手机在人类生活中所扮演的角色越来越重要,除了电话、短信、上网等功能之外,手机与其相邻基站进行连接所产生的日志记录——即手机轨迹数据,往往会呈现出规律性,围绕其居住地、工作地做周期性的位置变迁,在很大程度上记录并反映了用户的日常生活习惯。
该数据具有数据量大、用户基数大及覆盖人群广等特点,并为发现用户重要位置提供了可能,即人们在日常生活中的主要活动地点,比如居住地和工作地。
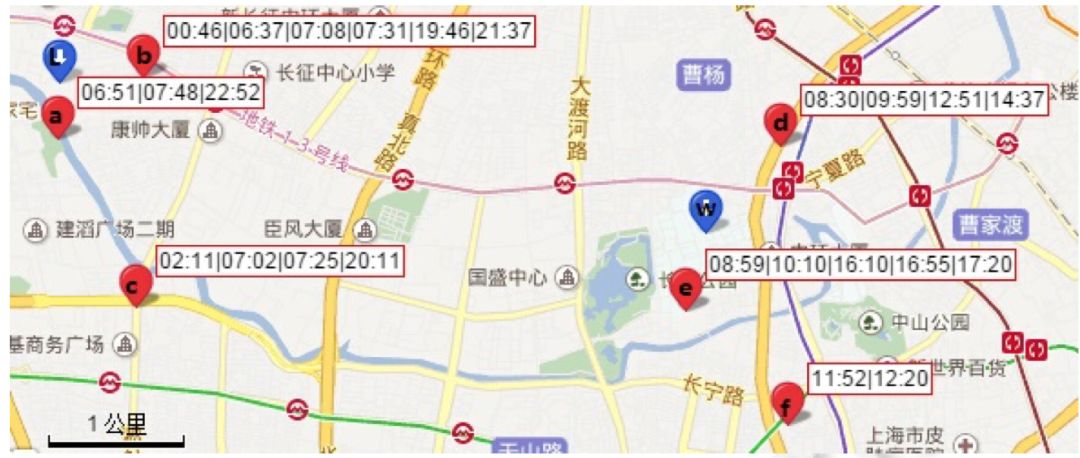
图 1 某用户一天的基站连接日志
然而,“量大”并不意味着“质高”。对于重要位置分析来说,手机轨迹数据的低质主要体现在以下4个方面:
数据不准确性(精度误差)。轨迹数据本身是用户连接基站的记录集合,用户每连接一次基站,意味着用户在该基站周边的区域范围内,但不知道用户的具体位置。因此,数据本身存在着位置不确定性问题。同时,基站类型具有多样性,其包含微站、宏站、直放站和射频拉远站等类型,各类型的基站覆盖范围从几百米到几公里不等;
数据分布密度不均。基站的分布情况在城市的不同区域差异显著,例如市中心区域的基站密度远高于郊区的基站密度,因此用户在市中心区域出现的数据较多,而在郊区出现的数据较少;
数据中包含噪声。手机轨迹数据除了包含用户在重要位置的停留信息外,还混杂着大量在其他非重要位置上停留的记录(称为“噪声”数据)。如用户上下班途中连接基站所产生的记录,对重要位置分析来说,必须考虑噪声数据对分析的影响;
数据中存在基站跳变现象。换言之,用户所处位置恰巧处于多个基站的服务范围之内,手机信号会在多哥基站间跳动切换。
为了进一步地为提高挖掘结果的准确性和精确度,从3个方面进行优化:
使用多元数据的融合技术,提高结果的准确性;
提出了无工作地人群的发现算法;
提出了夜间工作人群的发现算法。
基于此框架设计了两种分布式挖掘算法: GPMA (grid-based parallel mining algorithm) 和SPMA (station-based parallel mining algorithm) 。
理论分析和实验结果表明,所提算法具有较高的执行效率和可扩展性,并具有更高的精度。
图1 介绍了某用户一天内连接基站的情况。矩形框中的时间表明,该用户曾经于该时间点与基站通信。例如,f基站的附加信息是“11:52|12:20”,这表明该用户曾经于这两个时间点分别访问基站f。其中,标记为L的蓝色标签指示了用户的居住地,标记为 W 的蓝色标签指示了用户的工作地。用户在L点停留期间,其手机会在 a、b和c这3个基站间切换;同时在W点停留期间,其手机也会在d和e两个基站间进行切换。目前最好的处理方法是针对精确轨迹数据进行分析,在海量低质情况下,不仅运行效率不高,而且结果准确率较低。
用户的多样性也为发现用户居住/工作地增加了难度,部分用户同时拥有一个以上工作地或居住地,还有些用户的居住/工作地会随用户搬家、换工作等原因而发生变化,部分无业人员无工作地,一些人员夜间工作,而白天休息,而现有工作未考虑用户的多样性问题,所以应结合数据融合等分析技术以解决用户多样性问题,提升结果的准确度。
针对轨迹数据质量的问题,接下来将介绍一个通用解决框架,并提出了两种挖掘算法,以及3种处理方案,以提高结果的准确度和精度。
声明:本文来自LBS,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
