
深度学习模型已成为现代人工智能中的重要资产,未经授权对模型进行复制将会导致版权侵犯,并给模型所有者带来巨大的经济损失。因此,深度学习模型的版权保护问题至关重要。现有的模型版权保护技术主要包括水印和指纹。然而,模型水印具有入侵性,即需要篡改训练过程以嵌入水印,这可能会损害模型效用或在模型中引入新的安全威胁,同时,模型水印和模型指纹在面对多样化的自适应攻击和模型提取攻击时都存在一定的不足。
DeepJudge框架考虑的攻击场景和测试流程如图1所示。攻击场景包括对模型的微调、剪枝和提取攻击,三种攻击得到的模型都被认为是受害者模型的拷贝。测试流程包括三个阶段,第一阶段生成测试用例,第二阶段在一组测试指标下计算可疑模型和受害者模型之间的相似度,第三阶段根据阈值做出可疑模型是否为拷贝的最终判断。
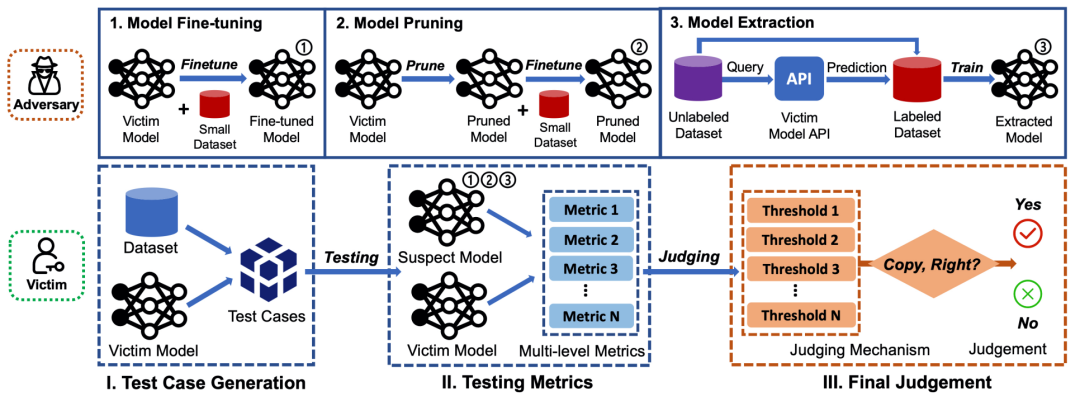
图1 DeepJudge测试框架
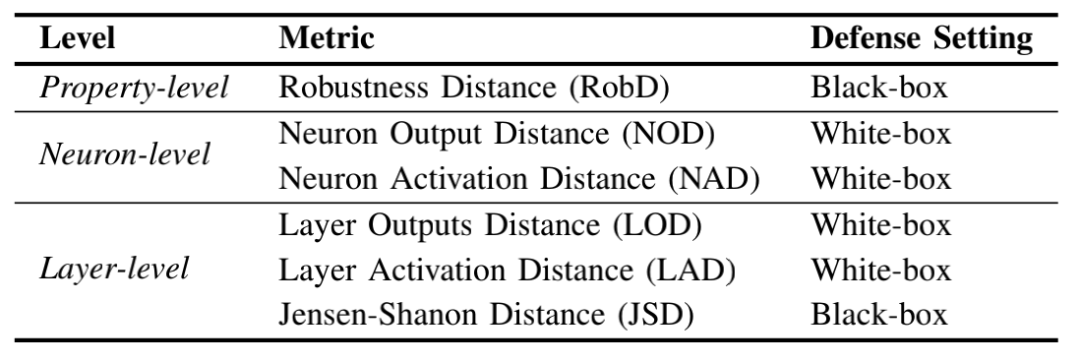
本文设计了多个刻画两个模型之间的相似度的指标,这些指标总结在表1中,包括了黑盒测试和白盒测试,这些指标的计算依赖于预先根据受害者模型和数据集生成的测试用例。黑盒测试只需要访问模型预测概率或预测标签,以在受害者模型上通过对抗攻击方法生成的一组对抗样本为测试用例,其中RobD用于计算两个模型在测试用例上分类准确率的差值,JSD用于计算两个模型在测试用例上预测概率的JS散度。白盒测试需要访问模型内部,作者为白盒测试设计了测试用例生成算法,旨在使得测试用例能够使得神经元输出超过一定的阈值。NOD和NAD都是神经元级别的度量指标,分别用于计算两个模型中某个神经元对于测试用例的输出和激活之间的距离,LOD和LAD都是层级别的指标,分别用于计算两个模型中某个层对于测试用例的输出和激活之间的距离。
表1 本文提出的多级测试指标
对于可疑模型,DeepJudge根据对其黑盒或白盒的访问权限计算测试指标,与受害者模型相似的可疑模型(正可疑模型)将会有较小的距离值,而不相似的可疑模型(负可疑模型)将会有较大的距离值,因此,通过对每一个指标设定阈值可以做出该指标下的判断,再对各个指标的判断进行投票,可以最终确定可疑模型是否为受害者模型的拷贝。
