
作者:王宇、佘箫寒、邱雪涛、万四爽
一、背景介绍
客服部门在日常运营过程中,会产生大量的非结构化的语音与文本数据,这些数据中往往蕴含了用户对企业产品、营销活动等最真实的反馈数据,客服部门在日常工作中,投入了大量的人力进行人工分析,因此,提升该类数据的分析与挖掘能力,不仅会显著降低客服部门的日常运营成本,还能大大提升公司营销活动、产品设计的优化水平。
文本聚类(Text clustering)是自然语言处理中的一项重要技术,它主要将大量文本语料通过机器处理,自动分成若干类别。作为一种无监督的机器学习方法,文本聚类技术不需要预先对文档手工标注类别,因此具有较强的灵活性和自动化处理能力,已经成为对文本信息进行有效地挖掘、摘要提取的重要手段。另一方面,随着语音识别技术取得重大进展,尤其是语音转文本技术为传统的语音数据转换成文本数据提供了有效的方法,为传统的语音非结构化数据分析,大大提供了便利。为此,我们可以看出以文本聚类技术为代表的文本挖掘技术是客服部门大量非结构化数据分析与挖掘核心。
本文主要阐述了我们在客服对话文本挖掘领域的探索与实践,重点对短文本聚类中的初始簇数设置以及聚类描述归纳两类核心问题,提出了有效的优化方法。
二、数据理解与分析
(一)数据介绍
客服的原始数据主要以对话的形式保存的,具体样例可见图1(已隐藏客户个人信息)。

图1客服文本对话数据样例
通过这个例子可以看出,客户所关心的问题是“自己没有享受到优惠”,但需要注意的是,如果直接将整个对话文本作为聚类的样本,格式噪声以及语义噪声必然会对聚类的效果造成较大的影响。因此,我们必须要对数据进行预处理。
(二)数据预处理
1、抽取用户关键意图语句
首先,为了后续描述方便,我们将对话的某一方在一次说话中的连续内容定义为一个“句段”。根据观察及经验,客户往往会在第一时间将自己需要咨询的问题或者投诉的内容表达出来,因此,在不损失相对较多的语义信息的前提下,我们可以直接提取客户的第一个句段来达到简化模型,去除对话噪声干扰的效果。同时,由于部分客户的第一句段是“你好”、“请问在吗”这些问候性质的对话,为了避免只提取到这些无意义的语句,我们对句段的词语数量设定了一个阈值(文中定为4),如果第一句段的词语数量低于这个阈值,则自定将后续的一个句段也加进来,直到不低于阈值。
