零、引言
情报分析是当前自然语言处理应用的一个重要场景,也甚至可以说,情报需求,直接催生并促进了自然语言处理的发展。例如最早的机器翻译是用于破解敌方情报,最早的话题演化追踪TDT项目用于情报演化追踪,评测MUC等也都是DARPA资助开展的。
对于世界科技的领头羊,不得不说下美国的DARPA。
美国国防高级研究计划局(Defense Advanced Research Projects Agency),简称DARPA,是美国国防部属下的一个行政机构,负责研发用于军事用途的高新科技。
在情报分析领域,DARPA陆续提出了多项具有开创且引领性的技术。
上世纪70年代初,DARPA启动语音识别研究SUR项目,用于支持多个研究机构采用不同的方法进行语音识别研究,并在80年代开始采用统计学的方法研究语音识别技术,开发了Sphinx、BYBLOS、DECIPHER等一系列语音识别系统。
2000年,DARPA开始研制通过对话进行人机交互(HCI)的系统,希望从与不同人的对话中学习经验,提供个性化的服务。
2005年,DARPA启动全球自动化语言情报利用(GALE)项目,寻求能够对标准阿拉伯语和汉语的印刷品、网页、新闻及电视广播进行实时翻译的技术,目标是使得95%的文本文档翻译和90%的语音文件翻译均能达到95%的正确率。
2008年,DARPA启动Machine Reading项目,旨在实现人工智能的应用和发展学习系统的过程中,对自然文本进行知识插入。
2012年,DARPA启动文本深度发掘和过滤DEFT项目,提出要利用深度学习技术发掘大量结构化文本中隐含的、有实际价值的特征信息,同时还要具备可将处理后的信息进行进一步整合的能力,在此基础上,将这些技术用于作战评估、规划、预测的辅助决策支持中。
2014年,DARPA启动大机制Big Mechanism项目,开发协助计算机阅读科学和技术文章的技术,将知识片段综合成更完整的模型,并提出实现特定目标的干预措施。
2016年,DARPA发布可解释的人工智能项目XAI,其目标是建立一套新的或改进的机器学习技术,生成可解释的模型,结合有效的解释技术,使得最终用户能够理解、一定程度的信任并有效地管理未来的人工智能系统。
2017年,DARPA启动L2M项目,探索生物学习机理在人工智能中的应用,推进新一代人工智能系统的发展。该项目的目标是开发支持下一代自适应人工智能系统所需的技术,使其能够在实际环境中基于情景进行在线式现场学习并改善性能,不需要进行线下再编程或再训练。
2018年,DARPA宣布计划投入20亿美元开发新的人工智能XAI技术,打造具有常识、能感知语境和更高能源效率的系统。
2019年,DARPA开展“知识导向型人工智能推理模式”KAIROS项目,旨在用一种“基于模式的人工智能”技术感知世界各地的事件,尤其可用于发掘多媒体信息中的复杂事件,并对其进行上下文理解和时间推理,预测其如何发展。
特别的,在这些计划当中,知识导向的“人工智能推理图谱”(KAIROS )、“指南针”(Compass )、“大机制”(Big Mechanism )、“复杂作战环境中的因果探索”(Causal Exploration )、“不同来源主动阐释”(AIDA )等项目旨在自动化地利用呈指数增长的数据信息,将复杂系统的建模与推理相结合,从而辅助国防部快速认识、理解甚至是预测复杂国际和军事环境中的重要事件。
通过整理并思考这些项目的目标、过程,对于提升情报分析的落地与思路具有重要意义。本文就以上五个典型项目进行介绍,以期打开大家的视野。