本文在四个基准数据集上对微调、剪枝、模型提取攻击进行了测试。在CIFAR10和SpeechCommands数据集上对受害者模型微调、剪枝,以及两种负可疑模型的测试结果如图2所示。图2中的六边形雷达图是对六个距离指标归一化后再转化为相似度得到的结果(如将RobD归一化到[0,1],再1-RobD),正可疑模型与受害者模型的相似度远高于负可疑模型,因此可以给出可靠的判断。
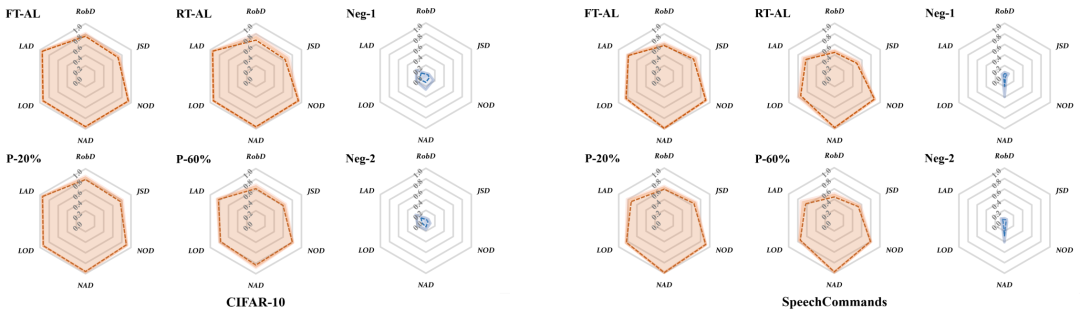
图2 不同可疑模型与受害者模型的相似度
DeepJudge对三种模型提取攻击的测试结果如表2所示。DeepJudge对于除了JBA(Jacobian-Based Augmentation)以外的提取攻击和负可疑模型都能够做出正确的判断,而JBA得到的拷贝因准确率过低而不能认为是成功的提取攻击。
表2 对模型提取攻击的测试结果

该论文被IEEE Symposium on Security and Privacy (S&P) 2022录用,作者为来自浙江大学、曼彻斯特大学、迪肯大学、伊利诺伊大学厄巴纳-香槟分校、加州大学伯克利分校的Jialuo Chen, Jingyi Wang, Tinglan Peng, Youcheng Sun, Peng Cheng, Shouling Ji, Xingjun Mat, Bo Lis, Dawn Song.
参考文献
J. Chen, J. Wang, T. Peng, Y. Sun, P. Cheng, S. Ji, X. Ma, B. Li, and D. Song, “Copy, right? A testing framework for copyright protection of deep learning models,” in 2022 IEEE Symposium on Security and Privacy (SP), 2022. (点击下方阅读原文查看论文全文)
(本文由复旦大学多媒体智能安全实验室谭景轩撰稿介绍)
声明:本文来自隐者联盟,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