如图2所示,两个蓝框中选定的内容分别是客户的第一、二句段,其中实线蓝框的内容就是我们需要提取的客户的第一句段。

图2 客服对话用户关键意图语句的抽取
2、提取用户数据的否定窗口
在咨询或者投诉的过程中,客户大多数情况下都会借助否定词或者疑问词来提出遇到的问题,因此为了进一步的提炼客户对话信息,我们采取以下方法来提取客户对话的否定窗口。
※ 利用常见的中英符号(如全、半角的逗号、句号等)将第一句段分为若干个短句。
※ 找到第一个否定词或者疑问词所在的短句作为窗口。
※ 设置指定的窗口大小(本文设定的前后步长均是1),提取否定窗口。
另外,在极少情况下,客户的第一句段不包含任意否定词或者疑问词,这种情况下我们会直接将第一句段作为否定窗口。
如图3所示,在上一步样例提取的第一句段中,我们找到的第一个否定词是“没有”,因此第3个分句作为否定窗口的中心,第2~4个分句作为否定窗口。最终我们提取将否定窗口用空格拼成一句话,作为数据预处理的最终结果,即 “我昨天用银联钱包62开头信用卡消费满5元为何今天再次消费没有减5元156********手机号码”。
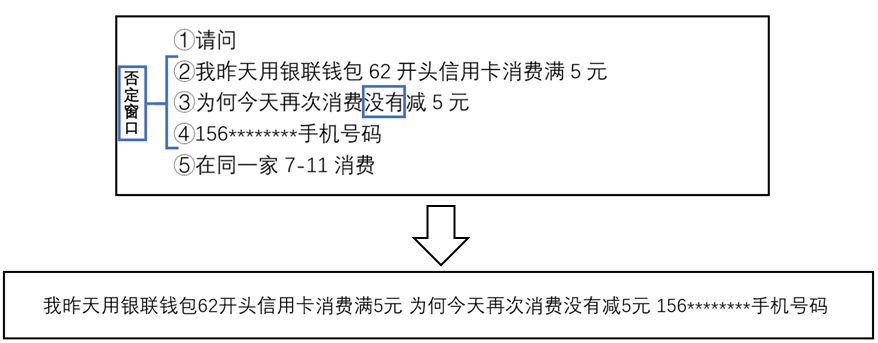
图3 用户数据的否定窗口的提取
三、文本模型的构造
1、词向量编码方式
为了将自然语言交给机器学习中的算法来处理,我们首先要将文本数字化,而词向量模型就是用来将文本中的词语进行数字化的一种方式。
在词向量模型中,最简单的一种方式是独热编码(One-Hot Representation),这种方式是用一个维度等于词典大小的向量来表示一个词,其中向量的分量只在该词语在词典中的位置所对应的下标为1,其他全为0。但是这种表示方法没有考虑词与词之间的语义相关性,如 “云闪付”和“银联钱包”,如果利用独热编码的表示方法,两者相似度为0。但是二者文本意义都是关于银联支付app的相关问题。由于短文本长度较短,采用传统的VSM表示文本时会出现严重的特征稀疏问题,在解决某些任务的时候会造成维数灾难。