一、Causal Exploration项目
Causal Exploration,复杂作战环境中的因果探索项目。
美国印太司令部与DARPA合作开展了一个名为“因果探索”的人工智能项目,该项目旨在 “建立一种工具,利用人工智能来增强机器所擅长的研究大量数据和模式识别等工作的效能并将其与人类相结合,允许人类发挥特有的专长,如提出新想法等。”
1、项目研究目标
该项目旨在开发一个建模平台,用于帮助军事规划者理解和解决导致区域混合冲突的潜在原因。
该平台可以根据作战环境(OE)快速创建和维护因果模型,支持探索影响作战环境的因果动力学,并且能够深入全面地了解作战环境等功能。
该项目的成果可直接用于支持并告知规划工作,以解决由政治、种族或宗教紧张等因素主导的复杂人类层面的冲突、低强度冲突、经济侵略、或网络恐吓。
2、项目研究构成
该项目在技术构成上涉及“知识组织”、“因果模型装配”、“人机交互”、“模型评估”以及“系统集成”几个研究内容。

1)在知识组织阶段。该阶段旨在处理多种多样的异构和语义多样的文本及数字信息源,如军事和情报文件(如情报报告、作战评估、军事信息)、开源文本(如新闻媒体、基于Web的内容)、政府或非政府组织数据(如人口统计和经济等报告和数据库分析)。
此外,以此作为输入源,提取出有关实体(参与者、条件、事件等)和关系的知识,并将实体和关系映射到公共本体中。
这个阶段存在包括广泛变化的源材料、源信息的偏差或不可靠性、不符合清晰句法模式的因果关系、对因果关系特征(如置信度、强度、延迟)的一致估计等在内的多个挑战。
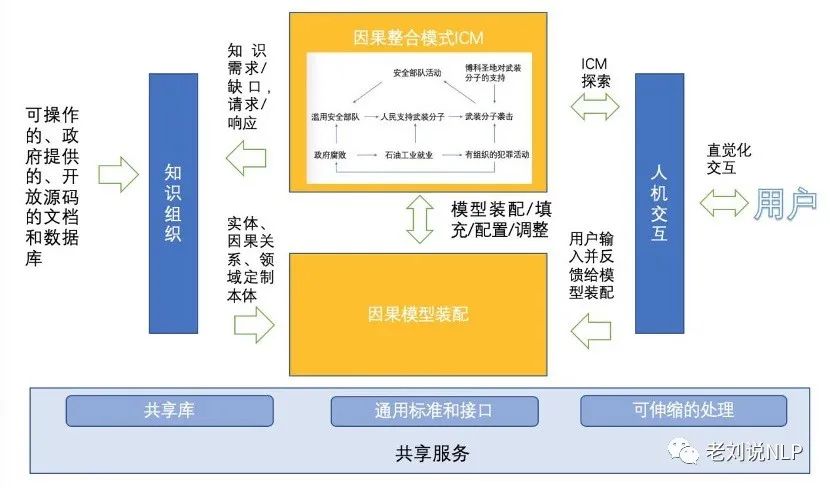
2)因果模型装配阶段。该阶段需要从知识组织阶段输出的数据集(以及可能的其他来源,如编码专家知识)中汇编出来一个因果整合模式,并识别出因果整合模式的缺陷和差异,以便进一步整合人的输入从而修改或增强因果整合并整合新知识,从而实现最终的更新或完善。
3)人机交互阶段。该阶段要求有良好的人机交互性能。一方面需要使具有不同经验和专业知识的用户能够与建好的因果整合模式进行互动,以建立理解,提供捕获因果整合模式的结果以及用户上下文的技术,产生灵活和动态产品。另一方面,还需要提供直观的探索功能,以帮助用户发现潜在的原因并评估潜在的方法,并使用户能够操作ICM结构、执行计算、可视化和简要的结果。
3、项目应用
该项目的定位为一个建模平台,以帮助军事规划者理解和解决导致复杂冲突局势的潜在因果因素,典型地应用于以区域混合冲突为例的场景挖掘。
1)给定一个冲突实例:“尼日尔三角洲爆发了危机,武装分子占领了油田和沿海地区,并与有组织犯罪集团联手攻击海湾的航运”)。
2)获取相应数据:获取军事和情报(作战评估、军事信息、情报报告)、政府和非政府组织数据(人口/经济报告和数据库)以及开源(公开信息,包括基于文本的新闻媒体、基于Web的内容、社交媒体)。
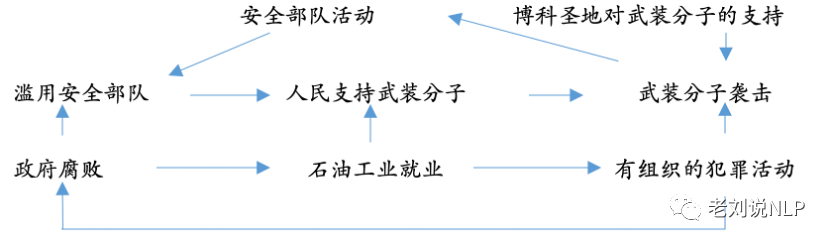
3)自动提取相关知识:实体知识: 尼日利亚政府、尼日利亚安全部队、尼日尔三角洲人口、石油公司、犯罪集团、武装分子、博科圣地;条件、事件和趋势: 滥用安全部队、人民支持武装分子;因果关系的识别:滥用安全部队增加了对武装分子的人口支持;领域本体的定制:博科圣地---恐怖分子---非国家军事演员---武装分子民兵组织---武装分子。
4)半自动因果模型装配:将提取到的各项知识进行组织。
二、AIDA项目
