作者:李丹枫
来自京东科技风险管理中心原创,转载请获得授权
一、风险洞察平台介绍
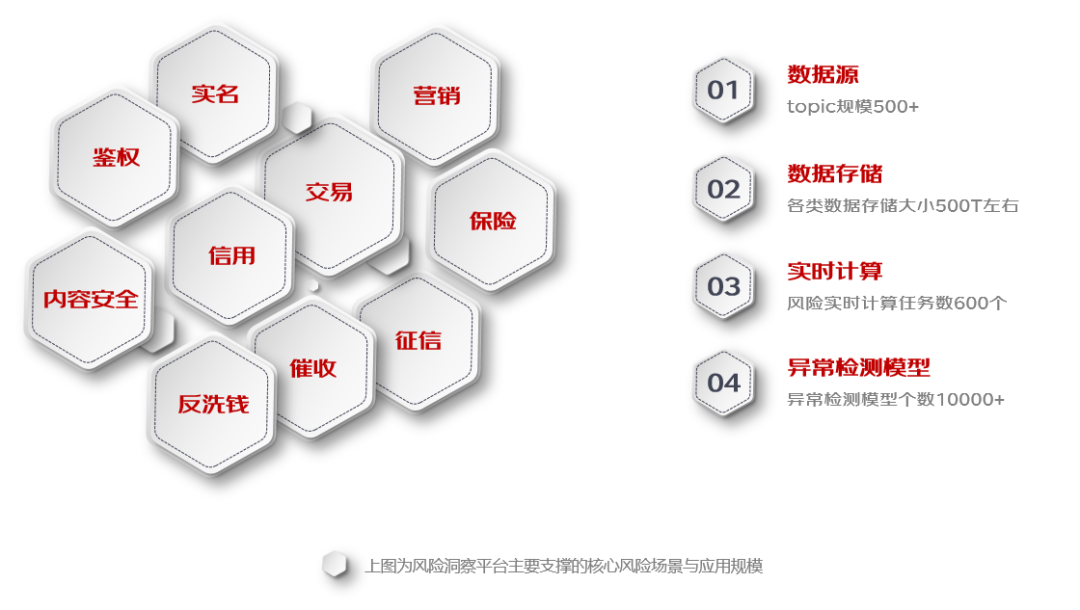
以Clickhouse+Flink实时计算+智能算法为核心架构搭建的风险洞察平台,建立了全面的、多层次的、立体的风险业务监控体系,已支撑欺诈风险、信用风险、企业风险、小微风险、洗钱风险、贷后催收等十余个风控核心场景的实时风险监测与风险预警,异常检测算法及时发现指标异常波动,基于根因策略快速做到风险归因分析并生成风险报告,接入MQ主题500+、数据模型6000+、实时预警4000+、 风险监控看板1000+、 异常检测模型10000+, 大促时期分钟级消息处理量达3400w/min,日均消息处理量达百亿。
二、风险洞察-遇到的技术挑战与解决方案
1、技术难点与挑战
风险洞察平台早期架构采用ElasticSearch作为数据存储,通过消费MQ消息进行批量写入,基于ElasticSearch明细数据进行指标计算来满足风险预警与风险监控的需求实现. 这种架构早期可以满足业务需求,但随着平台业务的发展与数据的膨胀,面临了以下痛点:
1)高吞吐的实时写入:随着平台接入的业务增多,数据规模也跟着相应增长。以营销反欺诈场景为例,大促期间峰值流量最大达到12000w/min,日常流量为60w/min, 如何保证海量数据的高吞吐、低延迟的写入,实现数据高效率的存储是当下风险洞察面临的核心问题;
2)高性能的实时查询:随着业务的快速发展,风险实时监控方面要求进一步提高。在保障风险指标的实时监控预警,实现风险策略的实时分析与验证方面有着极大的挑战;
3)复杂聚合计算能力:随着风险策略的优化升级,相关指标的计算逻辑已不满足于单表的简单聚合, 分析师需要结合更多的标签、特征、算等维度来进行策略的评估验证, 所以能够支撑分析师实现复杂聚合灵活分析是一大挑战. es这类复杂计算能力较弱的数据源已无法满足当下需求;
4)海量数据下的计算性能:在大促时期分钟级数据量处理量达到3400w/min, 所以在海量数据存储规模下, 最大程度保证计算性能, 提供实时计算结果仍是一大严峻挑战看。
2、技术解决方案