另一种词向量的表达方式是分布式编码(Distributed Representation),这里的“分布式”是指一个个体用几个编码单元而不是一个编码单元表示,即一个个体分布在几个编码单元上,而在独热编码中,一个个体仅由一个编码单元表示。该方法最早是 Hinton 于 1986 年提出的,可以克服独热编码的缺点。其基本想法是:通过训练将某种语言中的每一个词映射成一个固定长度的短向量(相对于独热编码的长向量而言的),将所有这些向量放在一起形成一个词向量空间,而每一向量则为该空间中的一个点,在这个空间上引入距离,则可以根据词语之间的距离来判断其语义或语法上的相似性。
2、神经网络语言模型
本文采取Google提出的Word2Vec方法中的N-gram模型,利用gensim库中的word2vec函数进行训练(本文中词向量维度设定为200,窗口大小为5),得到分布式编码的词向量表示。具体的神经网络训练模型如下
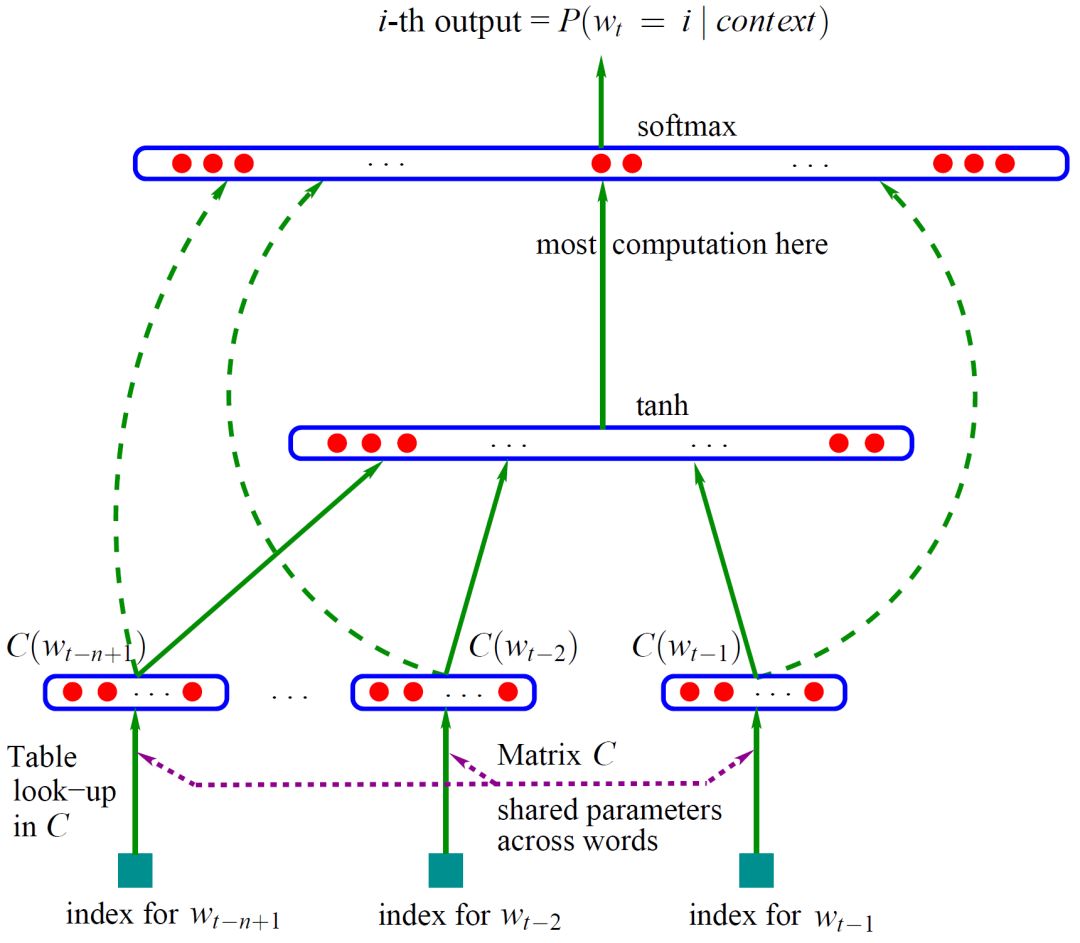
图4 N-gram 模型
针对网络客服对话文本聚类这一特定业务问题下,经过实验,我们发现直接采用网络上预训练好的词向量(如Google的Word2Vec中文模型),或者是利用大型的开源语料库(搜狗实验室互联网语料库)来进行词向量训练,其效果均一般。因此,本文的词向量训练语料直接从网络客服对话数据中获取:将每个对话去除固定格式,作为一个独立的文本,最终语料库的大小为109479个客服对话数据。
3、词向量模型训练效果
如表1、2,选取了“云闪付”和“711”这两个词语作为展示对象。
表1 表2

4、短文本编码:词向量均值
由于聚类模型的输入的一个文本,因此我们在训练得到词向量之后仍需要对文本进行编码,对其进行数字化。同时,通过箱图(图5)可看出,否定窗口长度的中位数是23,上下四分位数分别是23和17,上下边缘分别是52和1,其余均属于异常值。因此,可以得知经过第一步数据预处理后得到的否定窗口文本长度较低,属于短文本的类型。
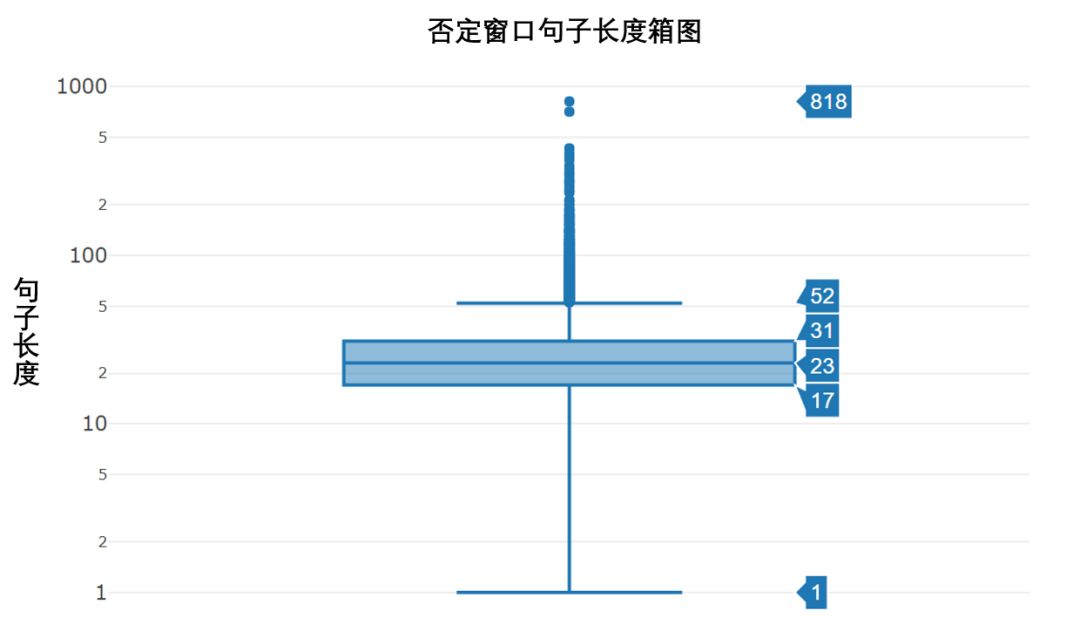
图5 否定窗口句子长度箱图
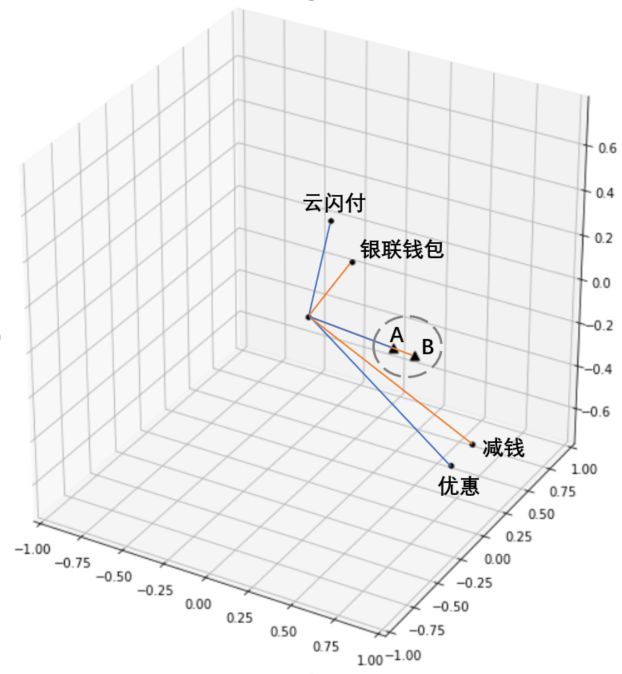
