导读
2025年12月3日,未来生命研究所(Future of Life Institute)发布2025年冬季《AI安全指数报告》(AI Safety Index Winter 2025)。这是该指数报告自2024年底首次发布以来的第三份安全指数报告。
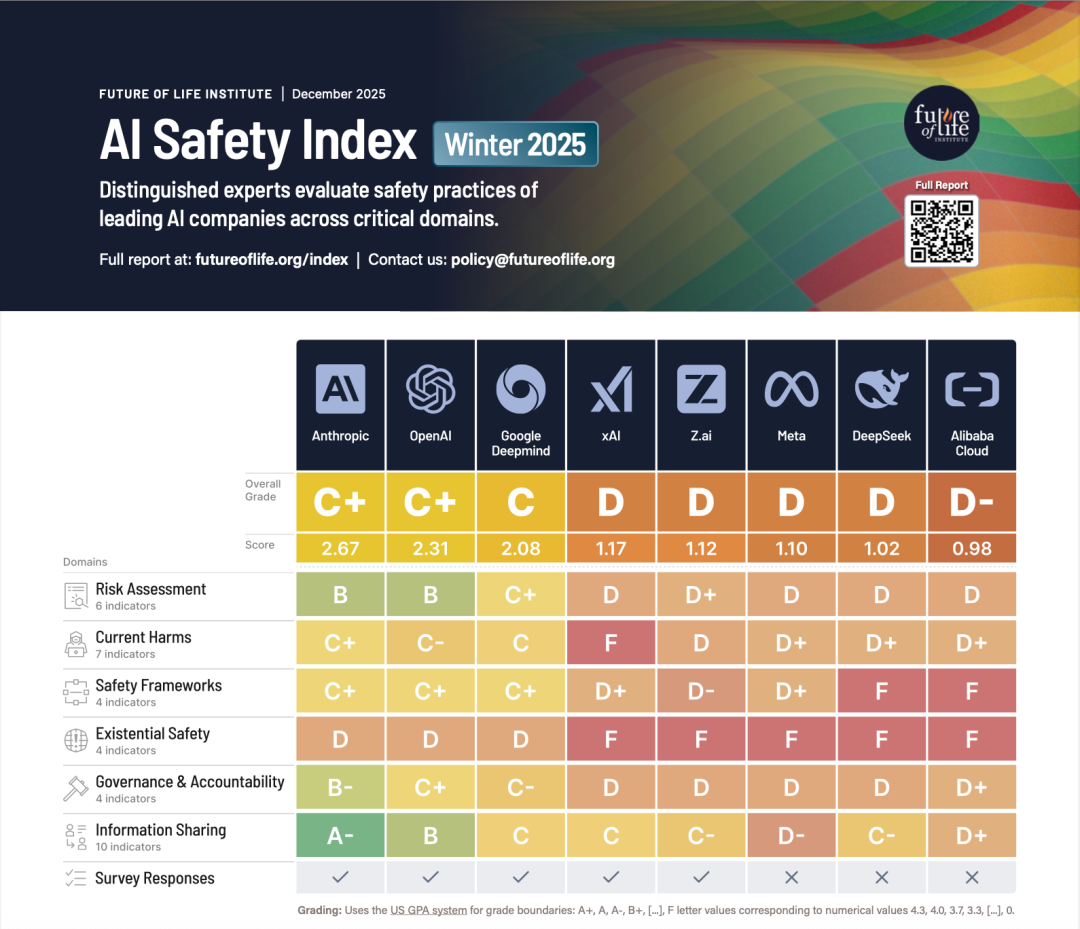
本期指数由8位独立专家对全球主要AI公司的安全实践进行系统评估,涵盖风险评估、现实危害、安全框架、生存安全、治理问责、信息共享等六个维度。评估对象包括Anthropic、OpenAI、Google DeepMind、xAI、智谱AI、Meta、DeepSeek以及阿里云,其中前五家今年首次完整提交详细问卷,披露了此前未公开的关键安全信息。中国企业得分较以往明显提升,智谱AI在安全指标上赶超Meta,但整体仍存在明显差距。
安远AI在肯定该指数推动AI行业安全透明度的同时,也认为其方法论与评价视角仍有待商榷和完善,其中部分评价指标的设计未充分考虑中国企业的现实合规环境和已有安全治理实践,客观上使中国公司先天处于不利的位置,低估中国企业在AI安全治理方面的真实进展。
关于本期《AI安全指数报告》
(本节转述自FLI报告摘要和媒体通稿,不代表安远AI观点)
最新《AI安全指数报告》显示,当前全球主要AI公司在安全治理方面仍存在显著差距。顶级公司(Anthropic、OpenAI、Google DeepMind)在风险评估、安全框架和跨机构信息共享等维度上整体领先,其余受评公司(Z.ai、xAI、Meta、阿里云、DeepSeek)在信息披露、系统性安全流程和稳健评估实践方面仍相对薄弱,难以形成统一而稳定的行业水准。
本期指数在评估对象中纳入三家中国企业,反映出中国在前沿模型上的发展速度正持续加快。继之前已纳入评估的智谱AI和DeepSeek之后,本期新增阿里云。在11月20日更新的Chatbot Arena最新榜单中,GLM-4.6与Qwen3 Max表现已领先于包含Anthropic在内的多家国际竞争者,进一步凸显了中国前沿模型在全球的竞争力正快速提升。同时,智谱AI在风险评估和信息公开上都有明显进步,整体得分赶超Meta。
报告指出,生存安全(Existential Safety)仍是整个行业的核心结构性弱点。各家公司在竞相开发通用人工智能(AGI)和超级人工智能(ASI)的同时,并未提出足够明确、可验证的策略来确保此类系统在能力突破后仍保持可控,这意味着最严重的风险在当前阶段仍未得到有效应对。
尽管做出了公开承诺,但各公司的安全实践仍然未能达到新兴的全球标准。虽然许多公司在一定程度上符合这些新兴标准,但实施的深度、具体性和质量仍然参差不齐,导致其安全实践尚未达到欧盟人工智能行为准则等框架所设想的严谨性、可衡量性和透明度。
报告同时指出,各家公司在“现实危害”项目上的得分整体下降,反映行业在快速扩张的同时暴露出更多潜在问题。包括心理健康风险、误导性内容、AI辅助黑客攻击以及用户可能遭受的精神伤害等。正如未来生命研究所主席、麻省理工学院教授Max Tegmark所强调的,尽管近期AI引发的现实危害不断出现,“美国AI公司的监管仍低于餐饮业,并持续反对具有约束力的安全标准。”
报告呼吁各公司进一步加强系统化的风险识别,提升安全治理措施的针对性和实际成效,完善可验证的控制机制,并加快推进面向高能力系统的风险缓解方案建设。特别建议中国企业在保持能力快速提升的同时,进一步主动披露安全治理流程、模型危害审核方法、内部红队实践及第三方独立监督机制,以促进外部机构的充分评估,并推动全球人工智能安全治理朝着更加均衡与协同的方向发展。