基于以上面临的技术痛点再结合当下风控业务现状的背景下, 我们以效率、成本、质量等方面对市面上主流OLAP引擎进行调研对比,如presto, impala, druid, kylin等,最终确定clickhouse能够更好的涵盖风险洞察所需的技术特点,并结合Flink实时计算能力实现整体风险洞察的计算+存储架构,具体方案如下:
1)高吞吐、实时的数据写入:clickhouse采用MPP架构,利用LSM算法实现内存预排序磁盘顺序写入,具备大批量、低延迟的写入优势, 并具有出色的数据压缩能力,最大能够达到20:1的压缩比;
2)高效快速的查询速度:clickhouse为列式存储数据库,稀疏索引结构,采用向量化执行引擎,最大程度上利用cpu能力,能够达到百亿数据秒级响应;
3)具备复杂聚合能力:clickhouse支持标准化SQL与完整的DBMS,拥有多样化的表引擎满足各类业务场景,能够灵活支撑复杂聚合计算需求;
4)clickhouse+flink预计算架构:将海量数据基于Flink预先聚合,减少clickhouse数据存储规模,降低聚合查询成本,最大程度上保证clickhouse的查询性能。
三、风险洞察-整体架构图
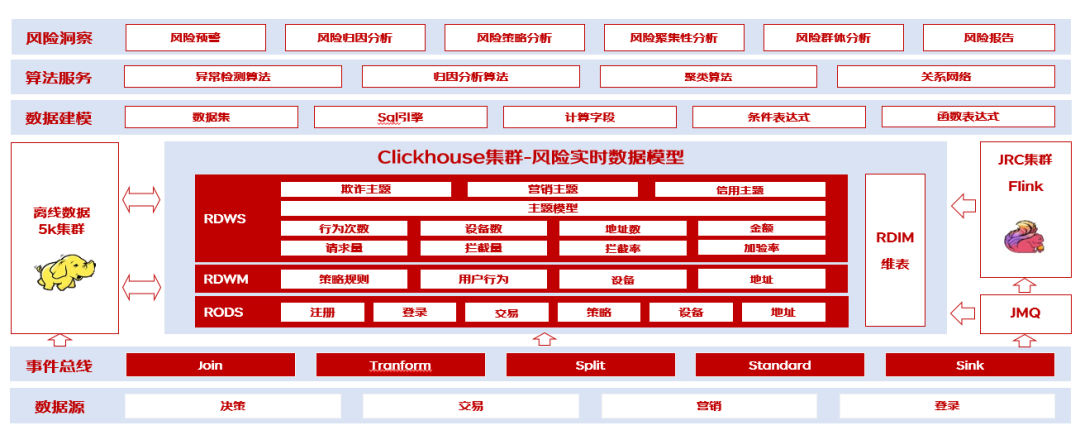
1、风险洞察-架构介绍
1)数据源:风险核心场景数据来源,底层基于插件化设计原则抽象统一数据源引擎,可通过扩展数据源连接器实现异构数据源接入,目前已支持clickhouse、mysql、presto、r2m、openmldb、csv等数据源;
2)事件总线:承担风险实时数据统一标准化处理的职责,负责将上游复杂数据进行解析、转换, 富化、分发等操作. 底层核心算子抽象为source、transform、sink三层架构, 支持各层算子插件式扩展, 并支持groovy、python等脚本语言自定义配置,可直接对接clikchouse集群或转发MQ至Flink进行实时计算处理,为整个风险洞察数据流转的重要一环;
3)风险数据模型:风险数据模型采用以clickhouse为基础的三层存储结构,分别对贴源层(RODS),轻度汇总(RDWM),聚合层(RDWS)数据进行存储,打通离线数据平台链路可实现离线与实时数据之间的互相推送转换,并基于Flink实现实时指标加工处理;