对于短文本,我们采取了短文本向量编码方式:将文本分词后的词向量均值来作为该文本在向量空间上的编码。在文本所含词语个数不多的情况下,语义相近的句子在向量空间中仍可以保持较小的余弦距离。下面用一个例子来说明短文本的词向量均值编码方式的合理性。如图6,我们选取了 A:“昨天使用银联钱包没有减钱 ”和 B:“怎么我使用云闪付没优惠”这两个句子并对其进行分词。
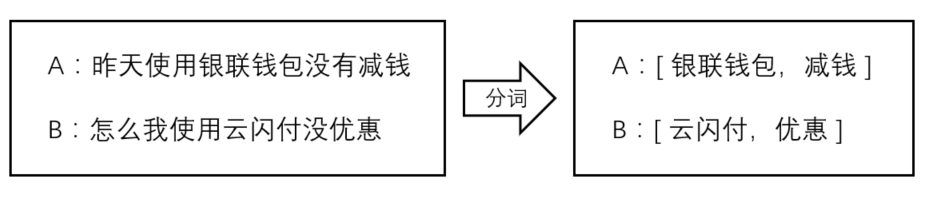
图6 短文本的词向量均值编码
对于短文本句子A和B,从图7中我们可以看到,A分词后的词向量均值与B的在向量空间上距离相近,因此我们,我们可以合理地将每一个否定窗口的词向量均值向量作为其特征,然后根据一定的距离度量(本文采用的是欧式距离)来进行聚类。
四、基于关键词连接矩阵的文本聚类模型
为了从客服对话数据中提取用户的主要问题以及业务痛点,一个基本思路就是首先对大量的文本对话数据进行聚类,形成业务主题,然后归纳出主题的具体描述。
1、基于K-means算法的聚类算法
K-means算法是最为经典的基于划分的聚类方法,是十大经典数据挖掘算法之一。K-means算法的基本思想是:以空间中k个点为中心进行聚类,对最靠近他们的对象归类。通过迭代的方法,逐次更新各聚类中心的值,直至得到最好的聚类结果。
具体算法描述如下:

通过词向量均值的短文本编码方法,将每一个否定窗口转换为一个特定维度(与词向量模型的维度相同)的向量,作为该样本的特征作为输入,然后调用sklearn机器学习库中的Cluster.Kmeans模块来进行聚类。
由于K-Means聚类方法需提前指定聚类个数,且聚类个数对聚类的效果影响较大,因此建议在聚类之前,根据业务逻辑进行多次取值尝试,不断优化聚类个数。另外,针对银联客服网络客服对话数据的问题,本模型通过多次实验,设定了一系列的较为合理的默认聚类个数,如不指定聚类个数,模型会自动根据样本数量来自动调整聚类个数。
2、K-means算法的不足
经过实验发现,K-means聚类的结果任然存在以下两个问题:
