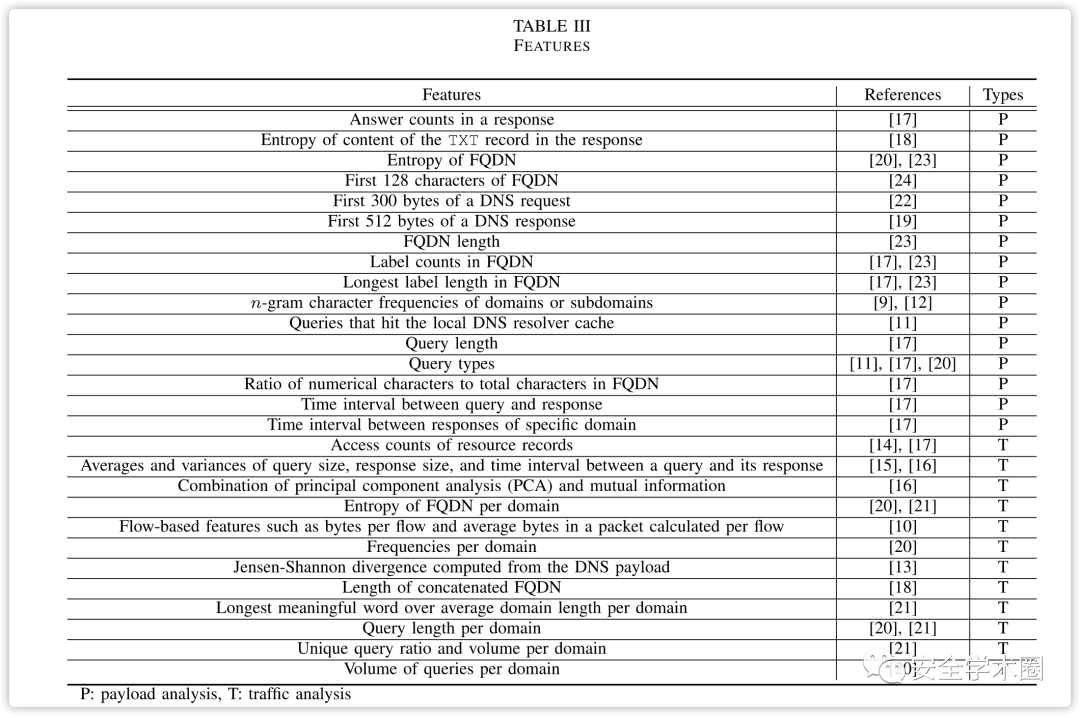
在现有的研究中,多是采特征和机器学习算法分类,相关算法和特征如下图所示。
3.缓存属性感知特征
作者提出了三个基于缓存属性的特征来识别DNS隧道流量。
缓存命中率
访问命中率
访问未命中数
其计算实例如下图所示: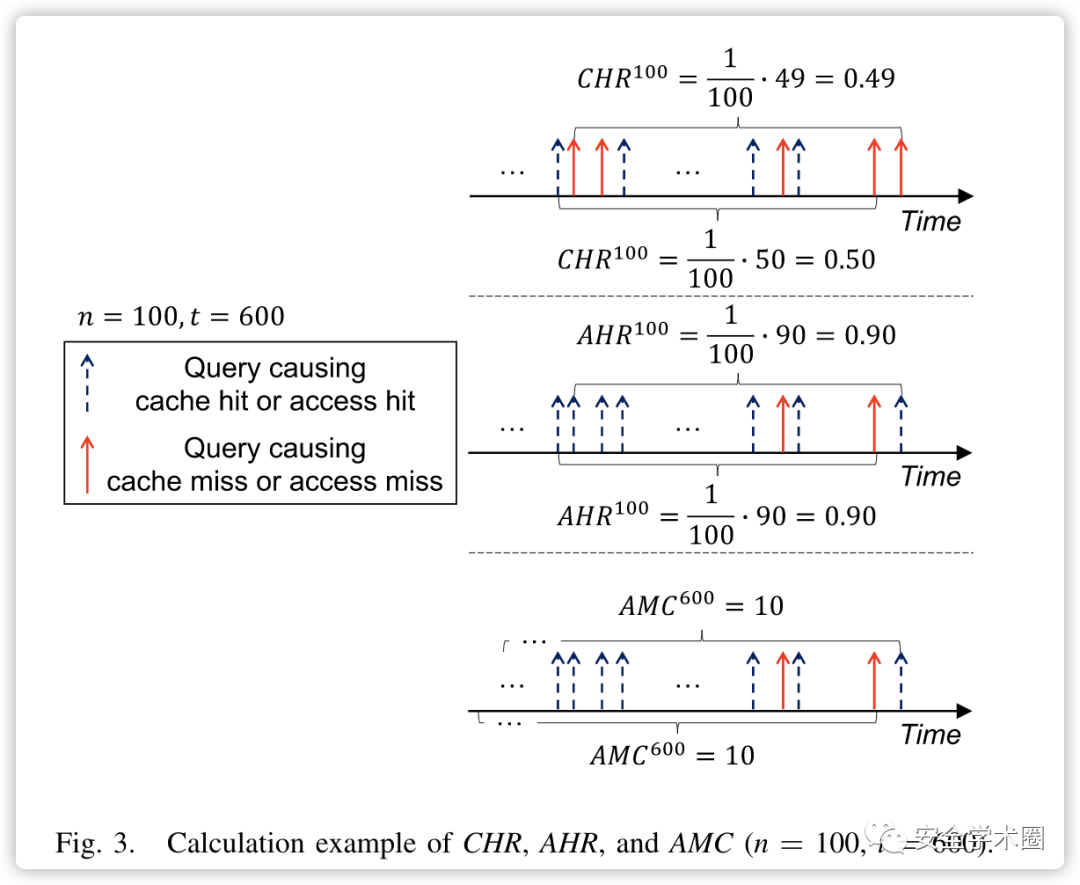
4.监测分析
作者通过在实验室捕获21个客户端31天的DNS流量,创建了缓存项和访问项列表。实验参数如表六所示。根据隧道查询传输间隔准备了三种数据分类场景:场景1、2和3,传输间隔分别为1、10和100秒。我们仅在场景1中使用了缓存项列表,这证明了HRAN和MCA克服CHR缺点的有效性。省略了场景2和场景3的实验,因为场景1(DNStunneling检测的“最简单”案例)的结果已经表明了CHR的缺点。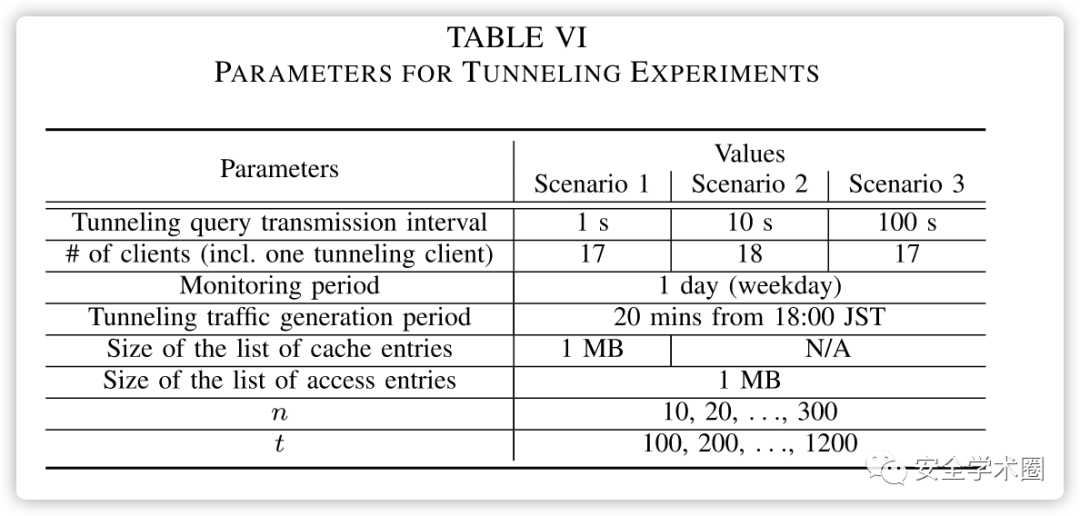
5.基于缓存属性特征的分类