4)数据建模:统一标准化数据建模,支持拖拽生成或自定义SQL建模。底层抽象统一SQL引擎,基于ANSI SQL协议实现异构数据源语法解析、执行优化、数据查询等能力,支持自定义函数、sql参数、条件表达式等多种功能设定;
5)算法服务:基于数据模型结果进行异常检测、归因分析、聚类分析,挖掘潜在风险问题,为风险指标提供算法能力支撑;
6)风险洞察:上层风险数据应用,提供风险核心能力,如风险预警,风险分析,风险报告,风险感知,风险策略分析,风险群体分析等服务。
2、风险洞察-clickhouse实时数据模型设计
风险洞察架构的核心在于风险实时数据模型+实时计算架构,风险实时数据模型的核心在于clickhouse,接下来我们深入介绍下clickhouse在风险实时数据模型中的设计与使用。
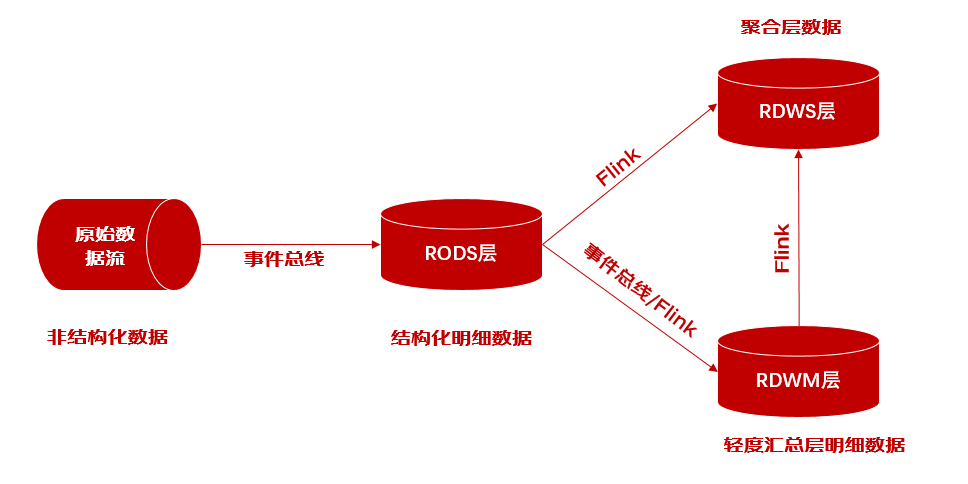
1)层级缩短: 首先,风险数据模型采用短链路架构设计,从RODS层可直接通过Flink构建RDWM层与RDWS层,重视层级缩短, 降低数据延迟;clickhouse作为分层数据载体,可根据业务需求提供不同层级的数据查询服务,当然基于性能的考虑推荐业务尽量使用第二层或第三层数据;
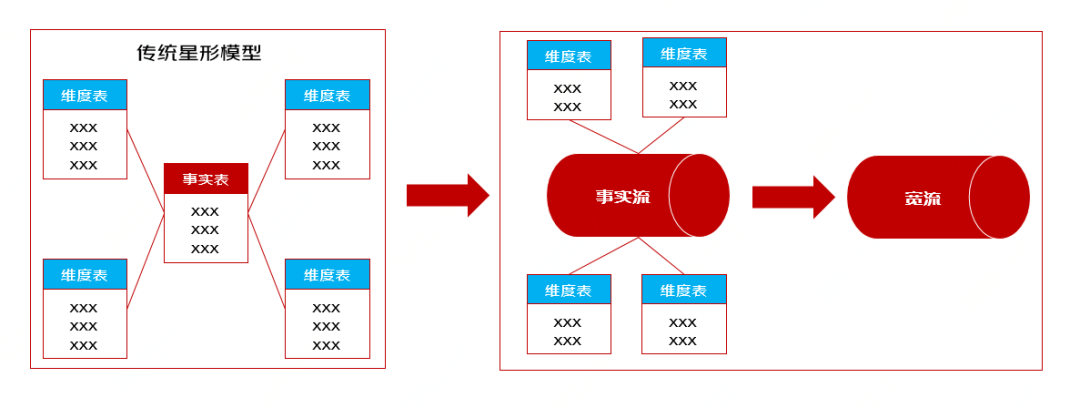
2)维度退化:传统数仓中查询会涉及事实表与维度表之间的关联,该操作会带来复杂的性能调优问题。为了发挥clickhouse单表计算优势,尽量多的将常用维度字段退化到事实表中,形成宽表供业务方来使用,减少联查带来的性能效率问题;
3)Flink预聚合:结合Flink实时计算引擎实现海量数据风险指标秒级或分钟级周期预聚合计算,降低下游计算成本,尤其在大促环境时期,通过预聚合手段能够显著提高clickhouse计算能力。

四、风险洞察-clickhouse的实践应用
介绍完clickhouse参与的架构设计理念,接下来结合具体实践场景来介绍下clickhouse在使用中遇到的问题与优化方案。
1、营销反欺诈场景大促实践