1)若把聚类个数设置得较大,模型会将那些出现次数多的问题的不同表述分成不同的类别,例如,在抱怨“没有享受到优惠活动”这个问题上,有一些用户或直接抱怨说“付款时没减**元”;而另外一些用户可能就会比较完整地说“我在参加***活动时,使用云闪付后无法享受优惠”。这实际上属于同一种问题,但是由于客户表述的差异程度高,模型有可能会错误地将其视为不同的类别。
2)若把聚类个数设置得稍小,模型在一定程度上可以改善1)的问题,但这时候又会引入另外一个新的问题:由于基于词向量均值的句子编码方式不能完全地提取句子的语义含义,不可避免地会引入噪声或者偏差。因此如果聚类个数较小,模型有可能会将不同类别的样本错误地聚为一类。
3、基于关键词连接矩阵的聚类合并算法
上述提及K-means聚类结果存在的问题,可以总结为:K-means方法可以保证每一个聚类类别中样本都属于同一内容,但会存在将关于同一内容的样本拆分成若干类的问题。具体情况如表3所示,假设样本的类别有3种,分别用不同的颜色来表示。
针对这一问题的特点,本文提出了基于关键词连接矩阵的聚类合并方法,算法思想为:把聚类个数设置得稍大,再对K-means算法的初步聚类结果进行合并修正,从而得到更加准确的聚类结果。
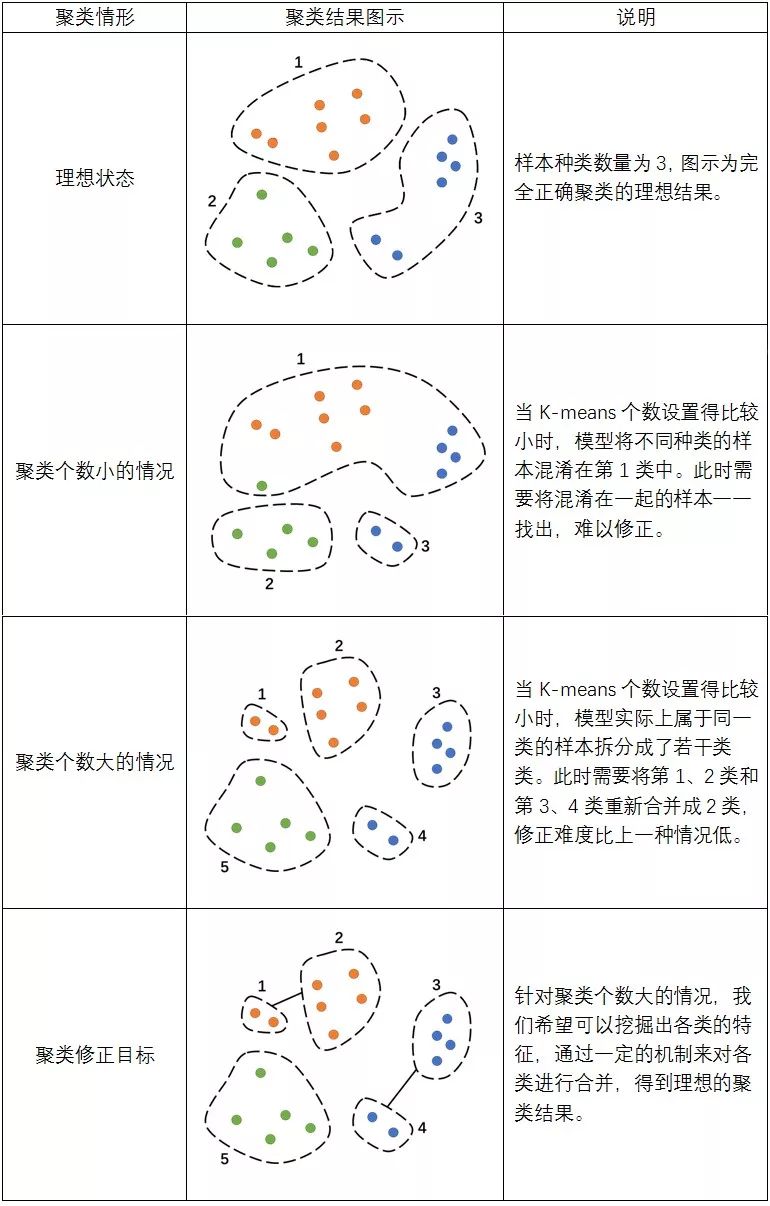
通过对K-means聚类结果的观察,需要修正重新合并为一类的样本具有这样的特点:
※ 客户均在描述同一个内容,但是表述的方式不一样。
※ 虽然表述的方式各异,但总是会提到一些具有明显辨识度的关键词。
通过分析两个不同“优惠”类别提取的核心关键词,虽然表述方式不一样,但两类样本均常出现”享受“、”优惠”、“减”、“5折”、“双十二”、“双12“等词语,因此可以进行合并。受此启发,我们利用关键词提取算法提取每一类的关键词,然后将关键词集合交叉程度较高的若干类合并成新的一类。由此展开,本文提出了基于关键词连接矩阵的聚类合并算法。具体步骤如下:
1)记K-means聚类结果有类。对于这类中的每一类,计算各词的tf-idf值并从大小排序,取前(本文取5)个词语作为该类的关键词。
2)如示例,以第类的关键词与第类的关键词的重叠个数作为连接度,得出各类的连接矩阵(图9)。

3)设定合并阈值(本文设为3),根据下述公式以及矩阵得出合并矩阵(图9)。
