数据访问控制是零信任的最后环节和终极目标。基于零信任的数据访问控制,已经成为数据安全保护和治理的新方法。
但是,对于数据访问控制的实施问题,企业客户却不得不面对几种选择:
1)基于数据存储原生控制的方法:是指利用数据存储的原生控制能力,来构建自己需要的数据访问控制。企业客户可以自己动手构建DIY(自己动手)解决方案,也可以花钱购买数据访问编排解决方案。但都无法摆脱数据存储原生控制存在可观察性不足的问题。
2)基于数据访问代理的方法:通过在数据消费者(用户/应用程序)和数据存储之间建立独立的数据访问层,将访问控制与数据存储基础设施分离。这是目前主流的商用数据访问平台采用的方式,也是当前最被看好的数据访问控制方法。但传统的数据库代理技术主要用于南北向的流量控制,且难以适应于云原生微服务环境。
3)基于数据层边车的方法:将服务网格(Service Mesh)中的边车(Sidecar)技术理念,应用到数据网格(Data Mesh),专门解决云原生微服务环境中的东西向数据访问控制难题。数据层边车本质上充当应用程序和数据之间的断路器。尽管数据层边车还是发挥代理的作用,但它是为云原生架构和数据网格架构而设计的未来型代理。
虽然新一代技术常常代表了未来的方向,但是企业客户还是应该结合自身的实际情况,选择最适合的数据访问控制实施方案。
目 录
1.数据存储原生控制方法
1)DIY(自己动手)解决方案
2)数据访问编排解决方案
3)数据存储库的可观察性不足
2.数据访问代理方法
1)代理和数据库代理
2)SQL无感知数据库代理
3)SQL感知数据库代理
3.数据层边车方法
1)传统代理无法适应云原生环境
2)云原生世界需要数据层边车
3)数据层边车 vs. 数据库代理
01 数据存储原生控制方法
数据存储原生控制方法可以细分为两种方案:DIY(自己动手)解决方案+数据访问编排方案。
1)DIY(自己动手)解决方案
方法说明。DIY(自己动手)解决方案是指客户利用数据存储原生能力,自己动手构建客户需要的数据访问控制。
原生功能包括数据存储中可用的安全视图、函数、策略。
如果客户的数据团队有能力利用数据存储中的原生功能,他们通常会这样做。
方法不足。使用原生能力构建DIY(自己动手)解决方案的问题在于:
它不是核心业务。在大多数情况下,利用原生功能构建DIY数据访问控制方案,并不是客户的高优先级事项。客户的工程资源最好用于支持和发展客户业务的核心活动,从而为企业创造更大的业务价值。
维护成本高。数据访问控制不是那种“设置好后就可以抛之脑后”的东西,它需要持续、悉心的照料,这会带来隐性成本和风险。
学习曲线陡峭。很多时候,如果您缺乏创建或管理数据访问解决方案的经验,此类项目可能会带来未知的工程挑战。
迁移数据平台的烦恼。如果客户想从一个数据平台迁移到另一个数据平台,可能需要重新编写DIY解决方案的大部分内容。
原生功能受限。DIY解决方案受限于可用的数据存储原生能力。参见下文。
2)数据访问编排解决方案
方法说明。数据访问编排解决方案是对原生数据存储能力进行编排的产品,只需要付费购买即可,无需客户自己的数据团队亲自动手实现它们。