背景:营销反欺诈作为风控体系中的重要场景,其原始数据流具备两大特点:1. 消息体庞大且复杂,包含多种数据结构,但MQ消息体大小达17kb;2. 消息流量大,营销数据日常流量在1w/s左右,在2021双11大促时期峰值更是达到60w/s,为日常流量的60倍。因数据需要支撑实时看板监控与预警,所以如何保证数据写入的吞吐量与数据查询的及时性是极具挑战的问题。
初始设计:通过消费原始消息流,通过事件总线写入clickhouse。
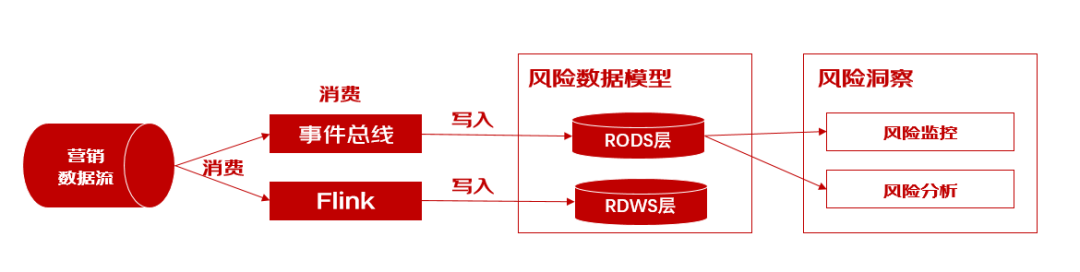
问题发现:
1)消费能力不足: 营销的消息体较为复杂,mq消息序列化反序列化操作耗费大量cpu,吞吐量瓶颈在于消息解析;
2)clickhouse写入异常: 在海量数据场景下会造成多频少批的写入,导致ck服务端生成大量小文件,文件merge时消耗服务端大量cpu与io,不足以支持写入频次导致抛出异常;
3)clickhouse查询异常: 大促时期数据查询与写入场景增多,导致超过ck集群最大并发数限制,抛出异常;
4)clickhouse计算效率下降: 大促时期海量数据背景下,基于海量明细数据的监控指标范围内数据量激增,影响一定的计算效率。
架构改造:
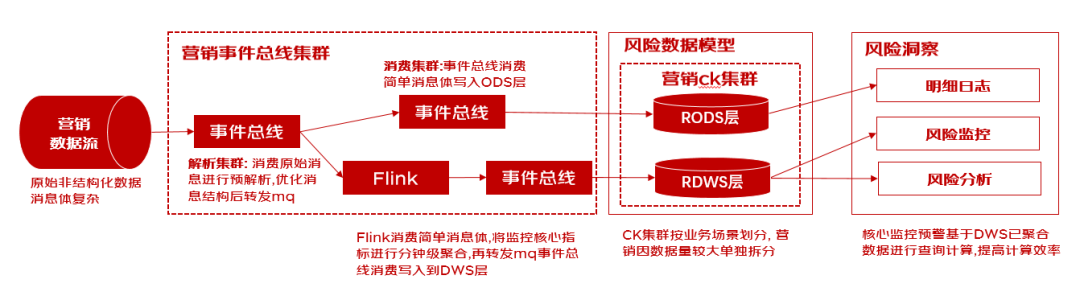
1)改造点1: 分而治之,集群拆分解耦
消费集群拆分,事件总线按照业务维度,职责维度进行深度拆分,将有远高于其他场景的营销流量单独拆分解耦,再根据解析,入库职责进一步拆分集群,实现解析集群机器cpu利用最大化,并降低下游如Flink计算,事件总线入库的cpu压力.提高消费效率;
clickhouse集群拆分,clickhouse按照业务维度进行单独拆分,总共拆分出4大ck集群:交易集群、营销集群、信用集群、混合集群. 营销场景承担着更大的存储与更高频次的写入,与其他业务解耦可以更好地提高ck集群的并发量与计算效率。
2)改造点2: 因势利导,动态的写入策略
clickhouse集群数据写入规则在消费端进行封装优化, 支持按批量条数,批量大小,定时间隔的策略进行批量写入,对不同场景不同流量的数据进行写入规则调节适配,发挥ck大批量写入的同时也保证数据的实时性.