Active Interpretation of Disparate Alternatives ,主动解释不同替代方案。
信息的复杂性已超出分析师从各种信息源搜集有价值信息的能力,这些信息样式各异,是结构数据和非结构数据的混合体,从军事情报到社交媒体,包含准确和不准确的消息。对于那些力图理解世界大事的人,没有由其他媒体提供的信息作为参考,经常独立分析来自各个媒体的信息是有挑战的。
DARPA通过开发“对不同方案的主动解释”(Active Interpretation of Disparate Alternatives,AIDA)项目,试图克服今天数据环境的混乱、矛盾和潜在的欺骗性。
1、项目研究目标
主动解释不同替代方案(AIDA)的目标是。
首先,该引擎必须能够将从多个媒体源自动派生的知识元素映射到公共语义表示,聚合从这些媒体源派生的信息,并生成和探索有关事件、情况和感兴趣趋势的多个假设,能够根据分析的准确性和每个假设的语义表示的一致性,为派生知识和假设建立置信度量。
其次,该引擎还必须能够利用公共语义表示中的知识和生成的假设作为媒体分析算法的替代上下文,通过改变它们的模型或先验概率来提高准确性,并根据上下文的期望解决歧义。
最后,该语义引擎还需要能够与用户通信,以揭示生成的假设,并允许用户更改假设或建议新的假设。
2、项目构成
该项目最终定位为一个多假设语义引擎,这个引擎包括映射和反馈(Semantic Mapping and Feedback)、公共语义表示(Common Semantic Representation)、多重假设(Multiple Hypotheses)、集成和多重解释(Integration and Multiple Interpretations)等主要组成部分。
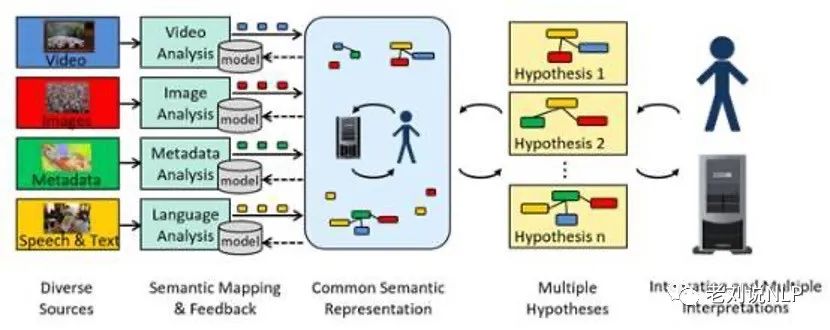
首先,在语义映射和反馈阶段,需要解决本项目的核心部分,即利用现有分析算法从所有可用媒体中提取知识元素,并将这些信息映射到定义的公共语义表示语言中。这一阶段的主要输入包括各种类型的文本、语音、图像、视频及其相关元数据流。通过分析每个输入的信息项,最终生成出一组关于该信息项中可观察到的事件、子事件或动作、实体、关系、位置、时间和情感的结构化表示。除了出处记录外,表示的每个知识元素(包括互排斥的知识要素)都需要有一个与之相关的置信度度量。
其次,在公共语义表示阶段,需要重点研究和开发一种新的通用语义表示,使人和计算机都可读。将输入的结构化且具有置信度量知识元素,用通用语义表示语言表示,并形成一个体系化的知识库。另外,在多重假设阶段,需要在知识库中以公共语义表示的方式组装信息,从而形成一个或多个内部一致的假设,其中的每个假设都应该捕获一个内部一致的世界模型,通过对输入数据的某些子集的解释,进而估计和传播不确定性。
最后,集成和多重假设阶段,需要开发出一个能够接受各种数据流的原型,该原型必须能够实现通过探测知识库、显示假设、向系统提交查询、编辑知识库或假设中的知识元素,以及向计算的任何阶段注入额外的“假设”来管理用户交互。
3、项目应用
AIDA可以帮助分析员和军队决策者改善他们的分析,以便他们更能同更大更完整的整体语境相一致,并且能获得对塑造世界的元素和力量的更加透彻的理解。
此外,AIDA提供对趋势和事件的更好理解,清除出不相干的和不可靠的数据。
三、Big Mechanism项目