安远AI对本期《AI安全指数报告》的评论
对美国公司自愿安全实践的结构性偏向。本期《AI安全指数报告》在评价方法上明显侧重于美国公司普遍采取的自愿性安全实践,例如主动披露安全评估、发布前沿AI安全框架等。相较之下,中国公司主要由强制性法规与行业标准驱动,其安全实践更多体现为合规性要求而非自愿承诺和披露。尽管报告承认了这一差异,并指出“在国内法规要求下,中国公司在部分指标上具有更强的基本问责制”,但评分机制对这一结构性差异的体现仍不充分。此外,指数未纳入中国人工智能产业发展联盟(AIIA)发布的《人工智能安全承诺》,该承诺由阿里巴巴、DeepSeek、智谱AI等主要企业共同签署,并汇总披露了典型实践,代表着中国行业内部的重要自律性举措。
对公司自主披露的过度依赖与关键实践的遗漏。指数在多个核心环节上依赖企业自主披露,例如“系统卡、基础模型评测”和“企业安全调查”等。这一做法在一定程度上削弱了评估的独立性和全面性。一个关键的疏漏是,它未能认可DeepSeek R1模型在《自然》(Nature)杂志上发表的同行评审论文,这是首个通过权威学术期刊同行评审的大语言模型,其中包含一个接受独立专家公开检视的安全评估部分。这一里程碑式成果本应被列为DeepSeek的“进展亮点”(Progress Highlights)中被引用,并可作为业界在治理透明度方面的重要范例。此外,指数对开放权重(open-weight)模型的认可也明显不足,而这类模型(其中相当部分由中国公司发布)天然具备更高透明度与外部可审计性。
评估框架中的西方中心视角。从整体结构来看,该指数在设计上仍带有西方中心视角。例如,对中国企业提出的改进建议之一是“考虑签署《欧盟通用型人工智能行为准则》”,这一建议本身假定欧盟框架为普遍适用的基准。此外,“当前危害”(Current Harms)类别高度依赖由西方机构开发的评测工具(如斯坦福大学的HELM安全基准),这些基准可能在文化价值观、社会关注点或语言环境上天然更贴近西方语境,从而无法完整反映中国《生成式人工智能服务管理暂行办法》等国内法规对内容安全和价值导向方面的合规要求。
中国监管框架对生存安全议题的覆盖深度仍有限。目前,中国的生成式AI强制性法规尚未涉及生存安全,例如失控风险等前沿议题。相关内容主要出现在全国网安标委发布的《人工智能安全治理框架》2.0版等指导性文件中,其定位以原则性引导为主,尚未形成具有强制约束力的制度要求。
在模型能力快速提升的同时,中国模型的前沿风险水平正在逼近国际领先模型,但安全水平还有差距。这一趋势在安远AI“前沿AI风险监测平台”的监测报告等研究中有所体现。相关发现已被《人民日报》、新华社《经济参考报》、中国香港《南华早报》等媒体连续报道和引用,显示中国模型在性能提升的同时,其风险级别已进入全球前沿区间。然而,与部分美国公司已对前沿风险展开系统性投入相比,中国企业在相关议题上的整体关注度仍存在差距。这既与国内监管框架中前沿风险议题的非强制性定位有关,也反映出企业在风险优先级判断和资源配置上的现实选择。
综上所述,我们建议未来生命研究所的《AI安全指数报告》在后续迭代中进一步提升方法论的全球代表性,充分吸收不同治理体系的差异,减少对单一监管模式与价值体系的隐性偏置,以构建更平衡、更广泛适用的AI安全评估框架。
声明:本文来自安远AI,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