数据编排通常由软件平台支持,该平台连接各种存储系统,并在需要时启用与其他应用程序的连接。它将来自多个存储位置的数据进行整合,以便企业可以在其分析和管理平台中使用这些数据。
在数据访问编排中,被编排的是对数据的访问,而非数据本身。不是在数据存储本身(例如数据库、数据仓库和数据湖)中手动配置数据访问,而是使用单个工具定义访问策略,然后在各种数据存储中执行安全策略。
编排解决方案可能会节省客户利用原生能力构建方案的时间。
方法不足。与后文介绍的数据访问代理方案相比,编排解决方案在许多方面受到限制:
缺乏数据感知能力。通常来说,编排解决方案依赖于定期批处理,来识别和标记敏感数据。而数据访问代理平台则能够在访问数据的同时对其进行分析,可以即时发现敏感信息并立即采取行动。
侵入性。编排解决方案经常会使用抽象数据访问所需的对象,污染数据基础设施。此外,在许多情况下,它们会迫使您更改现有逻辑(例如访问新的抽象对象而非现有对象)。而使用数据访问代理,则无需添加任何数据库对象,也无需改变查询中的任何内容。
超级管理员凭据使用。编排解决方案需要使用高访问权限账户。这意味着您可能需要设置一个账户,能在SaaS或设备上执行很多操作(即创建对象和读取数据)。而使用数据访问代理,您无需添加任何额外的凭据,从而消除了意外更改的风险。
原生功能受限。编排解决方案受限于可用的数据存储原生能力。参见下文。
3)数据存储库的“可观察性不足”
数据存储库存在“可观察性不足”的问题。
3.1)数据存储库日志通常被禁用
在传统的本地数据库和DBaaS(数据库即服务)中,日志的唯一来源通常是由数据存储库本身将活动记录到文件系统中。但是,日志记录通常会因为性能下降和PII泄密风险等原因而关闭:
性能下降。在MySQL和PostgreSQL数据库中,当打开查询日志记录时,由于关键查询执行路径中产生的额外I/O,QPS(每秒查询数)通常会下降25-30%;
PII泄密的风险。被记录的查询/请求日志,并没有经过对PII信息的隐私处理。这必然导致安全问题。
3.2)DBaaS(数据库即服务)的可见性不足
DBaaS中的指标主要有两个来源,但都存在不足:
一是粗粒度的DBaaS指标。这些是由DBaaS引擎自身发布的聚合指标,比如说每秒连接次数、每秒SELECT/UPDATE/INSERT次数、每秒慢速查询次数。但它们都是粗粒度的,无法对应到与DBaaS交互的特定用户或服务;
二是汇总的云提供商指标。但这些指标也无法被有效映射和归因。例如,AWS Cloudwatch发布了与DBaaS引擎的网络I/O活动相对应的字节数和吞吐量。然而,它无法识别出某个表中的多少行或者某个集合中的多少文档,对应于网络层观察到的字节数量。也不可能将这些指标的观察值,归因于特定用户或服务。
3.3)传统数据库部署的可见性不足
传统的数据库部署的确增加了一些可见性,如下所示。但由于性能影响或存储成本,这些日志通常会被禁用。
服务帐户:用户通常使用BI(商业智能)工具或应用程序登录数据库,而BI工具和应用程序将使用共享型服务帐户来查询数据库。也就是说,真实用户的身份无法记录在数据库日志中。