Big Mechanism是一项耗资4,500万美元的DARPA研究计划,始于2014年,旨在开发可读取癌症研究论文,将其整合到癌症模型中的软件,并在2017年底之前通过自动收集大数据并整合通过阅读研究摘要和论文以提取因果机制各方面的因素,例如基于知识的自然语言处理,策展和本体论,系统和数学生物学等各种学科。
该计划专注于Ras基因家族的突变,该突变是人类癌症的约三分之一。目前,粗略的路线图显示了影响细胞复制和死亡的蛋白质之间的相互作用序列,但是,因果关系了解得很少。
1、项目目标
大机制计划旨在开发技术来阅读研究摘要和论文,以提取因果机制的各个部分,将这些部分组装成更完整的因果模型,并对这些模型进行推理以产生解释。该计划的领域是癌症生物学,重点是信号传导途径
2、项目构成
该项目希望建成的系统能够实现三个目标:阅读摘要和论文以提取因果机制的片段;将片段组装成更完整的“大机制”;用大机制实现解释和推理。整个系统的因果模型可能很难构建,因为它们的已知信息分布在大量文献中。大型机制计划旨在让机器阅读文献,并自动将个别论文中发现的因果片段组装成巨大的因果模型。

该计划将分三个阶段进行:首先是阅读文学并将其转换为正式的表述,其次将知识整合到计算模型中,第最后是产生实验可检验的解释和预测。
四、COMPASS项目
目前采用的OODA环不适合于“灰色地带”作战,因为这种环境中的信息通常不够丰富,无法得出结论,且对手经常故意植入某些信息来掩盖真实目的。
2018年3月,DARPA战略技术办公室公布了“通过规划主动的情景想定进行情报收集和监视COMPASS指南针”项目,旨在开发一款高级软件,帮助作战人员通过衡量对手对各种刺激手段的反应来了解对手的意图。
1、项目目标
COMPASS旨在帮助作战人员通过衡量对手对各种刺激手段的反应来弄清对手的意图。
首先,试图确定对手的行动和意图,然后再确定对手如何执行这些计划,如地点、时机、具体执行人等。
其次,在重复的博弈论过程中使用人工智能技术在对手真实意图的基础上试图确定最有效的行动选项。
2、项目构成
COMPASS项目包含三个主要模块,分别对应对手长期的意图、策略,战术和动态作战环境的短期态势感知以及建立指挥官工具箱。

其中,在在第一个模块上,涉及从非结构化信息源中提取事件的处理手段。
3、项目应用
按照官方显示,COMPASS能够应对不同类型的灰色地带情况,包括但不限于关键基础设施中断、信息作战、政治压力、经济勒索、安全部队援助、腐败、选举干预、社会不和谐以及混乱等。
五、KAIROS项目
Knowledge-directed Artificial Intelligence Reasoning Over Schemas, KAIROS,知识导向的人工智能推理模式。
美国国防部希望利用人工智能技术在日益复杂的全球环境中更好地追踪、分析各地的重要事件。
在这一需求的驱动下,DARPA启动了“知识导向人工智能推理图谱”(KAIROS)项目,计划利用人工智能技术分析多媒体中的信息,理解世界各地发生的事件,旨在通过开发能够对现实世界事件进行上下文和时间推理的人工智能技术,从看似无关的事件中,分析发现事件之间的关联性。
1、研究目标
KAIROS这一系统旨在实现一个基于模式的人工智能系统,能够根据事件的上下文和时间推理,产生对复杂现实世界事件的可操作理解,并预测它们将如何展开。该系统可以筛选每天产生的无数事件和媒体片段,并识别其中任何连接或叙述的线索,识别和绘制事件或数据之间的相关性。
该项目大体上分成两个阶段:
在第一阶段,开发一种半自动化系统,能够识别和绘制看似无关的事件或数据之间的相关性,以帮助我们了解或创建关于我们周围世界的通用描述。