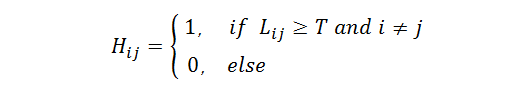
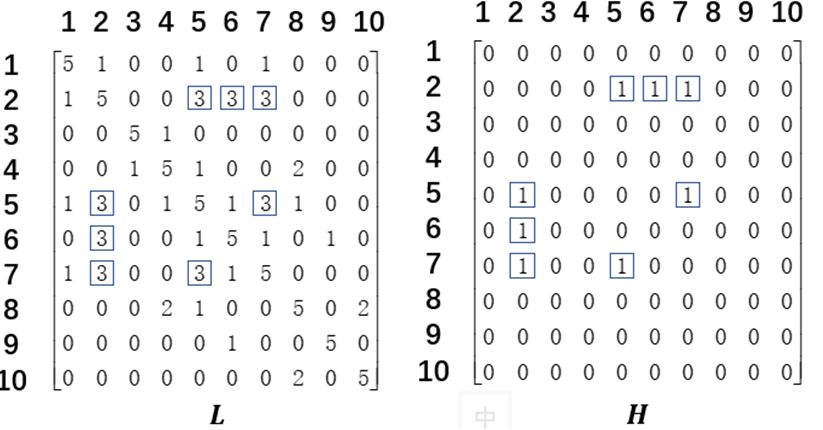
4)根据合并矩阵,画出无向图(图10),将直接或间接相连的若干类合并为新的同一类。
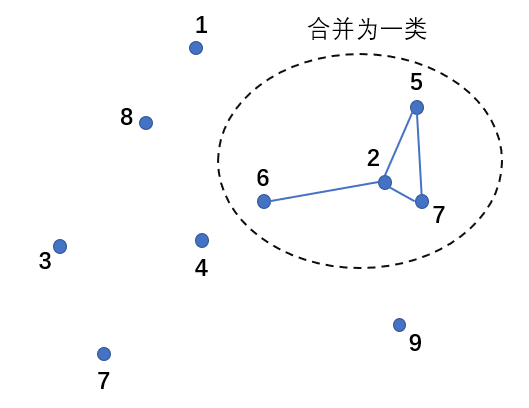
图10 聚类结果的二次合并
五、基于关键词评分的聚类摘要自动提取模型
从短文本中生成摘要,是困扰业界由来已久的问题,常用的信息摘要生成方法在该情形下常常失效,本文提出了一种新的思路,借助于词频统计,通过综合考量关键词命中得分与句子简明得分,筛选用户对话数据,作为短文本的聚类摘要。充分利用了原始语料的可读性,也避免了传统方法生成摘要的晦涩。
1、抽取式自动摘要
为了使聚类的结果更易于理解,更好地挖掘客户的业务需求和业务痛点,我们需要对于每一个类别生成一个摘要。但是,传统的自动摘要算法是针对一篇完整的文档来提取的,而我们的情况是:某一类别下的各个样本是语义相近的短文本,无法拼凑成文档,因此直接采用现有的自动摘要算法效果一般。
针对这一特定问题,本文借鉴了自动提取文档摘要中的抽取式方法,对各个样本进行评分排序,选取得分最高的作为该类的摘要。通过这样的方法,各类的摘要均是直接从客户对话来提取中,语句通顺度、可读性比较高;但另一方面,抽取式方法的效果十分依赖于评分的标准,因此我们必须针对网络客服对话这一特定场景制定合适的评分规则。
2、关键词评分标准
关键词命中得分:对于某一类的一个样本,对它进行分词,得到词语列表。若词语属于该类的关键词,则视为命中,最后将命中率作为这个样本的关键词命中得分。关键词命中得分越高,说明句子语义在类别的关键问题上的集中程度越高。
句子简明性得分:对于某一类的一个样本,对它进行分词,得到词语列表,计算保留下来的词语字符长度所占原来样本长度的比率,以此作为这个样本的句子简明性得分。句子简明性得分越高,说明句子越简明,包含的无关语义噪声越少。
具体计算过程可见下图实例(表4),类别中的某一个样本“我昨天在云闪付app充了50话费没有到账”的关键词命中得分、句子简明性得分分别是0.75和0.5。