用户活动:身份认证日志可以突出显示身份认证失败时间,包括事件的日期和时间。但是,这类日志不包括上下文数据,包括执行的查询或调用者的源IP。
查询活动:这类日志通常用于数据库调优,包含性能细节,包括查询计划和执行时间。
系统健康状况:关于数据库健康状况的聚合指标,包括使用的内存和存储、上次运行性能调优的时间,以及硬件或损坏问题。
3.4)增强型数据库原生控制方法的不足
增强数据访问控制的一种常见方法,是将数据存储与IAM产品进行集成,从而为数据访问增强用户身份识别能力。
但是,这种集成在安全和监管方面留下了空白,因为它们没有将数据库原生访问控制的全部功能扩展到经过SSO身份认证的用户,也没有提供可以扩展的访问策略工具。
总而言之,数据存储原生控制在很多时候都靠不住。所以,数据访问代理方法才被广泛采用。
02 数据访问代理方法
1)代理和数据库代理
代理是位于客户端和服务器之间的拦截服务。当代理靠近客户端部署时,称为正向代理。当代理部署在离服务器更近的地方,使得客户端不知道服务器的来源时,它被称为反向代理。
数据库代理(ProxySQL、MaxScale等)基本上是一种反向代理,旨在为数据库、键值存储、消息队列提供安全性、可伸缩性、高可用性等优势。

图1-数据库代理
2)SQL无感知数据库代理
在高度分布式的数据存储库(如MongoDB和Cassandra)流行之前,数据库代理通过为后端数据存储库提供连接池,来实现扩展性和高性能。通过将请求路由到健康的数据后端,来确保高可用性,并减少故障转移时间。
此类数据库代理通常被称为L4层代理或SQL无感知代理,包括HAProxy、Nginx和类似工具。
3)SQL感知数据库代理
随着应用程序迁移到云端,数据量猛增,现代数据存储库开始提供可扩展性和高可用性功能,使用分布式Coordinator-Worker(协调器-工作节点)架构的数据分片和复制。
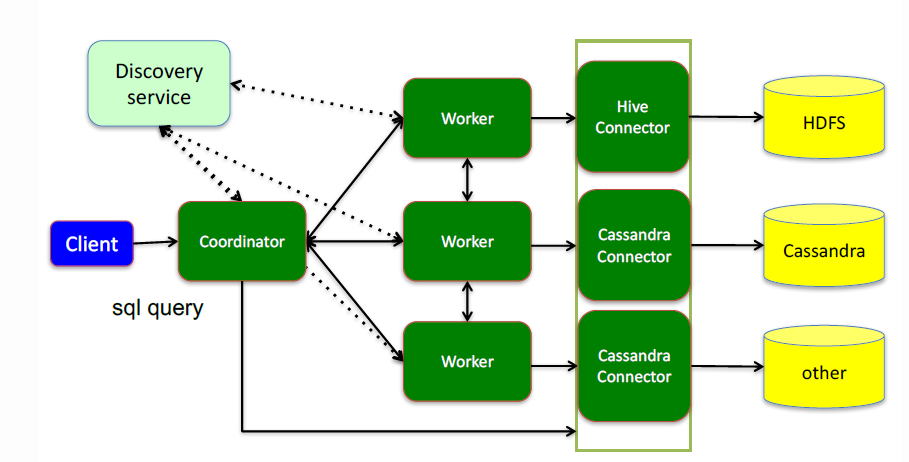
图2-Coordinator-Worker架构
为了保护应用程序逻辑免受底层拓扑变化的影响,ProxySQL和MaxScale等SQL感知数据库代理开始受到关注。
SQL感知代理可以执行这类任务:通过将读查询定向到Worker并将写查询定向到Coordinator中的master,来执行SQL读查询/写查询的路由。
SQL感知代理也用于这些场景:需要在SQL层操作以缓存SQL查询的响应,以提高性能;或者重写和阻断某些SQL查询,以增加安全性。
事实上,目前主流的数据访问平台都采用了感知型数据库代理的方式。这也是当前最被看好的数据访问控制方法。

图3-基于数据库代理模式的数据访问平台
03 数据层边车方法
1)传统代理无法适应云原生环境
随着容器技术尤其是Docker的成熟,以微服务为可组合单元的面向服务架构(SOA)开始受到广泛欢迎。云原生应用程序开始使用微服务作为它们的构建模块,从而将自身用于持续集成和持续部署的DevOps方法。
虽然基于微服务的新架构带来了许多好处,但它们也暴露了挑战,特别是在安全和流量管理方面:
这些分散的微服务之间的通信,导致东西向流量激增;
却没有可以强制执行安全规则的明确边界;
也没有可以执行流量管理的单一入口/出口点。