该阶段关注通过基于语言学推断和常识推理的检测、分类、汇聚,从海量数据中形成事件模式,参与这个阶段的研究人员将运用归纳、综合和特殊化的流程来帮助形成可描述简单和复杂事件的模式,然后再将多个图式串列使用来提取诸如“角色”、“事件”这样的关键语境因素,并运用专业领域知识针对特定需求定制分析过程。
第二阶段,将系统用于分析复杂的现实世界数据,并尝试根据创建的模式提取事件和叙述。该阶段关注将形成于第一个阶段的图式库应用到多媒体、多语言信息中去,以发现和提取复杂事件,这个阶段的研究将致力于识别事件、实体等因素之间的关联关系,以帮助人工智能系统形成和扩展其知识库。
2、项目构成
在系统构成上,该项目包括事件模式的生成(Generation of Schemas for Events)、时间知识和模式的表示和使用(Representation and Use of Temporal Knowledge and Schemas)、系统集成和用户界面 (System Integration and User Interface)等模块。

首先,在事件模式的生成阶段,需要根据辅助元素、参数及时间和顺序信息分析复杂事件,以组成和概括事件模式。其输入数据包括多媒体、多语言批处理数据,要求输出表示事件及其辅助元素结构的模式,事件如何演变,辅助元素的典型持续时间和顺序是什么。
其次,在时间事件模式的生成阶段,该阶段以来自多媒体、多语言流作为输入,以事件模式的生成阶段中开发的模式,实现运行时使用的知识库。知识库中具体包含有关运行时数据中实例化模式的信息、与模式相关的所有事件和参与者,以及事件元素和参与者的时间关系,并能够基于模式进行可能后续事件预测。
最后,在系统集成和用户界面阶段,需要设计一个平台,该平台以多媒体或语料库作为输入,并允许所有系统组件与一个界面通信,该界面允许用户查询系统并控制可视化模块,例如允许用户与时间事件模式的生成算法之间进行读取、编辑或可视化的接口。
六、总结
情报分析是当前自然语言处理应用的一个重要场景,也甚至可以说,情报需求,直接催生并促进了自然语言处理的发展。
本文梳理了DARPA围绕情报分析上做的一些项目部署,并对知识导向的“人工智能推理图谱”(KAIROS )、“指南针”(Compass )、“大机制”(Big Mechanism )、“复杂作战环境中的因果探索”(Causal Exploration )、“不同来源主动阐释”(AIDA )等项目进行了简要介绍,从中可以看到一些项目上的信息。
DARPA为我们树立了一个很好的目标,了解并深耕这些项目,对于开拓我们的视野,布局情报分析技术,寻找情报分析方向,具有重要意义。
参考文献
1、http://www.81.cn/gfbmap/content/2019-02/15/content_227338.htm
2、http://www.i-zb.com/7434.html
3、http://www.infocomm-journal.com/bdr/article/2020/2096-0271/2096-0271-6-4-00125.shtml
4、https://www.secrss.com/articles/4609
关于我们
老刘,刘焕勇,NLP开源爱好者与践行者,主页:https://liuhuanyong.github.io。就职于360人工智能研究院、曾就职于中国科学院软件研究所。
声明:本文来自老刘说NLP,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