表4 聚类摘要的生成过程

3、关键词评分规则
1)考虑到避免选取长度较短的句子,我们对句子长度制定了一定的限制,只有大于阈值(本文设为7)的样本才参与评分,从而避免了提取的摘要过短。
2)两项得分越高越好,但优先考虑关键词命中得分,句子简明性得分次之。如果对于某一类,关键词命中得分最高句子只有一个,则该句子直接作为摘要;若不止一个,则从中选取句子简明性得分最高的句子作为摘要。
4、聚类摘要的润色
实验过程中发现,通过上述步骤所提取的摘要有一定的可能存在以下的问题:
※ 口语化严重
※ 冗余信息较多,不够精炼
※ 用户反复说同一句话,导致摘要重复度高
※ 出现用户的私人信息,如手机号、银行卡号等
针对以上的问题,本文提出了以下的摘要润色步骤:
※ 去除“你好”、“啊”、“呀”等口语化词语
※ 以空格作为分隔符切割摘要,只保留含有关键词的句段,重新拼接成新的摘要
※ 进行重复子串检索,如果存在长度占比大于40%的重复子串,则对其进行去重
※ 对摘要进行分词,利用正则表达式匹配数字,如果数字部分长度占比大于50%,则去除该分词。
六、总结
本文主要针对短文本聚类中的初始簇数设置以及聚类描述归纳两类核心问题,提出了有效的方法:
※ 如何设置有效的聚类初始簇数。
针对该问题,在传统k-means聚类方法的基础了,我们提出了基于关键词链接矩阵的聚类类别合并算法,通过关键词集合交叉程度,实现相似簇的二次聚合,有效解决了传统聚类中大量相似簇无法有效合并的问题。
※ 如何归纳具体的簇描述信息。
从短文本中生成摘要,是困扰业界由来已久的问题,常用的信息摘要生成方法在该情形下常常失效,本文提出了一种新的思路,借助于词频统计,通过综合考量关键词命中得分与句子简明得分,筛选用户对话数据,作为短文本的聚类摘要。充分利用了原始语料的可读性,也避免了传统方法生成摘要的晦涩。
基于文本聚类的挖掘技术具有很强的灵活性,对语料有很强的敏感性,难以有通用的方法,本文为短文本的聚类挖掘提供了有效的方法。
声明:本文来自电子商务电子支付国家工程实验室,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