基于监测到的实验数据,作者使用访问未命中数作为缓存属性感知功能实现了一个基于规则和基于LSTM的分类器。如下图所示。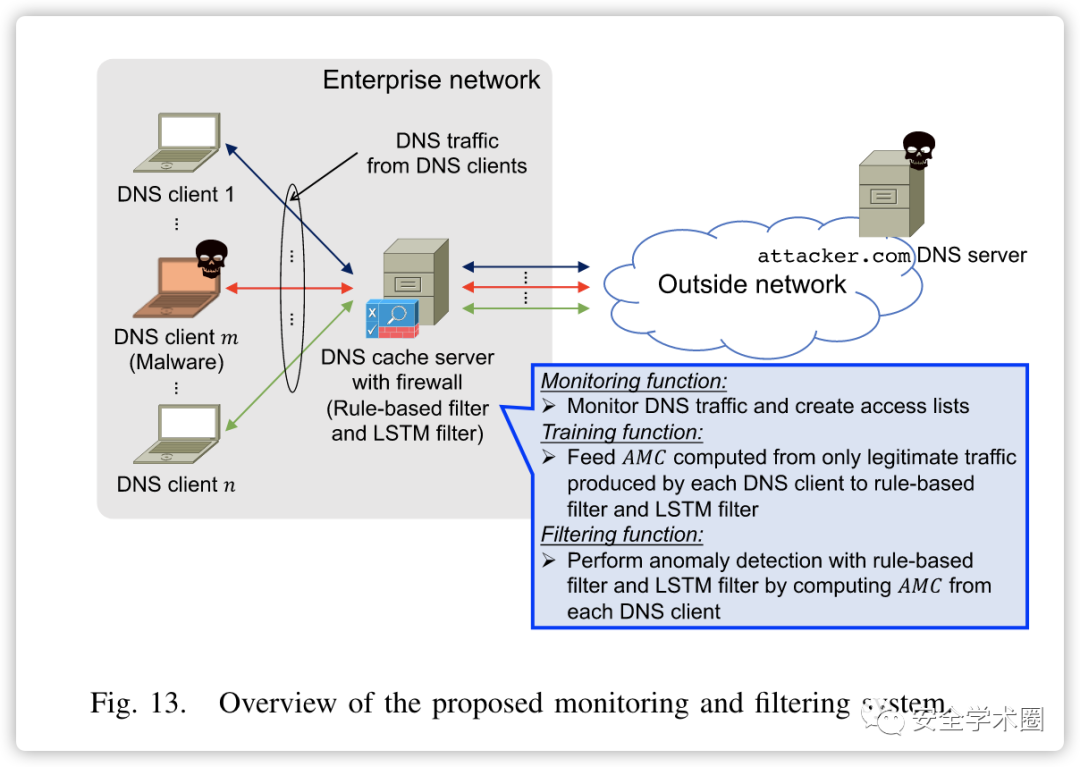
基于规则分类器
基于规则的分类器基于一个定义访问未命中数阈值的正常检测模型。具体来说,当访问未命中数超过预先配置的阈值时,分类器将DNS查询分类为异常。为了提取阈值,作者只收集合法DNS流量,创建访问列表,并为每个DNS客户端生成的DNS查询计算访问未命中数。访问未命中数值(从所有客户端)收集到训练数据集中。分类器的阈值是通过从该数据集中获取用户定义的百分位值来确定的。
基于LSMT分类器
LSTM分分类器基于时间数据的异常检测管道。首先仅收集合法DNS流量、创建访问列表,并计算每个DNS客户端生成的DNS查询的访问未命中数。然后,将这些值收集到一个训练数据集中。使用这些数据来训练LSTM模型并获得其下一步预测。然后,根据模型的预测和实际值计算预测误差。由于合法DNS流量本身包含异常值,因此预测误差往往高于这些异常值,并可用于创建分类器。因此,通过构造一个以预测误差为输入的二元分类器来创建一个分类器。