因此,在应用程序和数据存储库(数据库或数据仓库)之间部署代理的传统模型,在云原生的新世界中不再适用。
2)云原生世界需要数据层边车
在云原生世界中部署代理的思路是数据层边车(Sidecar),即采用边车模式部署的无状态拦截服务。
在云原生应用程序部署架构中,数据层边车本质上充当应用程序和数据之间的断路器,以保护数据存储库。
数据层边车诞生于云中,可以快速部署到客户环境中,并实时拦截对任何类型数据存储库(数据库、数据管道、数据仓库等)的所有请求,而不会影响性能和可扩展性。所有的集成和配置,都可以从统一控制平面进行集中管理。
由于数据层边车便于使用Kubernetes等服务编排工具进行部署,因此企业可以确保其所有存储库的数据保护始终处于开启状态。
虽然数据层边车仍然发挥代理的作用,但它的架构是为云原生架构而设计的:
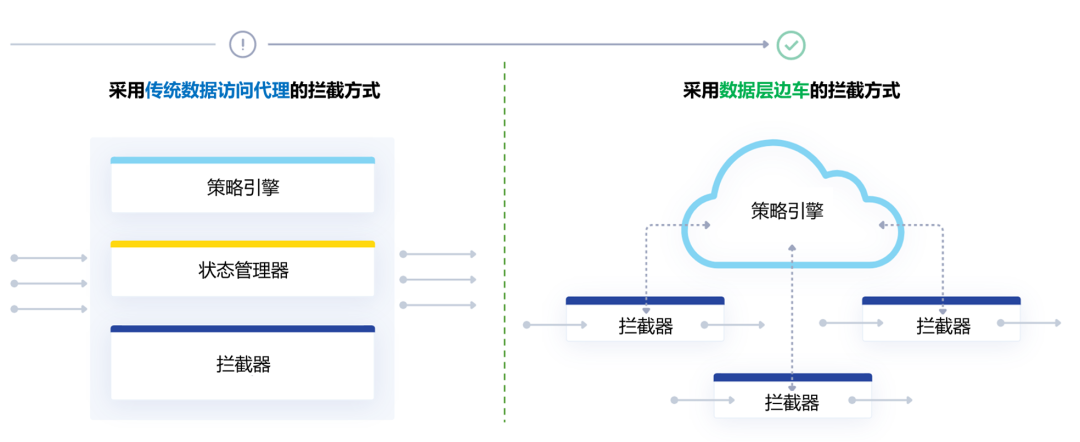
图4-拦截方式对比:传统代理 vs. 数据层边车
如上图所示,数据层边车可以采取无状态方式运行,从而支持横向扩展和高可用性。
传统的应用程序代理,需要管理查询客户端的会话状态,以帮助旧数据库架构应付繁重的工作压力。
而如今,数据存储库能够自己管理数据层连接,因此数据层边车可以无状态运行。于是,可以部署多个边车,来保护单个数据存储库。
3)数据层边车 vs. 数据库代理
数据层边车与数据库代理相比,具有很多明显的优势:
数据架构的先进性:数据层边车支持现代数据网格架构;而数据库代理采用中心辐射架构,来自微服务的流量被迫先到达代理,然后才被发送到目标。
云编排平台的可用性:数据层边车使用云编排平台(如Kubernetes)部署;而数据库代理通常使用未集成到云编排平台。
流量控制能力:数据层边车支持全方向流量控制,即包括南北向和东西向;而数据库代理仅支持南北向。
可观测能力:数据层边车与可观测性技术栈(如ELK、Prometheus等)高度集成,具有丰富的遥测数据;而数据库代理只有基本的日志数据。
微服务环境的适应性:数据层边车与基础设施模板工具(如Terraform、Cloudformation等)一起使用;而数据库代理不适合高度分布式的微服务环境。
DevOps集成:数据层边车采取API优先原则,与DevOps工具(如Prometheus、Grafana等)集成,用于日志记录、监测、可视化、CI/CD;而数据库代理缺少与DevOps工具的集成。
持续部署:数据层边车通过与CI/CD工具(如Jenkins X、Spinnaker等)的集成,实现持续部署;而数据库代理不支持CI/CD。
网络延迟:数据层边车采用无状态的断路器设计,使得去往数据存储库的流量延迟可以忽略不计;而数据库代理在服务和数据存储库之间引入额外控制点,导致不可忽略的网络延迟。
身份保护:数据层边车内置了使用mTLS的身份保护,提供了原生的身份认证和授权能力;而数据库代理缺少对连接服务进行身份认证和授权的原生支持。(一帆 & 柯学)
声明:本文来自网络安全观,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