3)改造点3: 化繁为简,,预聚合
原始消息经过解析集群规整富化后, 消息体大小缩减10倍, 再由Flink集群基于核心指标进行分钟级聚合,最终写入到RDWS层,规模相较于RODS层减少95%,大幅提高ck查询效率。
2、用户行为路径查询实践
背景: 行为路径分析能够帮助分析师洞察出某一类用户在各个主题事件间的路径分布特性。可依次通过人群筛选与路径筛选来得到目标人群与目标路径,再将筛选结果及相应的数据通过桑基图或排行榜的方式来呈现。所以用户行为路径面临着海量数据如何高效查询、指标计算等问题。
设计:
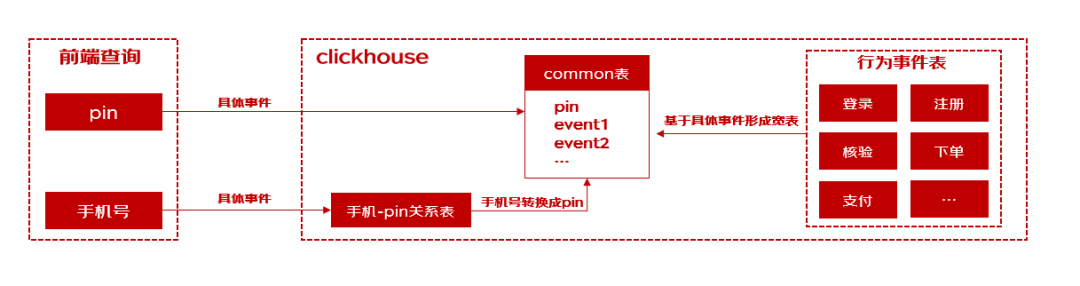
1)及时生成common表,减少查询数据范围:因用户行为事件明细极其庞大,分散在各个行为主题表中,所以在查询过程中,基于需要查询的事件与时间范围进行筛选, 实时创建并推送值common表,从common中查询明细结果,减少查询范围提高查询效率;
2)合理利用clickhouse一级索引: clickhouse基于一级索引字段建立稀疏索引,所以若无法命中一级索引相当于进行一次全表扫描;以pin为一级索引,并建立pin与手机号的mapping关系表,使得每次查询即使不同条件也能命中索引,提高检索效率;
3)巧妙利用位图函数实现去重等操作: 利用clickhouse自带bitmapCardinality、bitmapAndCardinality、bitmapOrCardinality等函数实现用户pin的去重操作,有效地节省了存储空间。
3、clickhouse生产运维实践
背景: 在clickhouse的日常使用中,也遇到了一些优化实践,最后简单介绍一下相关问题与优化:
Q: 生产过程中发现zk机器磁盘多次报警,zk日志与快照占用存储较多
A: 设置日志与快照份数以及自动清理的频率,合理利用磁盘使用率
Q: 分布式表写入时会进行分片计算与数据分发,导致cpu与内存飙升,报错:Merges are processing significantly slower than inserts,merges速度跟不上写入速度
A: 写local表,同时使用vip写入,尽量保持数据写入磁盘均匀分布;
Q: zk session经常断掉,或者处理不过来事务,导致ck所有表结构出现readonly;
A: 高版本clickhouse集群支持raftKeeper,在一定程度上解决zookeeper性能问题,目前正在持续调研跟进中
五、未来展望
总结起来,clickhouse在大批量数据读写场景下对比同类型引擎有着巨大的性能优势,在风险洞察实时分析、实时预警领域承担着重要职责;同时我们也在对clickhouse不断地深挖优化,针对高并发、zookeeper集群不稳定等ck劣势方面进行采取集群拆分、优化SQL来提高查询并发能力,后续也将推进升级版本支持RaftKeeper等措施来完善clickhouse的不足之处。
声明:本文来自京东科技技术说,版权归作者所有。文章内容仅代表作者独立观点,不代表安全内参立场,转载目的在于传递更多信息。如有侵权,请联系 anquanneican@163.com。