基于规则和基于LSTM的分类器之间的区别在于前者使用直接从访问未命中数计算的阈值,而后者使用根据LSTM模型的预测误差计算的阈值。
6.实验评估
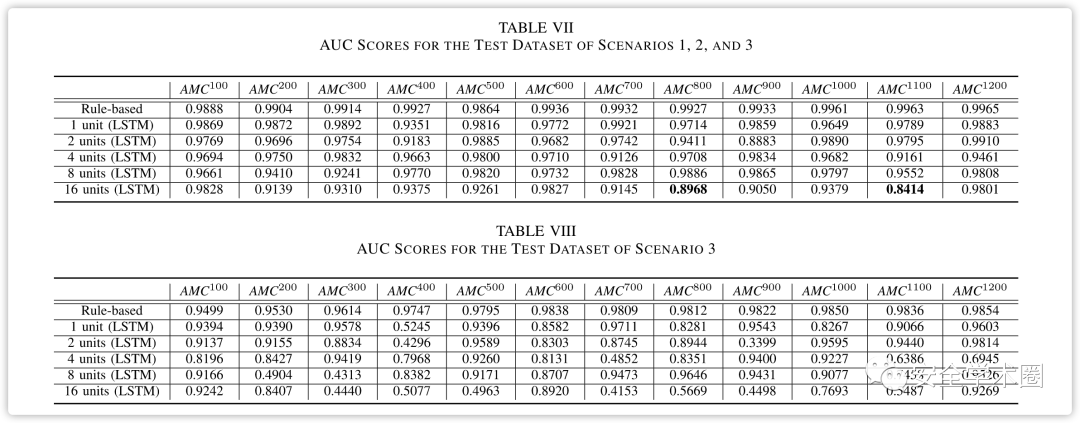
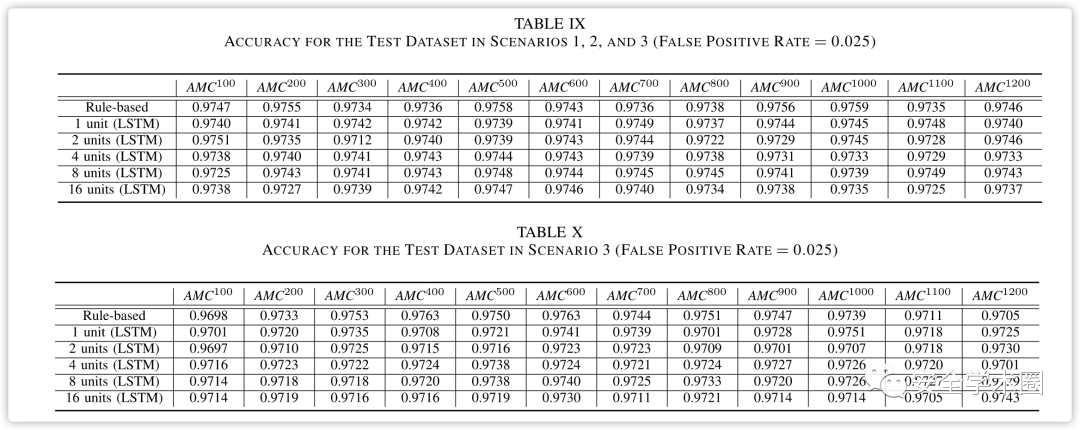
对于基于规则的分类器,为训练数据集确定了多个阈值,以根据访问未命中数将查询分类为攻击或非攻击。在作者实验中,考虑了10000个阈值(从0.01%到100%,增量为0.01%)。对于LSTM分类器,使用经过训练的LSTM模型对训练集进行预测,并计算预测误差,即实际和预测数据之间的平方误差。实验中,考虑了10000个阈值(从0.01%到100%,增量为0.01%),然后从场景1、2和3中生成的DNS流量数据中提取每个DNS查询的AMC(访问未命中数),用于获取AMC的初始访问列表是根据31天DNS流量数据集创建的。用于评估数据的测试数据集是计算的AMC,它是时间序列数据。基于规则的分类器使用其计算的阈值直接对测试数据集的活动进行分类。
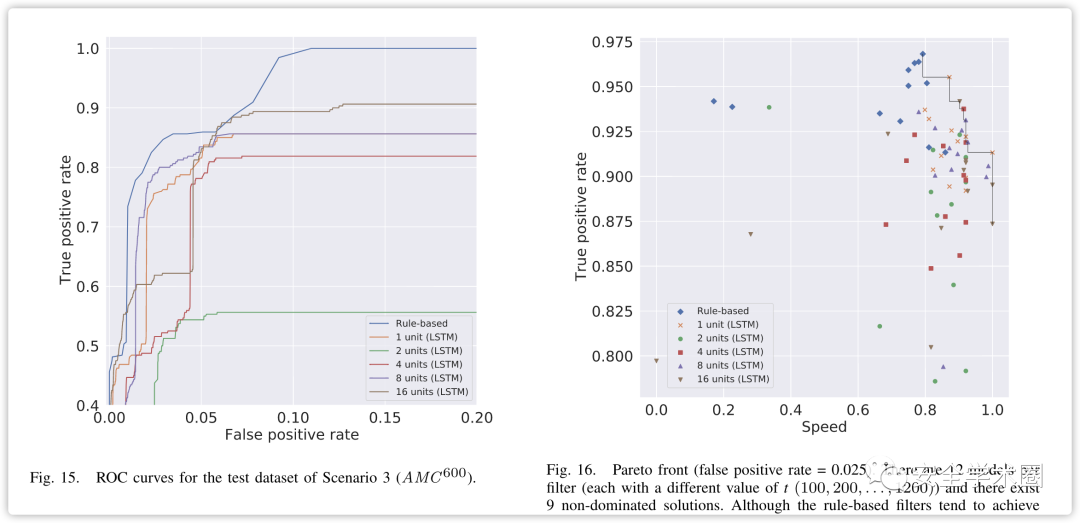
图14显示了场景1、场景2和场景3的测试数据集在600时的ROC曲线。从图中可以看出,当假阳性率超过0.025时,真阳性率超过0.91,这表明分类器能够以高概率正确分类合法和恶意DNS查询。相比之下,在图15中,显示了仅场景3的测试数据集的ROC曲线,当为600时,分类性能恶化。从这些图中可以看出,基于规则的分类器优于基于LSTM的分类器。在通过分类器检查被分类为否定(即合法查询)的肯定时,LSTM分类器有时会将多个位置识别为合法查询,因为它根据根据预测误差计算的阈值评估查询,这意味着预测误差可能在某个点变低,甚至在隧道攻击期间。同时,基于规则的分类器使用直接从AMC计算的阈值来评估查询。当LSTM分类器获得的预测误差低于预定阈值且AMC超过基于规则的分类器的阈值时,基于规则的分类器将查询分类为异常。

声明:本文来自安全学术圈,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
